实体消歧综述整理
阅读文献:[1] 段宗涛,李菲,陈柘.实体消歧综述[J].控制与决策,2021,36(05):1025-1039.DOI:10.13195/j.kzyjc.2020.0388.
文章目录
-
- 分类
-
- 按实体任务领域划分
- 按有无目标知识库划分
- 按链接知识库类型划分
- 词义消岐
- 命名实体识别
- 方法
-
- 基于无监督聚类的消岐系统
-
- (1) 基于词袋模型的聚类方法
- (2) 基于语义特征的聚类方法
- (3) 基于社会化网络的聚类方法
- (4) 基于百科知识的聚类方法
- (5) 基于多源异构语义知识融合的聚类方法
- 基于实体链接的实体消歧
- 其他实体消岐
- 应用
- 测评
- 总结与展望
-
- 优缺点
-
- 实体消歧优缺点
- 基于无监督聚类的实体消歧优缺点
- 基于实体链接的实体消歧优缺点
实体消歧是指解决同名实体存在的一词多义歧义问题. 实体消歧研究中常用的方法是基于实体链接的实体消歧, 通常链接的目标知识库为Wikipedia,随着知识图谱的发展, 基于知识图谱的实体消歧研究逐渐增多。
分类
按实体任务领域划分
- 基于结构化文本
- 通常被存储在数据库中,结构化的文本记录,缺少上下文信息,主要依赖字面意思和实体关系信息进行消歧。
- 基于非结构化文本
- 一段非结构化的文本,含有大量的上下文信息,主要利用指称项上下文信息进行消岐。
按有无目标知识库划分
-
无监督聚类
将所有实体指称项按指向的目标实体进行聚类
一个实体的指称项是在具体上下文中出现的待消歧实体名
-
实体链接
将实体指称项链接到目标候选实体列表中所对应的实体上
按链接知识库类型划分
-
基于知识库的实体链接
在大型文本知识库中提取上下文特征和获取上下文信息
-
基于知识图谱的实体链接
利用知识图谱(KG)结构来表示实体之间的关系以及候选实体的上下文特征
除此之外,实体消岐还分为词义消岐、命名实体识别(实体抽取)
词义消岐
传统词义消岐采用的主要是基于知识库或基于语料库的消岐方法
-
基于知识库的消岐方法
消岐知识库包括Wordnet和Hownet等,自适应Lesk算法推广至基于语义消岐方法;基于3种符号编码模型的消岐方法
-
基于语料库的消岐方法
- 无监督的聚类词义消岐
- 有监督的消岐方法
命名实体识别
-
任务
- 识别文本种任命、地名、机构名、时间、日期等指定类型的实体。
-
命名实体识别系统通常包括两部分:实体边界识别和实体类别标注
- 实体边界识别确定一个字符串是否构成一个实体
- 实体归类将识别出的实体事先划分为指定的不同类别
-
命名实体识别方法分为:基于规则的方法、基于统计的方法和基于深度学习的方法
- 基于规则的方法:不需要标注训练语料,直接根据词典和规则进行分词,但可扩展性交叉,难以适应各种数据的变化。
- 基于统计模型的方法:使用统计模型来建模输入与输出之间的关联,并使用机器学习方法来学习模型参数,隐马尔可夫模型、最大熵、SVM、条件随机场等较为常用。
- 基于深度学习的方法:利用神经网络实体的低维表示,利用表示找出实体类别。
方法
实体消岐方法主要按照目标列表是否给定划分为:基于聚类的消岐系统和基于实体链接的消岐系统
基于无监督聚类的消岐系统
没有给定目标库,通过比较各个实体的相似程度,将相似度高的聚集到一起,核心问题是选取何种特征对指称项进行表示,根据定义实体对象与指称项之间的相似度,以下是五种聚类法:
(1) 基于词袋模型的聚类方法
典型的方法是将当前语料库中实体指称项周围的词组成特征向量,然后利用向量的相似度对指称项进行比较,并将指称项划分到最接近的实体引用项集合中。
例如, Bagga等利用向量空间模型(VSM)计算实体指称项词向量之间的相似度进行聚类; Liu等利用标准空间向量模型以及HAC聚类算法进行消歧。
基于词袋模型的聚类方法采用的特征向量往往不能很好地代表实体本身,而且实体之间的向量区分不明确,从而影响聚类效果。
(2) 基于语义特征的聚类方法
基于语义特征的聚类方法与基于词袋模型的聚类方法类似,但两者的构造方法不同. 语义模型的特征向量不仅包括词袋向量, 还包含语义特征。
例如, Pederson 等[26] 通过对文本进行分解得到实体的语义向量, 并结合词袋向量得到更精确的聚类结果。
(3) 基于社会化网络的聚类方法
基于社会化网络的聚类方法遵循“物以类聚,人以群分”的原则. 该类方法先构造社会化网络,再利用网络中的社会关系计算实体指称项之间的相似度。
Emami[30] 提出了一个基于聚类的人名消歧系统,将从文本中提取实体之间的个人属性和社会关系映射到一个无向加权图(属性-关系图),使用聚类算法对图进行聚类,其中每个聚类包含指向一个人的所有web页面
基于社会化网络的聚类方法较为注重实体之间的关系而忽略实体本身的特征以及实体的上下文特征,并且网络构造难度大、复杂度高.
