数据挖掘复习
1. 概要
1.1 为什么要做数据挖掘?
我们生活在大量数据日积月累的年代。分析这些数据是一种重要需求。数据的爆炸式增长,广泛可用和巨大数量使得我们的时代成为真正的数据时代。急需功能强大和通用的工具,以便从这些海量数据中发现有价值的信息,把这些数据转换成有组织的知识。这种需求导致了数据挖掘的诞生。
1.2 数据挖掘需要解决什么问题
分类与回归、聚类、关联规则、时序模式、偏差检测
1.3 数据挖掘的主要步骤
- 数据清理
- 数据集成
- 数据选择
- 数据变换
- 数据挖掘
- 模式评估
- 知识表示
2. 数据的概念:统计描述、可视化、距离度量
2.1 数据的基本概念
-
标称属性(Nominal):是一些符号或事物的名称。每个值代表某种类别、编码或状态,因此标称属性又被看做是分类的。
-
二元属性(Binary):是一种标称属性,只有两个类别或状态:0 和 1。
-
序数属性(Ordinal):其可能的值之间具有有意义的序或秩评定,但是相继值之间的差是未知的。例如小、中、大。
-
数值属性(Numeric):是定量的,是可度量的量。用整数或实数值表示。
- 区间标度属性(interval-scaled):用相等的单位尺度度量。区间的值有序,可以为正、0、或负;没有真正的零点;可以计算差值、均值、中位数和众数。
- 比率标度属性(ratio-scaled):具有固定零点的数值属性,也就是说一个数可以是另一个数的倍数;此外这些值是有序的,可以计算差值、均值、中位数和众数。
-
离散数学和连续属性:
- 离散属性具有有限或无限可数个值,可以用或者不用整数表示。
- 如果属性不是离散的,则它是连续的。
2.2 数据常见的统计特征有哪些 分别是怎么计算
基本统计描述有三类
- 中心趋势度量:度量数据分布的中部或中心位置。讨论均值、中位数、众数、中列数
- 数据的散布:数据分散程度的度量。极差、四分位差、四分位数极差、盒图、方差、标准差
- 基于图形的可视化审视数据:分位数图、分位数-分位数图、直方图、散点图
中心趋势度量
-
均值

-
中位数
奇数是中间的数,偶数是中间两个数的和。但是当观测的数量很大,中位数的计算开销就很大,所以我们可以计算中位数的近似值,

L 1 L_1 L1 是中位数的下界, N N N是整个数据集中值的个数, ∑ ( f r e q ) l \sum(freq)_l ∑(freq)l是低于中位数区间的所有区间的频率和, f r e a m e d i a n frea_median freamedian是中位数区间的频率,而 w i d t h width width是中位数区间的宽度。
-
众数(mode)
集合中出现的最频繁的值。具有一个、两个、三个众数的数据集合分别称为单峰的(unimodal)、双峰的(bimodal)和三峰的(trimodal)。具有两个或多个众数的数据集是多峰的,极端情况下,每个数据只出现一次,则没有众数。
-
中列数
数据集中最大和最小值的平均值。
度量数据散布
-
极差
max-min
-
四分位数
2-分位数是将数据分为两半,小于二分位数的数据最多有1/2,对应于中位数。四分位数用3个数据点把数据划分成4个相等的部分。q-分位数将数据分成100个大小相等的连贯集。中位数,四分位数和百分位数是使用最广泛的分位数。
-
四分位数极差(IQR)
I Q R = Q 3 − Q 1 IQR = Q_3 - Q_1 IQR=Q3−Q1
给出被数据中间一半所覆盖的范围
-
五数概括
min,Q1,中位数(Q2),Q3,max
-
盒图
盒图体现了五数的概念

