pandas的自带数据集_如何正确使用Pandas库提升项目的运行速度?

TUSHARE 金融与技术学习兴趣小组
翻译整理 | One
本期编辑 | Little monster
译者简介:西南财经大学应用数学本科,英国曼彻斯特大学金融数学硕士,金融分析师,专注于利用数据建立金融模型,发掘潜在投资价值。
作者:Joe Wyndham
如果你从事大数据工作,用Python的Pandas库时会发现很多惊喜。Pandas在数据科学和分析领域扮演越来越重要的角色,尤其是对于从Excel和VBA转向Python的用户。
所以,对于数据科学家,数据分析师,数据工程师,Pandas是什么呢?Pandas文档里的对它的介绍是:
“快速、灵活、和易于理解的数据结构,以此让处理关系型数据和带有标签的数据时更简单直观。”
快速、灵活、简单和直观,这些都是很好的特性。当你构建复杂的数据模型时,不需要再花大量的开发时间在等待数据处理的任务上了。这样可以将更多的精力集中去理解数据。
但是,有人说Pandas慢…
第一次使用Pandas时,有人评论说:Pandas是很棒的解析数据的工具,但是Pandas太慢了,无法用于统计建模。第一次使用的时候,确实如此,真的慢。
但是,Pandas是建立在NumPy数组结构之上的。所以它的很多操作通过NumPy或者Pandas自带的扩展模块编写,这些模块用Cython编写并编译到C,并且在C上执行。因此,Pandas不也应该很快的吗?
事实上,使用姿势正确的话,Pandas确实很快。
在使用Pandas时,使用纯“python”式代码并不是最效率的选择。和NumPy一样,Pandas专为向量化操作而设计,它可在一次扫描中完成对整列或者数据集的操作。而单独处理每个单元格或某一行这种遍历的行为,应该作为备用选择。

本教程

先说明下,本教程不是引导如何过度优化Pandas代码。因为Pandas在正确的使用下已经很快了。此外,优化代码和编写清晰的代码之间的差异是巨大的。
这是一篇关于“如何充分利用Pandas内置的强大且易于上手的特性”的指引。此外,你将学习到一些实用的节省时间的技巧。在这篇教程中,你将学习到:
· 使用datetime时间序列数据的优势
· 处理批量计算更效率的方法
· 利用HDFStore节省时间
在本文中,耗电量时间序列数据将被用于演示本主题。加载数据后,我们将逐步了解更有效率的方法取得最终结果。对于Pandas用户而言,会有多种方法预处理数据。但是这不意味着所有方法都适用于更大、更复杂的数据集。
【注】
Github 源码见文末【1】
【工具】
Python 3、Pandas 0.23.1
任务
本例使用能源消耗的时间序列数据计算一年能源的总成本。由于不同时间段的电价不同,因此需要将各时段的耗电量乘上对应时段的电价。
从CSV文件中可以读取到两列数据:日期时间和电力消耗(千瓦)
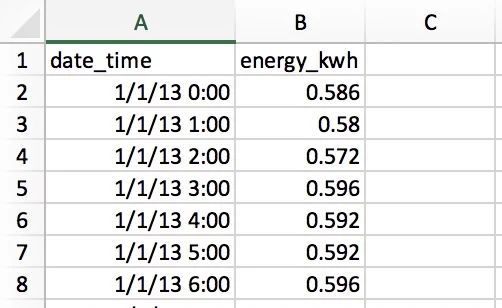
每行数据中都包含每小时耗电量数据,因此整年会产生8760(356×24)行数据。每行的小时数据表示计算的开始时间,因此1/1/13 0:00的数据指1月1号第1个小时的耗电量数据。
用Datetime类节省时间
首先用Pandas的一个I/O函数读取CSV文件:
>>> import pandas as pd这结果看上去挺好,但是有个小问题。Pandas 和NumPy有个数据类型dtypes概念。假如不指定参数的话,date_time这列将会被归为默认类object:
>>> df.dtypes默认类object不仅是str类的容器,而且不能齐整的适用于某一种数据类型。字符串str类型的日期在数据处理中是非常低效的,同时内存效率也是低下的。
为了处理时间序列数据,需要将date_time列格式化为datetime类的数组,Pandas 称这种数据类型为时间戳Timestamp。用Pandas进行格式化相当简单:
>>> df[至此,新的df和CSV file内容基本一样。它有两列和一个索引。
df上述代码简单且易懂,但是有执行速度如何呢?这里我们使用了timing装饰器,这里将装饰器称为@timeit。这个装饰器模仿了Python标准库中的timeit.repeat() 方法,但是它可以返回函数的结果,并且打印多次重复调试的平均运行时间。Python的timeit.repeat() 只返回调试时间结果,但不返回函数结果。
