论文阅读:MMFT-BERT: Multimodal Fusion Transformer with BERT Encodings for Visual Question Answering
1、abstract
We present MMFT-BERT (MultiModal Fusion Transformer with BERT encodings), to solve Visual Question Answering (VQA) ensuring individual and combined processing of multiple input modalities.
Our approach benefits from processing multimodal data (video and text) adopting the BERT encodings individually and using a novel transformer- based fusion method to fuse them together.
2、contribution
1、we propose a novel multi-stream end-to-end trainable architecture which processes each input source separately followed by feature fusion over aggregated source features.
2、we propose a novel MultiModal Fusion Transformer (MMFT) module, repurposing trans- formers for fusion among multiple modalities.
3、we isolate a subset of visual questions, called TVQA-Visual (questions which require only visual information to answer them). Studying our method’s behavior on this small subset illustrates the role each input stream is playing in improving the overall performance.
3、Framework
figure1 below is MMFT module architecture:
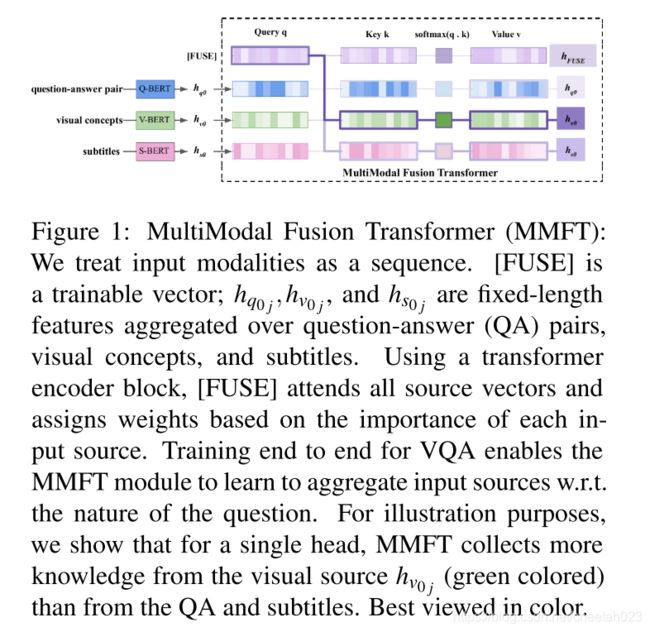
figure 2 below is full architecture:
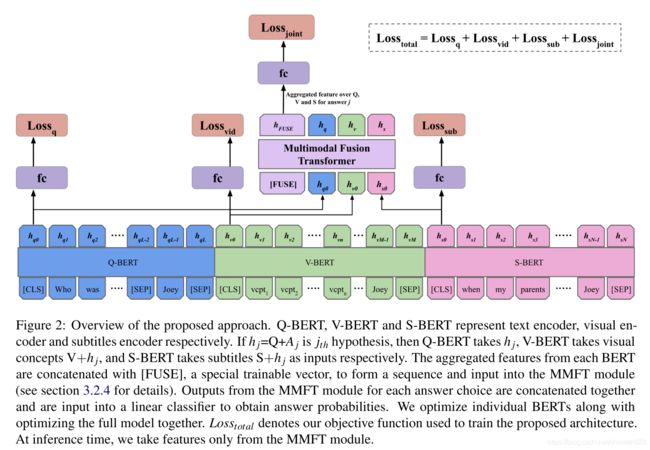 4、Approach
4、Approach
4.1、Problem Formulation:
we assume that each data sample is a tuple (V,T,S,Q,A, l) comprised of the following:
V: input video;
T: T = [tstart ,tend], i.e., start and end timestamps for answer localization in the video;
S: subtitles for the input video;
Q: question about the video and/or subtitles;
A: set of C answer choices;
l: label for the correct answer choice.
TVQA has 5 candidate an- swers for each question. Thus, it becomes a 5-way classification problem.
4.2、MultiModal Fusion Transformer with BERT encodings (MMFT-BERT)
4.2.1、Q-BERT
text encoder named Q-BERT takes only QA pairs. The question is paired with each candidate answer Aj, where, j = 0,1,2,3, 4; |A| =C.
The input I to the text encoder is formulated as:
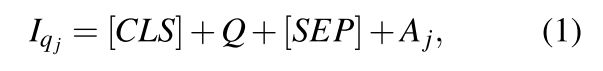
![]() is the input sequence which goes into Q-BERT and represents the combination of question and the jth answer.
is the input sequence which goes into Q-BERT and represents the combination of question and the jth answer.
We initiate an instance of the pre-trained BERT to encode each of the ![]() sequences:
sequences:
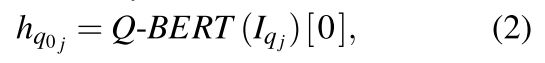
4.2.2、V-BERT
Input to our visual encoder is thus formulated as follows:
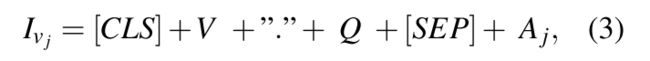
V is the sequence of visual concepts(Visual concepts is a list of detected object labels using FasterRCNN (Ren et al., 2015) pre-trained on Visual Genome dataset.)。
![]() is the input sequence which goes into our visual encoder.
is the input sequence which goes into our visual encoder.
