【论文阅读】A CNN-Transformer Hybrid Approach for CropClassification Using MultitemporalMultisensor Images
论文题目:利用多时相多传感器图像进行作物分类的CNN-Transformer混合方法
目录
摘要
I.INTRODUCTION
II. RELATE WORK
A. Ground Truth of Crop Types
B. Preprocessing
III. PROPOSED METHODOLOGY
A. Multisensor Spatial-Spectral Scale Unifification
B. CNN-Transformer Architecture for Classifification
IV.EXPERIMENTATION
A. Study Area and Dataset Description
B. Evaluation Criteria and Classifification Methods
C. Hyperparameter Analysis of the Proposed Network
D. Experimental Results
V. DISCUSSION AND CONCLUSION
REFERENCES
摘要
多时相地球观测能力在作物监测中发挥着越来越重要的作用。随着卫星获取遥感图像的频率越来越高,如何充分利用密集多时相数据中隐含的物候规律变得越来越重要。在本文中,我们提出了一种CNN-Transformer方法来执行作物分类,在该模型中,我们借用NLP知识中的Transformer架构来挖掘多个片段的模式。首先,在统一从不同传感器获取的每个多波段数据的空间光谱尺度后,我们获得了多时相序列的尺度一致性特征和位置特征。其次,通过采用变压器衍生的多层编码器模块,我们挖掘了多时序列的深度相关模式。最后,前馈层和softmax层作为模型的输出层来预测作物类别。拟议的CNN-Transformer方法在加利福尼亚州中部一个作物丰富的农业地区得到了说明,2018年,该地区获得了来自多传感器Sentinel-2 a/B和Landsat-8的65个多时剖面。通过多波段多分辨率融合、多时相数据序列相关性提取和类别特征提取,分类结果表明,与其他传统方法相比,该方法具有显著的性能改进。
关键字:作物分类、多时相传感器、self-attention、Transformer
I.INTRODUCTION
粮食安全是世界经济安全的基础。农业不仅是保障社会发展的基本条件,也是促进社会发展的重要经济领域。为了促进农业的健康发展,对农用地上的作物种类进行监测,控制作物种类的变化越来越重要。近年来,随着越来越多的地球观测卫星投入使用,我们可以获得越来越时间密集的遥感(RS)图像,这可以帮助我们提高作物的分类精度[1],[2]。特别是,通过结合Sentinel-2A、B和Landsat-8[3],我们可以获得中等分辨率的遥感数据,回访周期短至3-5天。得益于密集的时态遥感数据,我们可以更准确地监测土地利用[5],[6],例如:作物分类、物候变化和土地分类。
不同作物具有物候差异,通过区分作物的不同时间光谱规则,可以提高作物的分类精度。一些研究表明了多时相信息的重要性,Devadas等人[7]提出了一种使用支持向量机(SVM)的基于对象的分类方法,该方法在利用多时相陆地卫星数据对夏季和冬季不同作物类型进行分类时优于基于像素的方法。Li等人[8]使用支持向量机和决策树监督分类方法对多时相HJ卫星图像进行分类,作物分类结果表明,HJ-1 A/B卫星具有较高的时间分辨率,在提取植被信息方面具有独特的优势。在[9]中,Melgani提出了一种用于分类的空间和光谱模糊融合方法,并利用转移概率获得了时间信息。农业土地覆盖图的精度基本上与多时相图像的数量呈正相关,Pax等人[10]发现,随着时间序列图像数量的增加,埃及农业地区土地面积的估计精度变得更高。