NLP入门实践总结:预训练时代下的文本分类、数据增强与模型调优、常见数据集与动手实践...
分类问题是NLP(Natural Language Processing,自然语言处理)领域的经典常见任务,而随着预训练模型的发展,预训练时代下的文本分类算法逐步成为了我们从事NLP相关工作的必备技能。
本文作为NLP经典任务入门的实践总结,结合了最前沿的算法、开源工具(飞桨自然语言处理模型库PaddleNLP)与代码实操、工作实践,希望借此抛砖引玉,能多多交流探讨当前预训练模型在文本分类上的应用,供大家一起参考学习。
一、场景介绍
文本分类,顾名思义,就是对给定的一个句子或一段文本进行分类。文本分类在互联网、金融、医疗、法律、工业等领域都有广泛的应用,例如文章主题分类、商品信息分类、对话意图分类、论文专利分类、邮件自动标签、评论正负倾向识别、投诉事件分类、广告检测以及敏感违法内容检测等,这些应用场景全部都可以抽象为文本分类任务。
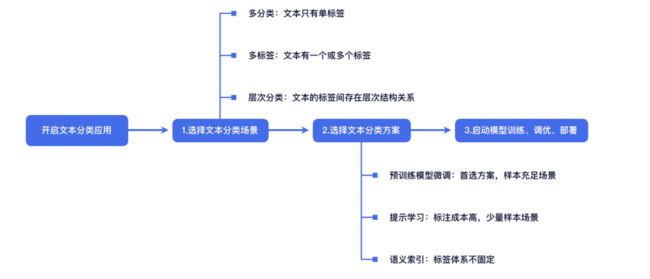
根据任务类别定义,可以将文本分类划分为二分类/多分类、多标签、层次分类三类场景。以下面的新闻分类为例:
二分类/多分类:标签集中有两个或以上的标签类别,每个样本有且只有一个标签;
多标签:每个样本有一个或多个标签;
层次分类:特殊的多分类或多标签任务,标签之间具有层次关系。比如下图样本的一级标签是体育,二级标签是足球,体育为足球的父标签。

图:三类文本分类场景
二、技术方案选型与开源工具推荐
预训练模型微调、提示学习是当前解决分类任务的主流思路。此外,笔者最近还使用了PaddleNLP中开源的基于语义索引的技术方案,下面一一介绍。
方案一:预训练模型微调
预训练模型微调是目前NLP领域最通用的文本分类方案。预训练模型与具体的文本分类任务的关系可以直观地理解为,预训练模型已经懂得了通用的句法、语义等知识,采用具体下游任务数据微调训练可以使得模型”更懂”这个任务,在预训练过程中学到的知识基础可以使文本分类效果事半功倍。
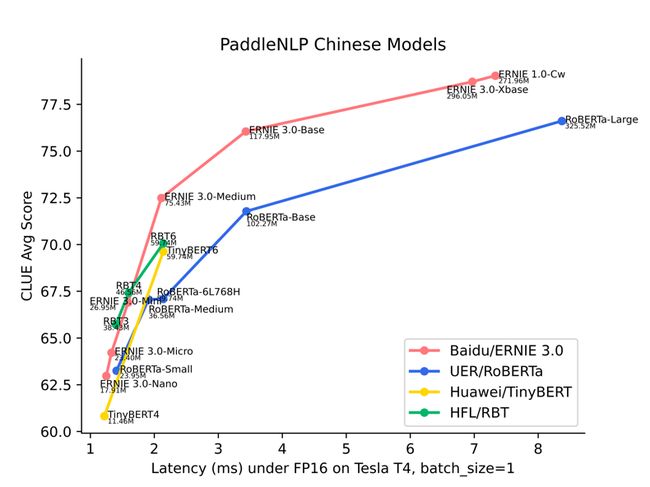
图:模型精度-时延图
在预训练模型选择上,推荐使用百度开源的文心ERNIE 系列模型,其在精度和性能上的综合表现已全面领先于 UER/RoBERTa、Huawei/TinyBERT、HFL/RBT、RoBERTa-wwm-ext-large等中文模型。PaddleNLP开源了如下多种尺寸的ERNIE系列预训练模型,满足多样化的精度、性能需求:
ERNIE 1.0-Large-zh-CW(24L1024H)
ERNIE 3.0-Xbase-zh(20L1024H)
ERNIE 2.0-Base-zh (12L768H)
ERNIE 3.0-Base (12L768H)
ERNIE 3.0-Medium (6L768H)
ERNIE 3.0-Mini (6L384H)
ERNIE 3.0-Micro (4L384H)
ERNIE 3.0-Nano (4L312H)
… …
除中文模型外,PaddleNLP 也提供ERNIE 2.0英文版、以及基于96种语言(涵盖法语、日语、韩语、德语、西班牙语等几乎所有常见语言)预训练的多语言模型ERNIE-M,满足不同语言的文本分类任务需求。
方案二:提示学习
提示学习(Prompt Learning)适用于标注成本高、标注样本较少的文本分类场景。在小样本场景中,相比于预训练模型微调学习,提示学习能取得更好的效果。提示学习的主要思想是将文本分类任务转换为构造提示(Prompt)中掩码的分类预测任务,使用待预测字的预训练向量来初始化分类器参数,充分利用预训练语言模型学习到的特征和标签文本,从而降低样本量需求。PaddleNLP集成了R-Drop 和 RGL 等前沿策略,帮助提升模型效果。
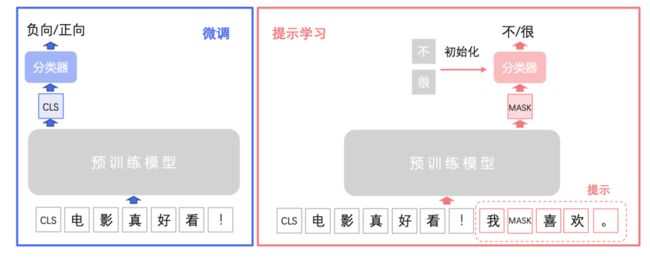
图:预训练模型微调 vs 提示学习
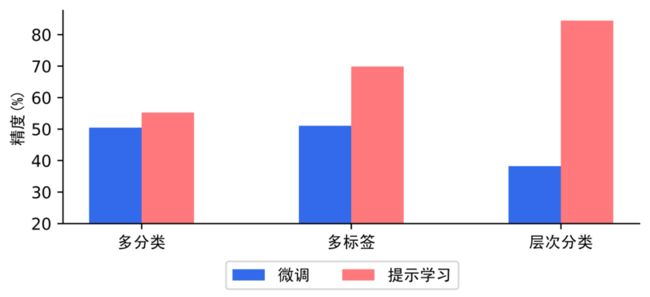
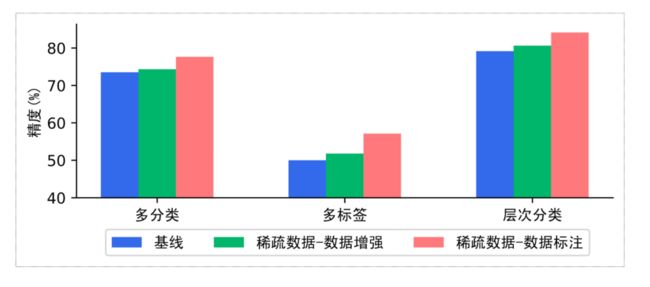
如下图,在多分类、多标签、层次分类任务的小样本场景下,提示学习比预训练模型微调方案,效果上有显著优势。
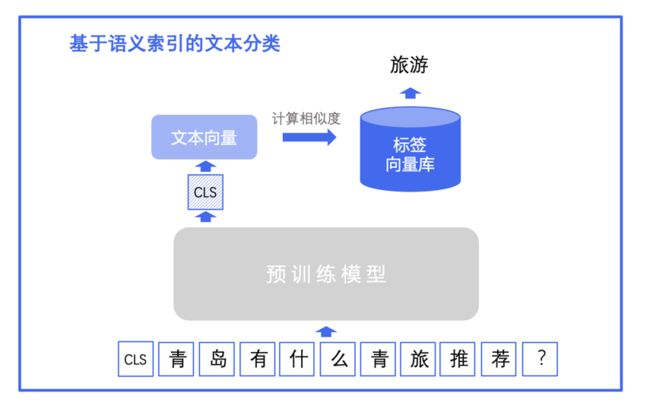
方案三:语义索引
基于语义索引的文本分类方案适用于标签类别不固定、或大规模标签类别的场景。在新增标签类别的情况下,无需重新训练模型。语义索引的目标是从海量候选召回集中快速、准确地召回一批与输入文本语义相关的文本。基于语义索引的文本分类方法具体来说是将标签集作为召回目标集,召回与输入文本语义相似的标签作为文本的标签类别,尤其适用于层次分类场景。
综上,针对多分类、多标签、层次分类等高频分类场景,推荐使用PaddleNLP中开源的预训练模型微调、提示学习、语义索引三种端到端全流程分类方案。
PaddleNLP文本分类方案提供了简单易用的数据标注-模型训练-模型调优-模型压缩-预测部署全流程方案,如下图所示。
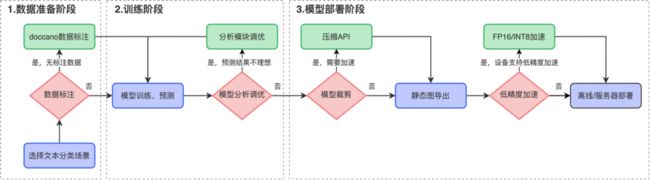
