优化器(SGD、SGDM、Adagrad、RMSProp、Adam等)
1.1 SGD
SGD全称Stochastic Gradient Descent,随机梯度下降,1847年提出。每次选择一个mini-batch,而不是全部样本,使用梯度下降来更新模型参数。它解决了随机小批量样本的问题,但仍然有自适应学习率、容易卡在梯度较小点等问题。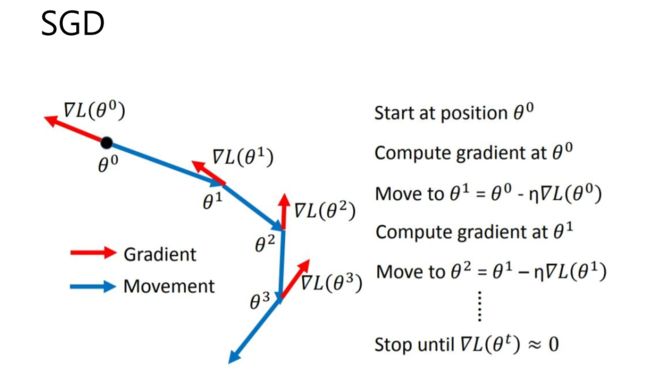
1.2 SGDM
SGDM即为SGD with momentum,它加入了动量机制,1986年提出。![]()
![]()
如上所示,当前动量V由上一次迭代动量,和当前梯度决定。第一次迭代时V0=0,由此可得到前三次迭代的动量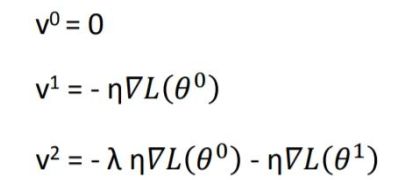
由此可见t迭代的动量,其实是前t-1迭代的梯度的加权和。λ为衰减权重,越远的迭代权重越小。从而我们可以发现,SGDM相比于SGD的差别就在于,参数更新时,不仅仅减去了当前迭代的梯度,还减去了前t-1迭代的梯度的加权和。由此可见,SGDM中,当前迭代的梯度,和之前迭代的累积梯度,都会影响参数更新。
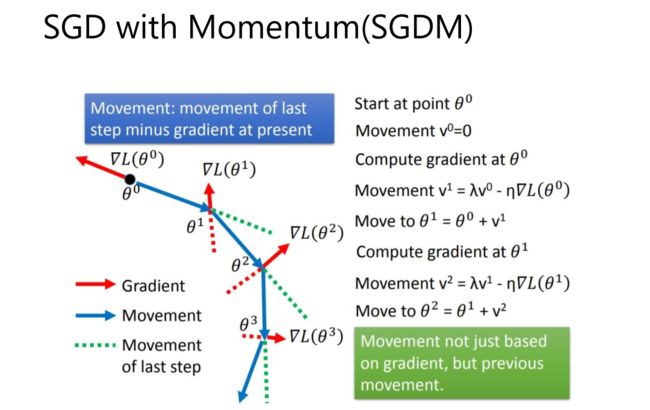
SGDM相比SGD优势明显,加入动量后,参数更新就可以保持之前更新趋势,而不会卡在当前梯度较小的点了。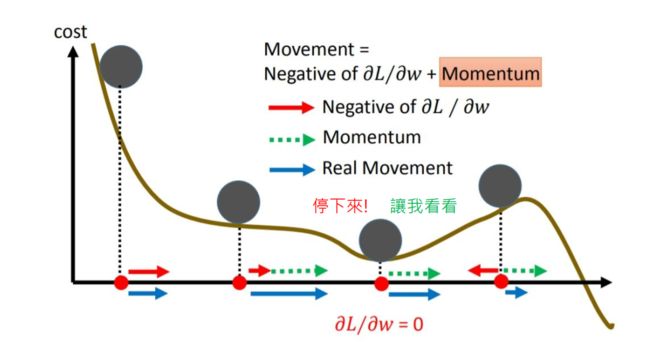
美中不足的是,SGDM没有考虑对学习率进行自适应更新,故学习率的选择很关键。
1.3 Adagrad
它利用迭代次数和累积梯度,对学习率进行自动衰减,2011年提出。从而使得刚开始迭代时,学习率较大,可以快速收敛。而后来则逐渐减小,精调参数,使得模型可以稳定找到最优点。其参数迭代公式如下
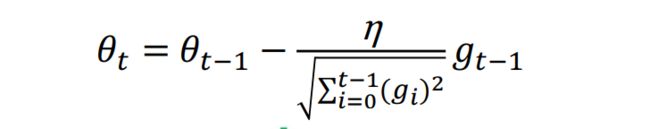
与SGD的区别在于,学习率除以 前t-1 迭代的梯度的平方和。故称为自适应梯度下降。
