膨胀卷积(Dilated convolutions)(又叫空洞卷积、扩张卷积)
一、背景
论文:Multi-Scale Context Aggregation by Dilated Convolutions
大部分图像分割的框架都是经历一系列的卷积和下采样的模块之后,再不断与之前卷积结果跨层融合经历一系列卷积和上采样模块的过程,只不过大家融合的方式不尽相同,FCN是逐像素直接相加,U-NET是通道维度拼接,DFAnet是矩阵相乘,但大体框架是一样的,主要还是因为之前的下采样降低了图片的分辨率,而我们只能采用这种方法既能及时补充细节信息又能恢复原始图片分辨率。论文在介绍中,大胆提出这些问题的根源在于池化、下采样层的存在,而它们的存在并不是必要的。
创新点:
(1)丢掉池化、下采样模块;
(2)构建一种新的卷积网络结构 — 膨胀卷积;
(3)提出了一种既可以结合上下文信息,又不降低分辨率的模型。
二、原理

kernel_size =3, dilated_ratio=2, stride=1, padding=0
相当于实际普通个卷积核:K=3+(3-1)(2-1)=5; 卷积后得出的尺寸为w=(w-K+2P)/S+1=3

1.连续使用几个膨胀系数不同的空洞卷积,有如下的结果:

(a)F1由F0通过1-dilated(相当于普通卷积)扩张卷积产生的;F1中每个元素具有3x3的感受野。
(b)F2由F1通过2-dilated扩张卷积产生的;F2中每个元素具有7x7的感受野。
(c)F3由F2通过4-dilated扩张卷积产生的;F3中每个元素具有15x15的感受野。
上图可以看出,卷积核参数量没有发生改变,只是被0填充大小发生变化,随着空洞系数的增大,感受野 ( receptive field ) 也逐渐变大,而他们训练的参数是完全相同的。文章当中给出了上面三种情况感受野的计算公式:
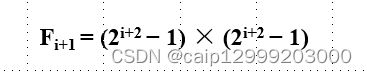
2.连续使用几个膨胀系数相同的空洞卷积,有如下的结果:
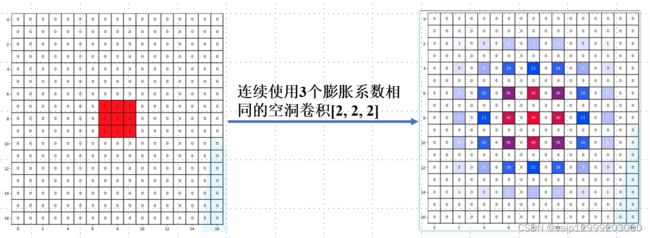
相比于前面使用连续不同膨胀系数的空洞卷积而言:
- 两种方法在仅是膨胀系数不同情况下,它们的参数数量是一样的。
- 对于[2, 2, 2]的空洞卷积来说,Layer4(三层卷积后得到的那层)的感受野也是13×13,但在这个视野下有很多像素值是没有利用到的。
对此,我们更加倾向于使用[1, 2, 4]这样的膨胀系数 —— 感受野下使用的区域是连续的。
3.全部使用普通的卷积:
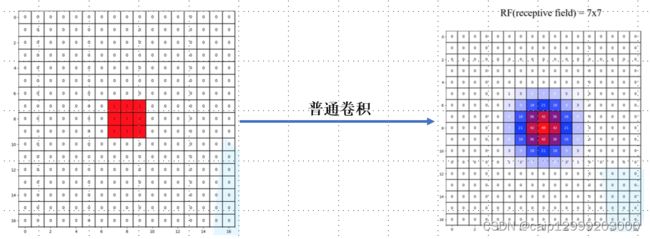
可以发现:
- 在相同层对应的感受野:普通卷积(7x7)要小于膨胀卷积(13x13)。
- 这说明使用膨胀卷积可以大幅度增加感受野。
三、膨胀卷积使用的方法
1.论文第一个建议:连续使用多个膨胀卷积时应该如何设计它的膨胀系数如下:
针对于几个膨胀系数相同的空洞卷积和几个膨胀系数不同的空洞卷积连接卷积产生的不同结果,论文给出了相应的解决方法: Hybird Dilated Convolution (HDC)。
假设我们连续堆叠N个空洞卷积(它的kernel_size都是等于KxK 的),每个空洞卷积的膨胀系数分别对应[ r1 , r2 , …, rn ] 。那HDC的目标是通过一系列空洞卷积之后可以完全覆盖底层特征层的方形区域,并且该方形区域中间是没有任何孔洞或缺失的边缘(withou any holes or missing edges)。作者定义了一个叫做"maximum distance between two nonzero values,两个非零元素之间最大的距离"的公式:

针对第一个建议给出的两个例子:(其中最大距离为Mn = rn)
• 当 kernel_size (K)=3 时,对于膨胀系数 r=[1, 2, 5] 来说, M 2 =max[M 3 − 2r 2 , 2r i −M i+1 , r 2 ] =max[5-4, 4-5, 2]=2 ≤ (K= ) 3, 所以 满足 设计要求。• 当 kernel_size (K)=3 时,对于膨胀系数 r=[1, 2, 9] 来说,M 2 =max[M 3 − 2r 2 , 2r i −M i+1 , r 2 ] =max[9-4, 4-9, 2]=5 ≥ (K=)3, 所以 不满足 设计要求,所以这组参数时不合适的。
设计对应的效果图对比:
明显可以看出r=[1, 2, 9], 中间丢失了一部分信息,而r=[1,2,5]没有丢失。
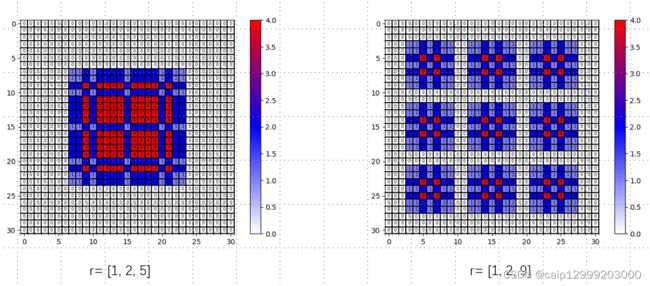
提问:为什么例子中的 r都是从1开始的?
我们希望在高层特征图的每个像素可以利用到底层特征图的感受野内的所有像素,那么M1应该等于1。 M1=1意味着非零元素之间是相邻的(没有间隙的),而M1的计算公式如下:
M1 = max[M2−2r1 , 2r1 − M2,r1] = max[正, 负, ri]
既然我们希望M1=1而且M1且取3个中最大的数,那么M1应该≥ r1 ,即1 ≥ r1,所以r1等于1。
2.论文第二个建议:将膨胀系数设置为锯齿形状。


3.论文第三个建议:公约数不能大于1的。

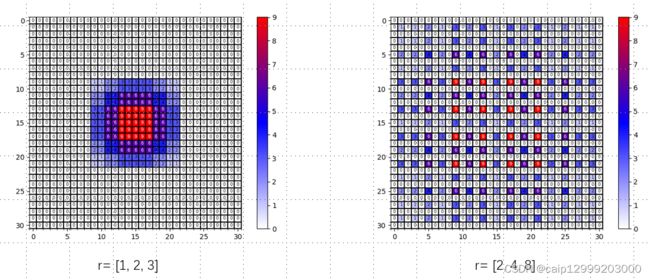
设计对应的效果图对比:
明显可以看出r=[2, 4, 8],有公约数2而且中间丢失了一部分信息,而r=[1,2,5]公约数为1且没有丢失任何信息。
四、 膨胀卷积用途
在语义分割中,通常会使用分类网络作为backbone。通过backbone之后会对特征图进行一系列的下采样,之后再进行一系列的上采样还原原图的大小。
在分类网络中,一般都会对图片的高度和宽度下采样32倍,由于后续需要通过上采样还原到原来的尺寸。如果下采样的倍率很大时,即便使用上采样还原回原来的尺寸,那么信息丢失是比较严重的。以VGG16为例,该网络通过MaxPooling层对特征图进行下采样:
• 通过 MaxPooling 会降低特征图的 shape• MaxPooling 会丢失特征图的一些细节信息(毕竟是用最大值代替局部值,丢失信息是肯定的)• 丢失的信息和目标是无法通过上采样进行还原的
对于神经网络构建而言:
如果我们简单粗暴地将MaxPooling去掉的话,会引入新的问题:
• 特征图对应原图的感受野会变小• 为后面的卷积层带来影响(感受野不变,卷积层就无法获取深层的信息)
此时,空洞卷积就可以解决上面的问题,因为空洞卷积:
• 增大特征图的感受野•通过修改padding的大小,可以 保证输入输出特征图的 shape 不变
五、膨胀卷积各种设计效果比较
可以发现,使用HDC设计的膨胀卷积对于全局信息的捕获更齐全。

六、代码:
上面对应每个r=[x,x,x]生成图像的代码如下,只需改动dilated_rates = [1,2,3]中的值即可测试其他数据。这里参考了(空洞卷积(膨胀卷积)的相关知识以及使用建议(HDC原则)_Le0v1n的博客-CSDN博客_空洞卷积的作用)
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.colors import LinearSegmentedColormap
def dilated_conv_one_pixel(center: (int, int),
feature_map: np.ndarray,
k: int = 3,
r: int = 1,
v: int = 1):
"""
膨胀卷积核中心在指定坐标center处时,统计哪些像素被利用到,
并在利用到的像素位置处加上增量v
Args:
center: 膨胀卷积核中心的坐标
feature_map: 记录每个像素使用次数的特征图
k: 膨胀卷积核的kernel大小
r: 膨胀卷积的dilation rate
v: 使用次数增量
"""
assert divmod(3, 2)[1] == 1
# left-top: (x, y)
left_top = (center[0] - ((k - 1) // 2) * r, center[1] - ((k - 1) // 2) * r)
for i in range(k):
for j in range(k):
feature_map[left_top[1] + i * r][left_top[0] + j * r] += v
def dilated_conv_all_map(dilated_map: np.ndarray,
k: int = 3,
r: int = 1):
"""
根据输出特征矩阵中哪些像素被使用以及使用次数,
配合膨胀卷积k和r计算输入特征矩阵哪些像素被使用以及使用次数
Args:
dilated_map: 记录输出特征矩阵中每个像素被使用次数的特征图
k: 膨胀卷积核的kernel大小
r: 膨胀卷积的dilation rate
"""
new_map = np.zeros_like(dilated_map)
for i in range(dilated_map.shape[0]):
for j in range(dilated_map.shape[1]):
if dilated_map[i][j] > 0:
dilated_conv_one_pixel((j, i), new_map, k=k, r=r, v=dilated_map[i][j])
return new_map
def plot_map(matrix: np.ndarray):
plt.figure()
c_list = ['white', 'blue', 'red']
new_cmp = LinearSegmentedColormap.from_list('chaos', c_list)
plt.imshow(matrix, cmap=new_cmp)
ax = plt.gca()
ax.set_xticks(np.arange(-0.5, matrix.shape[1], 1), minor=True)
ax.set_yticks(np.arange(-0.5, matrix.shape[0], 1), minor=True)
# 显示color bar
plt.colorbar()
# 在图中标注数量
thresh = 5
for x in range(matrix.shape[1]):
for y in range(matrix.shape[0]):
# 注意这里的matrix[y, x]不是matrix[x, y]
info = int(matrix[y, x])
ax.text(x, y, info,
verticalalignment='center',
horizontalalignment='center',
font={'size':6},
color="white" if info > thresh else "black")
ax.grid(which='minor', color='black', linestyle='-', linewidth=1.5)
plt.show()
plt.close()
def main():
# bottom to top
dilated_rates = [1,2,3]
# init feature map
size = 31
m = np.zeros(shape=(size, size), dtype=np.int32)
center = size // 2
m[center][center] = 1
# print(m)
# plot_map(m)
for index, dilated_r in enumerate(dilated_rates[::-1]):
new_map = dilated_conv_all_map(m, r=dilated_r)
m = new_map
print(m)
plot_map(m)
if __name__ == '__main__':
main()
七、总结
1.在不做pooling损失信息和相同的计算条件下的情况下,加大了感受野,让每个卷积输出都包含较大范围的信息。空洞卷积经常用在实时图像分割中。当网络层需要较大的感受野,但计算资源有限而无法提高卷积核数量或大小时,可以考虑空洞卷积。
2.使用HDC设计的膨胀卷积通过卷积后能够保留更多原始的信息。
3.最后,如果你觉得上面的内容能给您带来一点作用的话,可以给我点个,谢谢
八、参考
1.膨胀卷积(Dilated convolution)详解_哔哩哔哩_bilibili
2.空洞卷积(膨胀卷积)的相关知识以及使用建议(HDC原则)_Le0v1n的博客-CSDN博客_空洞卷积的作用
3.一文详解什么是空洞卷积?_Mr.Jk.Zhang的博客-CSDN博客_空洞卷积
4.图像分割—— 膨胀卷积的应用_清水河小小龙虾的博客-CSDN博客