N-CMAPSS代码解析
代码目录介绍

重点部分代码解读
sample_creator_unit_auto.py
def main():
# current_dir = os.path.dirname(os.path.abspath(__file__))
parser = argparse.ArgumentParser(description='sample creator')
parser.add_argument('-w', type=int, default=10, help='window length', required=True)
parser.add_argument('-s', type=int, default=10, help='stride of window')
parser.add_argument('--sampling', type=int, default=1, help='sub sampling of the given data. If it is 10, then this indicates that we assumes 0.1Hz of data collection')
parser.add_argument('--test', type=int, default='0', help='select train or test, if it is zero, then extract samples from the engines used for training')
args = parser.parse_args() #解析参数——使用 parse_args() 解析添加的参数
sequence_length = args.w #窗口长度
stride = args.s #步长
sampling = args.sampling
selector = args.test
# Load data
'''
W: operative conditions (Scenario descriptors)
X_s: measured signals
X_v: virtual sensors
T(theta): engine health parameters
Y: RUL [in cycles]
A: auxiliary data
'''
df_all = df_all_creator(data_filepath, sampling)
'''
划分训练集和测试集
Split dataframe into Train and Test
Training units: 2, 5, 10, 16, 18, 20
Test units: 11, 14, 15
'''
# units = list(np.unique(df_A['unit']))
units_index_train = [2.0, 5.0, 10.0, 16.0, 18.0, 20.0]
units_index_test = [11.0, 14.0, 15.0]
print("units_index_train", units_index_train)
print("units_index_test", units_index_test)
# if any(int(idx) == unit_index for idx in units_index_train):
# df_train = df_train_creator(df_all, units_index_train)
# print(df_train)
# print(df_train.columns)
# print("num of inputs: ", len(df_train.columns) )
# df_test = pd.DataFrame()
#
# else :
# df_test = df_test_creator(df_all, units_index_test)
# print(df_test)
# print(df_test.columns)
# print("num of inputs: ", len(df_test.columns))
# df_train = pd.DataFrame()
df_train = df_train_creator(df_all, units_index_train)
print(df_train)
print(df_train.columns)
print("num of inputs: ", len(df_train.columns) )
df_test = df_test_creator(df_all, units_index_test)
print(df_test)
print(df_test.columns)
print("num of inputs: ", len(df_test.columns))
del df_all
gc.collect()
df_all = pd.DataFrame()
sample_dir_path = os.path.join(data_filedir, 'Samples_whole')
sample_folder = os.path.isdir(sample_dir_path)
if not sample_folder:
os.makedirs(sample_dir_path)
print("created folder : ", sample_dir_path)
cols_normalize = df_train.columns.difference(['RUL', 'unit']) #去掉df_train中的['RUL', 'unit']这两列
sequence_cols = df_train.columns.difference(['RUL', 'unit'])
#selector == 0则从train中选择数据进行训练,否则,从测试集单元中选择数据
if selector == 0:
for unit_index in units_index_train:
data_class = Input_Gen (df_train, df_test, cols_normalize, sequence_length, sequence_cols, sample_dir_path,
unit_index, sampling, stride =stride)
data_class.seq_gen()
else:
for unit_index in units_index_test:
data_class = Input_Gen (df_train, df_test, cols_normalize, sequence_length, sequence_cols, sample_dir_path,
unit_index, sampling, stride =stride)
data_class.seq_gen()
data_preparation_unit.py
#加载所有特征
def df_all_creator(data_filepath, sampling):
"""
"""
# Time tracking, Operation time (min): 0.003
t = time.process_time()
with h5py.File(data_filepath, 'r') as hdf:
# Development(training) set 训练数据和测试数据是已经分好了的
W_dev = np.array(hdf.get('W_dev')) # W
X_s_dev = np.array(hdf.get('X_s_dev')) # X_s
X_v_dev = np.array(hdf.get('X_v_dev')) # X_v
T_dev = np.array(hdf.get('T_dev')) # T
Y_dev = np.array(hdf.get('Y_dev')) # RUL
A_dev = np.array(hdf.get('A_dev')) # Auxiliary
# Test set
W_test = np.array(hdf.get('W_test')) # W