盒的端点一般在四分位数上,使得盒的长度是四分位数极差IQR;中位数用盒内线标记,盒外两条线(称作胡须)延伸到最小值和最大值。
-
方差和标准差
方差如下公式

标准差是方差的平方根,是发散性的度量。 δ \delta δ 度量关于均值的发散,仅当选择均值作为中心度量使用。 δ \delta δ越小,整体数据越靠近均值。
数据的基本统计描述图形显示
-
分位数图
对于一个序列数据 X X X,设每个观测值 x i ( i = 1 , ⋅ ⋅ ⋅ , N ) x_i(i = 1,···,N) xi(i=1,⋅⋅⋅,N)是按递增排序的, x 1 x_1 x1最小, x N x_N xN最大,每个观测值与一个百分数 f i f_i fi配对,指出大约 $f_i $ x 100% 的数据小于 x i x_i xi,这里说大约是因为可能没有一个精确地值 f i f_i fi
百分比0.25对应于四分位数Q1,百分比0.50对应于中位数,百分比0.75对应于Q3
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-a2buM3tv-1669877471579)(https://tva1.sinaimg.cn/large/008eGmZEgy1gmh789j66hj30me0b4abg.jpg)]
-
分位数-分位数图
-
直方图
-
散点图
-
2.3 怎么度量距离和相似性
标称属性和二元属性的邻近性度量
数值属性:Lp距离
标称属性的近邻性度量
标称属性可以取两个或多个状态,设一个标称属性的状态数目为 M M M
相异性
两个对象i和j之间的相异性可以根据不匹配率计算:
d ( i , j ) = p − m p d(i,j) = \frac{p - m} {p} d(i,j)=pp−m
其中 m m m是匹配的数目,即 i i i和 j j j取值相同的状态的属性数,而 p p p 是刻画对象的属性总数,由 d ( i , j ) d(i,j) d(i,j)可以构造相异性矩阵。
相似性
s i m ( i , j ) = 1 − d ( i , j ) = m p sim(i,j) = 1 - d(i,j) = \frac{m}{p} sim(i,j)=1−d(i,j)=pm
二元属性的近邻性度量
考察对称和非对称二元属性刻画的对象间的相异性和相似性度量。
二元属性只有 0 和 1 的取值。
相异性
如果所有的二元被看成具有相同的权重,则我们可以得到一个两行两列的列联表。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-WXnQio1L-1669877471579)(https://tva1.sinaimg.cn/large/008eGmZEgy1gmhbnm8yp1j30lg08k3zk.jpg)]
其中 q 是对象 i 和 j 都取 1 的属性数;
r 是在对象 i 中取 1 、在对象 j 中取 0 的属性数;
s 是在对象 i 中取 0、 在对象 j 中取 1 的属性数;
t 是对象 i 和 j 都取 0 的属性数;
属性总数为 p, p = q + r + s + t
基于对称二元属性的相异性叫做对称二元相异性,如果i 和 j是对称的,即它们同样重要,则 i 和 j 的相异性为
d ( i , j ) = r + s q + r + s + t d(i,j) = \frac{r+s}{q+r+s+t} d(i,j)=q+r+s+tr+s
对于非对称的二元属性,两个状态不是同样重要,认为两个都取1的情况比两个都取0的情况更有意义,这种二元属性经常被认为是(“一元的”)其中负匹配数t被认为是不重要的
d ( i , j ) = r + s q + r + s d(i,j) = \frac{r+s}{q+r+s} d(i,j)=q+r+sr+s
类似的,我们可以基于相似性而不是相异性来度量两个二元属性的差别,非对称的二元相似性可以用如下公式
s i m ( i , j ) = q q + r + s = 1 − d ( i , j ) sim(i,j) = \frac{q}{q+r+s} = 1 - d(i,j) sim(i,j)=q+r+sq=1−d(i,j)
这里的 s i m ( i , j ) sim(i,j) sim(i,j)被称作 Jaccard系数
数值属性的相异性
欧几里得距离、曼哈顿距离、闵可夫斯基距离
欧几里得距离
描述对象 i 、 j 之间的欧几里得距离
d ( i , j ) = ( x i 1 − x j 1 ) 2 + ( x i 2 − x j 2 ) 2 + . . . + ( x i p − x j p ) 2 d(i,j) = \sqrt{(x_{i1}-x_{j1})^2+(x_{i2}-x_{j2})^2+...+(x_{ip}-x_{jp})^2} d(i,j)=(xi1−xj1)2+(xi2−xj2)2+...+(xip−xjp)2
加权欧式距离
d ( i , j ) = w 1 ( x i 1 − x j 1 ) 2 + w 2 ( x i 2 − x j 2 ) 2 + . . . + w p ( x i p − x j p ) 2 d(i,j) = \sqrt{w_1(x_{i1}-x_{j1})^2+w_2(x_{i2}-x_{j2})^2+...+w_p(x_{ip}-x_{jp})^2} d(i,j)=w1(xi1−xj1)2+w2(xi2−xj2)2+...+wp(xip−xjp)2
曼哈顿距离
d ( i , j ) = ∣ x i 1 − x j 1 ∣ + ∣ x i 2 − x j 2 ∣ + . . . + ∣ x i p − x j p ∣ d(i,j) = |x_{i1}-x_{j1}| +|x_{i2}-x_{j2}| + ... + |x_{ip}-x_{jp}| d(i,j)=∣xi1−xj1∣+∣xi2−xj2∣+...+∣xip−xjp∣
欧式距离和曼哈顿距离满足如下数学性质
非负性:$d(i,j)>= 0 $ :距离是个非负的数值
同一性: d ( i , j ) = 0 d(i,j) = 0 d(i,j)=0:对象到自身的距离是0
对称性: d ( i , j ) = d ( j , i ) d(i,j) = d(j,i) d(i,j)=d(j,i):距离是对称函数
三角不等式: d ( i , j ) < = d ( i , k ) + d ( k , j ) d(i,j)<= d(i,k)+d(k,j) d(i,j)<=d(i,k)+d(k,j):从 i 到 j 的距离不会大于途径任何其他对象 k 的距离
满足这些条件的测度叫做度量(metric)
闵可夫斯基距离(Minkowski distance)
是欧氏距离和曼哈顿距离的推广
d ( i , j ) = ∣ x i 1 − x j 1 ∣ h + ∣ x i 2 − x j 2 ∣ h + . . . + ∣ x i p − x j p ∣ h h d(i,j) = \sqrt[h]{|x_{i1}-x_{j1}|^h+|x_{i2}-x_{j2}|^h+...+|x_{ip}-x_{jp}|^h} d(i,j)=h∣xi1−xj1∣h+∣xi2−xj2∣h+...+∣xip−xjp∣h
其中 h h h是实数, h > = 1 h>=1 h>=1,也称作 L p L_p Lp范数,其中的p就是这里的h,只不过这里保留了p作为属性数, p=1时候表示曼哈顿距离( L 1 L_1 L1范数),p=2表示欧氏距离( L 2 L_2 L2范数)
上确界距离( L m a x L_{max} Lmax, L ∞ L_{\infty} L∞范数和切比舍夫距离)
是 h − > ∞ h->\infty h−>∞是闵可夫斯基距离的推广
d ( i , j ) = lim h → ∞ ( ∑ f = 1 p ∣ x i f − x j f ∣ h ) 1 h = max f p ∣ x i f − x j f ∣ d(i,j) = \lim_{h\rightarrow\infty}{(\sum_{f=1}^{p}|x_{if}-x_{jf}|^h)^{\frac{1}{h}}} = \max_f^p{|x_{if}-x_{jf}|} d(i,j)=h→∞lim(f=1∑p∣xif−xjf∣h)h1=fmaxp∣xif−xjf∣
L ∞ L_{\infty} L∞范数又称一致范数
例如,使用相同的数据对象 x 1 = ( 1 , 2 ) x_1 = (1,2) x1=(1,2) 和 x 2 = ( 3 , 5 ) x_2 = (3,5) x2=(3,5),这两个对象的最大值差为 5 - 2 = 3.这是两个对象的上确界距离。
余弦相似度
s i m ( x , y ) = x ⋅ y ∣ ∣ x ∣ ∣ × ∣ ∣ y ∣ ∣ sim(x,y) = \frac{x · y}{||x||\times||y||} sim(x,y)=∣∣x∣∣×∣∣y∣∣x⋅y
其中, ∣ ∣ x ∣ ∣ ||x|| ∣∣x∣∣是向量x的欧几里得范数 x 1 2 + x 2 2 + . . . + x p 2 \sqrt{x_1^2+x_2^2+...+x_p^2} x12+x22+...+xp2,即向量的长度。该度量基于向量x和y之间夹角的余弦,等于0意味着两个向量呈 9 0 o 90^o 90o夹角(正交),没有匹配。
3. 数据预处理
3.1 为什么要进行数据预处理
不正确、不完整和不一致的数据是现实世界的大型数据库和数据仓库的共同特点。数据预处理正是需要解决这样的数据质量问题。
3.2 数据清洗主要解决什么问题
现实世界的数据一般是不完整的、有噪声的和不一致的。数据清洗试图填充缺失的值、光滑噪声并识别离群点、纠正数据中的不一致。
3.3 数据规约
数据规约(data reduction )技术可以用来得到数据集的规约表示,它小得多,但仍接近于保持数据的完整性。
数据规约策略包括
- 维规约(dimensionality reduction)减少所考虑的随机变量的属性的个数。维规约方法包括小波变换和主成分分析,它们把元数据变换或投影到较小的空间。属性子集选择是一种维规约方法,其中不相关、弱相关或冗余的属性或维被检测和删除。
- 数量规约(numerosity reduction)用替代的较小的数据表示形式替换元数据,这些技术可以使参数的也可以是非参数的。对于参数方法而言,使用模型估计数据,使得一般只需要存放模型参数,而不是实际数据,离群点可能要存放,例如回归和对数-线性模型。非参数方法包括直方图、聚类、抽样和数据立方体聚集。
- 数据压缩(data compression)使用变换,以便得到元数据的规约或者压缩表示。如果元数据能够从压缩后的数据重构而不损失信息,则该数据规约成为无损的,否则是有损的。维规约和数量规约也可以视为某种形式的数据压缩。
小波变换
离散小波变换(DWT)是一种线性信号处理技术,用于数据向量 X X X时,将它变换成不同的数值小波系数向量 X ′ X^{'} X′,两个向量具有相同的长度。用于数据规约时,每个元组看成是n维数据向量,即 X = ( x 1 , x 2 , . . . , x n ) X = (x_1,x_2,...,x_n) X=(x1,x2,...,xn) ,描述n个数据库属性在元组上的n个测量值。
如果小波变换后的数据与元数据的长度相等,这种技术如何能够实现数据压缩?关键在于小波变换后的数据可以截短,就能保留近似的压缩数据。例如保留大于设定的某个阈值的所有小波系数,其他系数置0。
DWT与离散傅里叶变换(DFT)有密切关系。一般来说DWT是一种更好的有损压缩,能提供元数据更准确的近似。
离散小波变换的一般过程使用一种层次金字塔算法(pyramid algorithm),它在每次迭代时将数据减半,导致计算速度很快。
- 输入数据向量长度L必须是2的整数幂,必要时补0,满足L>=n
- 每个变换涉及应用两个函数。第一个使用某种数据光滑,如求和或加权平均,第二个进行加权查分,提取数据细节特征。
- 两个函数作用于 X X X中的数据点对,即做用户所有的测量对( x 2 i , x 2 i + 1 x_{2i},x_{2i+1} x2i,x2i+1)。这导致两个长度为L/2的数据集,一般而言,它们粪便代表输入数据的光滑后的版本或低频版本和它的高频内容
- 两个函数递归地作用于前面循环得到的数据集,直到得到的结果数据集的长度为2.
- 由以上迭代得到的数据集中选择的值被指定为数据变换的小波系数。
主成分分析(PCA)
首先介绍方差过滤。如果一个特征的方差很小,则意味着这个特征上很可能有大量取值都相同(比如90%都是1,只有10%是0,甚至100%是1),那这一个特征的取值对样本而言就没有区分度,这种特征就不带有有效信息。从方差的这种应用就可以推断出,如果一个特征的方差很大,则说明这个特征上带有大量的信息。因此,在降维中,PCA使用的信息量衡量指标,就是样本方差,又称可解释性方差,方差越大,特征所带的信息量越多。
PCA作为矩阵分解算法的核心算法,其实没有太多参数,但不幸的是每个参数的意义和运用都很难,因为几乎每个参数都涉及到高深的数学原理。
教材《数据挖掘概念与技术中》进行了简短的定义
基本过程如下:
(1)对输入数据规范化,使得每个属性都落入相同的区间。此步有助于确保具有较大定义域的属性不会支配具有较小定义域的属性。
(2)PCA计算k个标准正交向量,作为规范化输入数据的基。这些是单位向量,每一个方向都垂直于另一个。这些向量称为主成分。输入数据是主成分的线性组合。
(3)对主成分按“重要性”或强度降序排列。主成分基本上充当数据的新坐标轴,提供关于方差的重要信息。也就是说,对坐标轴进行排序,使得第一个坐标轴显示数据的最大方差,第二个显示次大方差,如此下去。例如,图2-17显示原来映射到轴X1和X2的给定数据集的前两个主成分Y1和Y2。这一信息帮助识别数据中的分组或模式。
(4)既然主成分根据“重要性”降序排列,就可以通过去掉较弱的成分(即方差较小)来归约数据的规模。使用最强的主成分,应当能够重构原数据的很好的近似
参考自吴恩达《机器学习》
在PCA中,我们要做的是找到一个方向向量(Vector direction),当我们把所有的数据都投射到该向量上时,我们希望投射平均均方误差能尽可能地小。方向向量是一个经过原点的向量,而投射误差是从特征向量向该方向向量作垂线的长度。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-fzn0ep0w-1669877471579)(https://tva1.sinaimg.cn/large/008eGmZEgy1gmhfaciecrj308c06lmx4.jpg)]
下面给出主成分分析问题的描述:
问题是要将 n n n维数据降至 k k k维,目标是找到向量 u ( 1 ) u^{(1)} u(1), u ( 2 ) u^{(2)} u(2),…, u ( k ) u^{(k)} u(k)使得总的投射误差最小。主成分分析与线性回顾的比较:
主成分分析与线性回归是两种不同的算法。主成分分析最小化的是投射误差(Projected Error),而线性回归尝试的是最小化预测误差。线性回归的目的是预测结果,而主成分分析不作任何预测。

上图中,左边的是线性回归的误差(垂直于横轴投影),右边则是主要成分分析的误差(垂直于红线投影)。
PCA将 n n n个特征降维到 k k k个,可以用来进行数据压缩,如果100维的向量最后可以用10维来表示,那么压缩率为90%。同样图像处理领域的KL变换使用PCA做图像压缩。但PCA 要保证降维后,还要保证数据的特性损失最小。
PCA技术的一大好处是对数据进行降维的处理。我们可以对新求出的“主元”向量的重要性进行排序,根据需要取前面最重要的部分,将后面的维数省去,可以达到降维从而简化模型或是对数据进行压缩的效果。同时最大程度的保持了原有数据的信息。
PCA技术的一个很大的优点是,它是完全无参数限制的。在PCA的计算过程中完全不需要人为的设定参数或是根据任何经验模型对计算进行干预,最后的结果只与数据相关,与用户是独立的。
但是,这一点同时也可以看作是缺点。如果用户对观测对象有一定的先验知识,掌握了数据的一些特征,却无法通过参数化等方法对处理过程进行干预,可能会得不到预期的效果,效率也不高。
以下复习过程如有困惑直接不看吧。
主成分分析算法
PCA 减少 n n n维到 k k k维:
第一步是均值归一化。我们需要计算出所有特征的均值,然后令 x j = x j − μ j x_j= x_j-μ_j xj=xj−μj。如果特征是在不同的数量级上,我们还需要将其除以标准差 σ 2 σ^2 σ2。
第二步是计算协方差矩阵(covariance matrix) Σ Σ Σ:
∑ = 1 m ∑ i = 1 n ( x ( i ) ) ( x ( i ) ) T \sum=\dfrac {1}{m}\sum^{n}_{i=1}\left( x^{(i)}\right) \left( x^{(i)}\right) ^{T} ∑=m1∑i=1n(x(i))(x(i))T第三步是计算协方差矩阵 Σ Σ Σ的特征向量(eigenvectors):
X → Q Σ Q − 1 X\rightarrow QΣQ^{-1} X→QΣQ−1
将特征矩阵X分解为以下三个矩阵,其中 Q Q Q 和 Q − 1 Q^{-1} Q−1是辅助的矩阵,Σ是一个对角矩阵,其对角线上的元素就是方差。。降维完成之后,PCA找到的每个新特征向量就叫做“主成分”,而被丢弃的特征向量被认为信息量很少,这些信息很可能就是噪音。也可以我们可以利用奇异值分解(singular value decomposition)来求解,
[U, S, V]= svd(sigma)。[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-i1KTeRXF-1669877471580)(https://tva1.sinaimg.cn/large/008eGmZEgy1gmhfdsy0hyj30b403u0th.jpg)]
S i g m a = 1 m ∑ i = 1 n ( x ( i ) ) ( x ( i ) ) T Sigma=\dfrac {1}{m}\sum^{n}_{i=1}\left( x^{(i)}\right) \left( x^{(i)}\right) ^{T} Sigma=m1i=1∑n(x(i))(x(i))T
对于一个 n × n n×n n×n维度的矩阵,上式中的 U U U是一个具有与数据之间最小投射误差的方向向量构成的矩阵。如果我们希望将数据从 n n n维降至 k k k维,我们只需要从 U U U中选取前 k k k个向量,获得一个 n × k n×k n×k维度的矩阵,我们用 U r e d u c e U_{reduce} Ureduce表示,然后通过如下计算获得要求的新特征向量 z ( i ) z^{(i)} z(i):
z ( i ) = U r e d u c e T ∗ x ( i ) z^{(i)}=U^{T}_{reduce}*x^{(i)} z(i)=UreduceT∗x(i)其中 x x x是 n × 1 n×1 n×1维的,因此结果为 k × 1 k×1 k×1维度。注,我们不对方差特征进行处理。
而SVD使用奇异值分解来找出空间V,其中Σ也是一个对角矩阵,不过它对角线上的元素是奇异值,这也是SVD中用来衡量特征上的信息量的指标。 U U U和 V T V^{T} VT分别是左奇异矩阵和右奇异矩阵,也都是辅助矩阵。我们使用 U U U这个矩阵为我们构造降维后的特征。
选择主成分的数量
主要成分分析是减少投射的平均均方误差:
训练集的方差为: 1 m ∑ i = 1 m ∥ x ( i ) ∥ 2 \dfrac {1}{m}\sum^{m}_{i=1}\left\| x^{\left( i\right) }\right\| ^{2} m1∑i=1m∥∥x(i)∥∥2
我们希望在平均均方误差与训练集方差的比例尽可能小的情况下选择尽可能小的 k k k值。
如果我们希望这个比例小于1%,就意味着原本数据的偏差有99%都保留下来了,如果我们选择保留95%的偏差,便能非常显著地降低模型中特征的维度了。
我们可以先令 k = 1 k=1 k=1,然后进行主要成分分析,获得 U r e d u c e U_{reduce} Ureduce和 z z z,然后计算比例是否小于1%。如果不是的话再令 k = 2 k=2 k=2,如此类推,直到找到可以使得比例小于1%的最小 k k k 值(原因是各个特征之间通常情况存在某种相关性)。
还有一些更好的方式来选择 k k k,当我们在调用“svd”函数的时候,我们获得三个参数:
[U, S, V] = svd(sigma)。[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-d1b0szFA-1669877471581)(https://tva1.sinaimg.cn/large/008eGmZEgy1gmhfmtw8xwj3065031mx0.jpg)]
其中的 S S S是一个 n × n n×n n×n的矩阵,只有对角线上有值,而其它单元都是0,我们可以使用这个矩阵来计算平均均方误差与训练集方差的比例:
1 m ∑ i = 1 m ∥ x ( i ) − x a p p r o x ( i ) ∥ 2 1 m ∑ i = 1 m ∥ x ( i ) ∥ 2 = 1 − Σ i = 1 m S i i Σ i = 1 k S i i ≤ 1 % \dfrac {\dfrac {1}{m}\sum^{m}_{i=1}\left\| x^{\left( i\right) }-x^{\left( i\right) }_{approx}\right\| ^{2}}{\dfrac {1}{m}\sum^{m}_{i=1}\left\| x^{(i)}\right\| ^{2}}=1-\dfrac {\Sigma^{m}_{i=1}S_{ii}}{\Sigma^{k}_{i=1}S_{ii}}\leq 1\% m1∑i=1m∥∥x(i)∥∥2m1∑i=1m∥∥∥x(i)−xapprox(i)∥∥∥2=1−Σi=1kSiiΣi=1mSii≤1%也就是: Σ i = 1 k s i i Σ i = 1 n s i i ≥ 0.99 \frac {\Sigma^{k}_{i=1}s_{ii}}{\Sigma^{n}_{i=1}s_{ii}}\geq0.99 Σi=1nsiiΣi=1ksii≥0.99
在压缩过数据后,我们可以采用如下方法来近似地获得原有的特征: x a p p r o x ( i ) = U r e d u c e z ( i ) x^{\left( i\right) }_{approx}=U_{reduce}z^{(i)} xapprox(i)=Ureducez(i)

