22-变分推断-variational inference
文章目录
- 1.背景
-
- 1.1 频率派
-
- 1.1.1 回归问题
- 1.1.2 SVM支持向量机(分类问题)
- 1.1.3 EM
- 1.2 贝叶斯派
- 2.公式推导
-
- 2.1平均场理论
- 3.再回首
-
- 3.1 符号规范
- 4. SGVI-随机梯度变分推断
-
- 4.1求梯度 ∇ ϕ L ( ϕ ) \nabla_{\phi}L(\phi) ∇ϕL(ϕ)
- 4.2 梯度采样
- 4.3 重参数化技巧
1.背景
关于变分推断,现在补充一点背景知识,以便让每一个模块都很独立。我们指导机器学习可以分为频率派和贝叶斯派两大派系,关于这两个派系都有各自不同的特点。
1.1 频率派
我们知道从频率派角度来看,最终会演化为一个优化问题。比如我们熟悉的回归问题
1.1.1 回归问题
假设我们有一堆数据 D = { ( x i , y i ) } i = 1 N , x i ∈ R P , y i ∈ R ; D=\{(x_i,y_i)\}_{i=1}^N,x_i\in R^P,y_i\in R; D={(xi,yi)}i=1N,xi∈RP,yi∈R;,我们定义的模型为:
f ( x ) = W T X (1) f(x)=W^TX\tag1 f(x)=WTX(1)
-
定义一条线,我们需要结合数据X把W估计出来。
为了更好的拟合上述数据,我们提出了损失函数Loss Function:
L ( W ) = ∑ i = 1 N ∣ ∣ w T x i − y i ∣ ∣ 2 (2) L(W)=\sum_{i=1}^{N}||w^Tx_i-y_i||^2\tag2 L(W)=i=1∑N∣∣wTxi−yi∣∣2(2)
最后估计出来的w用 w ^ \hat w w^表示:
w ^ = arg min w L ( W ) (3) \hat w =\mathop{\arg\min}\limits_{w}L(W)\tag3 w^=wargminL(W)(3) -
这是一种无约束的优化问题。
求解上述优化问题我们有两种方法: -
解析解:
∂ L ( W ) ∂ w = 0 → W ∗ = ( X T X ) − 1 X T Y (4) \frac{\partial L(W)}{\partial w}=0\rightarrow W^*=(X^TX)^{-1}X^TY\tag4 ∂w∂L(W)=0→W∗=(XTX)−1XTY(4) -
数值解:
当解析解无法求解的时候,我们用梯度下降的方式求解GD,或者用随机梯度下降的方式求解SGD
1.1.2 SVM支持向量机(分类问题)
SVM支持向量机本质上就是一个分类问题。我们定义SVM的模型为:
f ( w ) = s i g n ( w T x + b ) (5) f(w)=sign(w^Tx+b)\tag5 f(w)=sign(wTx+b)(5)
我们定义SVM支持向量机的Loss Function损失函数为:
L ( W ) = 1 2 w T w ; s . t : y i ( w T x i + b ) ≥ 1 , i = 1 , 2 , . . . , N (6) L(W)=\frac{1}{2}w^Tw;s.t:y_i(w^Tx_i+b)\geq1,i=1,2,...,N\tag6 L(W)=21wTw;s.t:yi(wTxi+b)≥1,i=1,2,...,N(6)
- 这是一个约束问题,也是一个凸优化问题。
解法是用QP套件或者用拉格朗日对偶来求解。
1.1.3 EM
EM算法也是一种优化问题的思想,通过不停的迭代,来找到最好的参数:迭代公式如下:
θ ( t + 1 ) = arg max θ ∫ z log P ( X , Z ∣ θ ) ⋅ P ( Z ∣ X , θ ( t ) ) d z (7) \theta^{(t+1)}=\mathop{\arg\max}\limits_{\theta}\int_z \log P(X,Z|\theta)·P(Z|X,\theta^{(t)})dz\tag 7 θ(t+1)=θargmax∫zlogP(X,Z∣θ)⋅P(Z∣X,θ(t))dz(7)
- 故EM算法也是一个迭代优化问题
1.2 贝叶斯派
我们知道从频率派角度来看,最终会演化为一个积分问题。由贝叶斯公式可得:
P ( θ ∣ X ) = P ( X ∣ θ ) ⋅ P ( θ ) P ( X ) (8) P(\theta|X)=\frac{P(X|\theta)·P(\theta)}{P(X)}\tag8 P(θ∣X)=P(X)P(X∣θ)⋅P(θ)(8)
- P ( θ ∣ X ) : 后 验 P(\theta|X):后验 P(θ∣X):后验
- P ( X ∣ θ ) : 似 然 P(X|\theta):似然 P(X∣θ):似然
- P ( θ ) : 先 验 P(\theta):先验 P(θ):先验
- P ( X ) = ∫ θ P ( X ∣ θ ) ⋅ P ( θ ) d θ : 对 参 数 空 间 X 的 积 分 P(X)=\int_{\theta}P(X|\theta)·P(\theta)d\theta:对参数空间X的积分 P(X)=∫θP(X∣θ)⋅P(θ)dθ:对参数空间X的积分
贝叶斯推断指的是在贝叶斯框架中需要把后验的分布 P ( θ ∣ X ) P(\theta|X) P(θ∣X)求出来;贝叶斯决策就可以简单的理解为预测的意思。假设X为已经有的N个样本, X ^ \hat X X^为新的样本,决策的目标是为了求 P ( X ^ ∣ X ) P(\hat X|X) P(X^∣X)的值,为了求得新的 X ^ \hat X X^,那么我们就会引入一个新的参数 θ ; 使 得 \theta;使得 θ;使得
X ^ → θ → X (9) \hat X \rightarrow \theta \rightarrow X\tag 9 X^→θ→X(9)
从而转变为如下公式:
P ( X ^ ∣ X ) = ∫ θ P ( X ^ , θ ∣ X ) d θ = ∫ θ P ( X ^ , θ ∣ X ) ⋅ P ( θ ∣ X ) d θ = E { θ ∣ X } [ P ( X ^ ∣ θ ) ] (10) P(\hat X|X)=\int _{\theta}P(\hat X,\theta|X)d \theta=\int_{\theta}P(\hat X,\theta|X)·P(\theta|X)d \theta=E_{\{\theta|X\}}[P(\hat X|\theta)]\tag {10} P(X^∣X)=∫θP(X^,θ∣X)dθ=∫θP(X^,θ∣X)⋅P(θ∣X)dθ=E{θ∣X}[P(X^∣θ)](10)
所以最终的目标是求后验 P ( θ ∣ X ) P(\theta|X) P(θ∣X),也就是推断inference。
常见的推断分为两种: - 精确推断
- 近似推断
1.确定性近似推断:比如:VI 变分推断
2.随机性近似推断:比如 MCMC,MH,Gibbs
2.公式推导
变分推断VI的目的就是想办法找到一个分布q(z)去逼近我们没有办法计算求得解析解的后验分布p(z|x).我们定义
- X : o b s e r v e d − d a t a 观 测 数 据 ; X:observed-data观测数据; X:observed−data观测数据;