Adagrad有个致命问题,就是没有考虑迭代衰减。极端情况,如果刚开始的梯度特别大,而后面的比较小,则学习率基本不会变化了,也就谈不上自适应学习率了。这个问题在RMSProp中得到了修正
1.4 RMSProp
它与Adagrad基本类似,只是加入了迭代衰减,2013年提出,如下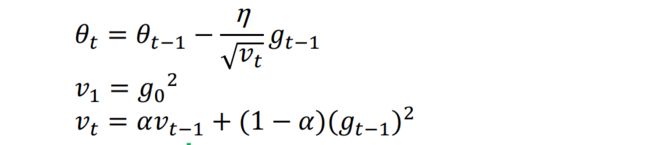
观察上式和Adagrad的区别,在于RMSProp中,梯度累积不是简单的前t-1次迭代梯度的平方和了,而是加入了衰减因子α。简单理解就是学习率除以前t-1次迭代的梯度的加权平方和。加入衰减时make sense的,因为与当前迭代越近的梯度,对当前影响应该越大。另外也完美解决了某些迭代梯度过大,导致自适应梯度无法变化的问题。
1.5 Adam
Adam是SGDM和RMSProp的结合,它基本解决了之前提到的梯度下降的一系列问题,比如随机小样本、自适应学习率、容易卡在梯度较小点等问题,2015年提出。如下
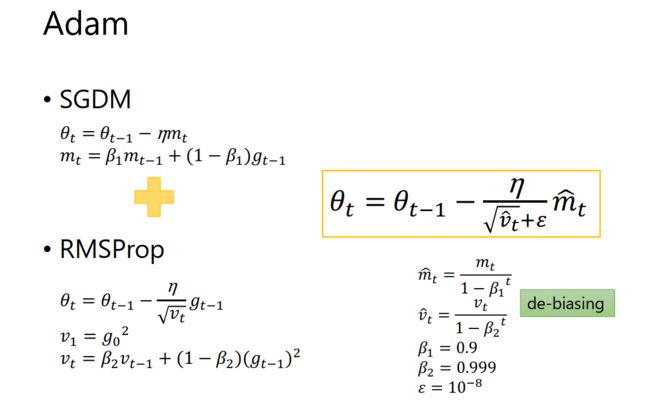
由上可见,mt即为动量,根号vt即为自适应学习率。加入了两个衰减系数β1和β2。刚开始所需动量比较大,后面模型基本稳定后,逐步减小对动量的依赖。自适应学习率同样也会随迭代次数逐渐衰减。则是防止除数为0,仅仅是数学计算考虑。
2 怎么选择优化器
五大优化器其实分为两类,SGD、SGDM,和Adagrad、RMSProp、Adam。使用比较多的是SGDM和Adam。
如上所示,SGDM在CV里面应用较多,而Adam则基本横扫NLP、RL、GAN、语音合成等领域。所以我们基本按照所属领域来使用就好了。比如NLP领域,Transformer、BERT这些经典模型均使用的Adam,及其变种AdamW。
3 优化器对比
CV任务实验
有人研究过几大优化器在一些经典任务上的表现。如下是在图像分类任务上,不同优化器的迭代次数和ACC间关系。