PCA作为压缩算法。在那里你可能需要把1000维的数据压缩100维特征,或具有三维数据压缩到一二维表示。所以,如果这是一个压缩算法,应该能回到这个压缩表示,回到你原有的高维数据的一种近似。
所以,给定的 z ( i ) z^{(i)} z(i),这可能100维,怎么回到你原来的表示 x ( i ) x^{(i)} x(i),这可能是1000维的数组?

PCA算法,我们可能有一个这样的样本。如图中样本 x ( 1 ) x^{(1)} x(1), x ( 2 ) x^{(2)} x(2)。我们做的是,我们把这些样本投射到图中这个一维平面。然后现在我们需要只使用一个实数,比如 z ( 1 ) z^{(1)} z(1),指定这些点的位置后他们被投射到这一个三维曲面。给定一个点 z ( 1 ) z^{(1)} z(1),我们怎么能回去这个原始的二维空间呢? x x x为2维,z为1维, z = U r e d u c e T x z=U^{T}_{reduce}x z=UreduceTx,相反的方程为: x a p p o x = U r e d u c e ⋅ z x_{appox}=U_{reduce}\cdot z xappox=Ureduce⋅z, x a p p o x ≈ x x_{appox}\approx x xappox≈x。如图:

如你所知,这是一个漂亮的与原始数据相当相似。所以,这就是你从低维表示 z z z回到未压缩的表示。我们得到的数据的一个之间你的原始数据 x x x,我们也把这个过程称为重建原始数据。
3.4 通过规范化变换数据
令A是数值属性,具有n个观测值 v 1 , v 2 , . . . , v n v_1,v_2,...,v_n v1,v2,...,vn
最小-最大规范化
把A的值 v i v_i vi映射到**新的区间 [ n e w _ m i n A , n e w _ m a x A ] [new\_min_{A},new\_max_{A}] [new_minA,new_maxA]**中的 v i ′ v_i^{'} vi′
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-p5wIRgZX-1669877471581)(https://tva1.sinaimg.cn/large/008eGmZEgy1gmhgrj9wf7j312g07m0ug.jpg)]
z分数(z-score)规范化
或零均值规范化,属性 A ˉ \bar{A} Aˉ的值基于 A A A的均值和标准差规范化
v ′ = v i − A ˉ δ A v^{'} = \frac{v_i - \bar{A}}{\delta_{A}} v′=δAvi−Aˉ
小数定标规范化
通过移动属性A的值的小数点位置进行规范化。小数点的移动位数依赖于A的最大绝对值,A的值 v i v_i vi被规范化为 v i ′ v_i^{'} vi′,又下式计算
v i ′ = v i 1 0 j v_i^{'} = \frac{v_i}{10^j} vi′=10jvi
j是使得 max ( ∣ v i ′ ∣ ) < 1 \max(|v_i^{'}|) < 1 max(∣vi′∣)<1的最小整数
4 数据仓库
基本概念:
-
cell**(单元格)cuboid(方体)cube(立方体)**
-
数据立方体:维度,度量,格
-
度量:分布的、代数的、整体的
基本操作(上卷、下钻、切片、切块)
数据立方体物化
- 全物化,半物化
- 聚集路径的选择,优化 (例题)
4.1 数据立方体(data cube )
允许以多维对数据建模和观察,由维和事实定义。
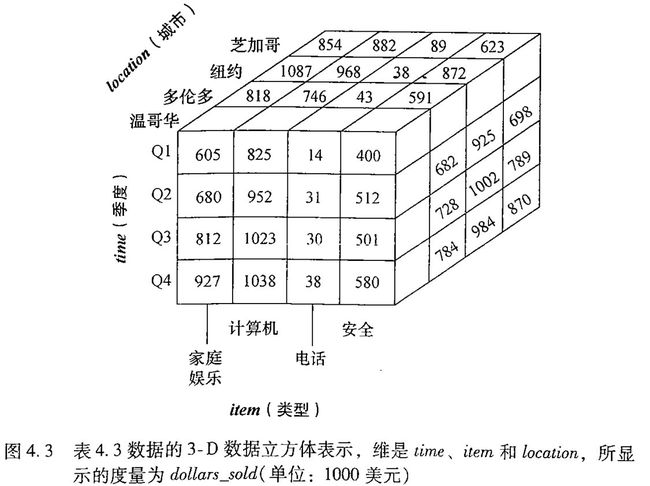
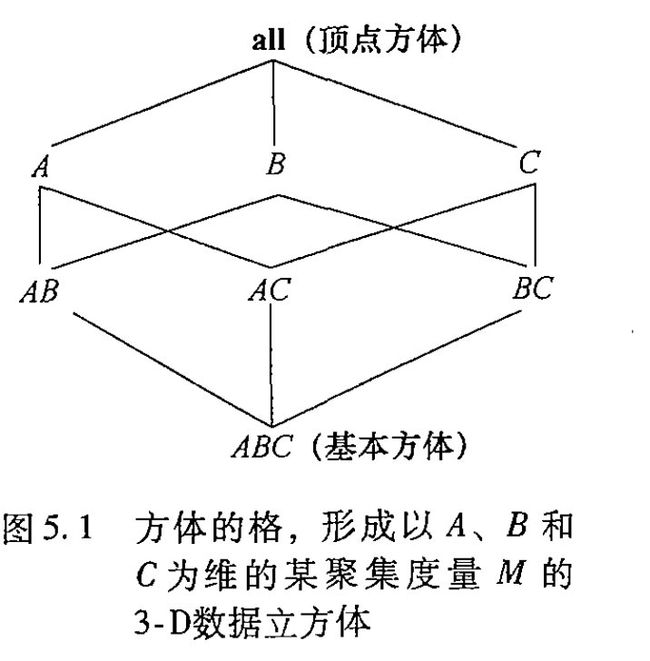
图4.3所示的数据立方体叫做方体(cubiod),我们对给定的诸维的每个可能的子集产生一个方体,结果形成一个个的格(cell),这个格就是一个个具体的数值的在立方体中的体现。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-5aJRUJIw-1669877471582)(https://tva1.sinaimg.cn/large/008eGmZEgy1gmhi07jhboj315c0nkafn.jpg)]
上图中,每个方体代表一个不同程度的汇总,存放最底层汇总的方体叫做基本方体,上图是4-D方体,逐渐往上是3-D方体;0-D方体存放最高层的汇总,叫做顶点方体,通常用all表示。
4.2 多维数据模式
星形模式
最常见的模型范式,其中数据仓库包括
- 一个大的中心表(事实表),包含大批数据且不含冗余
- 一组小的附属表(维表)每维一个,可以在这里有冗余
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-XtXwg3Gq-1669877471582)(https://tva1.sinaimg.cn/large/008eGmZEgy1gmhiee4zp0j312w0o2q7u.jpg)]
雪花模式
星形模式的变种,不同之处在于雪花模式的维表可能是规范化形式,以便减少冗余。这种表易于维护且节省存储空间,但是查询需要更多连接操作,可能降低性能。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-j2bzECjd-1669877471583)(https://tva1.sinaimg.cn/large/008eGmZEgy1gmhighfbv5j31600ok7a1.jpg)]
事实星座
复杂的应用,可能需要多个事实表共享维表,这种模式可以看做星形模式的汇集,