- Z : l a t e n t − v a r i a b l e + p a r a m e t e r 隐 变 量 Z:latent-variable+parameter隐变量 Z:latent−variable+parameter隐变量
- ( X , Z ) : c o m p l e t e − d a t a 完 整 数 据 (X,Z):complete-data 完整数据 (X,Z):complete−data完整数据
现在我们来根据贝叶斯公式来求导后验分布:
由贝叶斯公式可得:
P ( X ) = P ( X , Z ) P ( Z ∣ X ) = P ( X , Z ) / q ( Z ) P ( Z ∣ X ) / q ( Z ) P(X)=\frac{P(X,Z)}{P(Z|X)}=\frac{P(X,Z)/q(Z)}{P(Z|X)/q(Z)} P(X)=P(Z∣X)P(X,Z)=P(Z∣X)/q(Z)P(X,Z)/q(Z)
两边取对数可得:
log P ( X ) = log [ P ( X , Z ) / q ( Z ) ] − log [ P ( Z ∣ X ) / q ( Z ) ] \log P(X)=\log [P(X,Z)/q(Z)] - \log [{P(Z|X)/q(Z)}] logP(X)=log[P(X,Z)/q(Z)]−log[P(Z∣X)/q(Z)]
两边同时对分布q(Z)求期望:
左边:
∫ q ( z ) log P ( X ) d Z = ∫ Z log P ( X ) q ( Z ) d Z = log P ( X ) ∫ Z q ( Z ) d Z = log P ( X ) \int_{q(z)}\log P(X)dZ=\int_Z \log P(X)q(Z)dZ=\log P(X)\int_Z q(Z)dZ=\log P(X) ∫q(z)logP(X)dZ=∫ZlogP(X)q(Z)dZ=logP(X)∫Zq(Z)dZ=logP(X)
右边:
∫ Z q ( Z ) log P ( X , Z ) q ( Z ) d Z ⏟ E L B O + ∫ Z ( − q ( Z ) log P ( Z ∣ X ) q ( Z ) d Z ) ⏟ K L ( q ∣ ∣ p ) (11) \underbrace{\int_Z q(Z)\log \frac{P(X,Z)}{q(Z)} dZ}_{ELBO}+\underbrace{\int_Z(- q(Z)\log \frac{P(Z|X)}{q(Z)}dZ)}_{KL(q||p)}\tag{11} ELBO ∫Zq(Z)logq(Z)P(X,Z)dZ+KL(q∣∣p) ∫Z(−q(Z)logq(Z)P(Z∣X)dZ)(11)
则:
log P ( X ) = ∫ Z q ( Z ) log P ( X , Z ) q ( Z ) d Z ⏟ E L B O = L ( q ) + ∫ Z ( − q ( Z ) log P ( Z ∣ X ) q ( Z ) d Z ) ⏟ K L ( q ∣ ∣ p ) (12) \log P(X)=\underbrace{\int_Z q(Z)\log \frac{P(X,Z)}{q(Z)} dZ}_{ELBO=L(q)}+\underbrace{\int_Z(- q(Z)\log \frac{P(Z|X)}{q(Z)}dZ)}_{KL(q||p)}\tag{12} logP(X)=ELBO=L(q) ∫Zq(Z)logq(Z)P(X,Z)dZ+KL(q∣∣p) ∫Z(−q(Z)logq(Z)P(Z∣X)dZ)(12)
我们定义一个函数L(q)来代替ELBO,用来说明ELBO的输入是关于q的函数,q是我们随意找到的概率密度函数,其中函数L(q)就是我们的所指的变分。由于我们求不出P(Z|X),我们的目的是找到一个q(Z),使得P(Z|X)近似于q(Z),也就是希望KL(q||p)越来越小,这样我们求得的ELBO越接近于 log P ( X ) \log P(X) logP(X),那么我们的目标可以等价于:
q ( Z ) ^ = arg max q ( Z ) L ( q ) → q ( Z ) ^ ≈ p ( Z ∣ X ) (13) \hat{q(Z)}=\mathop{\arg\max}\limits_{q(Z)} L(q)\rightarrow \hat{q(Z)}\approx p(Z|X)\tag{13} q(Z)^=q(Z)argmaxL(q)→q(Z)^≈p(Z∣X)(13)
2.1平均场理论
为了求解q(Z),因为Z是一组隐变量组成的随机变量组合。我们假设q(Z)可以划分为M个组,且每个组之间是相互独立的。这种思想来自于物理学的平均场理论,表达如下:
q ( Z ) = ∏ i = 1 M q i ( Z i ) (14) q(Z)=\prod_{i=1}^{M}q_i(Z_i)\tag{14} q(Z)=i=1∏Mqi(Zi)(14)
平均场理论主要思想如下:
现在我们把q(Z)代入到L(q)中,因为q(Z)有M个划分,我们的想法是先求解第j项,所以我们需要固定其他所有项(固定 { 1 , 2 , . . . , j − 1 , j + 1 , . . . , M } \{1,2,...,j-1,j+1,...,M\} {1,2,...,j−1,j+1,...,M}).这样我们就一个一个求解 q j q_j qj后再求积得到q(Z)即可。
- 将q(Z)代入到L(q)中
L ( q ) = ∫ Z q ( Z ) log P ( X , Z ) d Z ⏟ 1 − ∫ Z q ( Z ) log q ( Z ) d Z ⏟ 2 (15) L(q)=\underbrace{\int_Zq(Z)\log P(X,Z)dZ}_{1}-\underbrace{\int_Zq(Z)\log q(Z)dZ}_{2}\tag {15} L(q)=1 ∫Zq(Z)logP(X,Z)dZ−2 ∫Zq(Z)logq(Z)dZ(15)
1 = ∫ Z ∏ i = 1 M q i ( Z i ) log P ( X , Z ) d Z 1 d Z 2 . . . d Z M 1=\int_Z\prod_{i=1}^{M}q_i(Z_i)\log P(X,Z)dZ_1dZ_2...dZ_M 1=∫Z∏i=1Mqi(Zi)logP(X,Z)dZ1dZ2...dZM
= ∫ Z j q j ( Z j ) d Z j ⋅ [ ∏ i = 1 , 且 i ≠ j M q i ( Z i ) log P ( X , Z ) d Z 1 d Z 2 d Z j − 1 d Z j + 1 . . d Z M ] =\int_{Z_j}q_j(Z_j)dZ_j·[\prod_{i=1,且i≠j}^{M}q_i(Z_i)\log P(X,Z)dZ_1dZ_2dZ_{j-1}dZ_{j+1}..dZ_M] =∫Zjqj(Zj)dZj⋅[∏i=1,且i=jMqi(Zi)logP(X,Z)dZ1dZ2dZj−1dZj+1..dZM]
