【人脸】人脸特征点检测---级联方法DCNN、Face++(1)、MTCNN
一、论文:《Deep Convolutional Network Cascade for Facial Point Detection》
链接:http://mmlab.ie.cuhk.edu.hk/archive/CNN_FacePoint.htm



级联的思想,先进行粗检测,然后微调特征点。步骤如下:
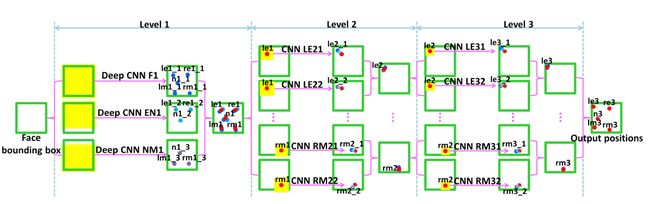
level1:3个CNN level2:10个CNN(每个CNN6层) level3:10个CNN
(1)首先在整个人脸图像(红色方框)上训练一个网络来对人脸特征点坐标进行粗回归,实际采用的网络其输入大小为39*39的人脸区域灰度图,预测时可以得到特征点的大概位置;如上图level1,在绿色框中,预测出5个点;第一层分为三波,分别是对五个点、左右眼和鼻子、鼻子和嘴巴,重复预测的特征点进行位置平均

 Deep CNN F1 的卷积网络结构标题
Deep CNN F1 的卷积网络结构标题
level1网络的输入层使用的是39*39的单通道灰色图像,经过四个带池化层的卷积层,最后经过全连接层,输出一个维度为10的结果,代表5个特征点的坐标值 ,在最后一层是欧几里得损失层,计算的是网络预测的坐标值与真实值(都是相对值)之间的均值误差的积累。
(2)设计另一个回归网络,以人脸特征点(取得是level1训练之后得到的特征点)周围的局部区域图像(如下图)作为输入进行训练,实际采用的网络为其输入大小为15*15的特征点局部区域灰度图,以预测到更加准确的特征点位置。最后将预测的特征点按取位置平均。这里level3比level2定义的输入区域要小一点。

