1. Introduction
雾霾是由气溶胶粒子在大气中的散射效应引起的一种自然现象。它会导致视觉内容的严重模糊,从而给人类观察者和计算机视觉系统带来麻烦。去雾方法的目的是去除雾霾,提高现实世界模糊图像的视觉质量,有利于图像分割[4,38]、对模糊天气的目标检测[15,34]等计算机视觉任务。
雾霾效应的退化可以用科什米德定律[29,30]来表述:
其中,I(z)表示观测到的模糊图像的第z个像素,J(z)和A分别为场景辐射和全球大气光。传输图t(z)=eβd(z)由场景深度d(z)和反映雾霾密度的散射系数β来定义。
由于深度神经网络[12,13]具有强大的学习能力,人们提出了许多方法,以监督的方式in a supervised manner. 解决图像恢复任务[3,25,35,46,48,49],以及图像去模糊[7,27,31,36]。通过对大量合成的模糊-干净图像对进行训练,监督深度去模糊方法在特定的测试集上取得了令人印象深刻的结果。Through training on a large amount of synthetic hazy-clean image pairs, supervised deep dehazing methods achieved impressive results on specific test sets.
然而,在合成图像和真实世界的模糊图像之间存在着相对较大的领域差距。仅在成对的合成图像上训练的去模糊模型很容易过拟合,并且不能很好地概括现实世界的模糊条件。However, there exists a relatively large domain gap between synthetic and real-world hazy images. Dehazing models that are solely trained on paired synthetic images are easy to over-fitting, and generalize poorly to real-world hazy conditions.
由于期望的真实世界模糊和干净图像对几乎无法获得,近年来,人们提出了许多未配对深度学习方法来探索未配对训练数据的去模糊线索。其中,构建去雾循环和重雾循环的[8,9,17,26,45,50]被广泛采用,因为它提供了一种保持域转换的内容一致性的简单有效的方案。如果模糊和清晰的图像域可以被精确地建模can be accurately modeled,那么该周期框架有望在未配对去雾获得良好的性能gain promising performance。然而,我们认为we argue that,简单地从未配对的图像到图像的转换方法继承CycleGAN[52]框架将无法处理未配对的图像去模糊任务。现有的基于循环的去雾方法忽略了现实世界雾环境的物理性质,即现实世界的雾随密度和深度而变化。如图1(i)和(iii)-(e)所示,基于CycleGAN的方法容易分解为合成固定密度的雾霾,可能会错误地模拟雾霾效应,如随着场景深度的增加,雾霾应变厚。

在本文中,我们提出了一种新的去雾框架D4,即通过将传输图分解为密度和深度
, i.e . Dehazing via Decomposing transmission map into Density and Depth
,用于不配对雾的合成和去除。在模糊图像形成过程中,我们明确地模拟了目标场景的散射系数β和深度图d(z)。如图1(ii)所示,在模糊-重模糊分支上Dehzing-Rehazing,我们的模型被训练为直接从一个雾天的图像from a hazy image 中估计传输图和散射系数。根据等式中表示的物理过程(1),场景深度和干净的内容,然后可以直接导出。在雾-去雾分支上Hazing-Dehazing,我们的模型的目的是估计输入的干净图像的深度信息,然后合成不同密度的模糊图像,即散射系数。考虑到“空间变化的雾霾厚度为感知场景深度提供了额外的线索”,从模糊图像中估计的深度地图作为干净图像深度的伪地面真实。同样,在雾-去雾分支中,在雾步骤中的随机抽样的散射系数β作为去雾步骤中预测的密度的pseudo伪地面真值。
最后,使用我们新的非配对脱雾框架,我们可以(i)从干净图像中估计深度图(图1(g));(ii)合成不同密度的真实模糊图像(数据增强)(图1(h),(i));(iii)比先进的非配对脱雾方法获得更好的脱雾性能。
总的来说,我们的贡献可以总结如下:
•我们提出了一种新的非配对脱雾框架We propose a novel unpaired dehazing framework,它明确地模拟了散射系数(即密度)和模糊场景的深度图。所提出的基于物理的框架在很大程度上缓解了现有的未配对脱雾方法中存在的不适定问题。
•受到直觉的启发:“空间变化的薄雾厚度反映了场景的深度”,我们的模型学习了从模糊的图像中预测深度信息。然后,只有未配对的模糊和干净的图像,我们的模型被训练来预测干净图像的深度信息。
•通过估计的场景深度,我们的模型可以通过改变散射系数来生成不同厚度的模糊图像。这种特征可以作为一种更好地训练脱雾网络的自我论证策略。
•在合成和真实图像上进行了大量的实验,以揭示我们设计的有效性。所提出的D4框架在泛化能力方面具有明显的优势。
2. Related Work
本节简要回顾了以前与我们密切相关的脱雾工作,它们分为基于优先的、有监督的和无监督学习的方法。
基于先验的方法。来消除人们的病态单图像去模糊,早期的尝试集中在从统计分析或观察中发现无雾图像的先验。其中,He等人[14]提出了先验暗通道,假设在无雾霾自然图像中,RGB通道的局部最低强度应接近于零。Zhu等人介绍了颜色衰减之前的[53],他们指出在线性模型中,像素值与饱和度的差应该与场景深度正相关。在[10]中,Fattal发现小斑块的值在RGB空间中主要沿着一维线分布。作为一个严重的缺点,这些方法都 是建立在手工制作的先验之上的,而这并不总是与复杂的真实环境相一致。 As a serious drawback, these methods are all built upon handcrafted priors, which are not always in line with the complex real environments.
