MTCNN:一种用于人脸检测的级联卷积网络
论文名称:Joint Face Detection and Alignment Using Multitask Cascaded Convolutional Networks
论文地址:https://arxiv.org/abs/1604.02878
这是个人写的第一篇论文解读,如有考虑不到或者解释不清楚的地方,请在下方留言。
摘要:
简单来说,作者提出了一种使用三个卷积网络做级联,来检测人脸区域和人脸的5个关键点检测。同时,提出了一种新的online hard sample mining 训练技巧来提高模型的判别能力。
模型结构:
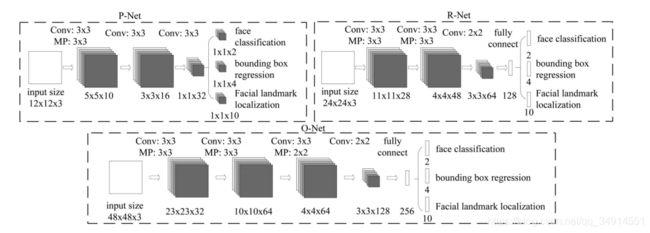
三个级联网络分别是pnet,rnet,onet。pnet采用全卷积结构,最后一部分是三个兄弟层,分别完成人脸分类,人脸框回归,和人脸关键点检测三个任务。另外两个网络的结构大致相似,只是在网络的后端使用全连接层。同时三个网络的在训练的时候的输入大小不一样。除了输出层,激活函数使用Prelu。
损失函数:
每个网络都有三个任务:分类,定位,关键点定位。所以每个网络都有三个损失函数,也就是多任务学习(Multi-task),MTCNN因此得名。
对分类任务而言,因为是二类分类,即仅仅判断是否是人脸区域,所以损失函数使用二类交叉熵(Binary Cross Entropy)。

对于框回归任务而言,网络得到的结果不是框的坐标。我们知道,一个框能用四个数字表示它的位置,即左上角的x,y坐标,框的width,height,这四个参数。为了将获得位置信息变成一个回归问题,我们希望网络学到的是产生的框和Ground Truth的偏置距离,框回归的标签就不应该是以上描述一个框位置的那四个参数,而是样本框的左上角坐标和右下角坐标相对于GT左上角的坐标和右下角坐标的偏置比例。如果没接触过什么是偏置比例,强烈推荐看下rcnn的那篇论文,即RCNN系列的第一篇。

框回归任务直接使用欧式距离作为损失函数。
对于人脸的关键点检测任务而言,也同样使用欧式距离作为损失函数。

总的损失函数的设计如下:
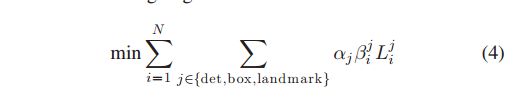
det只的是分类任务,box指的是框回归任务,landmark指的是关键点检测任务。N是一个min-batch的数目。aj是这三类任务的控制参数,这三个参数哪一个大,说明网络对于对应的任务就更加看重。

如文中写道,aj描述了任务的重要性,以及训练不同网络的参数设置是如何的。另外![]() 是一个很重要的参数,下标i是说,对应batch中的某一个样本,上标j是说,对于某一类任务。这个参数的取值是0或者1。也就是说,对于一个样本xi,当且仅当分类任务对xi的判断结果是阳性,
是一个很重要的参数,下标i是说,对应batch中的某一个样本,上标j是说,对于某一类任务。这个参数的取值是0或者1。也就是说,对于一个样本xi,当且仅当分类任务对xi的判断结果是阳性,![]() 才是1,否则为0。也就是说,框回归任务和关键点检测任务只在分类结果为阳性的时候才会加入训练。
才是1,否则为0。也就是说,框回归任务和关键点检测任务只在分类结果为阳性的时候才会加入训练。
训练数据的制作:
论文使用的人脸检测的数据集是WIDER FACE,对关键点检测使用的数据集是CelebA。
第一步
从WIDER FACE中随机crop出样本,判断样本的GT的IOU,如果IOU大于0.65,则得到一个正样本;如果IOU大于0.45,则得到一个part样本;如果IOU小于0.3,则得到了一个负样本。IOU在0.3-0.45之间的样本,被认为是不重要的,没有学习价值的样本。
对分类任务使用正样本和负样本,对框回归任务使用正样本和part样本,对关键点检测直接使用CelebA的标签再加上处理成偏置比例即可。
第二步
从用上一步得到的数据训练pnet,将WIDER FACE中的整张图片送入pnet,得到了结果再和GT计算IOU,同样用上面的方式采集正负样本和part样本,作为对onet训练的数据集。
第三步
同第二步的思路。
以上三步得到的数据都要resize到所训练网络的输入大小。
训练技巧:
使用了online hard sample mining。思路是对一个batch的loss值进行排序,只对前70%最大的loss值计算梯度。
作者认为,这样做可以忽略对检测器不太有帮助的样本,而更加注重那些难分类,难学习的样本,对它们进行学习。
(不过我不太明白为啥作者是这是一种全新的online hard sample mining,因为传统的不也是这样做吗!!!)
测试:
作者考虑到了多尺度问题,因此在输入图像之前,做了一个图像金字塔。总过程如图所示:

这篇文章就介绍到这里。后续会陆续更新自己看过的其他文章。欢迎订阅,点赞。