上图中有两个事实表sales和shipping,共享了维表time,item,location
4.3 概念分层
定义一个映射序列,将低层概念集映射到较高层

4.4 度量的分类和计算
立方体的度量是一个数值函数,可以对立方体的空间的每个点求值。
根据聚集函数可以分成三类:分布的(distributice)、代数的(algebraic)、整体的(holistic)
-
分布式的
如果一个聚集函数可以用于分布式的计算,将数据划分成n个集合,将函数用于每个部分,得到n个聚集值,得到的结果和用函数作用于整个数据集的结果一样的话,该函数可以用于分布式计算。如 sum(),count(),min(),max()。一个度量如果可以用分布聚集函数得到,则它是分布式的
-
代数的
一个聚集函数能够用一个具有M个参数的代数函数计算,而每个参数都可以用一个分布聚集函数求得,则他是代数的。如avg(),可以用sum()/count(), min_N()、max_N() (找到N个最小最大值), standard_deviation()。一个度量如果可以用代数聚集函数得到,则它是代数的。
-
整体的
一个聚集函数如果描述它的自己所需的存储没有一个常数界,则它是整体的。也即,不存在一个具有M个参数的代数函数进行这一计算。如 median()、mode()和rank()。一个度量如果用整体聚集函数得到的,则它是整体的。
4.5 典型的OLAP操作
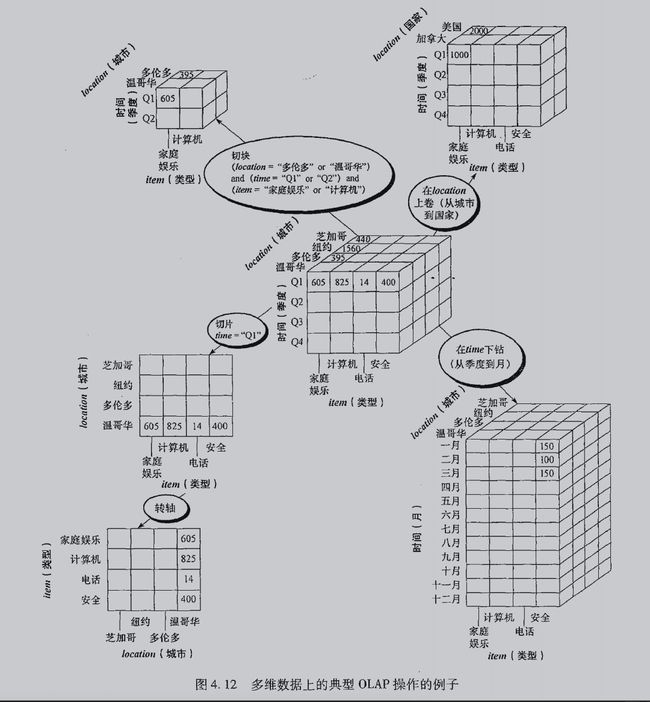
上卷(roll-up)/ 上钻(drill-up)
通过沿一个维的概念分层向上攀升或者通过维规约在数据立方体上进行聚集
下钻(drill-down)
是上卷的逆操作,它由不太详细的数据得到比较详细的数据。通过沿维的概念分层向下或引入附加的维来实现。
切片(slice)
在给定的立方体的一个维上进行选择,定义子立方体。
切块
通过在两个或多个维上进行选择,定义子立方体。
转轴(pivot)/旋转(rotate)
转动数据的视角,提供数据的替代显示
4.6 数据立方体的物化
compute cube 操作和维灾难
Compute cube操作在指定的维的所有子集上计算聚集。可能需要很大的存储空间。
对于n维立方体的方体总数为 2 n 2^n 2n。
全物化
预先计算所有的方体。通常需要海量的存储。
部分物化
有选择地计算整个可能的方体集中一个适当的子集。
冰山立方体
只存放其聚集值如(count)大于某个最小支持度阈值的立方体单元。这个阈值为最小支持度。
基本单元和聚集单元
基本方体的单元是基本单元,非基本方体的单元是聚集单元。基本方体泛化程度最低,逐层提高,最高的是顶点放图all。
数据立方体其实就是在大量的多维数据中,进行了一个group by的操作,使得数据能够按照一定的规则聚集起来,从而形成一些小的立方体,继而观察各种聚集的值。
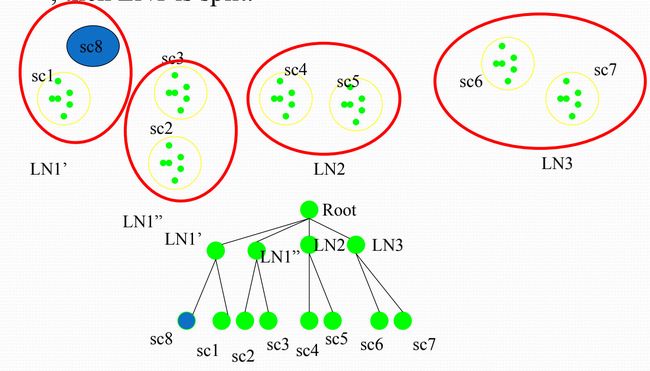
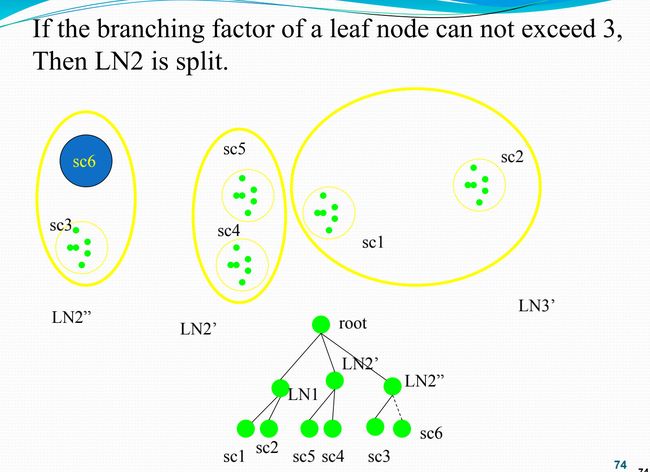
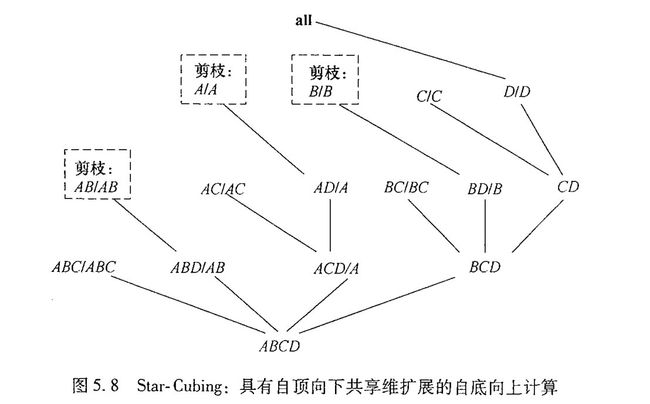
聚集单元在一个或多个维度上聚集,其中每个聚集维用单元记号中的 “*” 表示。假设我们有一个n维数据立方体。 令 a = ( a 1 , a 2 , . . . , a n , m e a s u r e s ) a = (a_1,a_2,...,a_n,measures) a=(a1,a2,...,an,measures)是一个单元,取自构成数据立方体的一个方体,如果 a 1 , a 2 , . . . , a n {a_1,a_2,...,a_n} a1,a2,...,an恰有 m ( m < = n ) m(m<=n) m(m<=n)个值不是**“*”**,则我们说 a a a是m维单元。m=n是基本单元,m 单元之间存在祖先后代的关系。在这里我们说一个 i − D i-D i−D单元是一个 j − D j-D j−D单元的祖先,当且仅当 i < j i 对于 1 ≥ k ≥ n 1 \geq k \geq n 1≥k≥n,只要 a k ≠ ∗ a_k \neq * ak=∗,就有 a k = b k a_k = b_k ak=bk,特别地, a a a是 b b b的父母,且 b b b是 a a a的子女,当且仅当 j = i + 1 j=i+1 j=i+1。 祖先是后代在某些维上的上卷操作,不考虑某些维或某些维已被上卷;而后代,则是祖先在某些唯上的下钻操作,更细致的去考虑某些维。因此祖先是后代的泛化,后代是祖先的具体。 一个单元 c 是闭单元,如果不存在单元d,使得 d 是单元 c 的后代,即d通过将 c 的 * 用非“*”值替换能得到,且d和c有相同的度量。闭立方体是一个仅由闭单元组成的数据立方体。 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-hBtfA38N-1669877471584)(https://tva1.sinaimg.cn/large/008eGmZEgy1gmkkz89inlj30om0gogmz.jpg)] 部分物化的另一个策略是只预计算涉及少数维的方体,这些方体形成对应数据立方体的立方体外壳,在附加的维组合上的查询必须临时计算。 多路数组聚集(MultiWay)方法使用多维数组作为基本的数据结构,计算完全数据立方体。MultiWay是一种使用数组直接寻址的典型MOLAP方法,其中维值通过位置或对应数组位置的下标访问,不能使用基于值的重新排序作为优化技术。基于数组的立方体结构构造方法: a.把数组分成块。块是一个子立方体,足够小,可以放入立方体计算时可用的内存。分块是一种把n维数组划分成小的n维块的方法,其中每个块作为一个对象存放在磁盘上。块被压缩,以避免空数组单元所导致的空间浪费。一个单元为空,如果它不含有任何有效数据(其单元计数为零)。如为了压缩稀疏数组结构,在块内搜索单元时可以用chunkID+offset作为单元的寻址机制。 b.通过访问立方体单元(即访问立方体单元的值)来计算聚集。可以优化访问单元的次序,使得每个单元必须重复访问的次数最小化,从而减少内存访问开销和存储开销。技巧是使用这样的一种次序,使得多个方体的聚集单元可以同时计算,避免不必要的单元再次访问。 由于分块技术涉及重叠某些聚集计算,因此称该技术未多路数组聚集(multiway array aggregation),执行同时聚集,即同时在多个维组合上计算聚集。 MultiWay使用直接数组寻址,比ROLAP基于关键字的寻址搜索策略快,不过MultiWay计算从基本方体开始,逐步向上到更泛化的祖先方体,因此不能利用先验剪枝。 计算方法 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-x844q50P-1669877471584)(https://tva1.sinaimg.cn/large/008eGmZEgy1gmkoobimjpj319m0lix35.jpg)] 根据前提条件,如果我们按顺序从1到64依次扫描,BC、AC、AB各有16个块,聚集 b 0 c 0 b_0c_0 b0c0块需要扫描 1-4块,聚集 a 0 c 0 a_0c_0 a0c0则需要扫描1-13块,也就是扫描1、5、7、13块,而对于 a 0 , b 0 a_0,b_0 a0,b0就需要扫描49块才能聚集了。 我们来计算一下按顺序扫描的话的内存消耗,A、B、C的大小分别为40、400、4000,因此最大的2-D平面是BC(400x4000 = 1600000),AC(40x400=160000),AB(40x400 = 16000)。按顺序扫描的时候,扫描ABC方体的块1到块4的行,就能聚集一个BC方体的块,相对的,AB需要扫描的块最多。我们的目的是节省内存,则显然我们需要尽可能少的扫描最大的平面。 为了避免把1个3-D块多次调入内存,我们在块内存中维持所有相关2-D平面所需的最小内存单位为: 40 x 400(用于整个AB平面) + 40 x 1000(用于AC平面的一行)+100x1000(用于BC平面的一块) = 156000个内存单位 整个扫描顺序就是先聚集BC,再是 AC,再是AB。 如果我们换一种次序,假设顺序为1、17、33、49、5、21、37、53等,也就是先向AB平面,然后向AC平面,最后向BC平面聚集,则需求量为 400 x 4000(用于整个BC平面) + 10 x 4000(用于AC平面的一行) +10 x 100(用于AB平面的一块) = 1641000个单位 上图演示了我们如何从ABC聚集到ALL,图从自底向上看,每次聚集都由所需内存小的上一方体聚集。一开始AB、AC、BC都由ABC聚集而成,由于AB所需内存最小,则A 和B 由AB聚集而成,C由AC聚集而成,ALL由A聚集而成 BUC是一种计算稀疏冰山立方体的算法。和MultiWay不同,BUC从顶点方体向下到基本方体构造冰山立方体,这使得BUC可以分担数据划分开销,这种处理次序也使得BUC在构造立方体时使用先验性质进行剪枝。 方体格一般采用顶点方体在顶部基本方体在底部的表示,将下钻(从高聚集单元向较低、更细化的单元移动)和上卷(从细节的、低层单元向较高层、更聚集的单元移动)概念一致起来。BUC是指自底向上构造(Bottom-Up Construction),BUC作者采用顶点方体在底部而基本方体在顶部的表示,这样看BUC确实是自底向上的。在这里,下钻表示从顶点方体向下到基本方体,所以我们将BUC的探查过程视为自顶向下(这里的下钻方向就反过来了)。 不用细看 Star-Cubing集成自顶向下和自底向上立方体计算,并利用多维聚集(类似MultiWay)和类Apriori剪枝(类似BUC),在一个称为星树(star-tree)的数据结构上操作,对该数据结构进行无损数据压缩,从而降低计算时间和内存需求量。 Star-Cubing算法利用自底向上和自顶向下的计算模式:在全局计算次序上,使用自底向上模式;同时有一个基于自顶向下模式的子层,利用共享维的概念。如果共享维上的聚集值不满足冰山条件,则沿该共享维向下的所有单元也不可能满足冰山条件。 共享维:ACD/A意味方体ACD具有共享维A,ABD/AB意味着方体ABD具有共享维AB,ABC/ABC意味方体ABC具有共享维ABC等。 这源于泛化,在以ACD为根的所有子树中的所有方体都包含维A,在以ABD为根的所有子树中的所有方体都包含维AB,在以ABCX为根的所有子树中的所有方体都包含维ABC(尽管只有一个),我们称这些公共维为特定子树的共享维(shared dimension) 几个概念:方体数、星节点、星树 方体树(cuboid tree),树的每一层代表一个维,每个结点代表一个属性值;每个结点有四个字段:属性值、聚集值、指向第一个子女的指针和指向第一个兄弟的指标;方体中的元组逐个插入组中,一条从根到树叶结点的路径代表一个元组。如果单个维在属性值p上的聚集不满足冰山条件,则在冰山立方体计算中识别这样的节点没有意义。这样的结点p用*替换,使方体树可以进一步压缩。 如图所示基本方体ABCD的方体树片段, c 2 c_2 c2具有聚集(计数)值5,表示 ( a 1 , b 1 , c 2 , ∗ ) (a_1,b_1,c_2,*) (a1,b1,c2,∗)有5个单元。这种表示合并了公共前缀,节省内存并允许聚集内部结点上的值。利用内部结点上的聚集值,可以进行基于共享维的剪枝,例如AB的方体树可以用来对ABD的可能单元进行剪枝。 星节点和星树:如果单个维p上的聚集不满足冰山条件,则称属性A中的结点p是星结点(star node);否则,称p为非星结点(non-star node)。使用星结点压缩的方体树称为星树(star-tree)。 