bert:pre-training of deep bidirectional transformers for language understanding
BERT 论文逐段精读【论文精读】_哔哩哔哩_bilibili更多论文请见:https://github.com/mli/paper-reading https://www.bilibili.com/video/BV1PL411M7eQ/?spm_id_from=333.788&vd_source=4aed82e35f26bb600bc5b46e65e25c2214.8. 来自Transformers的双向编码器表示(BERT) — 动手学深度学习 2.0.0-beta0 documentation
https://www.bilibili.com/video/BV1PL411M7eQ/?spm_id_from=333.788&vd_source=4aed82e35f26bb600bc5b46e65e25c2214.8. 来自Transformers的双向编码器表示(BERT) — 动手学深度学习 2.0.0-beta0 documentation https://zh-v2.d2l.ai/chapter_natural-language-processing-pretraining/bert.htmlGitHub - huggingface/transformers: Transformers: State-of-the-art Machine Learning for Pytorch, TensorFlow, and JAX. Transformers: State-of-the-art Machine Learning for Pytorch, TensorFlow, and JAX. - GitHub - huggingface/transformers: Transformers: State-of-the-art Machine Learning for Pytorch, TensorFlow, and JAX.
https://zh-v2.d2l.ai/chapter_natural-language-processing-pretraining/bert.htmlGitHub - huggingface/transformers: Transformers: State-of-the-art Machine Learning for Pytorch, TensorFlow, and JAX. Transformers: State-of-the-art Machine Learning for Pytorch, TensorFlow, and JAX. - GitHub - huggingface/transformers: Transformers: State-of-the-art Machine Learning for Pytorch, TensorFlow, and JAX. https://github.com/huggingface/transformersTransformer结构及其应用详解--GPT、BERT、MT-DNN、GPT-2 - 知乎本文首先详细介绍Transformer的基本结构,然后再通过 GPT、BERT、MT-DNN以及GPT-2等基于Transformer的知名应用工作的介绍并附上GitHub链接,看看Transformer是如何在各个著名的模型中大显神威的。一、取代RNN——T…
https://github.com/huggingface/transformersTransformer结构及其应用详解--GPT、BERT、MT-DNN、GPT-2 - 知乎本文首先详细介绍Transformer的基本结构,然后再通过 GPT、BERT、MT-DNN以及GPT-2等基于Transformer的知名应用工作的介绍并附上GitHub链接,看看Transformer是如何在各个著名的模型中大显神威的。一、取代RNN——T… https://zhuanlan.zhihu.com/p/69290203
https://zhuanlan.zhihu.com/p/69290203
bert是最为经典的自然语言处理,后续也在视觉上启发了mae等图像大规模自监督训练的大模型算法。看了抱抱脸的官方文档,感觉这块还是比较完善的。推荐的最后一篇文章写的很好,基本介绍了gpt和bert的区别。
1.introduction
自然语言任务包括句子级别的任务和token级别的任务。将预先训练好的语言表示应用到下游任务有两种方式,feature-based和fine-tuning。前者是将训练好的特征作为附加特征加入到下游任务中一起训练,后者在图像上就类比与用imagenet预训练的模型,相当于对模型中的参数做了初始化。这两种方法在预训练中使用相同的目标函数,即使用单向语言模型来学习通用的表征,类似gpt,gpt用的transformers中的解码部分,是单向的,本文的bert用的transformers中的编码部分,是双向的,这也是本文作者认为的bert的最大卖点。
bert受完形填空任务的启发,使用masked language model(MLM)预训练目标来缓解单向性约束。masked 语言模型随机屏蔽掉输入中一些标记,其目标是仅根据器上下文预测masked词。