SGD > Adam?? Which One Is The Best Optimizer: Dogs-VS-Cats Toy Experiment(https://shaoanlu.wordpress.com/2017/05/29/sgd-all-which-one-is-the-best-optimizer-dogs-vs-cats-toy-experiment/)
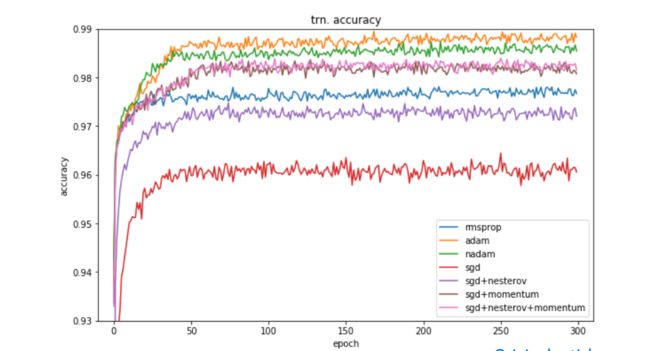
训练集上
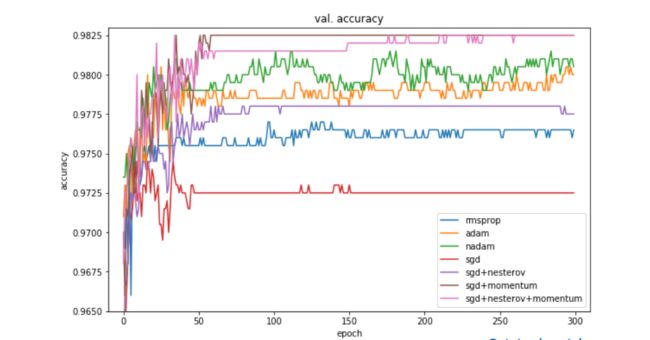
验证集上
可见:
优化器对ACC影响也挺大的,比如上图Adam比SGD高了接近3个点。故选择一个合适的优化器也很重要。
Adam收敛速度很快,SGDM相对要慢一些,但最终都能收敛到比较好的点
训练集上Adam表现最好,但验证集上SGDM最好。可见SGDM在训练集和验证集一致性上,比Adam好。
NLP任务实验
LSTM模型上,可见Adam比SGDM收敛快很多。最终结果SGDM稍好,但也差不多。
SGDM和Adam对比
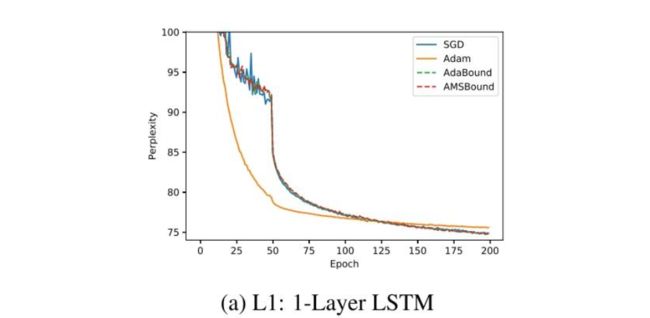
SGDM训练慢,但收敛性更好,训练也更稳定,训练和验证间的gap也较小。而Adam则正好相反。
4 SGDM和Adam优化
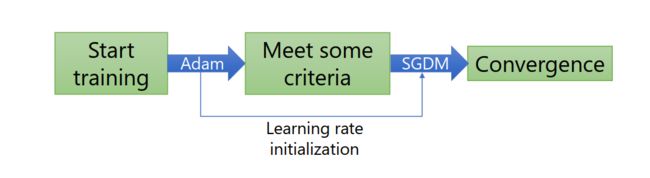
4.1 SWATS
结合了SGDM和Adam,刚开始使用Adam,使得模型快速收敛。然后使用SGDM,使模型收敛稳定。如下
4.2 AMSGrad
对Adam的改进在于,学习率衰减Vt变为了取max,如下。
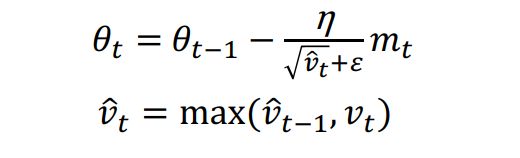
优点为
学习率可以随迭代次数单调递减,不会在某些迭代突然变大
去掉了没什么信息含量的梯度,也就是较小的梯度
4.3 AdaBound
AMSGrad处理了较大的学习率,而AdaBound则将学习率限制在一定范围内
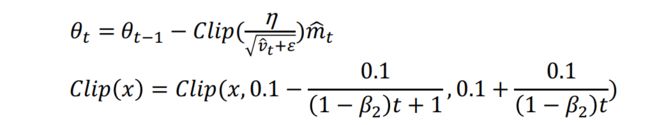