监督学习方法。由于cnn的成功和大规模合成数据集的发展,基于深度学习的监督方法放宽了手工制作先验的局限性,并占据了 主导地位 have occupied the dominant position.
。例如,[2]是通过构建卷积神经网络,以端到端的方式从模糊的图像中估计传输地图的先驱。Ren等人[36]提出了一种多尺度卷积网络来预测从粗到细的传输图。然而,这些方法在 分别估计透射光和大气光时,可能会出现累积误差。为了解决这个问题,Li等人[22]重新制定了等式(1)同时估计透射图和大气光。此外,许多方法[24,27,31,32]直接从模糊的输入中估计干净的图像,而没有明确地模拟大气散射模型。近年来,人们多次尝试将领域自适应方法引入图像去模糊任务中,旨在缩小合成数据[39,41,42]和真实数据[39,41,42]之间的领域差距。总的来说,尽管监督方法在合成数据集上取得了显著的性能,但它们 很容易对所提供的训练数据进行过拟合,并不能很好地 推广到其他模糊图像,特别是对于真实世界的雾霾。 they are easy to overfit to the provided training data and generalizing poorly to other hazy images, specifically for real-world haze.
无监督的学习方法。与有监督的学习方法相比,无监督的学习方法不依赖于成对的监督。一些无监督的方法可以直接在模糊的图像上进行训练。例如,[20,21]以零镜头的方式执行脱雾,它将模糊的图像分离到干净的图像和其他组件中。[11]通过最小化模糊图像上基于DCP的[14]损失来训练网络。在这些方法中,由于 干净图像不涉及到训练中,因此没有有效地考虑干净图像域的固有特性,从而限制了它们的性能。 In these methods, since the clean images are not involved in training, the intrinsic prop erty of the clean image domain is not efficiently considered, thus limit their performance.
未配对的去模糊方法从未配对的干净和模糊的图像中学习去模糊映射。除了少数试图在GAN监督下从模糊图像中分离干净成分的方法[47,51]外,大多数未配对脱雾方法都是基于CycllGAN和其他特定设计。例如,CDNet[8]将光学模型引入了CycleGAN中。[50]采用双鉴别器来稳定循环训练。[9]应用了一个拉普拉斯金字塔网络来处理高分辨率的图像,并提出了一个周期感知损失,以更好地保持结构。[26]在CycleGAN的每个分支中都使用了两级映射策略来提高除雾的效果。然而,这些方法在生成模糊图像时,
通常忽略了深度信息和密度的变异性
However, these methods usually ignore the depth information and the variousness of density when generating hazy images.这些因素的缺失导致了不现实的雾霾产生,这将进一步影响脱雾性能。为了解决这些问题,在我们提出的D4框架中,我们专注于探索模糊和干净图像中包含的深度信息和散射系数。
3. Proposed Method
CycleGAN[52]是一个广泛采用的非配对图像到图像转换的框架。一方面,GAN损失被用来强制图像在两个域之间的转换。另一方面, 循环重建损失可以很好地保持内容的一致性。对于图像去模糊,基于cyclegan的方法[8,9,26]通常包含一个去雾网络和一个重雾网络,它们可以预测来自它们对应的[9]的干净图像和模糊图像。在这里,我们认为这种做法可能值得怀疑。这些方法忽略了两个关键的特性, 即深度和密度。因此,所产生的雾霾往往缺乏现实主义和多样性,进一步影响了脱雾网络的学习。为了解决这些问题,我们提出了一种新的非配对脱雾框架,称为D4(通过将传输图分解为密度和深度来进行脱雾)。总体框架和培训程序具体如下。
3.1. The Overall Framework