(4) 基于百科知识的聚类方法
百科类网站通常会为每个实体(指称项)分配一个单独页面,其中包括指向其他实体页面的超链接,百科知识模型正是利用这种链接关系来计算实体指称项之间的相似度。
然而,百科知识覆盖性有限且实体种类较少,因此此类方法使用率较低
例如, Han等[31] 从维基百科中构建了一个大规模的语义网络,根据语义网络中的百科语义知识进行消歧; Sen[32] 提出了主题模型,利用群体学习主题模型进行集体消歧
(5) 基于多源异构语义知识融合的聚类方法
传统的聚类实体消歧方法所使用的目标知识库通常只有一种,覆盖度有限. 采用多源异构知识可以克服这一缺点. 多源异构知识是指知识源中存在大量的多源异构知识,挖掘和集成不同知识源中的结构化语义知识表示模型来统一表示这些语义知识可以提高实体消歧效率.
其中,多种方法的多源异构知识表示框架为结构化语义关联图. 语义关联图中每个节点代表一个独立的概念,节点之间的边代表概念之间的语义关系,边的权重代表语义关系的权重。
该方法使用多个知识库进行聚类,多种数据源之间表达方式略有差异且组合难度大,从而导致实体聚类效果差。
基于实体链接的实体消歧
任务是将给定实体指称项链接到目标知识库中的相应实体上,步骤为:
-
候选实体的生成
首先需要给定一个实体指称项,然后根据知识、规则等信息找到实体指称项所对应的候选实体列表。
候选实体集合的质量取决于:(1) 是否包含目标实体 (2) 候选实体的数目
-
基于词典构建的方法
常用方法为构建同义词词典及歧义词典. 首先通过同义词词典将实体指称映射为规范形式,然后通过歧义词典获得实体指称的初始候选实体集合。
例如, Ratinov 等[35] 使用实体流行度对候选实体进行筛选
-
基于表面形式扩展的候选生成方法
为解决缩写形式,可以使用扩展技术的候选生成方法,包括基于启发式方法和基于监督学习方法
-
基于启发式方法
对于实体指称的缩写形式,通过启发式模式匹配搜索实体指称周围的文本来扩展缩写. 最常见的模式是利用规则。然而,基于启发式方法的表面形式扩展无法识别一些复杂的缩写的扩展形式
Varma等[36]以及Gotipati等[37]将已经被识别的实体看成一个子串,如果实体指称包含一个
子串,则该实体为实体指称的扩展形式. Cucerzan[38]采用一个缩写检测器,主要利用网页数据识别缩写的扩展. -
基于监督学习方法
基于监督学习的方法需要标记数据,利用标记数据找到候选实体。
Zhang等[39] 提出了一种基于监督学习的缩略语展开算法,利用SVM分类器对每个候选缩写扩展输出一个置信得分,将得分最高的扩展实体作为候选实体
-
-
基于目标库的候选生成方法
由于目标知识库(例如维基百科、 DBpedia等)包含多种页面数据,可以利用这些页面数据找到候选实体. 主要利用消歧页面以及重定向页面的信息生成候选实体. 对于有歧义的实体,消歧页面进行了总结,重定向页面中汇总了提及以及其对应的别名。
杨光等[40] 利用DBpedia知识图谱数据中提供的数据集进行候选实体生成. 从消歧数据集中添加候选实体并利用提供的数据集,结合实体先验概率生成候选实体列表。
-
-
基于知识库的实体链接系统
基于知识库的实体链接系统的目标知识库通常为维基百科知识库。最常用的两种候选实体链接方法是局部实体链接和协同实体链接。
-
局部实体链接
局部实体链接通常得到实体指称以及实体的上下文信息的特征表示,然后计算实体指称以及实体表示的相似度以选出目标实体。局部实体链接方法主要包括传统特征方法和表示学习方法。
-
传统特征方法
核心:手工设计有效的特征
例如, Honnibal 等[41] 利用Bow模型得到实体指称项和候选实体的向量,将余弦相似度得分最高的作为候选实体。
传统特征方法对目标实体和实体指称项表示都是启发式的,如词袋模型、 TF-IFD等. 这些启发式算
法很难调整,而且很难捕获更细粒度的语义信息和结构信息,所以传统特征方法不是主流的方法。 -
表示学习方法
核心:获得实体和实体指称项上下文的分布式表示。
通常采用神经网络的方法自动学习实体以及实体指称项的分布式表示. 神经网络常用的有LSTM、 CNN、 RNN等。
神经网络进行实体链接的两种方法:排序方法、二值分类方法
- 排序方法:训练一个排序模型,对所有候选实体进行排序,取排序最高的作为目标实体
- 二值分类方法:训练一个分类器来决定实体指称项与候选实体是否相同
研究者们提出将注意力机制与深度神经网络相结合训练上下文的语义特征向量以改进实体消歧模型[50]. Sun等[51] 通过注意机制自动从周围的上下文中发现实体指称以及候选实体的重要线索,并利用这些线索促进实体消歧. Zeng 等[52] 将长短时记忆网络 (LSTM) 与双重注意力相结合进行实体消歧. 第1个注意力机制将实体嵌入作为注意向量来突出实体描述中的信息部分;第2个注意力机制将实体上下文作为注意向量来突出实体指称上下文中的信息部分;最后结合相似度以及先验概率得到正确实体。
-
-
协同实体链接(全局链接)
一个文档中的实体具有一定的关联性,因而在局部链接之上增加了一个全局项,综合考虑目标实体之间的一致性。
-
基于图的方法
将所有实体指称的候选实体作为图的节点,指称之间的联系作为边的权重构成图模型,在此基础上采用消歧算法为实体指称选出一组最有可能的实体组合。主要分为三步:候选实体生成、实体相关图构造和集成实体链接。
Han等[56]提出的集成实体链接算法以维基百科作为本地知识库,对给定的文本首先提取出所有实体指称项,并通过查询确定每个实体指称项在知识库中的候选链接对象。
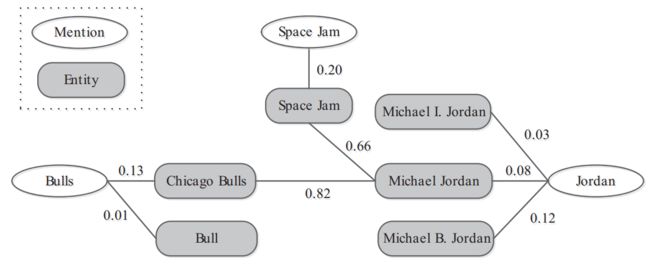
-
基于条件随机场的方法
基于条件随机场(CRF)模型全局方法可以很好地与局部方法联合起来。
Durrett等[59] 研究的模型在形式上是一个结构化的传统随机场. 一元因子从每个任务的强基线编码本地特性,添加二进制和三元因子来捕获跨任务交互,将实体识别与实体消歧联合实现。
-
基于Pair-Linking的方法
现有的协同链接方法假设每一个链接到的候选实体都要与其他所有的实体相关,这一假设在多主题的长文档中并不一定成立;而且要考虑所有链接的实体之间的一致性,现有方法计算复杂度高. 通过对实体做Pair-Linking[60]可以克服这一弊端。
Phan等[61] 利用Pair-Linking算法通过模拟Kruskal算法来近似MINTREE(基于树的实体消歧目标)的解,从而得到正确实体集合
-
基于深度学习的方法
Xue等[63] 提出了RRWEL模型,模型使用CNN学习局部上下文、提及、实体、类型信息的语义表征,使用随机漫步网络对文档信息进行学习,结合局部信息和全局信息得到文档中每个提及所对应的正确实体。
深度学习方法的消岐效率较高,但训练起来工程很大。
可以考虑深度学习+基于图的方法进行集体消岐[64],[65,66]将构建的实体图输入到图神经网络中进行学习。Deng 等[67] 构造了作者-文档的图网络,并提出了一种新的模型HRFAENE(异构关系融合和属性增强网络嵌入模型)进行集体消歧
-
-
-
基于知识图谱的实体链接系统
知识图谱是一个结构化的语义知识库,数据内容通常采用三元组表示,候选实体多侧重于从图结构中获取上下文信息,涉及图拓扑结构。
-
局部实体链接
主要利用实体指称以及候选实体的上下文信息选出目标实体候选实体
Shao等[71]在论文知识图XLore上提出了一个论文实体消歧框架,并设计了一个实体链接的概率公式以计算每个候选实体的概率,最后选出概率最高的实体作为正确实体。