开发者仅需输入指定格式的数据,一行命令即可开启文本分类训练。对于训练结果不理想情况,分析模块提供了多种模型调优方案,解决文本分类数据难题。
对于模型部署上线要进一步压缩模型体积的需求,可一行代码调用PaddleNLP的 模型压缩 API ——采用了DynaBERT 中宽度自适应裁剪策略,对预训练模型多头注意力机制中的头(Head )进行重要性排序,保证更重要的头(Head )不容易被裁掉,然后用原模型作为蒸馏过程中的教师模型,宽度更小的模型作为学生模型,蒸馏得到的学生模型就是我们裁剪得到的模型。实验表明模型裁剪能够有效缩小模型体积、减少内存占用、提升推理速度。此外,模型裁剪去掉了部分冗余参数的扰动,增加了模型的泛化能力,在部分任务中预测精度得到提高。通过模型裁剪,可以得到更快、更准的模型!

表:模型裁剪效果
完成模型训练和裁剪后,开发者可以根据需求选择是否进行低精度(FP16/INT8)加速,快速高效实现模型离线或服务化部署。
对预训练时代NLP任务入门感兴趣的小伙伴,可以扫码报名进群,获取PaddleNLP官方近期组织的直播链接,进群还可获得10GB NLP学习大礼包等超多福利~此外,课程中还将介绍数据增强、稀疏数据与脏数据挖掘等数据、模型调优策略,亲测好用,这部分是课程精华,非常推荐各位NLPer去学习交流。

挖掘该工具更多的潜力和惊喜,请进传送门(STAR收藏起来,不易走丢~)
https://github.com/PaddlePaddle/PaddleNLP/tree/develop/applications/text_classification
图:PaddleNLP文本分类详细文档介绍
接下来,我们来看如何进行数据、模型调优。
三、数据、模型调优
在实际工作中,除了技术方案选型、如何进行模型调优、如何解决少样本等问题,使很多开发者望而却步,迟迟难以上线。
有这么一句话在业界广泛流传,"数据决定了机器学习的上限,而模型和算法只是逼近这个上限",可见数据质量的重要性。PaddleNLP文本分类方案依托TrustAI可信增强能力和数据增强API开源了模型分析模块,针对标注数据质量不高、训练数据覆盖不足、样本数量少等文本分类常见数据痛点,提供稀疏数据筛选、脏数据清洗、数据增强三种数据优化策略,解决训练数据缺陷问题,用低成本方式获得大幅度的效果提升。
集可信分析和增强于一体的可信AI工具集-TrustAI,能够有效识别和优化NLP领域数据标注的常见问题,如『训练数据中存在脏数据阻碍模型效果提升』,『数据标注成本太高但又不清楚该标注什么数据』,『数据分布有偏导致模型鲁棒性差』等,TrustAI能帮助NLP开发者解决训练数据缺陷问题,用最小的标注成本获得最大幅度的效果提升