X_s_test = np.array(hdf.get('X_s_test')) # X_s
X_v_test = np.array(hdf.get('X_v_test')) # X_v
T_test = np.array(hdf.get('T_test')) # T
Y_test = np.array(hdf.get('Y_test')) # RUL
A_test = np.array(hdf.get('A_test')) # Auxiliary
# Varnams
W_var = np.array(hdf.get('W_var'))
X_s_var = np.array(hdf.get('X_s_var'))
X_v_var = np.array(hdf.get('X_v_var'))
T_var = np.array(hdf.get('T_var'))
A_var = np.array(hdf.get('A_var'))
# from np.array to list dtype U4/U5
W_var = list(np.array(W_var, dtype='U20'))
X_s_var = list(np.array(X_s_var, dtype='U20'))
X_v_var = list(np.array(X_v_var, dtype='U20'))
T_var = list(np.array(T_var, dtype='U20'))
A_var = list(np.array(A_var, dtype='U20'))
W = np.concatenate((W_dev, W_test), axis=0)
X_s = np.concatenate((X_s_dev, X_s_test), axis=0)
X_v = np.concatenate((X_v_dev, X_v_test), axis=0)
T = np.concatenate((T_dev, T_test), axis=0)
Y = np.concatenate((Y_dev, Y_test), axis=0)
A = np.concatenate((A_dev, A_test), axis=0)
print('')
print("Operation time (min): ", (time.process_time() - t) / 60)
print("number of training samples(timestamps): ", Y_dev.shape[0])
print("number of test samples(timestamps): ", Y_test.shape[0])
print('')
print("W shape: " + str(W.shape))
print("X_s shape: " + str(X_s.shape))
print("X_v shape: " + str(X_v.shape))
print("T shape: " + str(T.shape))
print("Y shape: " + str(Y.shape))
print("A shape: " + str(A.shape))
'''
Illusration of Multivariate time-series of condition monitoring sensors readings for Unit5 (fifth engine)
5号机组(第五发动机)状态监测传感器读数的多元时间序列说明
W: operative conditions (Scenario descriptors) - ['alt', 'Mach', 'TRA', 'T2']
X_s: measured signals - ['T24', 'T30', 'T48', 'T50', 'P15', 'P2', 'P21', 'P24', 'Ps30', 'P40', 'P50', 'Nf', 'Nc', 'Wf']
X_v: virtual sensors - ['T40', 'P30', 'P45', 'W21', 'W22', 'W25', 'W31', 'W32', 'W48', 'W50', 'SmFan', 'SmLPC', 'SmHPC', 'phi']
T(theta): engine health parameters - ['fan_eff_mod', 'fan_flow_mod', 'LPC_eff_mod', 'LPC_flow_mod', 'HPC_eff_mod', 'HPC_flow_mod', 'HPT_eff_mod', 'HPT_flow_mod', 'LPT_eff_mod', 'LPT_flow_mod']
Y: RUL [in cycles]
A: auxiliary data - ['unit', 'cycle', 'Fc', 'hs']
'''
df_W = pd.DataFrame(data=W, columns=W_var)
df_Xs = pd.DataFrame(data=X_s, columns=X_s_var)
df_Xv = pd.DataFrame(data=X_v[:,0:2], columns=['T40', 'P30']) #这里的virtual sensors只取了‘T40', 'P30'两个参数
# df_T = pd.DataFrame(data=T, columns=T_var)
df_Y = pd.DataFrame(data=Y, columns=['RUL'])
df_A = pd.DataFrame(data=A, columns=A_var).drop(columns=['cycle', 'Fc', 'hs']) #只取unit
# Merge all the dataframes
df_all = pd.concat([df_W, df_Xs, df_Xv, df_Y, df_A], axis=1)
# 这里的df_all实际只有22个参数
print ("df_all", df_all) # df_all = pd.concat([df_W, df_Xs, df_Xv, df_Y, df_A], axis=1).drop(columns=[ 'P45', 'W21', 'W22', 'W25', 'W31', 'W32', 'W48', 'W50', 'SmFan', 'SmLPC', 'SmHPC', 'phi', 'Fc', 'hs'])
print ("df_all.shape", df_all.shape)
# del [[df_W, df_Xs, df_Xv, df_Y, df_A]]
# gc.collect()
# df_W = pd.DataFrame()
# df_Xs = pd.DataFrame()
# df_Xv = pd.DataFrame()
# df_Y = pd.DataFrame()
# df_A = pd.DataFrame()
df_all_smp = df_all[::sampling]
print ("df_all_sub", df_all_smp) # df_all = pd.concat([df_W, df_Xs, df_Xv, df_Y, df_A], axis=1).drop(columns=[ 'P45', 'W21', 'W22', 'W25', 'W31', 'W32', 'W48', 'W50', 'SmFan', 'SmLPC', 'SmHPC', 'phi', 'Fc', 'hs'])
print ("df_all_sub.shape", df_all_smp.shape)
return df_all_smp
#加载训练集的所有数据
def df_train_creator(df_all, units_index_train):
train_df_lst= []
for idx in units_index_train:
df_train_temp = df_all[df_all['unit'] == np.float64(idx)]
train_df_lst.append(df_train_temp)
df_train = pd.concat(train_df_lst)
