深度学习实践1--FashionMNIST分类
目录
前言
一、深度学习是什么?
二、FashionMNIST分类
1.介绍数据集
2.获取数据集
3.分批迭代数据
4.图片可视化
5.构建网络模型
6.选择损失函数和优化器
7.训练
8.验证
9.训练并验证
10.写成csv
11.完整代码
总结
前言
随着人工智能的发展,深度学习也越发重要,目前深度学习可以应用到多方面,如图像处理领域、语音识别领域、自然语言处理邻域等。本篇是深度学习的入门篇,应用于图像分类。
一、深度学习是什么?
一般是指通过训练多层网络结构对未知数据进行分类或回归。
二、FashionMNIST分类
1.介绍数据集
Fashion-MNIST是Zalando的研究论文中提出的一个数据集,由包含60000个实例的训练集和包含10000个实例的测试集组成。每个实例包含一张28x28的灰度服饰图像和对应的类别标记(共有10类服饰,分别是:t-shirt(T恤),trouser(牛仔裤),pullover(套衫),dress(裙子),coat(外套),sandal(凉鞋),shirt(衬衫),sneaker(运动鞋),bag(包),ankle boot(短靴))。
2.获取数据集
使用torchvision.datasets.FashionMNIST获取内置数据集
import torchvision
from torchvision import transforms
# 将内置数据集的图片大小转为1*28*28后转化为tensor
# 可以对图片进行增广以增加精确度
train_transform = transforms.Compose([
transforms.Resize(28),
transforms.ToTensor()
])
# test_transform = transforms.Compose([])
train_data = torchvision.datasets.FashionMNIST(root='/data/FashionMNIST', train=True, download=True,
transform=train_transform)
test_data = torchvision.datasets.FashionMNIST(root='/data/FashionMNIST', train=False, download=True,
transform=train_transform)
print(len(train_data)) # 长度为60000
print(train_data[0])from torch.utils.data import Dataset
import pandas as pd
# 如果是自己的数据集需要自己构建dataset
class FashionMNISTDataset(Dataset):
def __init__(self, df, transform=None):
self.df = df
self.transform = transform
self.images = df.iloc[:, 1:].values.astype(np.uint8)
self.labels = df.iloc[:, 0].values
def __len__(self):
return len(self.images)
def __getitem__(self, idx):
image = self.images[idx].reshape(28, 28, 1)
label = int(self.labels[idx])
if self.transform is not None:
image = self.transform(image)
else:
image = torch.tensor(image / 255., dtype=torch.float)
label = torch.tensor(label, dtype=torch.long)
return image, label
train = pd.read_csv("../FashionMNIST/fashion-mnist_train.csv")
# train.head(10)
test = pd.read_csv("../FashionMNIST/fashion-mnist_test.csv")
# test.head(10)
print(len(test))
train_iter = FashionMNISTDataset(train, data_transform)
print(train_iter)
test_iter = FashionMNISTDataset(test, data_transform)3.分批迭代数据
调用DataLoader包迭代数据,shuffle用于打乱数据集,训练集需要打乱,测试集不用打乱
from torch.utils.data import DataLoader
batch_size = 256 # 迭代一批的大小(可以设置为其它的,一般用2**n)
num_workers = 4 # windows设置为0
train_iter = DataLoader(train_data, batch_size=batch_size, shuffle=True, num_workers=num_workers)
test_iter = DataLoader(test_data, batch_size=batch_size, shuffle=False, num_workers=num_workers)
# print(len(train_iter)) # 2534.图片可视化
import matplotlib as plt
def show_images(imgs, num_rows, num_cols, targets, scale=1.5):
figsize = (num_cols * scale, num_rows * scale)
_, axes = plt.subplots(num_rows, num_cols, figsize=figsize)
axes = axes.flatten()
for ax, img, target in zip(axes, imgs, targets):
if torch.is_tensor(img):
# 图片张量
ax.imshow(img.numpy())
else:
# PIL
ax.imshow(img)
# 设置坐标轴不可见
ax.axes.get_xaxis().set_visible(False)
ax.axes.get_yaxis().set_visible(False)
plt.subplots_adjust(hspace=0.35)
ax.set_title('{}'.format(target))
return axes
# 将dataloader转换成迭代器才可以使用next方法
X, y = next(iter(train_iter))
show_images(X.squeeze(), 3, 8, targets=y)
plt.show()
5.构建网络模型
卷积->池化->激活->连接
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 64, 1, padding=1)
self.conv2 = nn.Conv2d(64, 64, 3, padding=1)
self.pool1 = nn.MaxPool2d(2, 2)
self.bn1 = nn.BatchNorm2d(64)
self.relu1 = nn.ReLU()
self.conv3 = nn.Conv2d(64, 128, 3, padding=1)
self.conv4 = nn.Conv2d(128, 128, 3, padding=1)
self.pool2 = nn.MaxPool2d(2, 2, padding=1)
self.bn2 = nn.BatchNorm2d(128)
self.relu2 = nn.ReLU()
self.fc5 = nn.Linear(128 * 8 * 8, 512)
self.drop1 = nn.Dropout() # Dropout可以比较有效的缓解过拟合的发生,在一定程度上达到正则化的效果。
self.fc6 = nn.Linear(512, 10)
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = self.pool1(x)
x = self.bn1(x)
x = self.relu1(x)
x = self.conv3(x)
x = self.conv4(x)
x = self.pool2(x)
x = self.bn2(x)
x = self.relu2(x)
# print(" x shape ",x.size())
x = x.view(-1, 128 * 8 * 8)