= ∫ Z j q j ( Z j ) d Z j ⋅ ∫ Z i ; i = 1 , . . . j − 1 , j + 1 , . . . M log P ( X , Z ) ∏ i ≠ j M q i ( Z i ) d Z i =\int_{Z_j}q_j(Z_j)dZ_j·\int_{Z_i;i=1,...j-1,j+1,...M}\log P(X,Z)\prod_{i≠j}^Mq_i(Z_i)dZ_i =∫Zjqj(Zj)dZj⋅∫Zi;i=1,...j−1,j+1,...MlogP(X,Z)∏i=jMqi(Zi)dZi
= ∫ Z j q j ( Z j ) ⋅ E ∏ i ≠ j M q i ( Z i ) [ log P ( X , Z ) ] d Z j =\int_{Z_j}q_j(Z_j)·E_{\prod_{i≠j}^Mq_i(Z_i)}[\log P(X,Z)]dZ_j =∫Zjqj(Zj)⋅E∏i=jMqi(Zi)[logP(X,Z)]dZj
2 = ∫ Z q ( Z ) log q ( Z ) d Z 2=\int_Zq(Z)\log q(Z)dZ 2=∫Zq(Z)logq(Z)dZ
= ∫ Z ∏ i = 1 M q i ( Z i ) log ∏ i = 1 M q i ( Z i ) d Z =\int_Z\prod_{i=1}^{M}q_i(Z_i)\log \prod_{i=1}^{M}q_i(Z_i)dZ =∫Z∏i=1Mqi(Zi)log∏i=1Mqi(Zi)dZ
= ∫ Z ∏ i = 1 M q i ( Z i ) [ ∑ i = 1 M log q i ( Z i ) ] d Z =\int_Z\prod_{i=1}^{M}q_i(Z_i)[\sum_{i=1}^{M}\log q_i(Z_i)]dZ =∫Z∏i=1Mqi(Zi)[∑i=1Mlogqi(Zi)]dZ
将求和展开后拿出第一项目进行分析:
第 一 项 = ∫ Z ∏ i = 1 M q i ( Z i ) log q 1 ( Z 1 ) ] d Z 第一项=\int_Z\prod_{i=1}^{M}q_i(Z_i)\log q_1(Z_1)]dZ 第一项=∫Z∏i=1Mqi(Zi)logq1(Z1)]dZ
= ∫ Z 1 q 1 ( Z 1 ) log q 1 ( Z 1 ) d Z 1 ⋅ ∫ Z 2 . . . Z M ∏ i = 2 M q i ( Z i ) d Z 2 . . . d Z M ⏟ = 1 = ∫ Z 1 q 1 ( Z 1 ) log q 1 ( Z 1 ) d Z 1 =\int_{Z_1}q_1(Z_1)\log q_1(Z_1)dZ_1·\underbrace{\int _{Z_2...Z_M}\prod_{i=2}^{M}q_i(Z_i)dZ_2...dZ_M}_{=1}=\int_{Z_1}q_1(Z_1)\log q_1(Z_1)dZ_1 =∫Z1q1(Z1)logq1(Z1)dZ1⋅=1 ∫Z2...ZMi=2∏Mqi(Zi)dZ2...dZM=∫Z1q1(Z1)logq1(Z1)dZ1
同理可得:
2 = ∫ Z ∏ i = 1 M q i ( Z i ) [ ∑ i = 1 M log q i ( Z i ) ] d Z 2=\int_Z\prod_{i=1}^{M}q_i(Z_i)[\sum_{i=1}^{M}\log q_i(Z_i)]dZ 2=∫Z∏i=1Mqi(Zi)[∑i=1Mlogqi(Zi)]dZ
= ∫ Z 1 q 1 ( Z 1 ) log q 1 ( Z 1 ) d Z 1 + ∫ Z 2 q 2 ( Z 2 ) log q 2 ( Z 2 ) d Z 2 + . . . + ∫ Z M q M ( Z M ) log q M ( Z M ) d Z M =\int_{Z_1}q_1(Z_1)\log q_1(Z_1)dZ_1+\int_{Z_2}q_2(Z_2)\log q_2(Z_2)dZ_2+...+\int_{Z_M}q_M(Z_M)\log q_M(Z_M)dZ_M =∫Z1q1(Z1)logq1(Z1)dZ1+∫Z2q2(Z2)logq2(Z2)dZ2+...+∫ZMqM(ZM)logqM(ZM)dZM
= ∑ i = 1 M ∫ Z i q i ( Z i ) log q i ( Z i ) d Z i =\sum_{i=1}^{M}\int_{Z_i} q_i(Z_i)\log q_i(Z_i)dZ_i =∑i=1M∫Ziqi(Zi)logqi(Zi)dZi
由于我们现在只关心第j项目,其他项目已经固定,所以上式可变为如下:
2 = ∫ Z j q j ( Z j ) log q j ( Z j ) d Z j + C 常 数 2=\int_{Z_j} q_j(Z_j)\log q_j(Z_j)dZ_j+C_{常数} 2=∫Zjqj(Zj)logqj(Zj)dZj+C常数
综上所述:
我们发现1和2中的式子不一致,不方便化简,所以我们希望1中的式子也跟2中的log保持一致,这样就方便后续计算,所以我们定义如下:
因为:
1 = ∫ Z j q j ( Z j ) ⋅ E ∏ i ≠ j M q i ( Z i ) [ log P ( X , Z ) ] d Z j 1=\int_{Z_j}q_j(Z_j)·E_{\prod_{i≠j}^Mq_i(Z_i)}[\log P(X,Z)]dZ_j 1=∫Zjqj(Zj)⋅E∏i=jMqi(Zi)[logP(X,Z)]dZj
为方便后续计算,转换如下:
1 = ∫ Z j q j ( Z j ) ⋅ log P ^ ( X , Z j ) d Z j 1=\int_{Z_j}q_j(Z_j)·\log \hat{P}(X,Z_j)dZ_j 1=∫Zjqj(Zj)⋅logP^(X,Zj)dZj
又因为:
2 = ∫ Z j q j ( Z j ) log q j ( Z j ) d Z j + C 常 数 2=\int_{Z_j} q_j(Z_j)\log q_j(Z_j)dZ_j+C_{常数} 2=∫Zjqj(Zj)logqj(Zj)dZj+C常数
L ( q ) = 1 − 2 = ∫ Z j q j ( Z j ) ⋅ log P ^ ( X , Z j ) q j ( Z j ) d Z j − C = − K L ( q j ( Z j ) ∣ ∣ P ^ ( X , Z j ) ) − C 常 数 L(q)=1-2=\int_{Z_j}q_j(Z_j)·\log \frac{\hat{P}(X,Z_j)}{q_j(Z_j)}dZ_j-C=-KL(q_j(Z_j)||\hat{P}(X,Z_j))-C_{常数} L(q)=1−2=∫Zjqj(Zj)⋅logqj(Zj)P^(X,Zj)dZj−C=−KL(qj(Zj)∣∣P^(X,Zj))−C常数
又由于我们要求最值问题,所以尝试C可以忽略,只关心KL项即可。
L ( q ) = 1 − 2 = − K L ( q j ( Z j ) ∣ ∣ P ^ ( X , Z j ) ) ≤ 0 L(q)=1-2=-KL(q_j(Z_j)||\hat{P}(X,Z_j))\leq0 L(q)=1−2=−KL(qj(Zj)∣∣P^(X,Zj))≤0
- 当 q j ( Z j ) = P ^ ( X , Z j ) ⋅ C 常 数 时 , 上 式 不 等 式 取 等 号 . q_j(Z_j)=\hat{P}(X,Z_j)·C_{常数}时,上式不等式取等号. qj(Zj)=P^(X,Zj)⋅C常数时,上式不等式取等号.
3.再回首
我们已经讲解了基于平均场理论的变分推断,即:(VI-mean field),也称经典推断classical VI;
- 假设将q(Z)分为M份,且M份之间是相互独立的,这个假设比较强:
A s s u m p t i o n : q ( Z ) = ∏ i = 1 M q i ( Z i ) (16) Assumption:q(Z)=\prod_{i=1}^{M}q_i(Z_i)\tag{16} Assumption:q(Z)=i=1∏Mqi(Zi)(16) - 结论:
log q j ( Z j ) = E i ≠ j , q i ( Z i ) [ log P ( X , Z ∣ θ ) ] + C O N S T 常 数 (17) \log q_j(Z_j)=E_{i≠j,q_i(Z_i)}[\log P(X,Z|\theta)]+CONST_{常数}\tag{17} logqj(Zj)=Ei=j,qi(Zi)[logP(X,Z∣θ)]+CONST常数(17) - = ∫ q 1 ∫ q 2 . . . ∫ q j − 1 ∫ q j + 1 . . . ∫ q M q 1 q 2 . . . q j − 1 q j + 1 [ log P ( x ( i ) , z ] d q 1 . . . d q j − 1 d q j + 1 . . . d q M + C O N S T 常 数 \int_{q_1}\int_{q_2}...\int_{q_{j-1}}\int_{q_{j+1}}...\int_{q_{M}}q_1q_2...q_{j-1}q_{j+1}[\log P(x^{(i)},z]d_{q_1}...d_{q_{j-1}}d_{q_{j+1}}...d_{q_M}+CONST_{常数} ∫q1∫q2...∫qj−1∫qj+1...∫qMq1q2...qj−1qj+1[logP(x(i),z]dq1...dqj−1dqj+1...dqM+CONST常数
- 可以看出上述公式展开后就式一个迭代式。将上述公式迭代可得如下:
- q 1 ^ ( z 1 ) = ∫ q 2 . . . ∫ q M q 2 . . . q M [ log P ( x ( i ) , z ] d q 2 . . . . . . d q M \hat{q_1}(z_1)=\int_{q_2}...\int_{q_M}q_2...q_M[\log P(x^{(i)},z]d_{q_2}......d_{q_M} q1^(z1)=∫q2...∫qMq2...qM[logP(x(i),z]dq2......dqM
- q 2 ^ ( z 2 ) = ∫ q ^ 1 ∫ q 3 . . . ∫ q M q ^ 1 q 3 . . . q M [ log P ( x ( i ) , z ] d q ^ 1 d q 3 . . . d q M \hat{q_2}(z_2)=\int_{\hat{q}_1}\int_{q_3}...\int_{q_M}\hat{q}_1q_3...q_M[\log P(x^{(i)},z]d_{\hat{q}_1}d_{q_3}...d_{q_M} q2^(z2)=∫q^1∫q3...∫qMq^1q3...qM[logP(x(i),z]dq^1dq3...dqM
- …
- q M ^ ( z M ) = ∫ q ^ 1 . . . ∫ q ^ M − 1 q ^ 1 . . . q ^ M − 1 [ log P ( x ( i ) , z ] d q ^ 1 d q ^ 2 . . . d q ^ M − 1 \hat{q_M}(z_M)=\int_{\hat{q}_1}...\int_{\hat{q}_{M-1}}\hat{q}_1...\hat{q}_{M-1}[\log P(x^{(i)},z]d_{\hat{q}_1}d_{\hat{q}_2}...d_{\hat{q}_{M-1}} qM^(zM)=∫q^1...∫q^M−1q^1...q^M−1[logP(x(i),z]dq^1dq^2...dq^M−1
这种迭代方式就跟坐标上升法算法一样的思想。以上是一个经典的基于平均场理论的变分推断方法,但这种方法也有缺点
- 这种平均分割q(z)为M份的假设太强了。对于某些简单模型是可以实现的,但对于一些复杂的模型来说是不能成立的。比如深度玻尔兹曼机和深度神经网络就没法切割成相互独立的M份。
- 即使假设M份是成立的,但是对于复杂模型来说, log q j ( Z j ) = E i ≠ j , q i ( Z i ) [ log P ( x ( i ) , z ] \log q_j(Z_j)=E_{i≠j,q_i(Z_i)}[\log P(x^{(i)},z] logqj(Zj)=Ei=j,qi(Zi)[logP(x(i),z]积分也是非常难求出来的。
变分推断说到底还是推断,推断在概率图模型中指的往往是求后验是什么,EM和变分推断在推导过程中用的是同一套理论(ELBO)。只是处理问题有些不同而已。因为变分推断关心的是后验,所以我们应该弱化参数 θ \theta θ.
log P θ ( X ) = E L B O ⏟ L ( q ) + K L ( q ∣ ∣ p ) ⏟ ≥ 0 ≥ L ( q ) (18) \log P_{\theta}(X)=\underbrace{ELBO}_{L(q)}+\underbrace{KL(q||p)}_{\geq0}\geq L(q)\tag{18} logPθ(X)=L(q) ELBO+≥0 KL(q∣∣p)≥L(q)(18)
- 为了求最大的 log P θ ( X ) \log P_{\theta}(X) logPθ(X),我们其实就是为了求ELBO中最大的q(z),KL(q||p)中最小的q;
q ^ = arg min q K L ( q ∣ ∣ p ) = arg max q L ( q ) (19) \hat{q}=\mathop{\arg\min}\limits_{q}KL(q||p)=\mathop{\arg\max}\limits_{q}L(q)\tag{19} q^=qargminKL(q∣∣p)=qargmaxL(q)(19) - 这样我们就将一个求后验的变分问题转换成一个优化问题.
3.1 符号规范
为了以后更加方便描述数学问题,我们定义用小写表示随机变量:
- x:observed - variable 观测随机变量
- z:latent - variable 隐含随机变量
- x i : 表 示 维 度 x_i:表示维度 xi:表示维度
- x ( i ) : 表 示 第 i 个 x 样 本 ; X = { x ( i ) } i = 1 N x^{(i)}:表示第i个x样本;X=\{x^{(i)}\}_{i=1}^{N} x(i):表示第i个x样本;X={x(i)}i=1N
- z ( i ) : 表 示 第 i 个 z 样 本 ; Z = { z ( i ) } i = 1 N z^{(i)}:表示第i个z样本;Z=\{z^{(i)}\}_{i=1}^{N} z(i):表示第i个z样本;Z={z(i)}i=1N
我们假设每个样本 x ( i ) x^{(i)} x(i)之间是满足独立同分布的。所以可得如下:
log P θ ( X ) = log ∏ i = 1 N P θ ( x ( i ) ) = ∑ i = 1 N log P θ ( x ( i ) ) (20) \log P_{\theta}(X)=\log \prod_{i=1}^{N}P_{\theta}(x^{(i)})=\sum_{i=1}^{N}\log P_{\theta}(x^{(i)})\tag{20} logPθ(X)=logi=1∏NPθ(x(i))=i=1∑NlogPθ(x(i))(20) - 我们的目标是求得最大的 log P θ ( X ) \log P_{\theta}(X) logPθ(X),所以我们的想法是只需要求得每一个 log P θ ( x ( i ) ) \log P_{\theta}(x^{(i)}) logPθ(x(i))最大值即可。所以我们的研究对象变成了 log P θ ( x ( i ) ) \log P_{\theta}(x^{(i)}) logPθ(x(i))
E L B O = E q ( z ) [ log P θ ( x ( i ) z ) q ( z ) ] = E q ( z ) [ log P θ ( x ( i ) , z ) ] + H [ q ( z ) ] (21) ELBO=E_{q(z)}[\log \frac{P_{\theta}(x^{(i)}z)}{q(z)}]=E_{q(z)}[\log P_{\theta}(x^{(i)},z)]+H[q(z)]\tag{21} ELBO=Eq(z)[logq(z)Pθ(x(i)z)]=Eq(z)[logPθ(x(i),z)]+H[q(z)](21)
K L ( q ∣ ∣ p ) = ∫ q ( z ) ⋅ log q ( z ) P θ ( z ∣ x ( i ) ) d z (22) KL(q||p)=\int q(z)·\log \frac{q(z)}{P_{\theta}(z|x^{(i)})}dz \tag{22} KL(q∣∣p)=∫q(z)⋅logPθ(z∣x(i))q(z)dz(22) - 注:这里的 z i z_i zi不是指一个数据维度的集合,而指的是一个类似的最大团的概念。也就是多个维度结合在一起。
4. SGVI-随机梯度变分推断
4.1求梯度 ∇ ϕ L ( ϕ ) \nabla_{\phi}L(\phi) ∇ϕL(ϕ)
Stochastic Gradient Variational Inference简称SGVI算法,即随机梯度变分推断算法。对于Z和X组成的模型,我们常常按如下方式区分生成模型和推断模型。
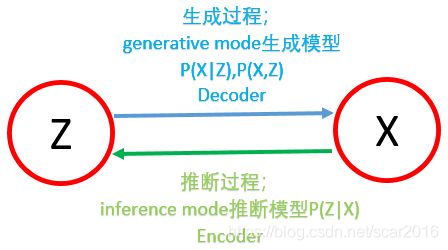
我们上一节分析了基于平均场理论的变分推断,通过平均假设得到了变分推断的结论。可以看到它是一种坐标上升法的思想去处理问题,那么,既然坐标上升法能够处理变分推断问题,那么我们也可以用梯度上升法来解决这个问题,这样我们就自然而然地想到了随机梯度变分推断SGVI。我们知道对于随机梯度算法来说,它的更新是需要方向和步长的,满足如下公式:
θ ( t + 1 ) = θ ( t ) + λ ( t ) ∇ L ( q ) (23) \theta^{(t+1)}=\theta^{(t)}+\lambda^{(t)}\nabla L(q) \tag{23} θ(t+1)=θ(t)+λ(t)∇L(q)(23)
- 注:这样我们只需要求得 ∇ L ( q ) \nabla L(q) ∇L(q)即可;
- 由于q是关于z和x的概率分布,即q(z|x)在这里我们通篇是忽略x 的,因为x是观测变量,为了简化起见,我们用q(z)表示q(z|x),我们令q(z)是一个指数族分布,那么为了求q(z)这个分布,本质上是为了求关于分布q(z)所需的参数 ϕ \phi ϕ,所以我们令所求的分布为 q ϕ ( z ) q_{\phi}(z) qϕ(z),所以我们的目标函数可以化简为如下:
E L B O = E q ϕ ( z ) [ log P θ ( x ( i ) z ) q ϕ ( z ) ] = E q ϕ ( z ) [ log P θ ( x ( i ) , z ) − log q ϕ ( z ) ] = L ( ϕ ) (24) ELBO=E_{q_{\phi}(z)}[\log \frac{P_{\theta}(x^{(i)}z)}{q_{\phi}(z)}]=E_{q_{\phi}(z)}[\log P_{\theta}(x^{(i)},z)-\log q_{\phi}(z)]=L(\phi)\tag{24} ELBO=Eqϕ(z)[logqϕ(z)Pθ(x(i)z)]=Eqϕ(z)[logPθ(x(i),z)−logqϕ(z)]=L(ϕ)(24)
L ( ϕ ) = E q ϕ ( z ) [ log P θ ( x ( i ) , z ) − log q ϕ ( z ) ] (25) L(\phi)=E_{q_{\phi}(z)}[\log P_{\theta}(x^{(i)},z)-\log q_{\phi}(z)]\tag{25} L(ϕ)=Eqϕ(z)[logPθ(x(i),z)−logqϕ(z)](25)
整理上式可得目标函数为:
ϕ ^ = arg max ϕ L ( ϕ ) = arg max ϕ E q ϕ ( z ) [ log P θ ( x ( i ) , z ) − log q ϕ ( z ) ] (26) \hat{\phi}=\mathop{\arg\max}\limits_{\phi}L(\phi)=\mathop{\arg\max}\limits_{\phi}E_{q_{\phi}(z)}[\log P_{\theta}(x^{(i)},z)-\log q_{\phi}(z)]\tag{26} ϕ^=ϕargmaxL(ϕ)=ϕargmaxEqϕ(z)[logPθ(x(i),z)−logqϕ(z)](26)
对 上 式 关 于 ϕ 求 导 , 我 们 令 ∂ L ( ϕ ) ∂ ϕ = ∇ ϕ L ( ϕ ) 对上式关于\phi求导,我们令\frac{\partial L(\phi)}{\partial \phi}=\nabla_{\phi}L(\phi) 对上式关于ϕ求导,我们令∂ϕ∂L(ϕ)=∇ϕL(ϕ):
∇ ϕ L ( ϕ ) = ∇ ϕ E q ϕ ( z ) [ log P θ ( x ( i ) , z ) − log q ϕ ( z ) ] (27) \nabla_{\phi}L(\phi)=\nabla_{\phi}E_{q_{\phi}(z)}[\log P_{\theta}(x^{(i)},z)-\log q_{\phi}(z)]\tag{27} ∇ϕL(ϕ)=∇ϕEqϕ(z)[logPθ(x(i),z)−logqϕ(z)](27)