为了在潮湿、热带或亚热带地区获得充足的无云遥感数据,Useya和Chen[11]融合了多时相Landsat 8、Landsat 7和Sentinel-2数据,并在津巴布韦获得了更准确的作物地图。然而,在作物生长的关键阶段,物候的细微差异往往对作物生产有重要指示,例如:油菜开花或移栽水稻分蘖期。但是,稀疏的多时相遥感数据并不表明作物物候的细微差异,因此,利用密集的多时相遥感数据挖掘细微的物候差异非常重要。到目前为止,如何利用遥感数据的密集时间特征来区分作物的精细物候差异仍然是一个重要的挑战。
作为一种强大的特征提取框架,深度学习在广泛的任务中取得了巨大的成功。与需要复杂特征工程的传统机器学习算法相比,深度学习能够自动学习鲁棒的特征表示,更容易适应不同的领域和应用。在遥感图像处理任务中,深度学习也显示出巨大的潜力[12]。在图像分析与数据融合大赛中 ,IEEE地球科学与遥感学会的融合技术委员会(FusionTechnicalCommitteeoftheIEEEGeoscienceandRe2;moteSensingSociety)采用了一系列深度学习技术[13],如CNN和超分辨率,发挥了重要作用,并取得了明显的成果。Zhang等人[14]提出了一种基于CNN的统一时空光谱框架来弥补遥感图像中的缺失数据,该方法可以解决缺失信息重建任务,包括:MODIS6波段的死线、厚云去除等。除了多传感器图像,Chen等人[15]在高光谱分类问题中引入了深度学习体系结构。通过使用堆叠式自动编码器,分类结果比传统的支持向量机方法具有更好的性能。
注意机制是人类利用注意力从大量信息中快速筛选出高价值信息的一种方法。它是人类在长期进化过程中形成的一种生存机制。视觉注意机制可以极大地提高信息处理的效率和准确性。注意机制模仿生物观察行为的内部加工,将内部感知和外部感知联系起来,以提高某些区域的观察精细度。注意力可以解释为一种方法,它将可用的计算能力分配给信号中信息量最大的部分[16]–[19]。注意机制在许多任务中都显示了它的效用,包括:顺序学习[20]、[21]、图像字幕[22]、[23]、机器翻译[24]、[25]、句子摘要[26]、机器理解[27]和文档分类[28]。
在本文中,我们借用NLP领域的transformer架构来模拟作物物候差异。谷歌提出的transformer架构基于自我注意机制,展示了对序列相关性建模的出色表达能力,并在许多NLP任务中取得了最佳效果,如机器翻译[29],文档分类等。依靠自我注意模块强大的序列建模能力,我们可以区分细微但重要的物候差异,例如在水稻插秧期,密集时间序列数据中包含的细微物候差异可以帮助我们区分分蘖期,并预测分蘖数[30];谷类作物孕穗期的旗叶生长具有细微的物候差异,也可用于预测粮食产量[31];由于种植日期、品种和土壤条件的不同,油菜田间开花和结荚的时间通常不同,对物候和环境条件的密集监测可能会提高油菜的疾病和虫害风险[32]。对于这些情况,与传统的分类方法ods[7]相比,transformer架构可以获得更精确的物候模式。
transformer架构利用多头自我注意模块来表示序列模式。多头自我注意模块摒弃了传统的递归序列信息建模方法,如RNN、GRU和LSTM,缩短了序列中不同位置之间的信息在网络中传播的路径长度,并且可以直接获得序列中任何位置组合的长程相关性。因此,与传统的RNN和LSTM结构相比,多头自我注意模块极大地提高了序列信息相关表示的能力。我们使用这种优良的结构来提取序列信息的特征,表达序列中时间位置之间的相关性,并使用作物之间的物理差异来获得更准确的作物分类结果。首先,利用CNN表达空间和光谱相关性的能力,我们统一了Sentinel-2和Landsat-8样本多波段图像的空间光谱特征尺度。其次,我们将变换器结构应用于时空谱张量,以获得其时间相关性。最后,添加一个前馈层和一个softmax层,我们可以得到作物类型。