x = F.relu(self.fc5(x))
x = self.drop1(x)
x = self.fc6(x)
return x
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model = Net()
model = model.to(device)
print(model)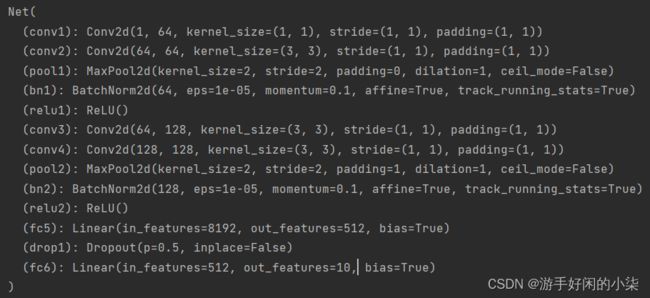
6.选择损失函数和优化器
import torch.optim as optim
criterion = nn.CrossEntropyLoss() # 交叉熵损失
optimizer = optim.Adam(model.parameters(), lr=0.001) # lr->learning rate学习率7.训练
def train(epoch):
model.train()
train_loss = 0
for data,label in train_iter:
data,label = data.cuda() ,label.cuda()
optimizer.zero_grad()
output = model(data)
loss = criterion(output,label)
loss.backward() # 反向计算
optimizer.step() # 优化
train_loss += loss.item()*data.size(0)
train_loss = train_loss/len(train_iter.dataset)
print('Epoch:{}\tTraining Loss:{:.6f}'.format(epoch+1, train_loss))
# train(1)8.验证
def val():
model.eval()
val_loss = 0
gt_labels = []
pred_labels = []
with torch.no_grad():
for data, label in test_iter:
data, label = data.cuda(), label.cuda()
output = model(data)
preds = torch.argmax(output, 1)
gt_labels.append(label.cpu().data.numpy())
pred_labels.append(preds.cpu().data.numpy())
gt_labels, pred_labels = np.concatenate(gt_labels), np.concatenate(pred_labels)
acc = np.sum(gt_labels == pred_labels) / len(pred_labels)
print(gt_labels,pred_labels)
print('Accuracy: {:6f}'.format(acc))
9.训练并验证
epochs = 20
for epoch in range(epochs):
train(epoch)
val()
torch.save(model,"mymmodel.pth") # 保存模型10.写成csv
用于提交比赛
# 写成csv
model = torch.load("mymodel.pth")
model = model.to(device)
id = 0
preds_list = []
with torch.no_grad():
for x, y in test_iter:
batch_pred = list(model(x.to(device)).argmax(dim=1).cpu().numpy())
for y_pred in batch_pred:
preds_list.append((id, y_pred))
id += 1
# print(batch_pred)
with open('result.csv', 'w') as f:
f.write('Id,Category\n')
for id, pred in preds_list:
f.write('{},{}\n'.format(id, pred))11.完整代码
import torch
import torchvision
from torchvision import transforms
from torch.utils.data import Dataset, DataLoader
import matplotlib.pyplot as plt
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import numpy as np
import pandas as pd
train_transform = transforms.Compose([
# transforms.ToPILImage(), # 这一步取决于后续的数据读取方式,如果使用内置数据集则不需要
transforms.Resize(28),
transforms.ToTensor()
])
# test_transform = transforms.Compose([
# transforms.ToTensor()
# ])
train_data = torchvision.datasets.FashionMNIST(root='/data/FashionMNIST', train=True, download=True,
transform=train_transform)
test_data = torchvision.datasets.FashionMNIST(root='/data/FashionMNIST', train=False, download=True,
transform=train_transform)
# print(test_data[0])
batch_size = 256
num_workers = 0
train_iter = DataLoader(train_data, batch_size=batch_size, shuffle=True, num_workers=num_workers)
test_iter = DataLoader(test_data, batch_size=batch_size, shuffle=False, num_workers=num_workers)
# # 如果是自己的数据集需要自己构建dataset
# class FashionMNISTDataset(Dataset):
# def __init__(self, df, transform=None):
# self.df = df
# self.transform = transform
# self.images = df.iloc[:, 1:].values.astype(np.uint8)
# self.labels = df.iloc[:, 0].values
#
# def __len__(self):
# return len(self.images)
#
# def __getitem__(self, idx):
# image = self.images[idx].reshape(28, 28, 1)
# label = int(self.labels[idx])
# if self.transform is not None:
# image = self.transform(image)
# else:
# image = torch.tensor(image / 255., dtype=torch.float)
# label = torch.tensor(label, dtype=torch.long)
# return image, label
#
#
# train = pd.read_csv("../FashionMNIST/fashion-mnist_train.csv")
# # train.head(10)
# test = pd.read_csv("../FashionMNIST/fashion-mnist_test.csv")
# # test.head(10)
# print(len(test))
# train_iter = FashionMNISTDataset(train, data_transform)
# print(train_iter)
# test_iter = FashionMNISTDataset(test, data_transform)
# print(train_iter)
def show_images(imgs, num_rows, num_cols, targets, scale=1.5):
"""Plot a list of images."""