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-yXgUGyw6-1669877471585)(https://tva1.sinaimg.cn/large/008eGmZEgy1gmkzqiqwrvj31n60u0dxo.jpg)] [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Ec3NX5fG-1669877471585)(https://tva1.sinaimg.cn/large/008eGmZEgy1gmkupdxhy0j31630u04qp.jpg)] 第一问,问立方体有几个非空的方体,就是最底层是10维的基本方体,一层一层聚集上去之后,一共有几个,是 2 10 2^{10} 210个。我们题目给的数据是基本方体的具体的格,两者是一种概念和实体的关系。 第二问,求非空的经过3个基本格聚集的格有多少个。题目给的格在数据立方体中是基本方体,每个格可以向上聚集 2 10 − 1 2^{10}-1 210−1个格,即将其中的数据p一个个的变成*。总的格数为 3 × 2 10 − 3 3\times2^{10}-3 3×210−3。 往上聚集时候必会有重叠的部分,相异的部分一定在前三个确定的情况下,其中前三个为*的可以分别由三个基本单元格聚集而成,它们的度量值为3,每个出现了 2 7 2^7 27次,因此需要减掉 2 × 2 7 2 \times 2^7 2×27个单元格即 ( ∗ , ∗ , ∗ , d 4 , . . . , d 10 ) (*,*,*,d_4,...,d_{10}) (∗,∗,∗,d4,...,d10),;另外 ( ∗ , d 2 , ∗ , . . . , ∗ ) 、 ( d 1 , ∗ , . . . , ∗ ) 、 ( ∗ , ∗ , d 3 , ∗ , . . . , ∗ ) (*,d_2,*,...,*)、(d_1,*,...,*)、(*,*,d_3,*,...,*) (∗,d2,∗,...,∗)、(d1,∗,...,∗)、(∗,∗,d3,∗,...,∗)各出现了两次合计度量值为6,则只取出现的1次,所以还要减掉 3 × 2 7 3\times2^7 3×27个单元格。 所以总的单元格为 3 × 2 10 − 3 − 2 × 2 7 − 3 × 2 7 3\times2^{10}-3 - 2 \times 2^7 - 3\times2^{7} 3×210−3−2×27−3×27 第三问,求聚集单元格大于等于2的数量,由第二问知, ( ∗ , d 2 , ∗ , . . . , ∗ ) 、 ( d 1 , ∗ , . . . , ∗ ) 、 ( ∗ , ∗ , d 3 , ∗ , . . . , ∗ ) (*,d_2,*,...,*)、(d_1,*,...,*)、(*,*,d_3,*,...,*) (∗,d2,∗,...,∗)、(d1,∗,...,∗)、(∗,∗,d3,∗,...,∗)符合,它们各出现两次, ( ∗ , ∗ , ∗ , d 4 , . . . , d 10 ) (*,*,*,d_4,...,d_{10}) (∗,∗,∗,d4,...,d10)出现了三次,也符合,所以一共有 4 × 2 7 4\times2^7 4×27。 第四问,一个单元 c 是闭单元,如果不存在单元d,使得 d 是单元 c 的后代,即d通过将 c 的 * 用非“*”值替换能得到,且d和c有相同的度量。闭立方体是一个仅由闭单元组成的数据立方体。闭单元要和祖先和后代单元的概念结合看。 本题问在全物化的数据立方体中闭单元的个数,则是答案中的7个。首先三个基本单元是闭单元,对于 ( ∗ , ∗ , d 3 , d 4 , . . . , d 10 ) (*,*,d_3,d_4,...,d_{10}) (∗,∗,d3,d4,...,d10) ( ∗ , d 2 , ∗ , d 4 , . . . , d 10 ) (*,d_2,*,d_4,...,d_{10}) (∗,d2,∗,d4,...,d10) ( d 1 , ∗ , ∗ , d 4 , . . . , d 10 ) (d_1,*,*,d_4,...,d_{10}) (d1,∗,∗,d4,...,d10)而言,度量值为2,当用 a或b或c去替换对应的*,度量值都变了,变成了1,最后一个单元格 ( ∗ , ∗ , ∗ , d 4 , . . . , d 10 ) (*,*,*,d_4,...,d_{10}) (∗,∗,∗,d4,...,d10)度量值为3,用a或b或c去替换*,度量值也变了,变成了1,因此也是闭单元格。 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Gnk0mcCQ-1669877471585)(https://tva1.sinaimg.cn/large/008eGmZEgy1gml32dbq8lj31af0u0th7.jpg)] [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-KiGpEhRJ-1669877471585)(https://tva1.sinaimg.cn/large/008eGmZEgy1gmkzr3uxwtj315q0u044c.jpg)] 对于©的多路计算,自底向上计算,AC数量级最大,AB次之,BC最小,因此B和C由BC聚集,A由AB聚集 支持度和置信度的定义和计算 K-项集 极大频繁项集、闭频繁项集的概念 频繁模式是频繁地出现在数据集中的模式(如项集、子序列、或子结构)。 支持度: s u p p o r t ( A ⇒ B ) = P ( A ∪ B ) support(A \Rightarrow B) = P(A \cup B) support(A⇒B)=P(A∪B) 即A和B这两个项集在事务集D中同时出现的概率 置信度: c o n f i d e n c e ( A ⇒ B ) = P ( B ∣ A ) confidence(A \Rightarrow B) = P(B \mid A ) confidence(A⇒B)=P(B∣A) 即在出现项集A的事务集D中,项集B也同时出现的概率。 同时满足最小支持度阈值(min_sup)和最小置信度阈值(min_conf)的规则称为强规则,为方便计算 用0%~100%来计算而不是0~1.0。 上面的支持度公式又是被成为相对支持度,而项集出现的频度,也就是计数称为绝对支持度。 项的合集称为项集,包含k个项的项集称为k项集。项集的出现频度是项集的事务数,也就是数它出现的次数。 如果项集 I I I的相对支持度满足最小支持度阈值,换句话说 I I I的绝对支持度满足对应的最小支持度计数阈值,则 I I I是频繁项集。频繁k项集通常记为 L k L_k Lk c o n f i d e n c e ( A ⇒ B ) = P ( B ∣ A ) = s u p p o r t ( A ∪ B ) s u p p o r t ( A ) = s u p p o r t c o u n t ( A ∪ B ) s u p p o r t c o u n t ( A ) confidence(A \Rightarrow B) = P(B \mid A ) = \frac{support(A\cup B)}{support(A)} = \frac{support_count(A \cup B)}{support_count(A)} confidence(A⇒B)=P(B∣A)=support(A)support(A∪B)=supportcount(A)supportcount(A∪B) 如果一个项集是频繁的,那么它的子集也是频繁的。一个长的项集包含组合个数较短的频繁子项集。 以啤酒尿布为例, 设置最小支持度和最小置信度为50%, 频繁模式有: Beer:3,Nuts:3,Diaper:4,Eggs:3,{Beer,Diper}:3 关联规则:(支持度,置信度) 括号中的前者是 A和B一起出现的概率,后者是A出现时候B也出现的概率。 B e e r ⇒ D i a p e r ( 60 % , 100 % ) Beer \Rightarrow Diaper (60\% ,100\%) Beer⇒Diaper(60%,100%) D i a p e r ⇒ B e e r ( 60 % , 75 % ) Diaper \Rightarrow Beer (60\%,75\%) Diaper⇒Beer(60%,75%) 上面的 如果不存在真超项集Y使得Y与X在S中有相同的支持度计数,则称项集X在数据集S中是闭的。项集X是数据集S中的闭频繁项集(closed pattern)。 这里的真超项集,就是类似与我们的真子集。 Y是X的真超项集,如果X是Y的真子项集,即如果 X ⊂ Y X \subset Y X⊂Y,X中的每一项都在Y中,而Y中至少比X多一个项。 所以闭频繁项集就是闭的+频繁的,这两个要求。 如果X是频繁的,并且不存在超集Y,使得 X ⊂ Y X \subset Y X⊂Y且Y在D中是频繁的,则项集X是D中的极大频繁项集,或极大项集(max pattern)。 频繁项集是最大频繁项集的子集。最大频繁项集中包含了频繁项集的频繁信息,且通常项集的规模要小几个数量级。所以在数据集中含有较长的频繁模式时挖掘最大频繁项集是非常有效的手段。 简单点说:如果这个itemset增加任何一个item它的支持度计数都会变低,那么它就是闭频繁项集。极大频繁项集就是增加任何一个item,他的支持度计数不仅会变低还会低于最小支持度计数的阈值。所以极大频繁项集一定是闭频繁项集,closed patterns不一定是max patterns。 栗子: 因为项集{b,c}出现在TID为1,2,3的事务中,所以{b,c}的支持度计数为3。而{b,c}的直接超集:{a,b,c}的支持度计数为2,都不等于{b,c}的支持度计数3,所以{b,c}为闭项集,如果支持度阈值为40%,则{b,c}也为闭频繁项集。 项集{a,b}出现在TID为1,2的事务中,其支持度计数为2。而它的直接超集{a,b,c}支持度计数也为2,所以{a,b}不是闭项集。 频繁项集的所有非空子集也一定是频繁的。 一个集合不是频繁的,它的所有超集也不是频繁的,则称它为反单调的。 首先,找出所有的频繁项集,即所有符合最小支持度的项集。再从频繁项集中找出符合最小置信度的项集,最终便得到有强规则的项集(即我们所需的项的关联性)。 还是用一个例子来理解 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-XkiNGUJf-1669877471586)(https://tva1.sinaimg.cn/large/008eGmZEgy1gmm0bljpbjj31ko0ditay.jpg)] [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-kpVfnypb-1669877471586)(https://tva1.sinaimg.cn/large/008eGmZEgy1gmm0btstc0j314f0u012s.jpg)] 假设最小支持度计数为2,对应的相对支持度为2/9=22%。 每个项都是候选1项集的集合C1的成员。算法扫描所有的事务,获得每个项,生成C1。然后对每个项进行计数。然后根据最小支持度从C1中删除不满足的项,从而获得频繁1项集L1。 对L1的自身连接生成的集合执行剪枝策略产生候选2项集的集合C2,然后,扫描所有事务,对C2中每个项进行计数。同样的,根据最小支持度从C2中删除不满足的项,从而获得频繁2项集L2。 对L2的自身连接生成的集合执行剪枝策略产生候选3项集的集合C3,然后,扫描所有事务,对C3每个项进行计数。同样的,根据最小支持度从C3中删除不满足的项,从而获得频繁3项集L3。 