df_train = df_train.reset_index(drop=True)
return df_train
#加载所有测试集数据
def df_test_creator(df_all, units_index_test):
test_df_lst = []
for idx in units_index_test:
df_test_temp = df_all[df_all['unit'] == np.float64(idx)]
test_df_lst.append(df_test_temp)
df_test = pd.concat(test_df_lst)
df_test = df_test.reset_index(drop=True)
return df_test
#特征滑窗如何选取数据
def gen_sequence(id_df, seq_length, seq_cols):
""" Only sequences that meet the window-length are considered, no padding is used. This means for testing
we need to drop those which are below the window-length. An alternative would be to pad sequences so that
we can use shorter ones """
'''
只考虑满足窗口长度的序列,不使用填充。这意味着在测试中,我们需要去掉那些低于窗口长度的部分。另一种选择是填充序列,这样我们就可以使用更短的序列
'''
# for one id I put all the rows in a single matrix 例如id=2的发动机,所有数据放在一个矩阵中
data_matrix = id_df[seq_cols].values #此处只是特征部分,没有取RUL
num_elements = data_matrix.shape[0] #行数
# Iterate over two lists in parallel.
# For example id1 have 192 rows and sequence_length is equal to 50 用长度为50的滑窗解释滑窗过程
# so zip iterate over two following list of numbers (0,142),(50,192)
# 0 50 -> from row 0 to row 50
# 1 51 -> from row 1 to row 51
# 2 52 -> from row 2 to row 52
# ...
# 142 192 -> from row 142 to 192
for start, stop in zip(range(0, num_elements - seq_length), range(seq_length, num_elements)):
yield data_matrix[start:stop, :]
#标签滑窗如何选取标签
def gen_labels(id_df, seq_length, label):
""" Only sequences that meet the window-length are considered, no padding is used. This means for testing
we need to drop those which are below the window-length. An alternative would be to pad sequences so that
we can use shorter ones """
# For one id I put all the labels in a single matrix.
# For example:
# [[1]
# [4]
# [1]
# [5]
# [9]
# ...
# [200]]
data_matrix = id_df[label].values #只有lable值
num_elements = data_matrix.shape[0]
# I have to remove the first seq_length labels
# because for one id the first sequence of seq_length size have as target
# the last label (the previus ones are discarded).
# All the next id's sequences will have associated step by step one label as target.
#窗口的下一条RUL作为标签
return data_matrix[seq_length:num_elements, :]
#特征窗口滑动过程代码 ,利用滑窗生成特征sample_array,以及标签label_array
def time_window_slicing (input_array, sequence_length, sequence_cols):
# generate labels
label_gen = [gen_labels(input_array[input_array['unit'] == id], sequence_length, ['RUL'])
for id in input_array['unit'].unique()]
label_array = np.concatenate(label_gen).astype(np.float32)
# label_array = np.concatenate(label_gen)
# transform each id of the train dataset in a sequence
seq_gen = (list(gen_sequence(input_array[input_array['unit'] == id], sequence_length, sequence_cols))
for id in input_array['unit'].unique())
sample_array = np.concatenate(list(seq_gen)).astype(np.float32)
# sample_array = np.concatenate(list(seq_gen))
print("sample_array")
return sample_array, label_array
#生成多个独立的窗口,只有RUL一列
def time_window_slicing_label_save (input_array, sequence_length, stride, index, sample_dir_path, sequence_cols = 'RUL'):
'''
ref
for i in range(0, input_temp.shape[0] - sequence_length):
window = input_temp[i*stride:i*stride + sequence_length, :] # each individual window
window_lst.append(window)
# print (window.shape)
'''
# generate labels
window_lst = [] # a python list to hold the windows
input_temp = input_array[input_array['unit'] == index][sequence_cols].values
num_samples = int((input_temp.shape[0] - sequence_length)/stride) + 1 #samples数量 也就是有多少个窗口
for i in range(num_samples):
window = input_temp[i*stride:i*stride + sequence_length] # each individual window 每个窗口内的数据