2.related work
2.1 unsupervised feature-based approaches
主要是ELMo。
2.2 unpervised fine-tuning approaches
openai的GPT。
3.BERT
bert有两个部分,pre-training和fine-tuning。在pre-training期间,模型在不同的预训练任务中基于未标记的数据进行训练。在fine-tuning中,首先使用预训练的参数初始化bert模型,然后使用来自下游任务的标记数据对所有的参数进行微调。每个下游任务都有自己的微调模型,即使他们使用相同的预训练参数初始化的。
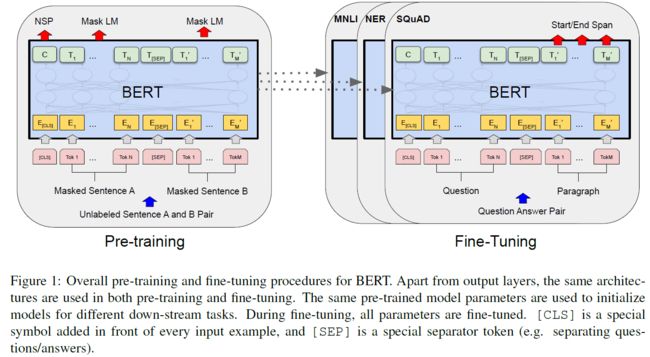
3.1 model architecture
主要有两个模型,bert的base版本(L=12,H=768,A=12,总参数:110m),bert的large版本(L=24,H=1024,A=16,总参数:340m),base版本和GPT的参数差不多,不过bert是双向的。
3.2 input/output representations
为了让bert处理不同的下游任务,输入表示既可以是一个句子,也是可以一对句子,因此bert中的句子可以连续文本的任意的任意跨度,就是说一对和一个这样的都叫句子,sentence,而输入到bert中的句子叫做序列,sequence,他可以是一个句子或者两个句子组成在一起的形式。
使用wordpiece,英文中有些词是词根词缀的组合形式,单词可能不常见,但是词根和词缀都常见,比如flying这种,就拆成fly和ing这种形式来减少词典的数量。这样大概有30000个token,单词数目,每个序列的第一份标记是一个特殊的分类标记[cls],vit也是这种形式,原始的vit也是把第一个cls作为特殊符号用来做下游任务的预测。最终的隐藏状态对应这个token用作分类任务的序列带标。句子被压缩成单一的序列,用两种方式来区分句子,首先用一个特殊的标记[sep]将句子分开,其次我们向每个嵌入中加入了是句子a还是b的一个token,
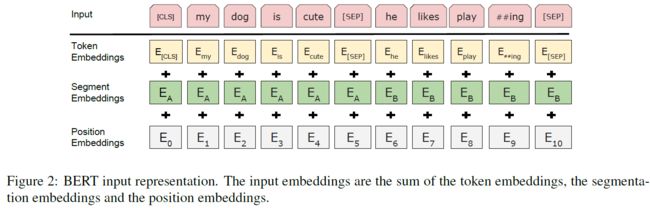
上图中比较清楚,有三个embedding,token,segment指示是句子a还是b的,以及位置的embedding,其中位置embedding是用来学出来的,不像transformers中是构造的
3.1 pre-training bert
使用了两个无监督的任务来预训练,这个是很重要的,bert的结构其实和transformers的encoder,没啥新东西,但是它构造了一个预训练的流程和下游任务利用的模式,这是最值得借鉴的,以至于在视觉领域,目前也兴起了这种潮流。
Task1:Masked LM.深度双向模型比从左到右或从右到左的模型的浅层连接层强大。常规的条件语言模型只能单向训练,双向训练将允许每个单词间接看到自己。
BERT采用的是不经过Mask的Transformer,也就是与Transformer文章中的Encoder Transformer结构完全一样:GPT中因为要完成语言模型的训练,也就要求Pre-Training预测下一个词的时候只能够看见当前以及之前的词,这也是GPT放弃原本Transformer的双向结构转而采用单向结构的原因。BERT为了能够同时得到上下文的信息,而不是像GPT一样完全放弃下文信息,采用了双向的Transformer。但是这样一来,就无法再像GPT一样采用正常的语言模型来预训练了,因为BERT的结构导致每个Transformer的输出都可以看见整个句子的,无论你用这个输出去预测什么,都会“看见”参考答案,也就是“see itself”的问题。ELMo中虽然采用的是双向RNN,但是两个RNN之间是独立的,所以可以避免see itself的问题。
在Transformer中,我们即想要知道上文的信息,又想要知道下文的信息,但同时要保证整个模型不知道要预测词的信息,那么就干脆不要告诉模型这个词的信息就可以了。也就是说,BERT在输入的句子中,挖掉一些需要预测的词,然后通过上下文来分析句子,最终使用其相应位置的输出来预测被挖掉的词。这其实就像是在做完形填空 (Cloze)一样。
但是,直接将大量的词替换为
- 输入数据中随机选择15%的词用于预测,这15%的词中,
- 80%的词向量输入时被替换为
- 10%的词的词向量在输入时被替换为其他词的词向量
- 另外10%保持不动
这样一来就相当于告诉模型,我可能给你答案,也可能不给你答案,也可能给你错误的答案,有
Task2:Next sentence prediction(NSP) 许多重要的下游任务,如问答和自然语言推理都是基于理解两个句子之间的关系,而语言建模并不能直接捕获这些关系。BERT还提出了另外一种预训练方式NSP,与MLM同时进行,组成多任务预训练。这种预训练的方式就是往Transformer中输入连续的两个句子,左边的句子前面加上一个
Pre-training data:BookCorpus(800m)和English wikipedia(2500m words)
3.2 fine-tuning BERT
对于每个任务,只需将特定于任务的输入和输出插入bert并端到端微调所有的参数。分类直接利用cls即可。
4.experiments