具体步骤如下:
∇ ϕ L ( ϕ ) = ∇ ϕ E q ϕ ( z ) [ log P θ ( x ( i ) , z ) − log q ϕ ( z ) ] \nabla_{\phi}L(\phi)=\nabla_{\phi}E_{q_{\phi}(z)}[\log P_{\theta}(x^{(i)},z)-\log q_{\phi}(z)] ∇ϕL(ϕ)=∇ϕEqϕ(z)[logPθ(x(i),z)−logqϕ(z)]
= ∇ ϕ { ∫ z q ϕ ( z ) ⋅ [ log P θ ( x ( i ) , z ) − log q ϕ ( z ) ] d z } =\nabla_{\phi}\{\int_z q_{\phi}(z)·[\log P_{\theta}(x^{(i)},z)-\log q_{\phi}(z)]dz\} =∇ϕ{∫zqϕ(z)⋅[logPθ(x(i),z)−logqϕ(z)]dz}
- 注:d(AB)=d(A)B+Ad(B),积分号与求导符号互换位置。
= ∫ z [ ∇ ϕ { q ϕ ( z ) } ⏟ d ( A ) ⋅ { [ log P θ ( x ( i ) , z ) − log q ϕ ( z ) ] } ⏟ B ] d z =\int_z[ \underbrace{\nabla_{\phi}\{ q_{\phi}(z)\}}_{d(A)}·\underbrace{\{[\log P_{\theta}(x^{(i)},z)-\log q_{\phi}(z)]\}}_{B}]dz =∫z[d(A) ∇ϕ{qϕ(z)}⋅B {[logPθ(x(i),z)−logqϕ(z)]}]dz
+ ∫ z [ { q ϕ ( z ) } ⏟ A ⋅ ∇ ϕ { [ log P θ ( x ( i ) , z ) − log q ϕ ( z ) ] } ⏟ d ( B ) ] d z +\int_z[ \underbrace{\{ q_{\phi}(z)\}}_{A}·\underbrace{\nabla_{\phi}\{[\log P_{\theta}(x^{(i)},z)-\log q_{\phi}(z)]\}}_{d(B)}]dz +∫z[A {qϕ(z)}⋅d(B) ∇ϕ{[logPθ(x(i),z)−logqϕ(z)]}]dz
我们对于上式分开解析:
1 = ∫ z [ ∇ ϕ { q ϕ ( z ) } ⋅ { [ log P θ ( x ( i ) , z ) − log q ϕ ( z ) ] } ] d z 1=\int_z[\nabla_{\phi}\{ q_{\phi}(z)\}·\{[\log P_{\theta}(x^{(i)},z)-\log q_{\phi}(z)]\}]dz 1=∫z[∇ϕ{qϕ(z)}⋅{[logPθ(x(i),z)−logqϕ(z)]}]dz
2 = ∫ z [ { q ϕ ( z ) } ⋅ ∇ ϕ { [ log P θ ( x ( i ) , z ) − log q ϕ ( z ) ] } ] d z 2=\int_z[ \{ q_{\phi}(z)\}·\nabla_{\phi}\{[\log P_{\theta}(x^{(i)},z)-\log q_{\phi}(z)]\}]dz 2=∫z[{qϕ(z)}⋅∇ϕ{[logPθ(x(i),z)−logqϕ(z)]}]dz
我 们 知 道 : log P θ ( x ( i ) z ) 与 ϕ 无 关 , 故 导 数 为 0. 我们知道:\log P_{\theta}(x^{(i)}z)与\phi无关,故导数为0. 我们知道:logPθ(x(i)z)与ϕ无关,故导数为0.
2 = ∫ z [ { q ϕ ( z ) } ⋅ ∇ ϕ { [ log P θ ( x ( i ) , z ) ⏟ 与 ϕ 无 关 − log q ϕ ( z ) ] } ] d z 2=\int_z[ \{ q_{\phi}(z)\}·\nabla_{\phi}\{\underbrace{[\log P_{\theta}(x^{(i)},z)}_{与\phi无关}-\log q_{\phi}(z)]\}]dz 2=∫z[{qϕ(z)}⋅∇ϕ{与ϕ无关 [logPθ(x(i),z)−logqϕ(z)]}]dz
2 = ∫ z [ { q ϕ ( z ) } ⋅ ∇ ϕ { − log q ϕ ( z ) } ] d z 2=\int_z[ \{ q_{\phi}(z)\}·\nabla_{\phi}\{-\log q_{\phi}(z)\}]dz 2=∫z[{qϕ(z)}⋅∇ϕ{−logqϕ(z)}]dz
= ∫ z [ { q ϕ ( z ) } ⋅ ∇ ϕ { − log q ϕ ( z ) } ] d z =\int_z[ \{ q_{\phi}(z)\}·\nabla_{\phi}\{-\log q_{\phi}(z)\}]dz =∫z[{qϕ(z)}⋅∇ϕ{−logqϕ(z)}]dz
= − ∫ z [ { q ϕ ( z ) } ⋅ 1 q ϕ ( z ) ∇ ϕ { q ϕ ( z ) } ] d z =-\int_z[ \{ q_{\phi}(z)\}·\frac{1}{q_{\phi}(z)}\nabla_{\phi}\{q_{\phi}(z)\}]dz =−∫z[{qϕ(z)}⋅qϕ(z)1∇ϕ{qϕ(z)}]dz
= − ∫ z [ ∇ ϕ { q ϕ ( z ) } ] d z =-\int_z[\nabla_{\phi}\{q_{\phi}(z)\}]dz =−∫z[∇ϕ{qϕ(z)}]dz
= − ∇ ϕ ∫ z [ { q ϕ ( z ) } ] d z =-\nabla_{\phi}\int_z[\{q_{\phi}(z)\}]dz =−∇ϕ∫z[{qϕ(z)}]dz
= − ∇ ϕ ∫ z [ { q ϕ ( z ) } ] ⏟ = 1 d z =-\nabla_{\phi}\underbrace{\int_z[\{q_{\phi}(z)\}]}_{=1}dz =−∇ϕ=1 ∫z[{qϕ(z)}]dz
= − ∇ ϕ 1 = 0 =-\nabla_{\phi}1=0 =−∇ϕ1=0
结论:
∇ ϕ L ( ϕ ) = ∫ z [ ∇ ϕ { q ϕ ( z ) } ⋅ { [ log P θ ( x ( i ) , z ) − log q ϕ ( z ) ] } ] d z (28) \nabla_{\phi}L(\phi)=\int_z[\nabla_{\phi}\{ q_{\phi}(z)\}·\{[\log P_{\theta}(x^{(i)},z)-\log q_{\phi}(z)]\}]dz\tag{28} ∇ϕL(ϕ)=∫z[∇ϕ{qϕ(z)}⋅{[logPθ(x(i),z)−logqϕ(z)]}]dz(28)
-
因为 ∇ ϕ { q ϕ ( z ) } = q ϕ ( z ) ∇ ϕ log { q ϕ ( z ) } , 故 上 式 可 变 如 下 : \nabla_{\phi}\{ q_{\phi}(z)\}= q_{\phi}(z)\nabla_{\phi}\log \{ q_{\phi}(z)\},故上式可变如下: ∇ϕ{qϕ(z)}=qϕ(z)∇ϕlog{qϕ(z)},故上式可变如下:
∇ ϕ L ( ϕ ) = ∫ z [ q ϕ ( z ) ∇ ϕ log { q ϕ ( z ) } ⋅ { [ log P θ ( x ( i ) , z ) − log q ϕ ( z ) ] } ] d z (29) \nabla_{\phi}L(\phi)=\int_z[q_{\phi}(z)\nabla_{\phi}\log \{ q_{\phi}(z)\}·\{[\log P_{\theta}(x^{(i)},z)-\log q_{\phi}(z)]\}]dz\tag{29} ∇ϕL(ϕ)=∫z[qϕ(z)∇ϕlog{qϕ(z)}⋅{[logPθ(x(i),z)−logqϕ(z)]}]dz(29) -
转换成关于分布 q ( ϕ ) q(\phi) q(ϕ)的期望形式:
结论:
∇ ϕ L ( ϕ ) = E { q ϕ ( z ) } [ ∇ ϕ log { q ϕ ( z ) } ⋅ { [ log P θ ( x ( i ) , z ) − log q ϕ ( z ) ] } ] (30) \nabla_{\phi}L(\phi)=E_{\{q_{\phi}(z)\}}[\nabla_{\phi}\log \{ q_{\phi}(z)\}·\{[\log P_{\theta}(x^{(i)},z)-\log q_{\phi}(z)]\}]\tag{30} ∇ϕL(ϕ)=E{qϕ(z)}[∇ϕlog{qϕ(z)}⋅{[logPθ(x(i),z)−logqϕ(z)]}](30)
- 所以我们的梯度可以用一个期望表示,这样我们用蒙特卡罗的方式近似求得期望,最后得到梯度。
将上述得到的梯度代入如下公式即可得到梯度法求解的迭代公式:
θ ( t + 1 ) = θ ( t ) + λ ( t ) ∇ L ( q ) (31) \theta^{(t+1)}=\theta^{(t)}+\lambda^{(t)}\nabla L(q) \tag{31} θ(t+1)=θ(t)+λ(t)∇L(q)(31)
4.2 梯度采样
我们已经把梯度转换成期望的公式,现在就是如何求这个期望,们采用的是蒙特卡罗采样法,具体步骤如下:
- 假 设 z l 来 自 于 分 布 即 : z l ∼ q ϕ ( z ) ; l = 1 , 2 , . . , L , 那 么 可 得 如 下 : 假设z^l 来自于分布即:z^l \sim q_{\phi}(z);l=1,2,..,L,那么可得如下: 假设zl来自于分布即:zl∼qϕ(z);l=1,2,..,L,那么可得如下:
- ∇ ϕ L ( ϕ ) ≈ 1 L ∑ l = 1 L [ ∇ ϕ log { q ϕ ( z ( l ) ) } ⋅ { log P θ ( x ( i ) , z ( l ) ) − log q ϕ ( z ( l ) ) } ] (32) \nabla_{\phi}L(\phi)≈\frac{1}{L}\sum_{l=1}^{L}[\nabla_{\phi}\log \{ q_{\phi}(z^{(l)})\}·\{\log P_{\theta}(x^{(i)},z^{(l)})-\log q_{\phi}(z^{(l)})\}]\tag{32} ∇ϕL(ϕ)≈L1l=1∑L[∇ϕlog{qϕ(z(l))}⋅{logPθ(x(i),z(l))−logqϕ(z(l))}](32)
对于上式最大的问题是,当我们在 q ϕ ( z ) q_{\phi}(z) qϕ(z)中采样的时候,会有概率采到 q ϕ ( z ) q_{\phi}(z) qϕ(z)在某一个时刻非常的小,所以就会导致 ∣ log { q ϕ ( z ( l ) ) } ∣ |\log \{ q_{\phi}(z^{(l)})\}| ∣log{qϕ(z(l))}∣会非常的大,从而出现方差较大的情况(high variance),当方差越大的时候,就会出现需要更多的样本L去平衡方差,那么现实过程中就出现无法采样的现象发生。即:
lim q ϕ ( z ) − > 0 log { q ϕ ( z ( l ) ) } = ∞ (33) \lim_{q_{\phi}(z)->0}\log \{ q_{\phi}(z^{(l)})\}=∞\tag{33} qϕ(z)−>0limlog{qϕ(z(l))}=∞(33)
为了解决因方差较大时,上述无法采样的现象,我们提出新的方法重参数化技巧[Reparameterization Trick]
4.3 重参数化技巧
重参数化技巧的核心思想是对 q ϕ ( z ) q_{\phi}(z) qϕ(z)进行简化,假设我们得到一个确定的解 P ( ϵ ) P(\epsilon) P(ϵ),那么我们就很容易解决上述期望不好求的问题。
∇ ϕ L ( ϕ ) = ∇ ϕ E { q ϕ ( z ) } [ log { q ϕ ( z ) } ⋅ { [ log P θ ( x ( i ) , z ) − log q ϕ ( z ) ] } ] (34) \nabla_{\phi}L(\phi)=\nabla_{\phi}E_{\{q_{\phi}(z)\}}[\log \{ q_{\phi}(z)\}·\{[\log P_{\theta}(x^{(i)},z)-\log q_{\phi}(z)]\}]\tag{34} ∇ϕL(ϕ)=∇ϕE{qϕ(z)}[log{qϕ(z)}⋅{[logPθ(x(i),z)−logqϕ(z)]}](34)
注:因为z来自于 q ϕ ( z ) q_{\phi}(z) qϕ(z),如果我们能够想办法将z中的随机变量分离出来,将 z 的随机性用另外一个变量 ϵ \epsilon ϵ表示出来,我们定义一个函数,表示变量 ϵ \epsilon ϵ与随机变量z之间的关系:
z = g ϕ ( ϵ , x ( i ) ) → ϵ ∼ P ( ϵ ) (36) z=g_{\phi}(\epsilon,x^{(i)})\quad\rightarrow\quad \epsilon \sim P(\epsilon)\tag{36} z=gϕ(ϵ,x(i))→ϵ∼P(ϵ)(36)
- 这样做的好处是:不再是连续的关于 ϕ \phi ϕ的采样了,可以有效的降低方差,并且,z是关于 ϵ \epsilon ϵ的函数,我们将随机性转移到了 ϵ \epsilon ϵ中,那么上述问题可以简化为如下:
z ∼ q ϕ ( z ∣ x ( i ) ) → ϵ ∼ p ( ϵ ) (37) z \sim q_{\phi}(z|x^{(i)})\quad\rightarrow \quad \epsilon\sim p(\epsilon)\tag{37} z∼qϕ(z∣x(i))→ϵ∼p(ϵ)(37)
我们引入如下等式:
∣ q ϕ ( z ∣ x ( i ) ) d z ∣ = ∣ p ( ϵ ) d ϵ ∣ (38) |q_{\phi}(z|x^{(i)})dz|=|p(\epsilon)d\epsilon|\tag{38} ∣qϕ(z∣x(i))dz∣=∣p(ϵ)dϵ∣(38)
由于 z = g ϕ ( ϵ , x ( i ) ) z=g_{\phi}(\epsilon,x^{(i)}) z=gϕ(ϵ,x(i))是一个函数关系,即映射关系,那么我们可以知道发生z的概率跟发生 ϵ \epsilon ϵ的概率一致;
我们令PA为发生z的概率,故 P A = q ϕ ( z ∣ x ( i ) ) d z PA=q_{\phi}(z|x^{(i)})dz PA=qϕ(z∣x(i))dz;同理令PB为发生 ϵ \epsilon ϵ的概率 P B = p ( ϵ ) d ϵ PB=p(\epsilon)d\epsilon PB=p(ϵ)dϵ,故可得:
P A = ∣ q ϕ ( z ∣ x ( i ) ) d z ∣ = P B = ∣ p ( ϵ ) d ϵ ∣ (39) PA=|q_{\phi}(z|x^{(i)})dz|=PB=|p(\epsilon)d\epsilon|\tag{39} PA=∣qϕ(z∣x(i))dz∣=PB=∣p(ϵ)dϵ∣(39)
现在我们根据上述公式更新梯度:
∇ ϕ L ( ϕ ) = ∇ ϕ ∫ z [ { q ϕ ( z ) } ⋅ { [ log P θ ( x ( i ) , z ) − log q ϕ ( z ) ] } ] d z (40) \nabla_{\phi}L(\phi)=\nabla_{\phi}\int_z[\{ q_{\phi}(z)\}·\{[\log P_{\theta}(x^{(i)},z)-\log q_{\phi}(z)]\}]dz\tag{40} ∇ϕL(ϕ)=∇ϕ∫z[{qϕ(z)}⋅{[logPθ(x(i),z)−logqϕ(z)]}]dz(40)
= ∇ ϕ ∫ z [ { [ log P θ ( x ( i ) , z ) − log q ϕ ( z ) ] } ] { q ϕ ( z ) } d z (41) =\nabla_{\phi}\int_z[\{[\log P_{\theta}(x^{(i)},z)-\log q_{\phi}(z)]\}]\{ q_{\phi}(z)\}dz\tag{41} =∇ϕ∫z[{[logPθ(x(i),z)−logqϕ(z)]}]{qϕ(z)}dz(41)
= ∇ ϕ ∫ z [ { [ log P θ ( x ( i ) , z ) − log q ϕ ( z ) ] } ] p ( ϵ ) d ϵ (42) =\nabla_{\phi}\int_z[\{[\log P_{\theta}(x^{(i)},z)-\log q_{\phi}(z)]\}]p(\epsilon)d\epsilon\tag{42} =∇ϕ∫z[{[logPθ(x(i),z)−logqϕ(z)]}]p(ϵ)dϵ(42)
= ∇ ϕ ∫ ϵ [ log P θ ( x ( i ) , z ) − log q ϕ ( z ) ] p ( ϵ ) d ϵ (43) =\nabla_{\phi}\int_{\epsilon}[\log P_{\theta}(x^{(i)},z)-\log q_{\phi}(z)]p(\epsilon)d\epsilon\tag{43} =∇ϕ∫ϵ[logPθ(x(i),z)−logqϕ(z)]p(ϵ)dϵ(43)
= ∇ ϕ E { P ϵ } [ log P θ ( x ( i ) , z ) − log q ϕ ( z ) ] (44) =\nabla_{\phi}E_{\{P_{\epsilon}\}}[\log P_{\theta}(x^{(i)},z)-\log q_{\phi}(z)]\tag{44} =∇ϕE{Pϵ}[logPθ(x(i),z)−logqϕ(z)](44)
= E { P ϵ } ∇ ϕ [ log P θ ( x ( i ) , z ) − log q ϕ ( z ) ] (45) =E_{\{P_{\epsilon}\}}\nabla_{\phi}[\log P_{\theta}(x^{(i)},z)-\log q_{\phi}(z)]\tag{45} =E{Pϵ}∇ϕ[logPθ(x(i),z)−logqϕ(z)](45)
= E { P ϵ } ∇ z [ log P θ ( x ( i ) , z ) − log q ϕ ( z ) ] ∇ ϕ z (46) =E_{\{P_{\epsilon}\}}\nabla_{z}[\log P_{\theta}(x^{(i)},z)-\log q_{\phi}(z)]\nabla_{\phi}z\tag{46} =E{Pϵ}∇z[logPθ(x(i),z)−logqϕ(z)]∇ϕz(46)
-
我们之前定义了 q ϕ ( z ) = q ϕ ( z ∣ x ( i ) ) ; z = g ϕ ( ϵ , x ( i ) ) q_{\phi}(z)=q_{\phi}(z|x^{(i)});z=g_{\phi}(\epsilon,x^{(i)}) qϕ(z)=qϕ(z∣x(i));z=gϕ(ϵ,x(i))
∇ ϕ L ( ϕ ) = E { P ϵ } { ∇ z [ log P θ ( x ( i ) , z ) − log q ϕ ( z ∣ x ( i ) ) ] } ⋅ ∇ ϕ g ϕ ( ϵ , x ( i ) ) (47) \nabla_{\phi}L(\phi)=E_{\{P_{\epsilon}\}}\{\nabla_{z}[\log P_{\theta}(x^{(i)},z)-\log q_{\phi}(z|x^{(i)})]\}·\nabla_{\phi}g_{\phi}(\epsilon,x^{(i)})\tag{47} ∇ϕL(ϕ)=E{Pϵ}{∇z[logPθ(x(i),z)−logqϕ(z∣x(i))]}⋅∇ϕgϕ(ϵ,x(i))(47)
那么我们的关于期望的采样就简化了很多,因为 p ( ϵ ) p(\epsilon) p(ϵ)与 ϕ \phi ϕ无关,我们可以先求 [ log P θ ( x ( i ) , z ) − log q ϕ ( z ∣ x ( i ) ) ] [\log P_{\theta}(x^{(i)},z)-\log q_{\phi}(z|x^{(i)})] [logPθ(x(i),z)−logqϕ(z∣x(i))]关于z的导数,然后再求 g ϕ ( ϵ , x ( i ) ) g_{\phi}(\epsilon,x^{(i)}) gϕ(ϵ,x(i))关于 ϕ \phi ϕ的导数,这三者之间是相互分离开的,最后我们对结果进行采样,可得:
ϵ ( l ) ∼ p ( ϵ ) ; l = 1 , 2 , . . , L (48) \epsilon^{(l)}\sim p(\epsilon);l=1,2,..,L\tag{48} ϵ(l)∼p(ϵ);l=1,2,..,L(48)
经过上述公式转换后的期望,因函数简化后,我们可以用蒙特卡洛的方法进行采样了。
∇ ϕ L ( ϕ ) ≈ 1 L ∑ i = 1 L [ { ∇ z [ log P θ ( x ( i ) , z ) − log q ϕ ( z ∣ x ( i ) ) ] } ⋅ ∇ ϕ g ϕ ( ϵ , x ( i ) ) ] (49) \nabla_{\phi}L(\phi)≈\frac{1}{L}\sum_{i=1}^{L}[\{\nabla_{z}[\log P_{\theta}(x^{(i)},z)-\log q_{\phi}(z|x^{(i)})]\}·\nabla_{\phi}g_{\phi}(\epsilon,x^{(i)})]\tag{49} ∇ϕL(ϕ)≈L1i=1∑L[{∇z[logPθ(x(i),z)−logqϕ(z∣x(i))]}⋅∇ϕgϕ(ϵ,x(i))](49) -
其中 z = g ϕ ( ϵ ( i ) , x ( i ) ) , 最 后 将 上 式 的 值 代 入 迭 代 公 式 即 可 : z=g_{\phi}(\epsilon^{(i)},x^{(i)}),最后将上式的值代入迭代公式即可: z=gϕ(ϵ(i),x(i)),最后将上式的值代入迭代公式即可:
θ ( t + 1 ) = θ ( t ) + λ ( t ) ∇ ϕ L ( ϕ ) (50) \theta^{(t+1)}=\theta^{(t)}+\lambda^{(t)}\nabla_{\phi}L(\phi)\tag{50} θ(t+1)=θ(t)+λ(t)∇ϕL(ϕ)(50)
证毕。