进行自连接时候如何生成C3项集中 { I 1 , I 2 , I 3 } \{I1,I2,I3\} {I1,I2,I3},它的二项子集为 { I 1 , I 2 } 、 { I 2 , I 3 } 、 { I 1 , I 3 } \{I1,I2\}、\{I2,I3\}、\{I1,I3\} {I1,I2}、{I2,I3}、{I1,I3}, L2中有它全部的二项子集,这样才能自连接生成 { I 1 , I 2 , I 3 } \{I1,I2,I3\} {I1,I2,I3}。 以此类推,对Lk-1的自身连接生成的集合执行剪枝策略产生候选k项集Ck,然后,扫描所有事务,对Ck中的每个项进行计数。然后根据最小支持度从Ck中删除不满足的项,从而获得频繁k项集。 上面每一步得到 L k + 1 L_{k+1} Lk+1都由 L k L_{k} Lk自连接,得到k+1项集 上述过程apriori做了两个动作,连接和剪枝,剪枝就是利用先验性质删除具有非频繁子集的候选。 量化关联规则(对Apriori算法的简单扩展,了解原理) Apriori算法有两个问题 因此提出了一种可以挖掘全部频繁项集而无需很高代价的候选产生过程——频繁模式增长(Frequent-Pattern Growth,FP-growth) 采取如下分治策略:将提供频繁项集的数据库压缩到一棵频繁模式树(FP-tree),但仍保留项集关联信息。 将事务数据表中的各个事务数据项按照支持度排序后,把每个事务中的数据项按降序依次插入到一棵以 NULL为根结点的树中,同时在每个结点处记录该结点出现的支持度 栗子: [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-WH1Yfl1H-1669877471586)(https://tva1.sinaimg.cn/large/008eGmZEgy1gmm2xpqvodj31fg0meds3.jpg)] 第一步操作和Apriori相同,扫描一遍数据库,构造频繁1项集,得到它们的支持度计数,按照支持度计数递减排序,这个表记为 L L L。 第二步构造FP-Tree。第二次扫描数据库D,每个事务的项都按L中的次序进行处理,即按递减的支持度j计数排序,并对每个事物创建一个分支。 例如,第一个事务“T100:I1,I2,I5”的三个项按照L中的次序排序为“I2,I1,I5”,导致构造树的包含三个节点的第一个分支 < I 2 : 1 > 、 < I 1 : 1 > 、 < I 5 : 1 > 然后是第二个事务T200,按L的次序包含I2和I4,它导致了一个分支,I4链接到I2,I4计数为1,I2计数增加1,变成2。 然后是第三个事务。。。以此类推。 当为一个事务考虑增加分支时候,沿共同前缀上的每个结点的计数增加1,为前缀之后的项创建结点和链接。 同时为了方便树的遍历,创建了个项表头,增加了一列结点链,表中的结点链指向它在树中的位置,同时相同的结点也链接起来。 条件模式基:包含FP-Tree中与后缀模式一起出现的前缀路径的集合 条件树:将条件模式基按照FP-Tree的构造原则形成的一个新的FP-Tree FP的挖掘过程,由长度为1的频繁模式(初始后缀模式)开始,就是上面FP树中计数为1的叶子节点,构造它的条件模式基(由改后缀模式一起出现的前缀路径集组成),然后构造它的条件FP树,并递归地在该树上挖掘,模式增长通过后缀模式与条件FP树产生的频繁模式连接实现。 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Gqgf50Rv-1669877471586)(https://tva1.sinaimg.cn/large/008eGmZEgy1gofy38oakaj31ew0swe0x.jpg)] 首先考虑I5,因为它是L中的最后一项,I5出现在FP树的两个分支中,路径是 < I 2 , I 1 , I 5 : 1 > 然后是计算I4、I3、I1,最后得到频繁模式。下图是构造的I3的条件FP树,I3的条件模式基是{ {I2,I1:2}, {I2:2} , {I1:2}},它的条件fp树有两个分支 < I 2 : 4 , I 1 : 2 > 如何构造条件FP树? 可以看到,上面构造条件FP树的时候是还是先计算一项集的支持度计数,然后构造一棵FP树。这个条件FP树其实还是原来FP树的一部分。构建频繁一项集并排序之后,第二步扫描数据库,我们扫描前缀加后缀的项集,并把不满足最小支持度计数的删除,构成新的项集,然后构造条件FP树。例如 I5项,扫描了 < I 2 , I 1 , I 5 > , 和 < I 2 , I 1 , I 3 , I 5 > (猜测)为什么说是条件就在于我们舍弃了不满足最小支持度计数的项。 如何产生条件模式基的频繁模式? 就是将该项插入这些分支,一个个的递归这个条件FP树,构造频繁2-项集、······ 、频繁K-项集,这个K就是加上当前项后的最长的路径长度。 最后构成的频繁项集还是包括1-项集的,这在生成L表时候已经构建完成了。 分类的数据分析任务中,需要构建一个模型或者分类器(classifer)来预测类标号。 数据分类是一个两阶段的过程,包括学习阶段(构建分类模型)和分类阶段(使用模型预测给定数据的类标号)。 学习阶段 分类算法通过从训练集中学习来构造分类器。训练集由数据库元组和它们相关联的类标号组成。 元组 X X X是用n维属性向量表示, X = ( x 1 , x 2 , . . . , x n ) X = (x_1,x_2, ... ,x_n) X=(x1,x2,...,xn),每个元组都属于一个预先定义的类,即确定一个类标号属性。这些元组也叫做样本、实例、数据点或对象。 提供了类标号的的学习也叫监督学习。(分类是监督学习,聚类是无监督学习) 分类的任务就是学习一个从元组到类别的映射 y = f ( X ) y = f(X) y=f(X),给定一组数据 X X X,输出类标号 y y y。 分类阶段 用第一阶段的模型进行分类,首先要在验证集上预测分类器的准确率,如果认为分类器的准确率是可以接受的,那么就可以用它对类标号未知的数据元组进行分类。 决策树是一种图结构,给定一个类标号未知的元组 X X X,在决策树上问一系列问问题,得到一条从根节点到叶子节点的路径,每个叶子节点都是一个类标签 算法的核心是解决两个问题: 决策树执行贪心策略,通过实现局部最优来达到接近全局最优结果。 优点 (1)速度快: 计算量相对较小, 且容易转化成分类规则. 只要沿着树根向下一直走到叶, 沿途的分裂条件就能够唯一确定一条分类的谓词. 缺点: 如果数据集D种所有的数据都属于一个类, 那么将该节点标记为叶子节点. 如果数据集D中包含属于多个类的训练数据, 那么选择一个属性将训练数据划分为较小的子集, 对于测试条件的每个输出, 创建一个子节点, 并根据测试结果将D中的记录分布到子节点中, 然后对每一个子节点重复1,2过程, 对子节点的子节点依然是递归地调用该算法, 直至最后停止. 这里涉及不纯度的概念 决策树的每个叶子节点中都会包含一组数据,在这组数据中,如果有某一类标签占有较大的比例,我们就说叶子节点“纯”,分枝分得好。某一类标签占的比例越大,叶子就越纯,不纯度就越低,分枝就越好。 如果没有哪一类标签的比例很大,各类标签都相对平均,则说叶子节点”不纯“,分枝不好,不纯度高。 分类型决策树在叶子节点上的决策规则是少数服从多数,在一个叶子节点上,如果某一类标签所占的比例较大,那所有进入这个叶子节点的样本都回被认为是这一类别。 如何计算不纯度? 其实是由误差率衍生而来 C l a s s i f i c a t i o n e r r o r ( t ) = 1 − max i = 1 [ p ( i ∣ t ) ] Classification error(t) = 1 - \max_{i=1}[p(i|t)] Classificationerror(t)=1−maxi=1[p(i∣t)] 信息熵 误差率越低,则纯度越高。由此还衍生出了其他两个常用指标,一个是ID3中Informationgain(信息增益)的计算方法可用Entropy推导,即最为人熟知的信息熵,又叫做香农熵,其计算公式如下: E n t t r o p y ( t ) = − ∑ i = 0 c − 1 p ( i ∣ t ) l o g 2 p ( i ∣ t ) Enttropy(t) = - \sum_{i=0}^{c-1}p(i|t)log_2p(i|t) Enttropy(t)=−i=0∑c−1p(i∣t)log2p(i∣t) 注意前面有个负号,等价于 $Enttropy(t) = \sum_{i=0}^{c-1}p(i|t)log_2{(\frac{1}{p(i|t)})} $ 其中c表示叶子节点上标签类别的个数,c-1表示标签的索引。注意在这里,是从第0类标签开始计算。设定 l o g 2 0 = 0 log_20 = 0 log20=0。 Gini(基尼指数) 另一个指标则是Gini(基尼)指数,主要用于CART决策树的纯度判定中,其计算公式如下: 举例 假设在二分类问题中各节点呈现如下分布,则可进一步计算上述三指数的结果 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-nQgRxcBb-1669877471587)(https://tva1.sinaimg.cn/large/008eGmZEgy1goelvocjtzj313s0nqaiz.jpg)] 能够看出,三种方法本质上都相同,在类分布均衡时(即当p=0.5时)达到最大值,而当所有记录都属于同一个类时(p等于1或0)达到最小值。换而言之,在纯度较高时三个指数均较低,而当纯度较低时,三个指数都比较大,且可以计算得出,熵在0-1区间内分布,而Gini指数和分类误差均在0-0.5区间内分布,三个指数随某变量占比增加而变化的曲线如下所示: [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-csMEIb6E-1669877471587)(https://tva1.sinaimg.cn/large/008eGmZEgy1goelwvqffej30wo0ke0xj.jpg)] 决策树最终的优化目标是使得叶节点的总不纯度最低,即对应衡量不纯度的指标最低。 ID3 ID3采用信息熵来衡量不纯度,此处就先以信息熵为例进行讨论。ID3最优条件是叶节点的总信息熵最小,因此ID3决策树在决定是否对某节点进行切分的时候,会尽可能选取使得该节点对应的子节点信息熵最小的特征进行切分。换而言之,就是要求父节点信息熵和子节点总信息熵之差要最大。对于ID3而言,二者之差就是信息增益,即Information gain。 假设现在有如下数据集,是一个消费者个人属性和信用评分数据,标签是”是否会发生购买电脑行为“,仍然是个二分类问题,在此数据集之上我们使用ID3构建决策树模型,并提取有效的分类规则。 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-rLPW7yam-1669877471587)(https://tva1.sinaimg.cn/large/008eGmZEgy1goemjj1sb7j31560lkk3k.jpg)] D就是我们的根节点,Info(D)就是计算它的信息熵,用 I ( s 1 , s 2 ) I(s_1,s_2) I(s1,s2)表示,其中s下标1和2代表两个分类水平,即图中的yes和no,14个样本,9个yes,5个no 即在不进行任何切分前,总信息熵为0.940。然后我们依次选取各特征来尝试进行切分,并计算切分完成后的子节点信息熵是多少。