深层语义匹配模型:模型使用字-LSTM 和词-LSTM 学习得到字以及上下文的匹配分数,并进行加权求和后对所有候选实体排序
知识图谱+图神经网络:一些研究者利用图神经网络(GCN[74]、 GAT[75])学习知识图的连续性表示,使得链接准确率得到提高
-
协同实体链接
基于知识图谱的协同实体链接假设文档中所有实体指称在知识图谱中所对应的目标实体是相关的。所以对一个文档中的多个指称项一起连接到目标知识图谱中。
基于知识图谱的实体链接系统的目标知识图谱是结构化的数据方式,实体的邻居节点可作为上下文信息,实体与实体之间的关系也可对链接提供帮助. 基于知识图谱的链接系统会成为未来实体消歧研究热点。
-
其他实体消岐
- 跨语言实体消岐
- 社交数据中的实体消岐
- 受限知识库的实体消岐
应用
实体消歧旨在解决文本中广泛存在的名称歧义问题,在知识图谱构建、语义化搜索、问答系统、推荐系统等领域有着广泛的应用。
知识图谱构建:知识图谱构建技术离不开实体消歧的支撑. 对于一段自然语言文本,例如“迈克尔·乔丹教授昨天访问了CMU” ,需要从自然语言文本中抽取信息以构成知识图谱. 处理流程如下:首先进行命名实体识别(“[迈克尔·乔丹]/PER教授昨天访问了[CMU]/ORG” );然后进行关系抽取(迈克尔·乔丹, visit, CMU). 抽取出三元组并不能直接构造知识图谱,因为不知道迈克尔·乔丹到底是哪个迈克尔·乔丹, CMU到底指的是哪个机构. 实体消歧技术将实体的歧义进行消除,经过实体抽取的实体都能够得到正确的链接. 实体消歧是知识图谱构建中必不可少的一步,对知识图谱的构建有着重要的作用。
测评
随着实体消歧技术的发展,实体消歧方法的评价技术也得到了重视. 主要包括实体消歧评测会议、实体消歧评测框架、实体消歧宏观评测指标。
总结与展望
实体消岐按有无目标知识库可划分为:基于无监督聚类的实体消岐和基于实体链接的实体消岐
- 根据有无目标知识库划分
- 基于无监督聚类的实体消岐
- 基于词袋模型的聚类
- 基于语义特征的聚类
- 基于社会网络的聚类
- 基于百科知识的聚类
- 基于多源异构语义知识融合的聚类
- 基于实体链接的实体消岐
- 基于知识库的实体链接系统
- 基于知识图谱的实体链接系统
- 基于无监督聚类的实体消岐
优缺点
实体消歧优缺点
| 方法 | 优点 | 缺点 |
|---|---|---|
| 基于无监督聚类的实体消歧 | 不需要候选实体集合以及标记训练数据 | 实体之间特征区分不明确 |
| 基于实体链接的实体消歧 | 有目标库,消歧更加准确 | 需要大量有标签数据,耗费人力 |
基于无监督聚类的实体消歧优缺点
| 方法 | 优点 | 缺点 |
|---|---|---|
| 基于词袋模型的聚类方法 | 思路简单,易于实现 | 实体向量之间难以区分 |
| 基于语义特征的聚类方法 | 向量特征表示准确,聚类效果好 | 算法匹配程度很难最优 |
| 基于社会化网络的聚类方法 | 能够利用社会关系进行聚类 | 忽略实体本身特征,网络构造难度大 |
| 基于百科知识的聚类方法 | 百科网站知识特征表示全面 | 百科知识覆盖性有限且实体种类较少 |
| 基于多源异构语义知识融合的聚类方法 | 利用多种数据源可提供多种特征 | 知识库表达方式有差异组合难度大 |
基于实体链接的实体消歧优缺点
| 方法 | 优点 | 缺点 |
|---|---|---|
| 基于知识库的局部实体链接 | 词条内容丰富 | 上下文信息对实体表示不够充分 |
| 基于知识库的协同实体链接 | 增加实体之间相关性,消歧准确率高 | 文档信息量大,链接复杂性高 |
| 基于知识图谱的局部实体链接 | 图数据实体的上下文信息丰富 | 图谱数据标记样本较为复杂 |
| 基于知识图谱的协同实体链接 | 图数据协同实体链接准确率高 | 图谱数据关系较多,检索较为麻烦 |