可戳项目地址了解详情:
https://github.com/PaddlePaddle/TrustAI
策略一:稀疏数据筛选
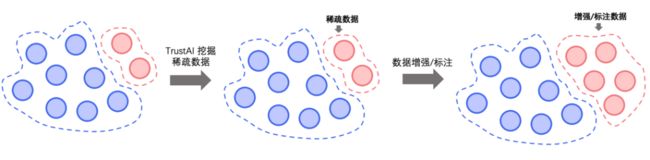
基于TrustAI中可信增强方法挖掘待预测数据中缺乏训练集数据支持的数据(稀疏数据),然后使用特征相似度方法选择能够提供证据支持的训练数据进行数据增强,或选择能够提供证据支持的未标注数据进行数据标注,这两种稀疏数据筛选策略均能有效提升模型表现。
策略二:脏数据清洗
基于TrustAI的可信增强能力,采用表示点方法(Representer Point)计算训练数据对模型的影响分数,分数高的训练数据表明对模型影响大,这些数据有较大概率为脏数据(被错误标注的样本)。脏数据清洗策略通过高效识别训练集中脏数据,有效降低人力检查成本。
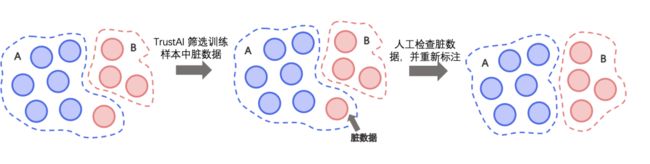
我们在多分类、多标签、层次分类场景中评测脏数据清洗策略,实验表明脏数据清洗策略对文本分类任务有显著提升效果。
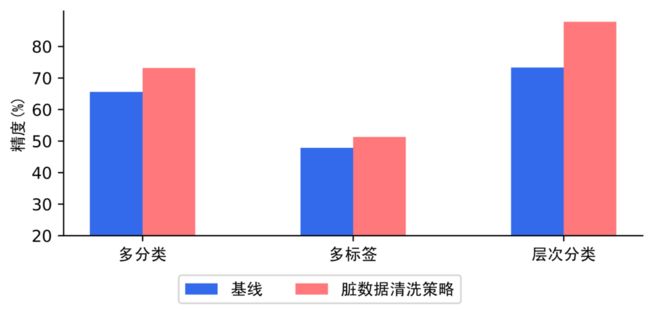
策略三:数据增强
PaddleNLP内置数据增强API,支持词替换、词删除、词插入、词置换、基于上下文生成词(MLM预测)、TF-IDF等多种数据增强策略,只需一行命令即可实现数据集增强扩充。我们在某分类数据集(500条)中测评多种数据增强 策略,实验表明在数据量较少的情况下,数据增强策略能够增加数据集多样性,提升模型效果。
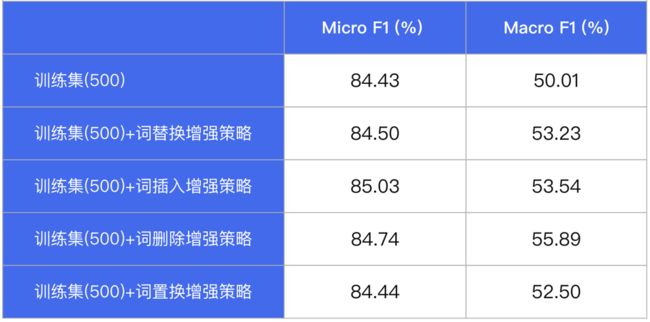
图:数据增强策略效果
总结一下PaddleNLP开源的文本分类场景方案特色:
方案全覆盖:涵盖文本分类高频场景,开源微调、提示学习、基于语义索引多种分类技术方案,满足不同文本分类落地需求;
模型高效调优:强强结合数据增强能力与TrustAI可信增强技术,解决脏数据、标注数据欠缺以及数据不平衡等问题,大幅提升模型效果;
产业级全流程:打通数据标注-模型训练-模型调优-模型压缩-预测部署全流程,助力开发者简单高效地完成文本分类任务。

百度飞桨PaddleNLP官方直播分享课程
10月27日-28日,两位百度高工将带来直播分享,详细解读预训练时代下的文本分类系统方案,数据增强与模型调优策略,推荐一波(定好闹钟哦,不确定是否有回放)~

*注:如果已经在前文扫码进群,无需重复操作。
扫码还可获得文本分类常用数据集、NLP学习大礼包等超多福利!