首先选取age列进行切分,age是三分类的离散变量,因此若用age对根节点进行切分,将有三个分支,每个分支分别对应一个age的取值, I n f o a g e ( D ) = E ( a g e ) = 5 14 × ( − 2 5 l o g 2 2 5 − 3 5 l o g 2 3 5 ) + 4 14 × ( − 4 4 l o g 2 4 4 − 0 4 l o g 2 0 4 ) + 5 14 × ( − 3 5 l o g 2 3 5 − 2 5 l o g 2 2 5 ) = 0.694 Info_{age}(D) = E(age) = \frac{5}{14} \times (-\frac{2}{5}log_2\frac{2}{5}-\frac{3}{5}log_2\frac{3}{5}) + \frac{4}{14} \times (-\frac{4}{4}log_2\frac{4}{4}-\frac{0}{4}log_2\frac{0}{4}) + \frac{5}{14} \times (-\frac{3}{5}log_2\frac{3}{5}-\frac{2}{5}log_2\frac{2}{5}) = 0.694 Infoage(D)=E(age)=145×(−52log252−53log253)+144×(−44log244−40log240)+145×(−53log253−52log252)=0.694 因此划分age的信息增益为 G a i n ( a g e ) = I n f o ( D ) − I n f o a g e ( D ) = 0.940 − 0.694 = 0.264 Gain(age) = Info(D) - Info_{age}(D) = 0.940 - 0.694 = 0.264 Gain(age)=Info(D)−Infoage(D)=0.940−0.694=0.264 以此类推,我们还能计算其他几个特征的信息增益,最终计算结果如下 ID3缺陷: C4.5 首先通过引入分支度(IV:Information Value)(在《数据挖掘导论》一书中被称为划分信息度)的概念,来对信息增益的计算方法进行修正,简而言之,就是在信息增益计算方法的子节点总信息熵的计算方法中添加了随着分类变量水平的惩罚项。而分支度的计算公式仍然是基于熵的算法,只是将信息熵计算公式中的 p ( i ∣ t ) p(i|t) p(i∣t)(即某类别样例占总样例数)改成了 P ( v i ) P(v_i) P(vi)(即某子节点的总样本数占父总样本数的比例),其实就是权重的意思。 其中,i表示父节点的第i个子节点, v i v_i vi表示第 i i i个子节点样例数, P ( v i ) P(v_i) P(vi)表示第i个子节点拥有样例数占父节点总样例数的比例,IV值会随着叶子节点上样本量的变小而逐渐变大,这就是说一个特征中如果标签分类太多,每个叶子上的IV值就会非常大。 使用之前的信息增益除以分支度作为选取切分字段的参考指标,该指标被称作GainRatio(获利比例,或增益率),计算公式如下: 增益比例是我们决定对哪一列进行分枝的标准,我们分枝的是数字最大的那一列,本质是信息增益最大,分支度又较小的列(也就是纯度提升很快,但又不是靠着把类别分特别细来提升的那些特征)。IV越大,即某一列的分类水平越多,Gainratio实现的惩罚比例越大。当然,我们还是希望GR越大越好。 然后我们可利用GR代替InformationGain重新计算1.2.3的实例,例如计算age字段的GR,由于根据age字段切分后,3个分支分别有5个、4个和5个样例数据,因此age的IV指标计算过程如下: 进而可计算age列的GR: 然后可进一步计算其他各字段的GR值,并选取GR值最大的字段进行切分。 CART CART用到了基尼指数来区分D的不纯度 对离散或者连续值属性A的二元划分导致的不纯度降低为 最大化不纯度降低(或等价地,具有最小基尼数)的属性选为分裂属性。该属性和它的分裂子集(对于离散值的分裂属性)或分裂点(对于连续值的分裂属性)一起形成分裂准则。 依旧是上面的题目,计算D的不纯度: 剪枝 剪枝分为先剪枝和后剪枝 混淆矩阵 对于一个二分类问题,我们可以得到如表 1所示的的混淆矩阵(confusion matrix): 准确率 准确率(accuracy)计算公式如下所示: [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-nMvbWly5-1669877471589)(https://tva1.sinaimg.cn/large/008eGmZEgy1gof0h5wzyqj317a05cmxt.jpg)] 准确率表示预测正确的样本(TP和TN)在所有样本(all data)中占的比例。在数据集不平衡时,准确率将不能很好地表示模型的性能。可能会存在准确率很高,而少数类样本全分错的情况,此时应选择其它模型评价指标。 精确率(查准率)和召回率(查全率) positive class的精确率(precision)计算公式如下: positive class的召回率(recall)计算公式如下: [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-D1LDYTW5-1669877471589)(https://tva1.sinaimg.cn/large/008eGmZEgy1gof0tzlmpqj31ee05cjrz.jpg)] F 1 F_1 F1值和Font metrics not found for font: .值 F 1 F_1 F1值就是精确率和召回率的调和平均值, F 1 F_1 F1值认为精确率和召回率一样重要。 F β F_β Fβ值的计算公式如下: 在β=1时, F β F_β Fβ就是 F 1 F_1 F1值,此时 F β F_β Fβ认为精确率和召回率一样重要;当β>1时,Fβ认为召回率更重要;当0<β<1时, F β F_β Fβ认为精确率更重要。除了 F 1 F_1 F1值之外,常用的还有 F 2 F_2 F2和 F 0 . 5 F_0.5 F0.5。 邻近算法,或者说K最近邻(KNN,K-NearestNeighbor) K-NN区别于K-means,它是有监督的,数据集是打好标签的,本质是基于一种数据统计的方法。 对于一个样本X,要给它分类,首先从数据集中,在X附近找离它最近的K个数据点,将它划分为归属于类别最多的一类 如上图,蓝色和红色是打好标签的数据,我们给绿色这个数据进行分类,K=3的时候发现离他最近的有1个蓝色2个红色,则绿色的这个被分类成红色,k=5的时候,发现离它最近蓝色有3个,红色有2个 则被分类为蓝色 贝叶斯 事件A在事件B已发生的条件下发生的概率,与事件B在事件A已发生的条件下发生的概率是不一样的。然而,这两者是有确定的关系的,贝叶斯定理就是这种关系的陈述。 A以及B为随机事件,且P(B)不为零。P(A|B)是指在事件B发生的情况下事件A发生的概率。 P(A|B)是已知B发生后,A的条件概率。也由于得自B的取值而被称作A的后验概率。 P(B|A)是已知发生后,B发生的条件概率。 P(B)是B的先验概率。 而 P(B|A)则是已知结果}A时,B的概率,称为B的似然性/可能性(likelihood)。 后验概率 = (似然性*先验概率)/标准化常量 记住下面三个公式 支持向量机 用二维的点距离,支持向量机就是找一条边,以最大间隔把两个类分开 扩展到超平面就是,数据点若是p维向量,我们用p-1维的超平面来分开这些点。但是可能有许多超平面可以把数据分类。最佳超平面的一个合理选择就是以最大间隔把两个类分开的超平面。因此,SVM选择能够使离超平面最近的数据点的到超平面距离最大的超平面。 对于训练集数据,我们通过训练若干个个体学习器,通过一定的结合策略,就可以最终形成一个强学习器,以达到博采众长的目的 本节的聚类是一种无监督学习 把一个数据对象划分成自己的过程,每个子集是一个簇(cluster),使得簇中的对象批次相似,但与其他簇中的对象不相似。 类间距离的计算有几种,其中 ∣ p − p ′ ∣ |p-p'| ∣p−p′∣是两个对象或点p和p’之间的距离, m i m_i mi是簇 C i C_i Ci的的均值,而 n i n_i ni是簇 C i C_i Ci中对象的数目 最小距离 分别在两个类中的两个点之间的最小距离 最大距离 分别在两个类中的两个点之间的最大距离 均值距离 两个类中心点的距离 期望值 重点 原理 一开始随机选取k个点,计算数据集每个点到k个点的欧式距离,对每个点来说距离最短的就是它的分类中心。全部计算完之后,再计算每一类的中心,不断循环直到中心不再发生改变。 缺点 要求事先给出聚蔟的簇数k 对噪声和离群点敏感,少量这类数据会对均值产生极大影响 均值可能不是很能反映各个类的属性(当不同的类有不同的大小、密度、形状) 和K-means很类似,只不过他的中心点是具体的对象,叫代表对象,设为 O i O_i Oi。非中心点叫非代表对象,设为 p p p。 算法循环决定每一轮的代表对象。假设初始有k个代表对象 O 1 , . . . , O j − 1 , O j , . . . , O k {O_1, ... , O_{j-1}, O_{j}, ... , O_k} O1,...,Oj−1,Oj,...,Ok,也即对应k个类,计算其他对象到这些代表对象的距离,将对象分配到对应的类,然后在每一个类中随机选取1个对象作为代表对象的替代,设为 O r a n d o m O_{random} Orandom,我们用 O r a n d o m O_{random} Orandom代替 O j O_j Oj,剩下的代表对象为 O i O_i Oi,重新计算p到这些类的距离,属的类。注意此时代表对象集合变为 O 1 , . . . , O j − 1 , O r a n d o m , . . . , O k {O_1, ... , O_{j-1}, O_{random}, ... , O_k} O1,...,Oj−1,Orandom,...,Ok。如果重新分配后绝对误差E减小,则 O j O_j Oj会被 O r a n d o m O_{random} Orandom代替。 绝对误差: p到代表对象的距离之和 CF-tree是聚类特征树 $CF_1 + CF_2 = (n,LS,SS) + (n,LS,SS) = (n_1 + n_2,LS_1 + LS_2,SS_1 + SS_2) $ 使用聚类特征,可以很容易推导出形心,半径和直径 CF树是一棵高度平衡的树,存储了层次聚类的聚类特征。树中非叶子结点都有后代。非叶子结点存储了其子女的CF的总和。 对于CF Tree,我们一般有几个重要参数,第一个参数是每个内部节点的最大CF数B,第二个参数是每个叶子节点的最大CF数L,第三个参数是针对叶子节点中某个CF中的样本点来说的,它是叶节点每个CF的最大样本半径阈值T,也就是说,在这个CF中的所有样本点一定要在半径小于T的一个超球体内。对于上图中的CF Tree,限定了B=7, L=5, 也就是说内部节点最多有7个CF,而叶子节点最多有5个CF。 BIRCH算法其实就是构建CF树的过程,构建CF树的过程包括插入和分裂的过程 我们先定义好CF Tree的参数: 即内部节点的最大CF数B, 叶子节点的最大CF数L, 叶节点每个CF的最大样本半径阈值T 如下,我们插入一个类簇sc8,根据聚类算法,它和sc1,sc2,sc3,sc4为一个类,因此sc8插入到CF树中作为LN1的孩子 如果此时LN1的直径大于阈值,则产生分裂,在这里L=3,因此LN1分裂,sc1和sc8为一个聚蔟LN1’。 而此时分支节点个数也为4了,因此LN1’所在那一层也要分裂 还有就是对于分类效果不是很好的CF树,可以进行合并操作祖先和后代
闭覆盖(closed coverage)
立方体外壳(cube shell)
4.7 数据立方体的计算
多路数组聚集(MultiWay)