将装饰器@timeit放在函数上方,每次运行函数时可以同时打印该函数的运行时间。
>>> @timeit(repeat=看结果如何?处理8760行数据耗时1.6秒。这似乎没啥毛病。但是当处理更大的数据集时,比如计算更高频的电费数据,给出每分钟的电费数据去计算一整年的总成本。数据量会比现在多60倍,这意味着你需要大约90秒去等待输出的结果。这就有点忍不了了。
实际上,作者工作中需要分析330个站点过去10年的每小时电力数据。按上边的方法,需要88分钟完成时间列的格式化转换。
有更快的方法吗?一般来说,Pandas可以更快的转换你的数据。在本例中,使用格式参数将csv文件中特定的时间格式传入Pandas的to_datetime中,可以大幅的提升处理效率。
>>> @timeit(repeat=新的结果如何?0.032秒,速度提升了50倍!所以之前330站点的数据处理时间节省了86分钟。
一个需要注意的细节是CSV中的时间格式不是ISO 8601格式:YYYY-mm-dd HH:MM。如果没有指定格式,Pandas将使用dateuil包将每个字符串格式的日期格式化。相反,如果原始的时间格式已经是ISO 8601格式了,Pandas可以快速的解析日期。
【注】Pandas的read_csv()方法也提供了解析时间的参数。详见parse_dates,infer_datetime_format,和date_parser参数。
遍历
日期时间已经完成格式化,现在准备开始计算电费了。由于每个时段的电价不同,因此需要将对应的电价映射到各个时段。此例中,电价收费标准如下:
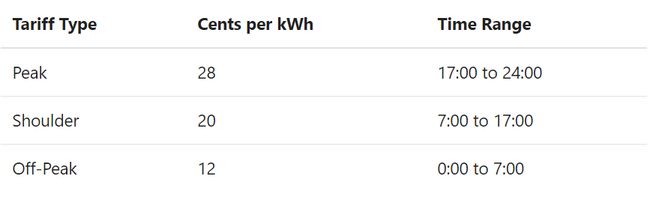
如果电价全天统一价28美分每千瓦每小时,大多数人都知道可以一行代码实现电费的计算:
>>> df[这行代码将创建一行新列,该列包含当前时段的电费:
date_time 但是电费的计算取决于不用的时段对应的电价。这里许多人会用非Pandas式的方式:用遍历去完成这类计算。
在本文中,将从最基础的解决方案开始介绍,并逐步提供充分利用Pandas性能优势的Python式解决方案。
但是对于Pandas库来说,什么是Python式方案?这里是指相比其他友好性较差的语言如C++或者Java,它们已经习惯了“运用遍历”去编程。
如果不熟悉Pandas,大多数人会像以前一样使用继续遍历方法。这里继续使用@timeit装饰器来看看这种方法的效率。
首先,创建一个不同时段电价的函数:
def apply_tariff(kwh, hour):如下代码就是一种常见的遍历模式:
# 注意:不要尝试该函数!对于没有用过Pandas的Python用户来说,这种遍历很正常:对于每个x,再给定条件y下,输出z。
但是这种遍历很笨重。可以将上述例子视为Pandas用法的“反面案例”,原因如下几个。
首先,它需要初始化一个列表用于存储输出结果。
其次,它用了隐晦难懂的类range(0, len(df))去做循环,接着在应用apply_tariff()函数后,还必须将结果增加到列表中用于生成新的DataFrame列。
最后,它还使用链式索引df.iloc[i]['date_time'],这可能会生产出很多bugs。
这种遍历方式最大的问题在于计算的时间成本。对于8760行数据,花了3秒钟完成遍历。下面,来看看一些基于Pandas数据结构的迭代方案。
用.itertuples()和.iterrow()遍历
还有其他办法吗?
Pandas实际上通过引入DataFrame.itertuples()和DataFrame.iterrows()方法使得for i in range(len(df))语法冗余。这两种都是产生一次一行的生成器方法。
.itertuples()为每行生成一个nametuple类,行的索引值作为nametuple类的第一个元素。nametuple是来自Python的collections模块的数据结构,该结构和Python中的元组类似,但是可以通过属性查找可访问字段。
.iterrows()为DataFrame的每行生成一组由索引和序列组成的元组。
与.iterrows()相比,.itertuples()运行速度会更快一些。本例中使用了.iterrows()方法,因为很多读者很可能没有用过nametuple。
repeat=取得一些不错的进步。语法更清晰,少了行值i的引用,整体更具有可读性了。在时间收益方面,几乎快了5倍!