本文的其余部分组织如下。第二节介绍了研究区域作物类型的基本情况和数据预处理。第三节阐述了基于transformer结构的分类方法。第四节介绍了研究区域和实验结果。最后,在第五节中给出了本文的进一步讨论和结论。
II. RELATE WORK
A. Ground Truth of Crop Types
农田数据层(CDL)产品由美国农业部(USDA)国家农业统计局(National Agricultural Statistics Service)生产,是一种地理参考、栅格格式的作物类型覆盖分类地图,在全国范围内分辨率为30米。通过使用CDL数据,可以很好地评估一系列农田变化,例如作物强度、轮作、流行病学、流域、环境风险和灾害响应。例如,Maxwell等人[33]研究了癌症与农业化学品接触之间的关系。Shan等人[34]利用遥感图像和CDL产品估算并绘制洪水损失图。
在CDL生产过程中,该项目利用美国农业部农业服务局(FSA)的公共土地单元(CLU)数据、国家土地覆盖数据库数据、遥感卫星数据和一些其他辅助数据作为输入数据。在输入数据中,FSA CLU数据集是作物类型的综合农业地面真实数据,在生长季节多次更新。得益于作物类型可用地面真实数据的增加,CDL计划大大提高了效率和准确性。通过将CDL作物类型与从FSA CLU地面真实数据中提取的独立验证数据进行比较,可以获得CDL农业作物类型地图的准确性。由于在CDL产品的生产中使用了大量农业调查数据,主要作物类别的分类精度很高,通常为85%至95%。在本文中,我们选择面积较大的纯单一作物区域作为我们的作物类型。
B. Preprocessing
在作物分类之前,对卫星图像进行了几个预处理步骤。对于从美国地质勘探局下载的Sentinel-2 Level1C场景,我们首先使用Sen2cor大气校正模块获取从Level-1C TOA反射率值导出的表面反射率数据,然后使用Zhu等人[35]开发和改进的Fmask算法执行云和云阴影移除。与Sentinel-2类似,对于下载的Landsat-8 Level1 DN值,Landsat-8图像首先从DN值转换为光谱辐射,然后通过ENVI中提供的大气校正工具FLAASH将光谱辐射转换为表面反射率。使用与Sentinel-2相同的Fmask算法对云和云阴影移除进行了改进。接下来,在研究区域对无云场景进行镶嵌。最后,对于缺少云洞的地表反射率数据,我们使用自组织Kohonen映射(SOM)来重建时间序列图像中缺少的间隙数据。对每个光谱带进行孔洞重建:1)对于Sentinel-2或Landsat-8的时间序列波段图像,时间剖面的一些像素包含从云移除中获得的孔洞,我们选择没有时间间隙的时间剖面像素来训练SOM。2) 通过SOM学习,可以将没有间隙的时间轮廓的像素投影到映射向量的子空间,即SOM的权重向量表示训练样本的时间轮廓。3) 最后,SOM中神经元赢家权重向量的相关分量用于重建时间序列中缺失的数据[36]。
III. PROPOSED METHODOLOGY
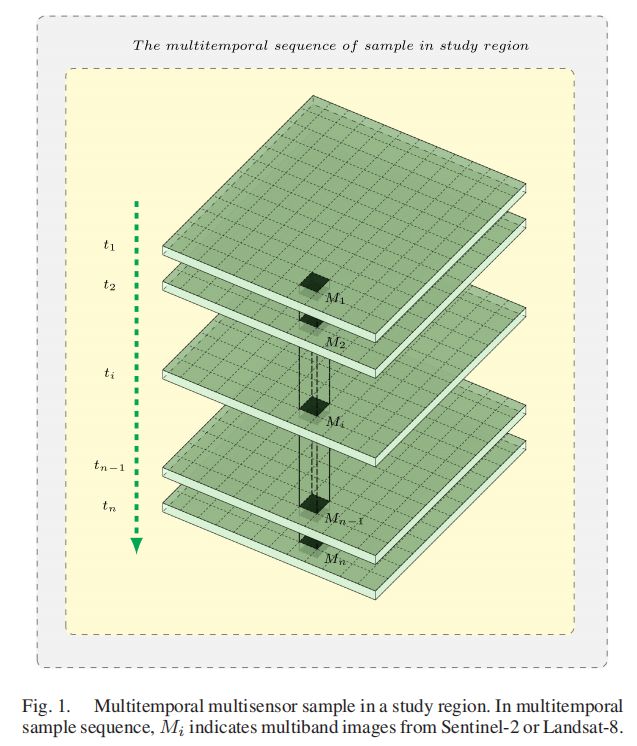
在本文中,Sentinel-2和Landsat-8获取的多时相多传感器图像可以从美国地质勘探局EROS中心下载。如图1所示,研究区域中的样本可以表示为M=[M1,M2,…Mi…,Mn],其中n是多时样本的时间长度,Mi代表对应多波段图像的日期。
在样本中,Sentinel2或Landsat-8的多波段图像集Mi可以表示为:
![]()
其中i表示多时序列中的采集时间,k表示传感器波段,ik表示采集时间i上的传感器波段,bik表示ik的波段图像,尺寸为wik×hik。
一般来说,传感器有不同数量的多光谱波段,Sentinel-2有13个波段,空间分辨率分别为10、20和60米,Landsat-8有11个波段,空间分辨率分别为15和30米。为了从不同的传感器获得归一化特征图,首先,我们对每幅波段图像的空间分辨率进行归一化,以获得归一化的宽度和高度,然后对特征映射的通道维数进行归一化。