BUC:从顶点方体向下计算冰山立方体

Star-Cubing:使用动态星树结构计算冰山立方体

4.8 课后练习
5. 关联规则
5.1 关联规则
频繁模式
支持度和置信度
频繁项集
关联规则挖掘步骤

闭频繁项集和极大频繁项集

5.2 Apriori算法的原理及实现
先验性质
反单调性
Apriori算法
5.3 FP-growth算法的原理及实现
FP-Tree
FP树的挖掘过程。

6. 分类:概念、决策树、最近邻、贝叶斯、集成学习
6.1 分类的概念
6.2 决策树(原理)
(2)准确性高: 挖掘出来的分类规则准确性高, 便于理解, 决策树可以清晰的显示哪些字段比较重要, 即可以生成可以理解的规则.
(3)可以处理连续和种类字段
(4)不需要任何领域知识和参数假设
(5)适合高维数据
(1)对于各类别样本数量不一致的数据, 信息增益偏向于那些更多数值的特征
(2)容易过拟合
(3)忽略属性之间的相关性6.2.1建立决策树的基本策略
G i n i = 1 − ∑ i = 0 c − 1 [ p ( i ∣ t ) ] 2 Gini = 1 - \sum_{i=0}^{c-1}[p(i|t)]^2 Gini=1−i=0∑c−1[p(i∣t)]2
G a i n ( A ) = I n f o ( D ) − I n f o A ( D ) Gain(A) = Info(D) - Info_A(D) Gain(A)=Info(D)−InfoA(D)
ID3中 I n f o ( ) Info() Info()函数就是我们的信息熵,唯一要确定的就是 I n f o ( D ) Info(D) Info(D)和 I n f o A ( D ) Info_A(D) InfoA(D)的含义
I n f o ( D ) = I ( s 1 , s 2 ) = − 9 14 l o g 2 9 14 − 5 14 l o g 2 5 14 ) = 0.940 Info(D) = I(s_1,s_2) = -\frac{9}{14}log_2\frac{9}{14}-\frac{5}{14}log_2\frac{5}{14}) = 0.940 Info(D)=I(s1,s2)=−149log2149−145log2145)=0.940

Gain(income)=0.029,Gain(student)=0.15,Gain(credit_rating)=0.048,很明显,第一次切分过程将采用age字段进行切分,因为它更接近。
对缺失值较为敏感,使用ID3之前需要提前对缺失值进行处理



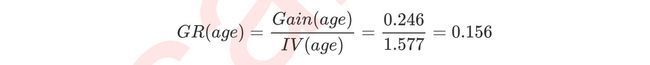
Δ G i n i ( A ) = G i n i ( D ) − G i n i A ( D ) \Delta Gini(A) = Gini(D) - Gini_A(D) ΔGini(A)=Gini(D)−GiniA(D)
G i n i ( D ) = 1 − ( 9 / 14 ) 2 − ( 5 / 14 ) 2 = 0.459 Gini(D) = 1 - (9/14)^2 - (5/14)^2 = 0.459 Gini(D)=1−(9/14)2−(5/14)2=0.459

6.3 混淆矩阵(精度、召回率计算)

TP
真实类别为positive,模型预测的类别也为positive
FP
预测为positive,但真实类别为negative,真实类别和预测类别不一致
FN
预测为negative,但真实类别为positive,真实类别和预测类别不一致
TN
真实类别为negative,模型预测的类别也为negative



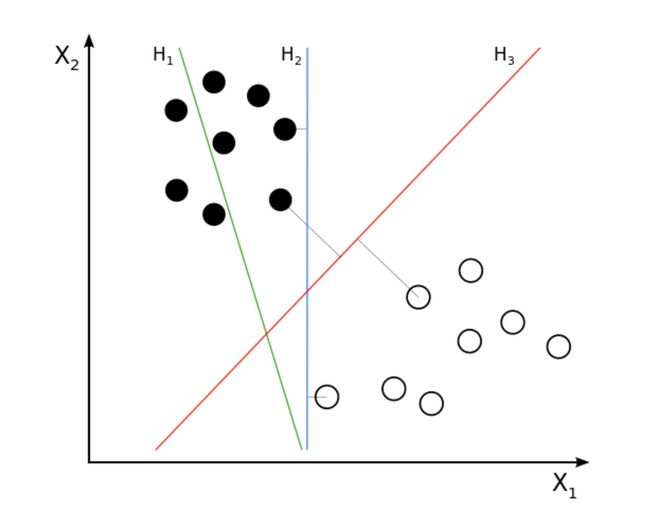
6.4 最近邻(原理) 、贝叶斯(原理) 、支持向量机(原理)


P(A)是A的先验概率(或边缘概率)。其不考虑任何B方面的因素。
6.5 集成学习(原理,为什么好于单分类器)
7. 聚类:概念、划分聚类、层次聚类
7.1 聚类概念
几种聚类间距离计算(平均值,最大最小距离,期望值等)
d i s t m i n ( C i , C j ) = min p ∈ C i , p ′ ∈ C j { ∣ p − p ′ ∣ } dist_{min}(C_i,C_j) = \min_{p\in C_i,p'\in C_j}{\{{|p-p'|}\}} distmin(Ci,Cj)=p∈Ci,p′∈Cjmin{∣p−p′∣}
d i s t m a x ( C i , C j ) = max p ∈ C i , p ′ ∈ C j { ∣ p − p ′ ∣ } dist_{max}(C_i,C_j) = \max_{p\in C_i,p'\in C_j}{\{{|p-p'|}\}} distmax(Ci,Cj)=p∈Ci,p′∈Cjmax{∣p−p′∣}
d i s t m e a n ( C i , C j ) = ∣ m i − m j ∣ dist_{mean}(C_i,C_j) = |m_i - m_j| distmean(Ci,Cj)=∣mi−mj∣
d i s t a v g ( C i , C j ) = 1 n i n j ∑ p ∈ C i , p ′ ∈ C j ∣ p − p ′ ∣ dist_{avg}(C_i,C_j) = \frac{1}{n_in_j}\sum_{p\in C_i,p'\in C_j}{|p-p'|} distavg(Ci,Cj)=ninj1p∈Ci,p′∈Cj∑∣p−p′∣聚类质量评价方法
7.2 K-means、K-Medoids 聚类方法(原理,算法,优化,优缺点)
k-means:基于形心
K-Medoids(K-中心点)
E = ∑ k = 1 k ∑ p ∈ C j d i s t ( p , o i ) E = \sum_{k=1}^{k}\sum_{p\in{C_j}}dist(p,o_i) E=k=1∑kp∈Cj∑dist(p,oi)
7.3 CF-Tree,BIRCH算法(原理,优缺点)
C F = ( n , L S , S S ) CF = (n,LS,SS) CF=(n,LS,SS)
n是数据的数量,LS是 ∑ i = 1 N X i ⃗ \sum_{i=1}^N{\vec{X_i}} ∑i=1NXi ,SS是 ∑ i = 1 N X i 2 ⃗ \sum_{i=1}^N{\vec{{X_i}^2}} ∑i=1NXi2,LS是n个点的线性和,SS是数据点的平方和

BIRCH算法构造CF-Tree