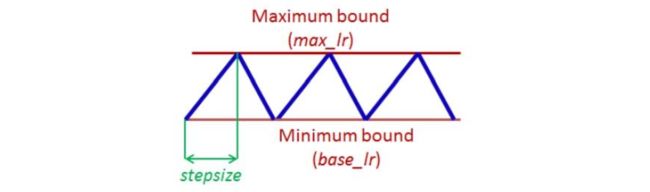
4.4 Cyclical LR
针对于SGDM收敛过慢,且没有使用自适应学习率的问题,Cyclical LR提出了让学习率在一定范围内变大和变小的方法,如下
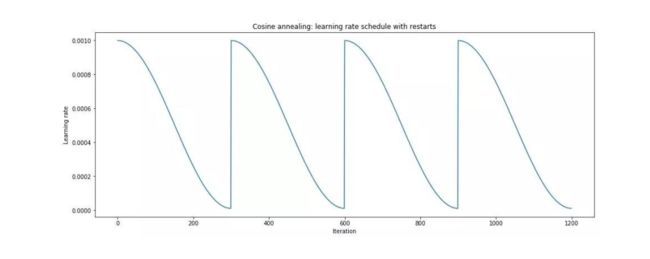
4.5 SGDR
和Cyclical LR类似,但增大时为阶跃增大,如下
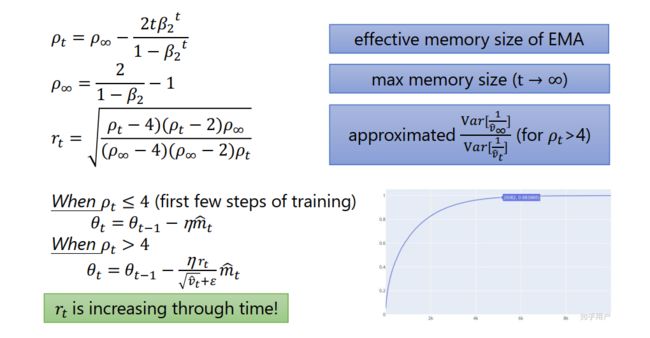
4.6 RAdam
2020最新文章,
4.7 Lookahead
参数迭代n步后,再退回来一步。以新的起点重新开始迭代,这样可以增加收敛稳定性,防止跑飞。

4.8 Nesterov accelerated gradient (NAG)
往future看几步,保证模型训练稳定

4.9 Nadam
Adam的future版本

4.10 加入L2正则

4.11 加入weight decay
和加入正则类似,但不同的是它加入的是weight decay。Huging Face的预训练模型广泛应用了AdamW作为优化器,需要重点掌握。
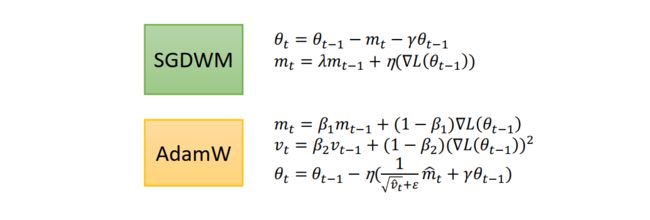
4.12 优化总结
总结下来,SGDM和Adam两大阵营的各种优化后的optimizer如下
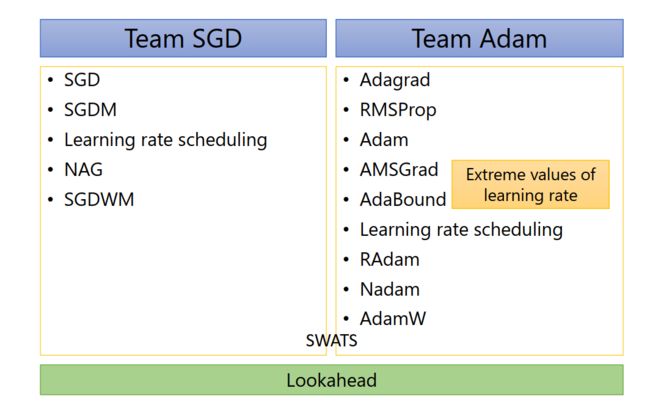
optimizer优化主要有四种方法:
让模型探索更多的可能,包括dropout、加入Gradient noise、样本shuffle等
让模型站在巨人肩膀上,包括warn-up、curriculum learning、fine-tune等
归一化 normalization,包括batch-norm和layer-norm等
正则化,惩罚模型的复杂度
原文链接:https://blog.csdn.net/u013510838/article/details/108268525