给定一个干净的图像集XC={C}N1i=1和一个模糊的图像集XH={H}N2i=1,其中N1和N2代表这两个集合的基数。与合成的模糊干净图像数据集不同,两个数据集之间不存在成对信息。如图2所示,我们的D4框架包含了三个网络:去雾网络GD、深度估计网络GE和细化网络GR。
训练去雾网络GD,从 模糊图像H中估计传输图ˆt和散射系数βˆ,可以表示为:
深度估计网络GE的目的是从一个 干净的图像C中估计深度ˆd,其公式为
请注意,我们的深度估计网络GE与其他单个图像深度估计网络[19,33]具有相同的功能,但在训练过程中,我们没有使用任何来自现有深度估计器的 预训练权值或 地面真实深度监督。在我们的D4框架中,网络GE使用来自去雾网络GD的伪监督进行训练,更多的细节在章节中介绍。
细化网络GR。与以往基于cyclegan的直接从输入的干净图像中合成模糊图像的方法不同,所提出的D4通过考虑两个物理性质(密度和深度)来 模拟再模糊过程。具体地说,我们首先结合 干净图像、估计深度和散射系数,推导出一个 粗糙的假模糊图像。然后,细化网络GR作为一个图像到图像的转换网络, 将粗糙的假模糊图像映射到遵循真实模糊图像分布的模糊图像,即。
换句话说,所提出的细化网络可以看作是执行一个有条件的模糊图像生成。给定深度和密度信息,细化网络的目的是生成视觉上真实的模糊图像。
在我们提出的D4框架中,去雾网络GD和深度估计网络GE都基于EfficientNet-lite3 [43]的结构,细化网络GR具有UNet[37]结构。详细的网络架构在我们的补充材料中提供。
3.2. Training Procedure 培训程序
如图2所示,我们的D4的训练包括两个分支:(i)再雾分支和(ii)去再雾分支。
(i) the Dehazing-Rehazing branch and (ii) the Hazing-Dehazing branch .
去雾-重建雾的分支。通过将模糊图像H输入去模糊网络GD,我们可以得到估计的传输图ˆt、估计的散射系数βˆH和计算出的深度dH。同时,去除结果cˆ的计算方法为:
雾-去雾分支。在这个分支中,我们从集合XC中采样一个干净的图像C。利用深度估计网络GE从图像c中估计深度图ˆdC,然后从预定义的均匀分布中随机抽取一个βC。遵循在等式中提出的相同的物理过程7、我们推导出具有可变雾霾密度的粗糙模糊图像ˆhcoarse,

然后由细化网络GR合成假的模糊图像ˆh,并由细化网络GD进一步处理,以预测传输ˆtC,即散射系数βˆC。最后,我们可以使用与等式中相同的计算方法来重建干净的输入 6.值得注意的是,在这个分支中,由于βC是从一个预定义的范围内采样的,我们的模糊过程可以看作是一个数据增强操作,用于后续训练的去模糊网络。
3.3. Training Objectives 培训目标
在提出的D4框架中,我们训练提出的三个网络一起执行去雾和再雾循环。与CycleGANs类似,分别采用循环一致性损失和对抗性训练损失来惩罚内容一致性和数据分布。不同的是,我们提出了新的伪散射系数监督损失和伪深度监督损失来从未配对的模糊和干净的图像中学习物理特性(密度和深度)。
循环一致性损失使得从一个域转移到另一个域的中间图像应该能够返回回来。在我们的D4框架中,重建的干净图像ˆC和模糊图像ˆH应该分别与输入的对应图像C和H一致。我们的D4中的周期稳定性损失可以写如下:
对抗性学习损失评估一个生成的图像是否属于一个特定的领域。换句话说,它惩罚了我们的去除和修复的图像应该在视觉上是真实的,并且遵循与训练集XH和XC中的图像相同的分布。我们采用LSGAN[28],因为其良好的稳定性和视觉质量。对于去雾网络GD和相应的鉴别器Dc,对抗性损失可以表示为:
伪散射系数监督损失惩罚了βC(在模糊-去雾分支中产生模糊的随机抽样散射系数)和βˆC(从生成的模糊图像ˆh估计的散射系数)之间的差异,
对于来自训练集XH的模糊图像,地面真实散射系数不可用的。因此,我们 交替采用随机抽样的散射系数和相应生成的模糊图像来训练所提出的脱雾网络。 to train the pro posed dehazing network.