四、实践经验总结
1、数据为王时代
以笔者个人的实践经验来说,提高文本分类精度最快、最有效的方法是既不是模型,也不是算法调参,而是数据质量。文本分类总的来说不是个复杂的自然语言处理任务(甚至可以说是最基本的任务),如何更好地进行数据标签的划分,减少混淆重合情况和高质量的数据标注(正确标注,标准统一,且训练集与预测数据分布一致)是得到高精度的文本分类模型的关键。
标签体系划分
文本分类任务的标签体系依具体的任务而定,一个清晰分界明确的标签体系有利于提升数据标注质量。在多分类任务中需尽量避免标签之间范围重合,避免标注环节中遇到相似的样本时,有的被标记为A,有的标记为B,降低模型准确率。
标注正确
"Garbage in, garbage out(垃圾进,垃圾出)",如果训练数据包含很多错误,可想而知模型不会有很好的预测结果。人工检查所有数据标注是否准确,成本不低,因此可以借助前文介绍的TrustAI工具,计算训练数据对模型的扰动,来筛选出脏数据进行重新标注。
训练数据和测试数据分布一致
模型学习的过程可以理解为拟合训练数据分布的过程,只有模型学习与预测场景相似的训练样本,才能在预测数据上有更好的表现。在实践场景中效果差,基本是这个问题。
精选有效信息
目前预训练模型通常支持的max_length最大为512,有些模型可能会应用一些策略使模型能够接受输入长度最长2048,当然还有一些支持长文本的模型例如Longformer,ERNIE-Doc。但输入文本过长,容易爆显存,训练速度过慢,并且由于文本包含过多无用的信息干扰使模型效果变差。如何精选文本数据需要根据实际情况而定,常见方法如按句号对句子截断、利用正则匹配筛选有效文本内容等。
充足的数据
虽然文本分类在零样本和小样本领域有许多探索,但效果暂时还是很难超越在充足训练数据下进行微调。人工标注结合数据增强策略是常见扩充数据的方法。
2、更多实战
PaddleNLP开源的文本分类方案涵盖多分类、多标签、层次分类三大场景,提供微调、提示学习、基于语义检索等多种分类技术方案。很全了!并且强强结合数据增强能力与可信增强技术,解决脏数据、标注数据欠缺、数据不平衡等问题,能够大幅提升模型效果,值得一试。
可以快速使用PaddleNLP完成实现多分类、多标签、层次分类任务。你可以仿照数据集格式,替换数据集目录,直接训练自己的数据。赶紧实践起来吧!
地址:
https://github.com/PaddlePaddle/PaddleNLP/tree/develop/applications/text_classification
更多精彩直播

PaddleNLP项目地址:
GitHub: https://github.com/PaddlePaddle/PaddleNLP
TrustAI项目地址:
GitHub: https://github.com/PaddlePaddle/TrustAI