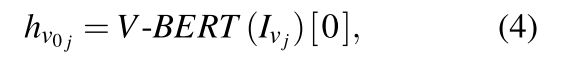
4.2.3、S-BERT
we concatenate the QA pair with subtitles as well; and the input is:
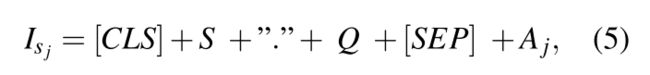
S is the subtitles input,![]() is the resulting input sequence which goes into the S-BERT encoder.
is the resulting input sequence which goes into the S-BERT encoder.
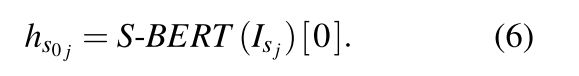
4.2.4、Fusion Methods
Let Ii ∈ Rd denote the feature vector for ith in- put modality with total n input modalities i.e. I1, I2, ..., In, d represents the input dimensionality. We discuss two possible fusion methods:
Simple Fusion:

![]() is the resulting multimodal represen- tation which goes into the classifier.
is the resulting multimodal represen- tation which goes into the classifier.
MultiModal Fusion Tranformer (MMFT):
MMFT module is illustrated in figure 1.
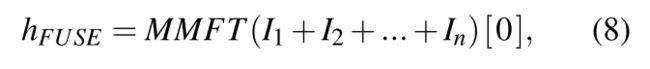
We treat 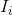 as a fixed d-dimensional feature aggregated over input for modality i.
as a fixed d-dimensional feature aggregated over input for modality i.
we have three input types: QA pair, visual concepts and subtitles.
For inputs i = {1,2,3} and answer index j = {0,1,2,3,4}, the input to our MMFT module is 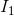 =
= ![]() ,
, 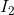 =
= ![]() , and
, and 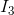 =
= ![]() and the output is
and the output is ![]() denoting hidden output corresponding to the [FUSE] vector. Here,
denoting hidden output corresponding to the [FUSE] vector. Here, ![]() ,
, ![]() , and
, and ![]() are the aggregated outputs we obtain from Q-BERT, V-BERT and S-BERT respectively.
are the aggregated outputs we obtain from Q-BERT, V-BERT and S-BERT respectively.
4.2.5、Joint Classifier

4.3、Objective Function
The formulation of the final objective function is as follows:
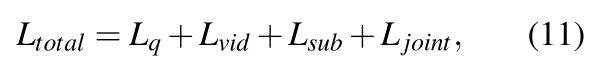
Lq, Lvid, Lsub, and Ljoint denote loss functions for question-only, video, subtitles, and joint loss respectively; all loss terms are computed using softmax cross-entropy loss function using label l.
The model is trained end-to-end using  .
.
5、Experiments and Results
5.1、results on TVQA validation set
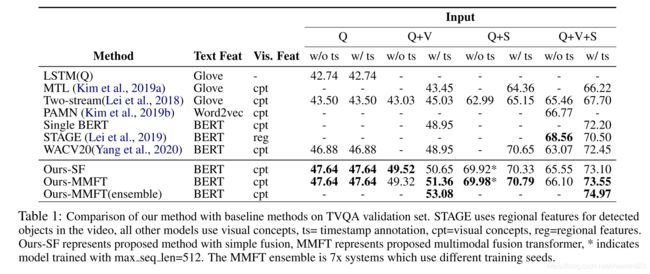
MMFT achieved SOTA performance with all three input settings: Q+V (↑ 2.41%), Q+S (↑ 0.14) and Q+V+S (↑ 1.1%) (compared to WACV20)
5.2、results on TVQA testset-public
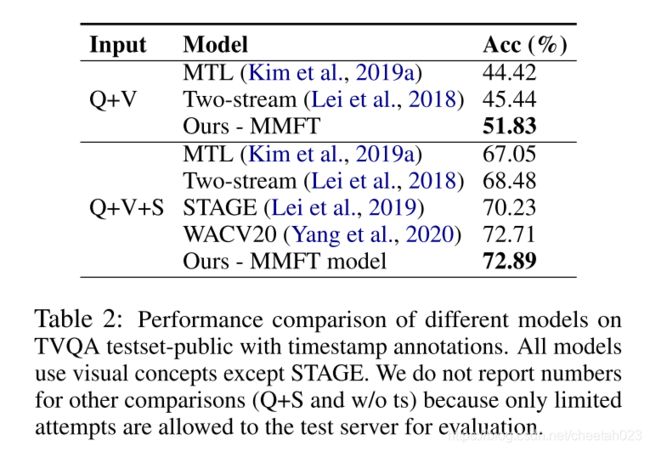
attention:
1、For Q+V+S, WACV20 reported 73.57% accuracy with a different input arrangement than MMFT
2、Due to limited chances for submission to the test server for evalua- tion, the reported accuracy for Q+V+S is from one of our earlier models, not from our best model.
6、conclusion
1、MMFT uses multiple BERT encodings to process each input type separately with a novel fusion mechanism to merge them together.
2、We repurpose transformers for using attention between different input sources and aggregating the information relevant to the question being asked.
3、on TVQA validation set,MMFT reach SOTA in Q+V (↑ 2.41%), Q+S (↑ 0.14) and Q+V+S (↑ 1.1%) (compared to WACV20)
4、Our proposed fusion lays the groundwork to rethink transform- ers for fusion of multimodal data in the feature dimension.