window_lst.append(window)
# print (window.shape)
label_array = np.asarray(window_lst).astype(np.float32)
# label_array = np.asarray(window_lst)
# np.save(os.path.join(sample_dir_path, 'Unit%s_rul_win%s_str%s' %(str(int(index)), sequence_length, stride)),
# label_array) # save the file as "outfile_name.npy"
return label_array[:,-1] #取label_array矩阵的所有行,最后一列
#生成多个独立的窗口,仅包含特征
def time_window_slicing_sample_save (input_array, sequence_length, stride, index, sample_dir_path, sequence_cols):
'''
'''
# generate labels
window_lst = [] # a python list to hold the windows
input_temp = input_array[input_array['unit'] == index][sequence_cols].values
print ("Unit%s input array shape: " %index, input_temp.shape)
num_samples = int((input_temp.shape[0] - sequence_length)/stride) + 1
for i in range(num_samples):
window = input_temp[i*stride:i*stride + sequence_length,:] # each individual window
window_lst.append(window)
sample_array = np.dstack(window_lst).astype(np.float32)
# sample_array = np.dstack(window_lst)
print ("sample_array.shape", sample_array.shape)
# np.save(os.path.join(sample_dir_path, 'Unit%s_samples_win%s_str%s' %(str(int(index)), sequence_length, stride)),
# sample_array) # save the file as "outfile_name.npy"
return sample_array
#准备数据,包含滑窗处理和归一化处理后的训练集和测试集
class Input_Gen(object):
'''
class for data preparation (sequence generator)
'''
def __init__(self, df_train, df_test, cols_normalize, sequence_length, sequence_cols, sample_dir_path,
unit_index, sampling, stride):
'''
'''
# self.__logger = logging.getLogger('data preparation for using it as the network input')
print("the number of input signals: ", len(cols_normalize))
min_max_scaler = preprocessing.MinMaxScaler(feature_range=(-1, 1)) # 定义归一化的范围是(-1,1)
norm_df = pd.DataFrame(min_max_scaler.fit_transform(df_train[cols_normalize]),#norm_df是归一化后的值
columns=cols_normalize,
index=df_train.index)
join_df = df_train[df_train.columns.difference(cols_normalize)].join(norm_df)
df_train = join_df.reindex(columns=df_train.columns) #重新设置索引,此时的df_train为归一化后的值
norm_test_df = pd.DataFrame(min_max_scaler.transform(df_test[cols_normalize]), columns=cols_normalize,
index=df_test.index)
test_join_df = df_test[df_test.columns.difference(cols_normalize)].join(norm_test_df)
df_test = test_join_df.reindex(columns=df_test.columns)
df_test = df_test.reset_index(drop=True)
self.df_train = df_train
self.df_test = df_test
print (self.df_train)
print (self.df_test)
self.cols_normalize = cols_normalize
self.sequence_length = sequence_length
self.sequence_cols = sequence_cols
self.sample_dir_path = sample_dir_path
self.unit_index = np.float64(unit_index)
self.sampling = sampling
self.stride = stride
def seq_gen(self):
'''
concatenate vectors for NNs
:param :
:param :
:return:
'''
#对不同的编号发动机逐个取特征和标签
if any(index == self.unit_index for index in self.df_train['unit'].unique()):#训练集
print ("Unit for Train")
label_array = time_window_slicing_label_save(self.df_train, self.sequence_length,
self.stride, self.unit_index, self.sample_dir_path, sequence_cols='RUL')
sample_array = time_window_slicing_sample_save(self.df_train, self.sequence_length,
self.stride, self.unit_index, self.sample_dir_path, sequence_cols=self.cols_normalize)
else:#测试集
print("Unit for Test")
label_array = time_window_slicing_label_save(self.df_test, self.sequence_length,
self.stride, self.unit_index, self.sample_dir_path, sequence_cols='RUL')
sample_array = time_window_slicing_sample_save(self.df_test, self.sequence_length,