伪深度监督损失。根据“空间变化的雾霾厚度为感知场景深度提供了额外的线索”的观察,我们采用从模糊图像H预测的深度图dH作为伪地面真实值。然后,我们训练深度估计网络GE从离散的图像cˆ中估计深度图ˆdH,即ˆdH=GE(cˆ)。然后,我们定义了训练损失,

总的来说,深度估计网络GE仅通过深度损失深度进行优化。其余模块采用循环损失、对抗损失和伪散射系数损失的加权组合,如下:

其中,λcyc、λadv和λscatt是平衡不同项的权重。在我们的实验中,通过经验设置λcyc=1、λadv=0.2和λscatt=1效果良好。
4. Experiments
4.1. Experimental Configuration
数据集。在这项工作中,我们采用驻留的[23]数据集、I-HAZE[1]数据集和Fattal的数据集[10]来训练和评估我们的模型和其他候选模型的性能。居住数据集[23]是一个广泛使用的大规模去模糊基准数据集,它包括以下子集:(i)ITS/OTS,其中包含13990/313950个合成的室内/室外模糊图像与地面真相的训练。(ii)室内/室外的模拟图像,其中包括500张合成的室内/室外模糊图像与地面真相的测试。(iii)RTTS和URHI,它们都包含超过4000张真实的模糊图像,没有地面真实干净的图像。I-HAZE[1]数据集包含35对模糊图像和相应的无雾室内图像。该数据集中的雾霾是由专业的雾霾发生器产生的。Fattal的数据集[10]包括31张真实的模糊图像,它被广泛用于视觉比较。
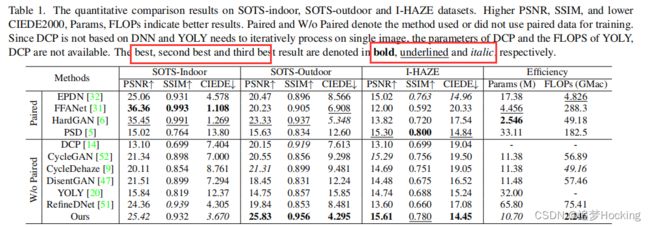
竞争对手和指标。我们将我们的方法与几种最先进的脱雾算法进行了比较。在这些方法中,有一些方法使用配对数据进行训练,包括EPDN[32]、HardGAN[6]、FFANet[31]、DADehaze[39]和PSD[5]。而其他方法则在不使用配对数据的情况下进行训练,包括DCP[14]、CycleGAN[52]、DCP[9]、DisentGAN[47]、YOLY[20]和RefineDNet[51]。采用PSNR、SSIM[44]和CIEDE2000(简称CIEDE)[40]等指标来定量评价其性能。
实施细节。在训练阶段,我们应用了在[16]中提出的补丁大小为30×30的鉴别器。Adam优化器[18]与β1=0.9,β2=0.999,学习率lr=10‘4,和2的批处理大小用于优化网络。所有的训练样本都被调整到256×256,其中一半被水平翻转以进行数据增强。为了估计大气光,我们采用了室外和I-HAZE数据集中的[14]方法。而对于合成的室内场景,最亮的像素被视为大气光。
4.2. Performance Evaluation
在基准测试数据集上的比较。为了定量评估D4的性能和泛化能力,我们首先在基准数据集上进行了实验。具体来说,我们在ITS数据集上训练我们的模型和比较方法。为了公平比较,所有监督方法都使用了ITS数据集中的配对训练数据,但未配对的方法,包括我们的D4,在训练过程中放弃了所有配对信息。考虑到sots-室内的合成方式与ITS相同,我们选择它作为我们的测试集之一。虽然sots-户外和I-HAZE在场景和雾霾类型上有所不同,但这两个测试集的结果可以反映出不同模型的去雾泛化能力。请注意,由于I-HAZE数据集不用于训练,所以我们采用整个I-HAZE数据集进行测试。
定量比较报告在表1中。 1.在sots-室内测试集上,监督方法HardGAN[6]和FFANet[31]展示了其强大的拟合能力,并以绝对优势排名第一和第二。我们的D4是在没有使用成对训练数据的方法中最好的。相比之下,由于sots-户外数据集和I-HAZE数据集的样本与训练数据不一致,因此FFANet和HardGAN失去了它们的主导地位。它部分地揭示了监督脱雾方法的过拟合问题。而我们的D4消除了这些缺陷,并在两个数据集上都优于其他竞争对手。此外,我们还在图3中提供了几个视觉比较。对于第一个和第二个合成室内的案例,FFANet和我们的D4都可以 完全去除雾霾,而其他方法仍然是 可观察到的雾霾的结果。在最后两个案例中,FFANet的 结果仍然很模糊。虽然PSD法产生了 更明亮的结果,但它并不能消除雾霾。第三种情况是fefennet 过度脱雾,在最后一种情况下留下明显的雾霾,而我们的D4 成功地消除了雾霾, 没有留下明显的伪影。这些结果验证了我们的 D4具有更好的泛化能力。总之,尽管我们的研究结果不是与sots-室内的监督方法相比,它在不使用配对数据的方法中是突出的。考虑到所有三个数据集的定量、可视化结果和模型效率,我们的方法更有 吸引力。