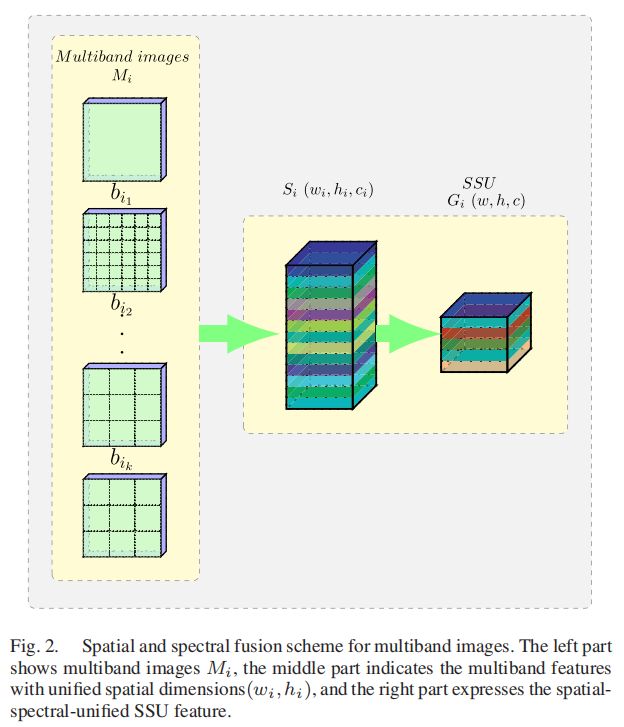
A. Multisensor Spatial-Spectral Scale Unifification
对应于多时多传感器样本M=[M1,M2,…Mi…,Mn],我们进行空间光谱融合,以获得每个图像集Mi的空间光谱统一(SSU)特征G=[G1,G2…,Gi,…Gn],其中Gi具有统一的特征尺寸(w,h,c),w,h,c表示SSU特征的宽度、高度和通道数。
如图2所示,空间光谱统一分为两个步骤,空间统一和光谱统一。
1) 每个波段的空间尺度统一:为了统一多波段图像的空间分辨率,我们将图像集Mi中的每个图像bik卷积起来,然后将所有卷积的特征以统一的尺度连接起来。

在公式中,Conv表示bik上的转置卷积变换,以获得尺度统一的特征,Concat表示以统一的尺度连接所有特征数据,bik是Mi中带ik的图像,bik是带ik的特征,具有统一的空间尺度(wi,hi),Si是三维维度张量(wi,hi,ci),其中wi和hi对应于统一特征的宽度和高度,ci对应于时间i上传感器的频带数。
2) 光谱尺度统一:不同的传感器通常具有不同的带数,为了统一来自不同传感器的多带特征,我们通过使用样本中整个时间序列的一致卷积核数来卷积三维张量Si
![]()
其中Conv表示卷积变换,Gi是一个维数为(w,h,c)的SSU张量,其中w,h,c对应于空间光谱统一特征的宽度、高度和通道。接下来,多时变压器模块将应用于获得的大规模统一多时SSU特征。
B. CNN-Transformer Architecture for Classifification
在网络中,引入了对序列信息具有卓越表达能力的变压器结构,对输入的多时相特征进行建模。作物分类的总体框图如图3所示:

模型架构由几个模块组成:SSU特征提取模块、位置特征模块、多层transformer编码器模块、前馈模块和softmax输出层模块。在本节中,我们将如下介绍这些模块。
1) SSU特征提取和位置特征嵌入:对于序列信息输入,transformer采用1-D矢量作为每个序列位置的输入,因此SSU特征的多时间序列需要首先转换为1-D矢量序列。多时相SSU特征具有(w,h,c)的统一形状,将每个序列位置上的SSU特征展平后,可以得到特征序列we=[e1,…,en],一维特征的长度为w×h×c。
序列的位置特征嵌入表示序列中特征的相对或绝对位置信息,位置特征可以用“位置编码”来描述位置编码与w×h×c的特征ei具有相同的向量长度dmodel。在这里,我们引用[37]中的函数来定义位置特征嵌入:

其中p是位置,i 表示位置特征的尺寸。
2) 多层transformer编码器模块:谷歌提出的transformer架构[37]与之前的RNN类序列信息建模模型不同,在NLP领域显示出强大的生命力。在transformer架构中,自我注意是一种类似于RNN和LSTM的顺序编码机制,它提高了单词序列之间关系的表达能力,从而在各种NLP任务中获得更好的性能。除了对序列信息之间的关系有很好的表达能力外,自注意在并行能力上远远优于类RNN模型,因为它一次输入整个序列进行训练,这可以大大提高序列模型的训练速度。
对于序列建模和序列分类,有不同的任务范式。对于序列建模,典型的任务是语言建模。对于句子sequence U={u1,…,un},可以使用标准语言建模目标来最大化可能性:L(U)=![]() .在使用transformer架构建立语言模型时,可以通过作用于编码器和解码器的前向掩蔽机制来实现句子序列的并行训练。掩码机制屏蔽了未来的单词嵌入,因此只能看到序列的左向信息,而右向信息是盲的。与语言模型任务不同,在分类任务中,输出是分类标签,而不是序列。标签对整个序列信息是可见的,因此分类模型可以利用所有序列信息。因此,在序列分类任务中,我们只利用transformer中的编码器模块,而不使用掩码机制。