但是,仍然有很大的改进空间。由于仍然在使用for遍历,意味着每循环一次都需要调用一次函数,而这些本可以在速度更快的Pandas内置架构中完成。
Pandas的.apply()
可以用.apply()方法替代.iterrows()方法提升效率。Pandas的.apply()方法可以传入可调用的函数并且应用于DataFrame的轴上,即所有行或列。此例中,借助lambda功能将两列数据传入apply_tariff():
>>> @timeit(repeat=.apply()的语法优势很明显,代码行数少了,同时代码也更易读了。运行速度方面,这与.iterrows()方法相比节省了大约一半时间。
但是,这还不够快。一个原因是.apply()内部尝试在Cython迭代器上完成循环。但是在这种情况下,lambda中传递了一些无法在Cython中处理的输入,因此调用.apply()时仍然不够快。
如果使用.apply()在330个站点的10年数据上,这大概得花15分钟的处理时间。假如这个计算仅仅是一个大型模型的一小部分,那么还需要更多的提升。下面的向量化操作可以做到这点。
用.isin()筛选数据
之前看到的如果只有单一电价,可以将所有电力消耗数据乘以该价格df['energy_kwh'] * 28。这种操作就是一种向量化操作的一个用例,这是Pandas中最快的方式。
但是,在Pandas中如何将有条件的计算应用在向量化操作中呢?一种方法是,根据条件将DataFrame进行筛选并分组和切片,然后对每组数据进行对应的向量化操作。
在下面的例子中,将展示如何使用Pandas中的.isin()方法筛选行,然后用向量化操作计算对应的电费。在此操作前,将date_time列设置为DataFrame索引便于向量化操作:
'date_time', inplace=执行结果如下:
>>> apply_tariff_isin(df)
Best of 3 trials with 100 function calls per trial:
Function `apply_tariff_isin` ran in average of 0.010 seconds.
要理解这段代码,也许需要先了解.isin()方法返回的是布尔值,如下:
[False, False, False, ..., True, True, True]
这些布尔值标记了DataFrame日期时间索引所在的时段。然后,将这些布尔值数组传给DataFrame的.loc索引器时,会返回一个仅包含该时段的DataFrame切片。最后,将该切片数组乘以对应的时段的费率即可。
这与之前的遍历方法相比如何?
首先,不需要apply_tariff()函数了,因为所有的条件逻辑都被应用在了被选中的行。这大大减少了代码的行数。
在速度方面,比普通的遍历快了315倍,比.iterrows()方法快了71倍,且比.apply()方法快了27倍。现在可以快速的处理大数据集了。
还有提升空间吗?
在apply_tariff_isin()中,需要手动调用三次df.loc和df.index.hour.isin()。比如24小时每个小时的费率不同,这意味着需要手动调用24次.isin()方法,所以这种方案通常不具有扩展性。幸运的是,还可以使用Pandas的pd.cut()功能:
@timeit(repeat=3, number=100)pd.cut()根据分组bins产生的区间生成对应的标签“费率”。
【注】include_lowest参数设定第一个间隔是否包含在组bins中,例如想要在该组中包含时间在0时点的数据。
这是种完全向量化的操作,它的执行速度已经起飞了:
>>> apply_tariff_cut(df)
Best of 3 trials with 100 function calls per trial:
Function `apply_tariff_cut` ran in average of 0.003 seconds.
至此,现在可以将330个站点的数据处理时间从88分钟缩小到只需不到1秒。但是,还有最后一个选择,就是使用NumPy库来操作DataFrame下的每个NumPy数组,然后将处理结果集成回DataFrame数据结构中。
还有NumPy!
别忘了Pandas的Series和DataFrame是在NumPy库的基础上设计的。这提供了更多的灵活性,因为Pandas和NumPy数组可以无缝操作。
在下一例中,将演示NumPy的digitize()功能。它和Pandas的cut()功能类似,将数据分组。本例中将DataFrame中的索引(日期时间)进行分组,将三个时段分入三组。然后将分组后的电力消耗数组应用在电价数组上:
@timeit(repeat=3, number=100)和cut()一样,语法简单易读。但是速度如何呢?
>>> apply_tariff_digitize(df)
Best of 3 trials with 100 function calls per trial:
Function `apply_tariff_digitize` ran in average of 0.002 seconds.