比较现实世界中模糊的图像 Comparisons on real-world hazy images 。为了进一步评估真实场景的脱雾性能,我们在Fattal的数据集[10]和URHI数据集上进行了实验。我们在来自OTS和RTTS的未配对的户外干净和模糊的图像上调整了我们的模型。从室内到室外,当扩展到室外场景时,我们使用了一个额外的超参数来调整传输估计器。对于DADehaze[39]、RefineDNet[51]和PSD[5],我们使用了他们发布的模型,该模型是对真实的模糊图像进行预训练的。对于FFANet[31]和HardGAN[6],我们采用成对合成图像训练的模型。在Fattal的数据集和URHI数据集上的可视化结果分别如图4和图5所示。从
图4可以看出,FFANet[31]对
真实模糊图像的影响非常有限 has a very limited effect towards real hazy images。PSD[5]产生的结果存在
严重的颜色失真。而我们的方法成功地消除了图像中的阴霾。在图5中,HardGAN[6]和DADehaze[39]的结果都含有
残留的雾霾,而我们的结果是
尖锐的和清晰 while our result is sharp and clear。这部分实验验证了我们的方法可以很好地推广到真实世界的户外模糊图像上
。This part of experiment validates that our method
generalizes well on real-world outdoor hazy images。
关于深度估算和雾霾产生的结果。我们注意到,如果没有成对的深度监督,我们的方法可以学会从未配对的模糊和干净的图像中预测视觉上合理的深度地图。图6给出了一些深度估计和雾霾生成的案例,从中我们可以看出,虽然我们的深度估计和监督FCRN之间存在差距,但我们的方法在没有地面真实深度信息的情况下是可以接受的。与CycleGAN相比,通过预测的深度,我们的网络可以在室内和室外的图像上产生 更真实和各种模糊的图像。
该方法的有效性的比较。为了测量网络的效率,我们对参数的数量和减雾模型的流量进行了比较。具体来说,只考虑了每个模型的去雾部分。如标签页中所示。1,我们的模型具有最低的FLOPs和更少的参数与一个轻量级的主干[43]。对于这样一个轻量级的模型,我们的方法仍然优于其他最先进的方法,这验证了我们的设计的有效性。
4.3. Ablation Study
在这一部分中,我们验证了我们提出的自我增强和伪监督机制的有效性。对于自增强,我们将模糊-去模糊分支中随机生成的β替换为一个固定的值,并保持其他设置不变(表示为w/oAug)。对于伪监督,由于伪β监督和伪深度监督是紧密相连的,所以我们必须将它们一起添加或删除。在没有这两种伪监督(w/oPS)的情况下,我们去掉了去雾网络GD的估计β函数,并改变深度估计网络GE来直接估计传输图。框架退化为一个香草-喜欢cyclegan的架构。定量和定性结果见表1。分别为图2和图7。从选项卡。我们可以看到,任何对我们的网络的消融都会导致性能的明显下降。图7显示了直观的视觉比较。从第一行的图像中,我们可以推断出,与没有自增强和伪监督机制的网络相比,我们的完整的D4最彻底地消除了雾霾。此外,如第二行的图像所示,我们完整的D4生成了最真实的模糊图像。具体来说,红色框区域靠近观察者,所以该区域的雾霾应该更薄。与其他配置相比,我们的完整模型所产生的图像更清楚地反映在这种特性上。消融研究验证了自增强和伪监督都是有效的。
5. Conclusion
本文提出了一种自增强的非配对图像去模糊框架D4,该框架将传输图的估计分解为密度图和深度图的预测。通过估计深度,该方法能够重新渲染不同密度的模糊图像作为自增强,从而很大程度地提高去模糊性能。大量的实验已经验证了我们的方法比其他最先进的脱雾方法的明显优点。然而,我们的方法也存在一个局限性,即它通常会 高估极亮区域的传输,从而误导深度估计网络来预测过亮区域的低深度值。此外,我们发现 低质量的训练数据会使训练不稳定。但积极的一点是,我们关于进一步 分解物理模型中的变量的想法可以扩展到其他任务中,比如弱光增强。我们希望我们的方法能够创新未来的工作,特别是在低水平视觉任务中的非配对学习。