.在使用transformer架构建立语言模型时,可以通过作用于编码器和解码器的前向掩蔽机制来实现句子序列的并行训练。掩码机制屏蔽了未来的单词嵌入,因此只能看到序列的左向信息,而右向信息是盲的。与语言模型任务不同,在分类任务中,输出是分类标签,而不是序列。标签对整个序列信息是可见的,因此分类模型可以利用所有序列信息。因此,在序列分类任务中,我们只利用transformer中的编码器模块,而不使用掩码机制。
在该体系结构中,我们使用多层变压器编码器模块作为序列模型,它是transformer的一个变体。如图4所示,编码器模块中有两个子层:第一部分是多头自我注意,第二部分是位置全连接前馈网络。此外,每个编码器中都有跳层连接和层规范化。
该模块以SSU特征和位置嵌入作为输入,因此h0可以作为
![]()
其中,SSU特征序列WE是时间序列特征[e1,…,en],包括整个日期和位置特征序列,WP代表每个时间位置[PE1,…,PEn]的位置嵌入。多层编码器模块可以描述如下:
![]()
其中n是层数。
3) 用于监督分类的输出层:为了获得作物分类,我们在网络中添加了前馈层和softmax层。对于我们的分类任务,我们得到一个带标签的数据集C,其中每个实例由时间序列特征G=[G1,…,Gn]和一个标签y组成。我们通过特征提取层和多层变压器编码器模块传递输入序列,以获得最后一个编码器的激活hl,然后添加带有参数Wy的前馈层和softmax层来预测y。
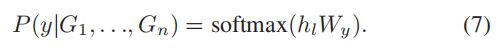
通过这个公式,我们得到了最大化的目标

在上述公式中,条件概率P是使用神经网络建模的。该模型可以使用随机梯度下降法进行训练。
IV.EXPERIMENTATION
A. Study Area and Dataset Description
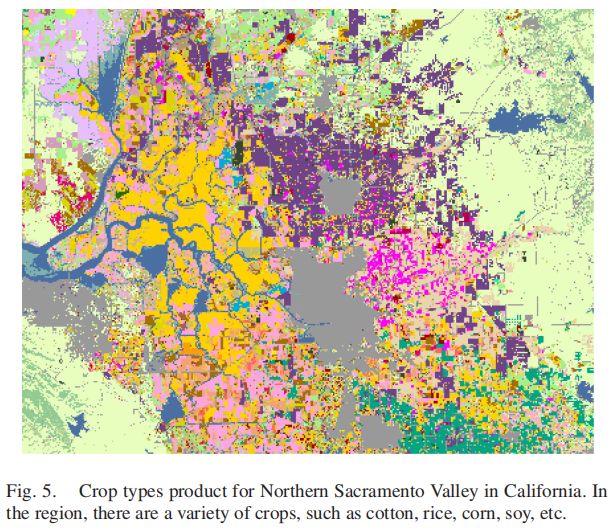
在我们的研究中,加利福尼亚州萨克拉门托河谷北部被选为研究区域,该区域具有典型的地中海气候。地中海气候在3月至9月作物生长季节阳光充足,云量较少,有利于获取更多有用的遥感图像。在该地区,选择了约100km×100km的区域作为研究区域,如图5所示。该地区有多种作物基质,包括西红柿、玉米、水稻、葡萄、苜蓿、向日葵、三叶草、杏仁和核桃,以及其他特殊作物(如西瓜、胡萝卜、洋葱、豌豆)如图6所示。该地区作物类型的基本情况可从CDL产品中获得。

为了保留卫星获取的多波段图像的原始空间信息,应避免对具有不同空间分辨率的多波段图像进行空间重采样。因此,样本块的像素大小设置为60m×60m,在一个像素块内,每个波段的空间信息是从卫星获取的原始信息。在研究区域内,选择面积较大的纯作物种植园作为主要作物的样本采集区。以60m×60m作为样本像素的大小,我们为主要作物类型选择大约相等数量的样本,以形成研究数据集,包括玉米、水稻、苜蓿、三叶草、休耕地、葡萄、杏仁、核桃、牧场、樱桃、冬小麦、红花。在本实验中,数据集共包含10种类型的39560个样本,其中1%用于训练,其余99%用于验证,如表一所示。

对于研究区域,Sentinel-2和Landsat-8的所有多波段遥感图像都是从美国地质调查局下载的2018年图像。然后,去除云层较厚的图像,保留无云和少云图像。通过几个预处理步骤,在图像中遮罩云,去除云覆盖的区域并填充相应的孔洞,我们可以得到长度为65的时间序列图像。如图7所示,由于天气晴朗,在3月至9月的作物生长季,生长期的时间数据非常密集。此外,丰富的时间信息可以帮助我们挖掘作物物候的微小差异。

B. Evaluation Criteria and Classifification Methods
为了评价不同分类模型的效果,人们制定了许多评价标准。混淆矩阵可以清楚地表示每个类别正确分类的样本数量和每个误分类类别的细节。然而,根据混淆矩阵,我们无法立即评估各种分类模型的性能。因此,从混淆矩阵中导出了各种分类精度指标,其中总体准确度(OA)、平均准确度(AA)和卡帕系数是使用最广泛的。