self.stride, self.unit_index, self.sample_dir_path, sequence_cols=self.cols_normalize)
# sample_split_lst = np.array_split(sample_array, 3, axis=2)
# print (sample_split_lst[0].shape)
# print(sample_split_lst[1].shape)
# print(sample_split_lst[2].shape)
# label_split_lst = np.array_split(label_array, 3, axis=0)
# print (label_split_lst[0].shape)
# print(label_split_lst[1].shape)
# print(label_split_lst[2].shape)
print("sample_array.shape", sample_array.shape)
print("label_array.shape", label_array.shape)
#以压缩的.npz 格式将多个数组保存到一个文件中,保存在 ./N-CMAPSS/Samples_whole 目录下
np.savez_compressed(os.path.join(self.sample_dir_path, 'Unit%s_win%s_str%s_smp%s' %(str(int(self.unit_index)), self.sequence_length, self.stride, self.sampling)),
sample=sample_array, label=label_array)
print ("unit saved")
return
inference_cnn_aggr.py
'''
DL models (FNN, 1D CNN and CNN-LSTM) evaluation on N-CMAPSS
12.07.2021
Hyunho Mo
[email protected]
'''
## Import libraries in python
import gc
import argparse
import os
import json
import logging
import sys
import h5py
import time
import matplotlib
import numpy as np
import pandas as pd
import seaborn as sns
from pandas import DataFrame
import matplotlib.pyplot as plt
from matplotlib import gridspec
import math
import random
from random import shuffle
from tqdm.keras import TqdmCallback
seed = 0
random.seed(0)
np.random.seed(seed)
import importlib
from scipy.stats import randint, expon, uniform
import sklearn as sk
from sklearn import svm
from sklearn.utils import shuffle
from sklearn import metrics
from sklearn import preprocessing
from sklearn import pipeline
from sklearn.metrics import mean_squared_error
from math import sqrt
from tqdm import tqdm
import scipy.stats as stats
# from sklearn.utils.testing import ignore_warnings
# from sklearn.exceptions import ConvergenceWarning
# import keras
import tensorflow as tf
print(tf.__version__)
# import keras.backend as K
import tensorflow.keras.backend as K
from tensorflow.keras import backend
from tensorflow.keras import optimizers
from tensorflow.keras.models import Sequential, load_model, Model
from tensorflow.keras.layers import Input, Dense, Flatten, Dropout, Embedding
from tensorflow.keras.layers import BatchNormalization, Activation, LSTM, TimeDistributed, Bidirectional
from tensorflow.keras.layers import Conv1D
from tensorflow.keras.layers import MaxPooling1D
from tensorflow.keras.layers import concatenate
from tensorflow.keras.callbacks import EarlyStopping, ModelCheckpoint, LearningRateScheduler
from tensorflow.python.framework.convert_to_constants import convert_variables_to_constants_v2_as_graph
from tensorflow.keras.initializers import GlorotNormal, GlorotUniform
initializer = GlorotNormal(seed=0)
# initializer = GlorotUniform(seed=0)
from utils.data_preparation_unit import df_all_creator, df_train_creator, df_test_creator, Input_Gen
from utils.dnn import one_dcnn,CNNBranch
# import tensorflow.compat.v1 as tf
# tf.disable_v2_behavior()
# Ignore tf err log
pd.options.mode.chained_assignment = None # default='warn'
# from tensorflow.compat.v1 import ConfigProto
# from tensorflow.compat.v1 import InteractiveSession
# config = ConfigProto()
# config.gpu_options.allow_growth = True
# session = InteractiveSession(config=config)
#gpus = tf.config.experimental.list_physical_devices('GPU')
#for gpu in gpus:
# tf.config.experimental.set_memory_growth(gpu, True)
# tf.compat.v1.logging.set_verbosity(tf.compat.v1.logging.ERROR)
# tf.get_logger().setLevel(logging.ERROR)
# tf.config.set_visible_devices([], 'GPU')
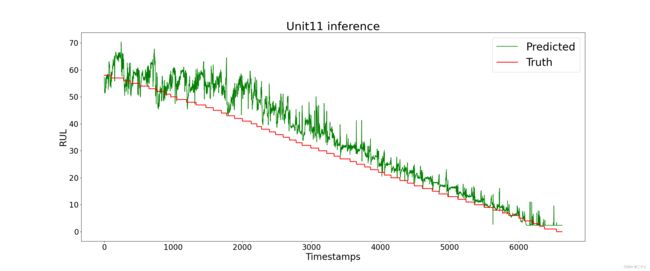
# 实验结果图