执行速度上,仍然有提升,但是这种提升已经意义不大了。不如将更多精力去思考其他的事情。
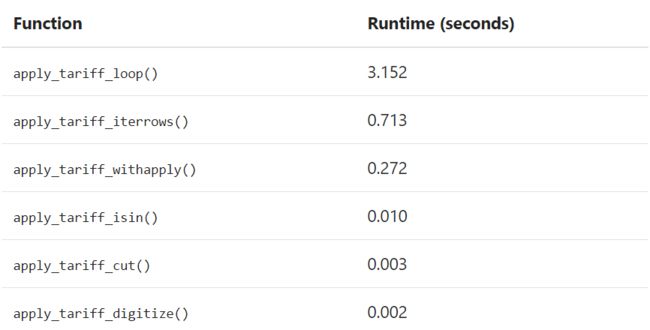
Pandas可以提供很多批量处理数据方法的备用选项,这些已经在上边都一一演示过了。这里将最快到最慢的方法排序如下:
1. 使用向量化操作:没有for遍历的Pandas方法和函数。
2. 使用.apply()方法。
3. 使用.itertuples():将DataFrame行作为nametuple类从Python的collections模块中进行迭代。
4. 使用.iterrows():将DataFrame行作为(index,pd.Series)元组数组进行迭代。虽然Pandas的Series是一种灵活的数据结构,但将每一行生成一个Series并且访问它,仍然是一个比较大的开销。
5. 对逐个元素进行循环,使用df.loc或者df.iloc对每个单元格或者行进行处理。
【注】以上顺序不是作者的建议,而是Pandas核心开发人员给的建议。
以下是本文中所有函数的调试时间汇总:
用HDFstore存储预处理数据
已经了解了用Pandas快速处理数据,现在我们需要探讨如何避免重复的数据处理过程。这里使用了Pandas内置的HDFStore方法。
通常在建立一些复杂的数据模型时,对数据做一些预处理是很常见的。例如,假如有10年时间跨度的分钟级的高频数据,但是模型只需要20分钟频次的数据或者其他低频次数据。你不希望每次测试分析模型时都需要预处理数据。
一种方案是,将已经完成预处理的数据存储在已处理数据表中,方便需要时随时调用。但是如何以正确的格式存储数据?如果将预处理数据另存为CSV,那么会丢失datetime类,再次读入时必须重新转换格式。
Pandas有个内置的解决方案,它使用HDF5,这是一种专门用于存储数组的高性能存储格式。Pandas的HDFstore方法可以将DataFrame存储在HDF5文件中,可以有效读写,同时仍然保留DataFrame各列的数据类型和其他元数据。它是一个类似字典的类,因此可以像Python中的dict类一样读写。
以下是将已经预处理的耗电量DataFrame写入HDF5文件的方法:
# 创建存储类文件并命名 `processed_data`将数据存储在硬盘以后,可以随时随地调取预处理数据,不再需要重复加工。以下是关于如何从HDF5文件中访问数据的方法,同时保留了数据预处理时的数据类型:
# 访问数据仓库一个数据仓库可以存储多张表,每张表配有一个键。
【注】使用Pandas的HDFStore需要安装PyTables>=3.0.0,因此安装Pandas后,需要更新PyTables:
install 总结
如果觉得你的Pandas项目不具备速度快、灵活、简单且直观的特征,那么该重新思考使用该库的方式了。
本文中已经相当直观的展示了正确的使用Pandas是可以大幅改善运行时间,以及代码可读性的。以下是应用Pandas的一些经验性的建议:
① 尝试更多的向量化操作,尽量避免类似for x in df的操作。如果代码中本身就有许多for循环,那么尽量使用Python自带的数据结构,因为Pandas会带来很多开销。
② 如果因为算法复杂无法使用向量化操作,可以尝试.apply()方法。
③ 如果必须循环遍历数组,可用.iterrows()或者.itertuples()改进语法和提升速度。
④ Pandas有很多可选项操作,总有几种方法可以完成从A到B的过程,比较不同方法的执行方式,选择最适合项目的一种。
⑤ 做好数据处理脚本后,可以将中间输出的预处理数据保存在HDFStore中,避免重新处理数据。
⑥ 在Pandas项目中,利用NumPy可以提高速度同时简化语法。

END
更多内容请关注“挖地兔”公众号。
 【参考链接】
【参考链接】
https://github.com/realpython/materials/tree/master/pandas-fast-flexible-intuitive【1】
https://realpython.com/fast-flexible-pandas/
【扩展阅读】这些方法解决了数据清洗80%的工作量
利用Python玩转PDF,简单实用
利用python进行蒙特卡罗模拟
利用Tushare数据实现知识图谱效果
你真的懂线程吗?史上最全Python线程解析