1) 总体准确度(OA):总体准确度是混淆矩阵中正确分类的值(右对角线上的值)之和除以样本总数,代表所有样本中正确预测的样本的比率。
2) 平均准确度(AA):平均分类准确度是所有分类准确度的平均值。
3) Kappa系数:与总体精度不同,Kappa系数是根据混淆矩阵的所有信息计算的。它被认为是地面真值图和最终分类图之间的一致性度量,可以更准确地表达整个分类精度。
为了评估本文提出的CNN transformer模型的效果,我们将其与传统的基于向量的分类方法(如支持向量机和随机森林)进行了比较。然后,将经典的深度网络模型如多时CNN和CNN-LSTM的性能与提出的CNN-transformer模型进行了进一步的比较。
1) RF-200:在实验中,随机森林中的决策树数设置为200。
2) SVM-RBF:我们使用LIBSVM软件包实现带有RBF核的支持向量机分类器,并考虑五次交叉验证来优化超平面参数。
3) CNN-transformer作物分类器:提出的CNN-transformer分类器结合CNN和transformer结构来挖掘作物的类别模式,其中CNN用于提取每个采集日期的空间光谱特征,transformer模块具有强大的序列模式提取能力,用于表示时间序列的相关性。
4) 多时相CNN分类器:对于提出的CNN-transformer分类器,我们用规则CNN层替换多层transformer编码器模块,以获得多时相CNN(MT-CNN)分类器,并将其与CNN-transformer分类器进行比较,以表示挖掘序列信息能力的差异。
5) CNN-LSTM作物分类器:CNN-LSTM分类器将CNN和LSTM结合起来,对样本有序且连续的多时多传感器特征进行建模,与多层transformer编码器模块不同,该分类器利用类似RNN的网络挖掘序列模式。
实验分为两部分。第一部分首先讨论了该方法中两颗卫星在每个采集日期的空间谱统一参数,然后讨论了transformer架构中的输入张量形状、自我注意层、编码器层数量和输出层配置,最后描述了用CNN结构代替transformer结构的比较多时相CNN分类器。第二部分比较了基于变压器结构的CNN变压器分类器与传统矢量模型的有效性,如随机森林、SVM、用常规CNN层代替变压器编码器层的常规CNN分类器,以及CNN-LSTM分类器。
C. Hyperparameter Analysis of the Proposed Network
在实验中,采集了尺寸为60×60m的基于像素的样本集。
(1) Sentinel-2的空间光谱统一:MSI在Sentinel-2上以VNIR和SWIR波段获取了13幅多光谱图像,10波段的卷云图像主要显示卷云的分布,而不是地面反射。因此,在丢弃卷云带后,剩余的多波段图像如下所示:
1) 10米处有4个波段:490纳米(B2),560纳米(B3),665纳米(B4),842纳米(B8)。
2) 20米处有6个波段:705纳米(B5)、740纳米(B6)、783纳米(B7)、865纳米(B8a)、1610纳米(B11)、2190纳米(B12)。
3) 在60米处有两个波段:443纳米(B1),945纳米(B9)。
如图8所示,在60×60米的样本区域中,有三种图像分辨率:10米波段的图像大小为6×6,20米波段的图像大小为3×3,60米波段的图像大小为1×1。

为了获得多波段图像的空间统一特征,我们对每个不同的输入图像使用不同的转置卷积核参数:
1)10米分辨率,在6×6输入上以单一步幅和无填充(i=6,k=1,s=1和p=0)解1×1核,输出为6×6。
2) 分辨率为20米,在3×3的输入上不求解4×4的内核,使用单一步长且无填充(i=3、k=4、s=1和p=0),输出为6×6。
3) 60米分辨率,在1×1输入上不求解6×6内核,使用单一步长且无填充(i=1、k=6、s=1和p=0),输出为6×6。
最后,对于多传感器,使用相同数量的5个卷积核,得到了具有统一维数(6,6,5)的多传感器空间谱统一特征。
(2)Landsat-8的空间光谱统一:样本上有11个Landsat-8光谱带,其中带9的卷云探测图像显示的是卷云的分布,而不是地面信息。因此,除卷云带外,有10个多光谱带具有两种空间分辨率:
1)30米处有9个多光谱带。
2)15米处有一个全色波段。
如图9所示,在60米×60米的样本中,Landsat-8多波段数据有两种图像大小:15米波段的图像大小为4×4,30米波段的图像大小为2×2。在产生相同的6×6空间输出的情况下,我们有两个用于Landsat-8:
1)15米分辨率的转置卷积核参数,在4×4输入上以单一步幅和无填充(i=4、k=3、s=1和p=0)解算3×3核,输出为6×6。
2) 分辨率为30米,在2×2输入上不求解5×5内核,使用单一跨距且无填充(i=2、k=5、s=1和p=0),输出为6×6。
将相同空间尺度的特征串接起来,得到维数(6,6,10),然后用五个卷积核进行卷积,得到维数(6,6,5)的SSU特征Gi。
(3)CNN变换网络的参数分析:如图3所示,经过上述空间谱尺度的统一,可以得到65个[6,6,5]形状的多时空间谱组特征。然后,为了获得变压器编码器输入的特征,我们将空间谱组特征展平,生成形状为[180]的一维特征,同时将位置嵌入的尺寸设置为[180],这与编码器输入相同。在该模型中,实验将多层编码器模块的数量设置为4个,对多时相特征进行序列编码后,将由两个完全连接的层组成的前馈层的参数设置为100和40。
为了公平地评估模型的效果,与CNN变换网络相比,多时相CNN分类器和CNN-LSTM仅用规则卷积层和LSTM层替换多层变换编码模块,模型的其他部分,如空间谱统一层和类别输出层,具有相同的网络结构。
对于所提出的模型,采用Adadelta算法对具有变压器结构的网络进行训练,在实验中,我们使用0.01的低学习率来训练网络。在该模型中,所有卷积层都附加了一个批量归一化层,其中模型中卷积层的所有权重矩阵和偏差向量都由xavier统一初始化,并且在训练过程中更新卷积权重和BN参数。在实验中,将CNN变换模型和比较的多时相CNN模型的训练历元数设置为1000,保证了模型的收敛性。
需要注意的是,在所提出的网络中,我们利用了具有不同空间分辨率的波段的原始空间信息,而传统的基于向量的分类方法,如随机森林和支持向量机,需要从具有不同空间分辨率的波段数据中重新采样的统一的60米空间分辨率波段图像。
D. Experimental Results
多时相作物数据集的分类混淆矩阵和精度评估如图10和表II所示。由于带RBF核的支持向量机比随机森林更有效地处理非线性数据,分类结果表明,支持向量机模型优于随机森林模型。此外,可以看出,提出的CNN-transformer模型比其他模型产生的结果更准确。具体而言,如表二所示,与RF相比,CNN-transformer模型的准确度分别显著提高了OA的6.12%、AA的5.61%和Kappa系数的0.0692。与SVM-RBF、多时相CNN和CNN-LSTM相比,CNN变压器模型得到的OA、AA和Kappa系数增量分别为4.86%、5.12%、0.0548和1.68%、2%、0.0189和2.28%、2.66%和0.0257。


根据分类精度分析,RF和SVM-RBF由于物候周期相似,无法有效区分类似作物,如玉米和水稻、核桃和樱桃。与RF和SVM-RBF相比,基于深度学习的多时相CNN模型具有强大的特征表达能力,可以挖掘相似作物的物候特征,提高作物的识别能力。与RF和SVM-RBF相比,多时相CNN和CNN-LSTM模型对核桃和樱桃的误分类率显著降低。本文提出的CNN-transformer模型在表达序列信息和区分序列特征方面优于多时相CNN模型序列的细微差异,与多时相CNN相比,玉米和大米的错误分类率降低了4%,核桃和樱桃的错误分类率降低了3%。
在实验中,我们在一台带有四个NVIDIA 1080ti GPU和TensorFlow库的机器上训练所提出的CNN-transformer模型。不同方法的训练时间如表III所示。预计深度神经网络模型的训练时间比传统方法更长,但如表IV所示,深度神经网络在测试时间上具有优势。

V. DISCUSSION AND CONCLUSION
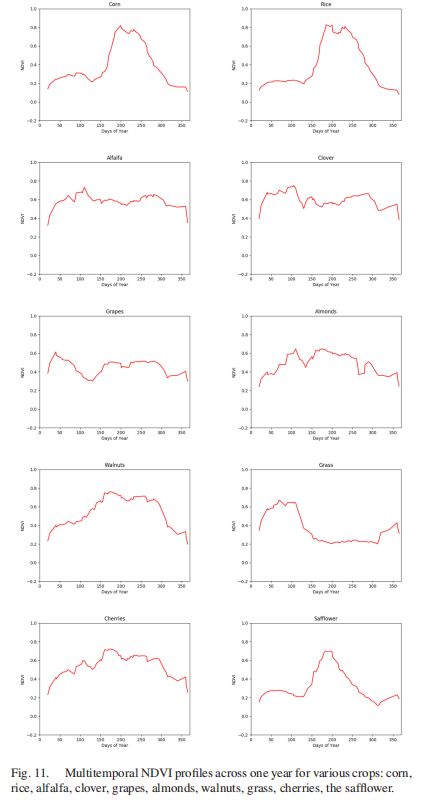
NDVI的多时相剖面代表作物的生长和退化,不同的剖面对应不同的作物类型和物候。样本集中某一类别的NVDI剖面与相同的物候周期大致一致,因此,为了计算每个样本的多期NDVI剖面并进一步平均每个类别的样本曲线,我们可以获得每个作物类型的平均时间NVDI剖面,如图11所示。在这些作物中,玉米、水稻和红花是夏秋作物,这些作物的NDVI剖面在春季有明显的生长发育阶段,在秋季有一个干燥阶段。然而,杏仁、核桃和樱桃,这些落叶或半常绿树木没有明显的生长期,但NVDI剖面也反映了这些树木的绿色状况。此外,紫花苜蓿和三叶草等草本植物全年的多时相NDVI剖面没有突然变化。总之,图11的剖面图可以描述作物的所有差异。
进一步分析物候周期相似的作物,如图12和13,我们进行了玉米、大米和红花的比较,以及杏仁、核桃和樱桃的比较。
图12(a)显示了玉米、水稻和红花的物候差异。通过使用这些物候相似的作物来训练CNN转换器,该模型可以得到这些作物物候之间的差异。对于测试作物样本,图12(b)表示第一编码器层的自我关注权重。图(b)中的下部序列表示编码器层1的多时输入,上部序列表示自我注意编码输出。为了进一步分析输入和输出序列之间的自我注意权重,我们可视化了输出序列的部分自我注意权重。输出序列之间的自我注意权重可以如果用不同的颜色表示,深色代表较大的权重,而浅色代表较小的权重。从图(b)中的权重可视化可以看出,自我注意力的权重在时间段内具有较大的值:0-16、24-40和50-60,这反映了这些时间段内作物之间最明显的物候差异。也就是说,权重反映了对物候差异的关注,这可以提高相似作物的识别精度。
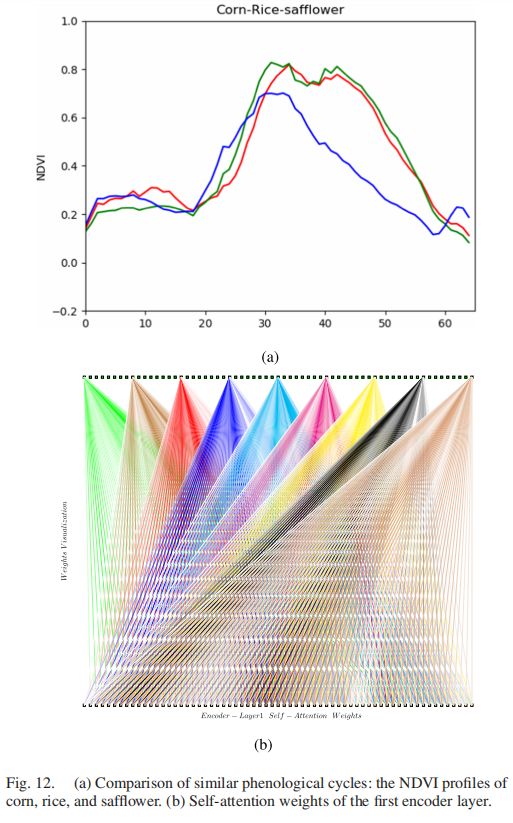
图13(a)显示了杏仁、核桃和樱桃的物候差异。与图12(b)类似,图13(b)也表示第一编码器层的自我注意权重。而0-20和40-60这两个时间段的权值较大,这表明微妙的物候差异主要在这两个时间段。
从以上分析中,我们发现一些作物的物候差异主要表现在微妙的时期。得益于一年内65个时态的多时数据,以及强大的自我注意模块来表达时间序列注意,我们可以得到更好的分类结果。换句话说,注意周期对分类结果的贡献更大,细微差异的区分可以通过自我注意机制实现。
在本文的总结中,我们建议使用CNN transformer网络对多时多光谱数据集进行作物分类。随着越来越多的地球观测卫星投入使用,我们可以获得密集的多时相遥感图像。本文从Sentinel-2 A/B和Landsat-8收集了65个采集日期的研究数据集。传感器的多波段图像具有不同的空间分辨率,然后利用转置卷积提取多波段的空间结构信息来融合空间光谱特征。多时相数据可以看作是一系列特征。为了处理序列信息,我们借鉴NLP的知识,借用transformer体系结构对作物分类中的时间序列之间的相关性进行建模,NLP具有强大的序列信息建模能力。在网络中,首先获得统一的多时相特征,然后得到序列信息的空间光谱特征和位置嵌入。其次,利用transformer导出的编码器模块来表示序列的相关性,通过将编码器模块堆叠成四层,可以得到序列的深度模式特征。第三,利用前馈层提取作物的类别特征。最后,利用softmax输出层对作物标签进行预测。实验结果表明,与其他传统方法相比,本文提出的CNN变换方法能够获得优异的性能。
该方法利用多层编码器模块的最终输出序列来提取类别特征。不同编码器层的输出可以表示不同级别的序列相关性。未来可以考虑融合不同层次的输出特征序列,更好地利用不同层次序列信息之间的关系,提高模型的性能。