figsize = (num_cols * scale, num_rows * scale)
_, axes = plt.subplots(num_rows, num_cols, figsize=figsize)
axes = axes.flatten()
for ax, img, target in zip(axes, imgs, targets):
if torch.is_tensor(img):
# 图片张量
ax.imshow(img.numpy())
else:
# PIL
ax.imshow(img)
# 设置坐标轴不可见
ax.axes.get_xaxis().set_visible(False)
ax.axes.get_yaxis().set_visible(False)
plt.subplots_adjust(hspace=0.35)
ax.set_title('{}'.format(target))
return axes
# 将dataloader转换成迭代器才可以使用next方法
# X, y = next(iter(train_iter))
# show_images(X.squeeze(), 3, 8, targets=y)
# plt.show()
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 64, 1, padding=1)
self.conv2 = nn.Conv2d(64, 64, 3, padding=1)
self.pool1 = nn.MaxPool2d(2, 2)
self.bn1 = nn.BatchNorm2d(64)
self.relu1 = nn.ReLU()
self.conv3 = nn.Conv2d(64, 128, 3, padding=1)
self.conv4 = nn.Conv2d(128, 128, 3, padding=1)
self.pool2 = nn.MaxPool2d(2, 2, padding=1)
self.bn2 = nn.BatchNorm2d(128)
self.relu2 = nn.ReLU()
self.fc5 = nn.Linear(128 * 8 * 8, 512)
self.drop1 = nn.Dropout()
self.fc6 = nn.Linear(512, 10)
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = self.pool1(x)
x = self.bn1(x)
x = self.relu1(x)
x = self.conv3(x)
x = self.conv4(x)
x = self.pool2(x)
x = self.bn2(x)
x = self.relu2(x)
# print(" x shape ",x.size())
x = x.view(-1, 128 * 8 * 8)
x = F.relu(self.fc5(x))
x = self.drop1(x)
x = self.fc6(x)
return x
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model = Net()
model = model.to(device)
# print(model)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
def train(epoch):
model.train()
train_loss = 0
train_loss_list = []
for data, label in train_iter:
data, label = data.cuda(), label.cuda()
optimizer.zero_grad()
output = model(data)
loss = criterion(output, label)
loss.backward()
optimizer.step()
train_loss += loss.item() * data.size(0)
train_loss = train_loss / len(train_iter.dataset)
train_loss_list.append(train_loss)
print('Epoch:{}\tTraining Loss:{:.6f}'.format(epoch + 1, train_loss))
def val():
model.eval()
gt_labels = []
pred_labels = []
acc_list = []
with torch.no_grad():
for data, label in test_iter:
data, label = data.cuda(), label.cuda()
output = model(data)
preds = torch.argmax(output, 1)
gt_labels.append(label.cpu().data.numpy())
pred_labels.append(preds.cpu().data.numpy())
gt_labels, pred_labels = np.concatenate(gt_labels), np.concatenate(pred_labels)
acc = np.sum(gt_labels == pred_labels) / len(pred_labels)
acc_list.append(acc)
print(gt_labels, pred_labels)
print('Accuracy: {:6f}'.format(acc))
epochs = 2
for epoch in range(epochs):
train(epoch)
val()
torch.save(model, "mymodel.pth")
# 写成csv
model = torch.load("mymodel.pth")
model = model.to(device)
id = 0
preds_list = []
with torch.no_grad():
for x, y in test_iter:
batch_pred = list(model(x.to(device)).argmax(dim=1).cpu().numpy())
for y_pred in batch_pred:
preds_list.append((id, y_pred))
id += 1
# print(preds_list)
with open('result_ljh.csv', 'w') as f:
f.write('Id,Category\n')
for id, pred in preds_list:
f.write('{},{}\n'.format(id, pred))
总结
里面还有许多可以改进的地方,如数据增广,调整超参数,卷积模型,调用多个GPU加快,同时还可以可视化损失及准确率。