bert 自己语料预训练pre-train、微调fine-tune;tensorflow/pytorch矩阵点乘、叉乘区别
1、bert 预训练模型加自己语料再训练 pre-train
参考:
https://github.com/zhusleep/pytorch_chinese_lm_pretrain
https://github.com/bojone/bert4keras/tree/master/pretraining
https://github.com/xv44586/toolkit4nlp/tree/master/pretraining
1、clone 下来,里面有数据 https://github.com/zhusleep/pytorch_chinese_lm_pretrain
2、下载transformers和pytorch相关库
3、运行进行再训练
python run_language_model_bert.py --output_dir=output --model_type=bert --model_name_or_path=bert-base-chinese --do_train --train_data_file=train.txt --do_eval --eval_data_file=eval.txt --mlm --per_device_train_batch_size=4

模型保存output文件夹:

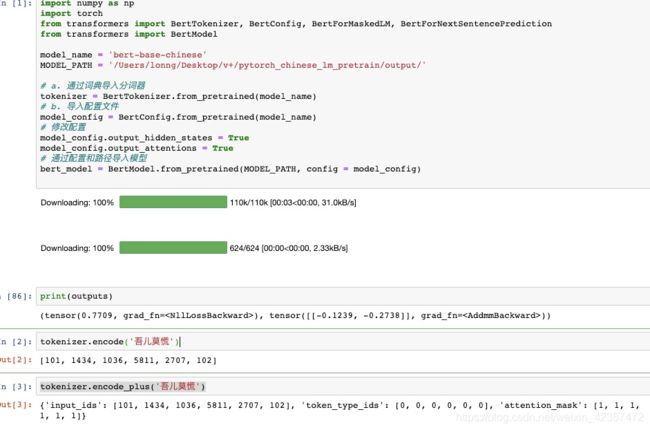
训练模型transformers导入
import numpy as np
import torch
from transformers import BertTokenizer, BertConfig, BertForMaskedLM, BertForNextSentencePrediction
from transformers import BertModel
model_name = 'bert-base-chinese'
MODEL_PATH = '/Users/lonng/Desktop/v+/pytorch_chinese_lm_pretrain/output/'
# a. 通过词典导入分词器
tokenizer = BertTokenizer.from_pretrained(model_name)
# b. 导入配置文件
model_config = BertConfig.from_pretrained(model_name)
# 修改配置
model_config.output_hidden_states = True
model_config.output_attentions = True
# 通过配置和路径导入模型
bert_model = BertModel.from_pretrained(MODEL_PATH, config = model_config)
tokenizer.encode('吾儿莫慌')
tokenizer.encode_plus('吾儿莫慌')
tokenizer.convert_ids_to_tokens(tokenizer.encode('吾儿莫慌'))
2、bert预训练模型再进行 fine-tune
参考:
https://tianchi.aliyun.com/competition/entrance/231776/introduction
数据下载:
百度云:链接:https://pan.baidu.com/s/1lFUtGO3cggooIRUFWFn-Cw 密码:8vc5

数据说明:

from keras.layers import *
from bert4keras.backend import keras, set_gelu
from bert4keras.models import build_transformer_model
from bert4keras.optimizers import Adam
from bert4keras.snippets import sequence_padding, DataGenerator
# from bert4keras.tokenizer import Tokenizer
from bert4keras.tokenizers import Tokenizer
import pandas as pd
import numpy as np
set_gelu('tanh') # 切换gelu版本
maxlen = 32
batch_size = 6
# config_path = 'publish/bert_config.json'
# checkpoint_path = 'publish/bert_model.ckpt'
# dict_path = 'publish/vocab.txt'
config_path = '/Users/lonng/Desktop/v+/xl/chinese_L-12_H-768_A-12/bert_config.json'
checkpoint_path = '/Users/lonng/Desktop/v+/xl/chinese_L-12_H-768_A-12/bert_model.ckpt'
dict_path = '/Users/lonng/Desktop/v+/xl/chinese_L-12_H-768_A-12/vocab.txt'
def load_data(filename):
D = pd.read_csv(filename).values.tolist()
print(D[:5])
return D
# 加载数据集
all_data = load_data('/Users/lonng/Desktop/v+/nCoV-2019-sentence-similarity/data/Dataset/train.csv')
random_order = range(len(all_data))
np.random.shuffle(list(random_order))
train_data = [all_data[j] for i, j in enumerate(random_order) if i % 6 != 1 and i%6!=2]
valid_data = [all_data[j] for i, j in enumerate(random_order) if i % 6 == 1]
test_data = [all_data[j] for i, j in enumerate(random_order) if i % 6 == 2]
# 建立分词器
tokenizer = Tokenizer(dict_path, do_lower_case=True)
class data_generator(DataGenerator):
"""数据生成器
"""
def __iter__(self, random=False):
idxs = list(range(len(self.data)))
# print(idxs)
if random:
np.random.shuffle(idxs)
batch_token_ids, batch_segment_ids, batch_labels = [], [], []
for i in idxs:
# print(self.data[i])
text1, text2, label = self.data[i][2],self.data[i][3],self.data[i][4]
# print(text1, text2, label)
token_ids, segment_ids = tokenizer.encode(text1, text2, maxlen=maxlen)
batch_token_ids.append(token_ids)
batch_segment_ids.append(segment_ids)
batch_labels.append([label])
if len(batch_token_ids) == self.batch_size or i == idxs[-1]:
batch_token_ids = sequence_padding(batch_token_ids)
batch_segment_ids = sequence_padding(batch_segment_ids)
batch_labels = sequence_padding(batch_labels)
yield [batch_token_ids, batch_segment_ids], batch_labels
batch_token_ids, batch_segment_ids, batch_labels = [], [], []
# 加载预训练模型
bert = build_transformer_model(
config_path=config_path,
checkpoint_path=checkpoint_path,
with_pool=True,
return_keras_model=False,
)
# 转换数据集,先取部分数据跑通测试
train_generator = data_generator(train_data[:50], batch_size)
valid_generator = data_generator(valid_data[:20], batch_size)
test_generator = data_generator(test_data[:10], batch_size)
output = Dropout(rate=0.1)(bert.model.output)
output = Dense(units=2,
activation='softmax',
kernel_initializer=bert.initializer)(output)
model = keras.models.Model(bert.model.input, output)
model.summary()
model.compile(
loss='sparse_categorical_crossentropy',
optimizer=Adam(2e-5), # 用足够小的学习率
# optimizer=PiecewiseLinearLearningRate(Adam(5e-5), {10000: 1, 30000: 0.1}),
metrics=['accuracy'],
)
def evaluate(data):
total, right = 0., 0.
for x_true, y_true in data:
y_pred = model.predict(x_true).argmax(axis=1)
y_true = y_true[:, 0]
total += len(y_true)
right += (y_true == y_pred).sum()
return right / total
class Evaluator(keras.callbacks.Callback):
def __init__(self):
self.best_val_acc = 0.
def on_epoch_end(self, epoch, logs=None):
val_acc = evaluate(valid_generator)
if val_acc > self.best_val_acc:
self.best_val_acc = val_acc
model.save_weights('best_model.weights')
test_acc = evaluate(test_generator)
print(u'val_acc: %.5f, best_val_acc: %.5f, test_acc: %.5f\n'
% (val_acc, self.best_val_acc, test_acc))
evaluator = Evaluator()
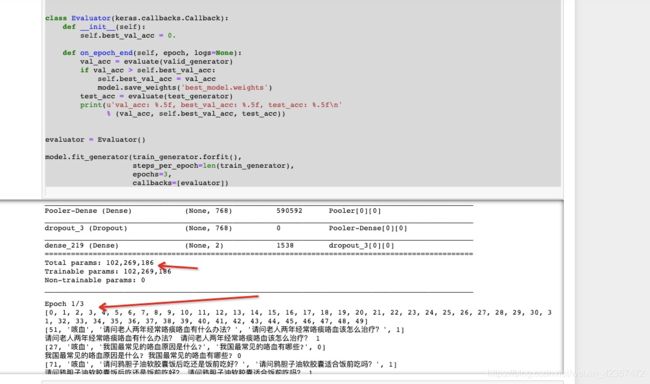
model.fit_generator(train_generator.forfit(),
steps_per_epoch=len(train_generator),
epochs=3,
callbacks=[evaluator])
12层transformer,1亿多参数,机器不好跑着挺难的
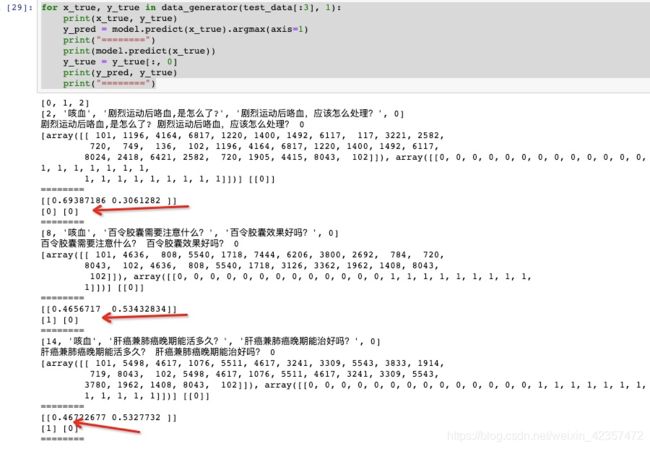
预测验证:
# model.load_weights('best_model.weights')
print(u'final test acc: %05f\n' % (evaluate(test_generator)))
for x_true, y_true in data_generator(test_data[:3], 1):
print(x_true, y_true)
y_pred = model.predict(x_true).argmax(axis=1)
print("========")
print(model.predict(x_true))
y_true = y_true[:, 0]
print(y_pred, y_true)
print("========")
bert4keras 微调fine-tune更新的模型在fit_generator后用save_weights_as_checkpoint进行保存;然后可以用build_transformer_model再加载使用
参考:https://github.com/bojone/oppo-text-match/issues/5
bert = build_transformer_model(xxx, return_keras_model=False)
model = bert.model
model.load_weights(xxxxxx)
bert.save_weights_as_checkpoint(xxxxx)
model.fit_generator(
train_generator.forfit(),
steps_per_epoch=steps_per_epoch,
epochs=epochs,
# callbacks=[evaluator]
)
bert.save_weights_as_checkpoint("***.ckpt")
3、矩阵相关运算
矩阵点乘(内积):对应位置直接相乘
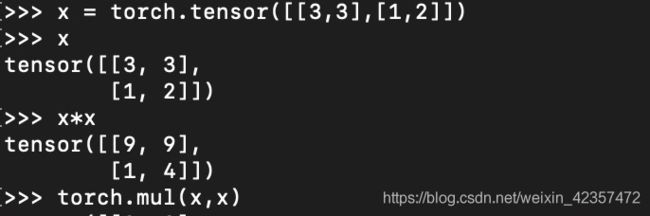

矩阵叉乘(外积,矩阵乘积):行向量的每一个元素乘以列向量中所有元素
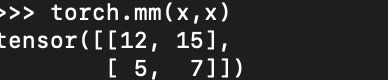
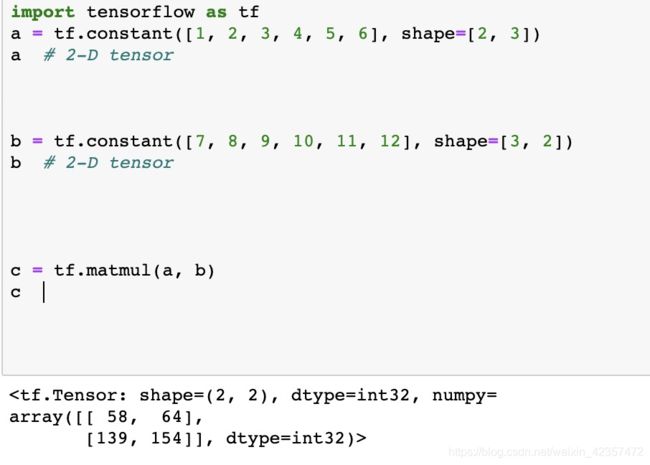
tf.matmul(A,C)=np.dot(A,C)= A@C都属于叉乘,而tf.multiply(A,C)= A*C=A∙C属于点乘
参考:https://blog.csdn.net/haiziccc/article/details/101361583


参考:https://lumingdong.cn/classification-and-difference-of-vector-multiplication-and-matrix-multiplication.html