第二层训练,以第一层训练得到的5个特征点为基础,每个特征点做两组数据集,即以第一组数据集特征点为中心,局部框大小为(2*0.18*W,2*0.18*H),其中W和H为人脸框的宽和高,并对此局部框做随机的微小平移使得特征点在局部框中的位置随机,裁剪出一个大小为15*15的局部框图像,第二组数据和第一组数据一样,只是框比例取0.16(第三层的两组数据比例为0.11、0.12,其余和第二层一样)。对每个特征点,针对这两组数据集采用同样的网络,得到两组模型;预测时,采用两组模型预测的均值作为预测结果,提高预测的准确度。
level3与level2类似,以Level2的预测特征点为中心,重新截取。
另外需要注意的是,回归采用的欧几里得损失,在计算坐标时,使用的是相对坐标而不是绝对坐标,即每一次坐标计算,相对坐标是相对于上图所示的黄色框的边界进行的,绝对坐标是基于绿色边框边界进行的。
除此之外,在level1训练时,还对训练集进行了增广。除了做镜像之外,还对人脸框进行了两组缩放和四组平移,以及两组小角度的旋转,然后再将人脸框区域裁剪成39*39大小的区域。
二、论文《Extensive Facial Landmark Localization with Coarse to fine Convolutional Network Cascade》face++2013年
链接:http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.961.2022&rep=rep1&type=pdf
人脸68特征点的定位方法,也是采用了从粗到精的定位思想,网络属于DCNN。
创新点:
1、在网络输入方面,不是用人脸检测器检测到的人脸区域图片作为网络输入,而是采用CNN预测人脸的bounding box,这个改进对初始level的定位精度提高很多;
2、内部关键点(Inner points)51个点和外部关键点(Contour points)17个点分开预测
3、针对内部关键点,对每一个器官用一个CNN预测,减少计算量
Inner points
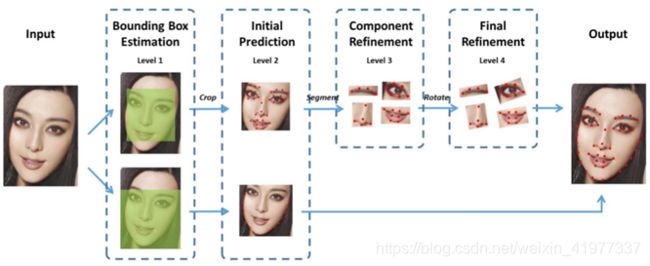
第一层次(level 1):
预测的是内部特征点的最小包围盒。输入一张完整的图片,我们通过这一层CNN,预测这51个点的最小包围盒(Bounding Box)。Bounding box 包含矩形左上角的坐标、右下角的坐标,也就是网络的输出是一个4维的向量;
第二层次(level 2):
网络的输入是我们通过第一层次预测到的51个点的最小包围盒中的人脸图片,网络的输出是51个特征点预测位置(粗定位位置),即有102个神经元。这一层次比较简单,说白了就是我们常见的CNN,用普通的CNN预测51个特征点(当然用这一层预测出来的位置,只能作为初始位置,因为通过这一层预测的精度还不够高,只能作为51个点的粗定位。我们需要有后面继续两个层次网络进行精定位);
第三层次(level 3):
因此我们这一层次的网络,就是要利用level 2的网络预测到的51个点,把五官的图片裁剪出来,然后对五官进行分别的定位。网络需要有4个CNN模型,每个模型用于预测各自的特征点,输出是各个器官各自的特征点;
第四层次(level 4):
把level 3的各个五官预测结果,计算各五官的旋转角度,然后把五官都摆正了,作为第四层次网络输入图片,然后在进行预测。
Contour points
这17个点的预测比较简单粗暴,就只是两个层次的DCNN模型,这两个层次说的简单一点就是类似上面Inner points的第一、二两个层次网络。
第一层次(level 1):
预测Contour points的最小包围盒
第二层次(level 2):
CNN直接预测这17个特征点,这个预测过程,没有精定位过程。也就是没有第三、四层次的CNN精定位,一来是因为这些脸庞特征点的图片区域比较大,如果加上第三、四层次的话,会比较耗时间;二来是因为paper还没想到比较好的方法,用于精定位。
三、论文 《 Joint Face Detection and Alignment using Multi-task Cascaded Convolutional Networks》
链接:https://github.com/kpzhang93/MTCNN_face_detection_alignment
提出一个新的框架使用统一的级联CNN通过多任务学习来集成人脸检测和特征点定位两个任务。
提出的CNN包括三个阶段:
(1)通过一个浅层CNN迅速产生候选框;
(2)通过一个稍复杂的CNN丢弃大部分没有人脸的框
(3)使用一个更强大的CNN精炼结果,同时显示面部特征点定位。设计轻量级CNN可以提高实时性能。

对于给定的图片,首先resize到不同的尺寸建立一个图片金字塔,作为接下来三层级联框架的输入。
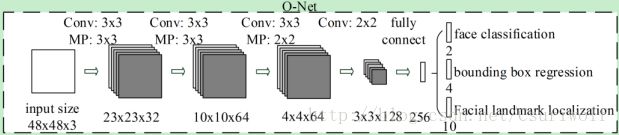
Stage1(P-Net):采用全卷积神经网络,去获得候选框和它们的边界框回归向量,然后,使用估算的边界框回归向量来校准候选框。 然后,利用NMS方法去除高度重叠的窗体;

Stage2(R-Net):所有候选框被送入下一个CNN,更进一步地去除大量的错误候选窗体,再使用bounding box regression进行校 准和NMS法;

Stage3(O-Net):该阶段类似于第二阶段,但该阶段目的是描述脸部更多细节,显示五个脸部特征点位置。
损失函数:
1、人脸检测:判断是否是人脸,二分类问题,使用交叉熵损失函数

Pi表示样本是人脸的概率, 表示ground-truth label(样本是否为人脸的真实取值)
表示ground-truth label(样本是否为人脸的真实取值)
2、候选框回归:对每个候选框和最近的ground truth之间的差距,回归问题对每个样本应用欧几里得损失函数

第一个参数y拔regression target来自网络,第二个是四维ground-truth 坐标,包括左上坐标、高和宽
3、人脸特征点定位:类似于检测框回归任务,脸部特征点检测也是回归问题,需最小化Euclidean loss

减号前是网络得到的面部特征点坐标,减号后是10维ground-truth 坐标,包括左眼、右眼、鼻子、左嘴角和右嘴角
目标函数:
