PyTorch 源码解读之 nn.Module:核心网络模块接口详解
目录
0 设计
1 nn.Module 实现
1.1 常用接口
1.1.1 __init__ 函数
1.1.2 状态的转换
1.1.3 参数的转换或转移
1.1.4 Apply 函数
1.2 属性的增删改查
1.2.1 属性设置
1.2.2 属性删除
1.2.3 常见的属性访问
1.3 Forward & Backward
1.3.1 Hooks
1.3.2 运行逻辑
1.4 模块存取
1.4.1 Hooks
1.4.2 功能实现
1.4.3 _load_from_state_dict 妙用
本次解读主要介绍 PyTorch 中的神经网络模块,即 torch.nn,其中主要介绍 nn.Module,其他模块的细节可以通过 PyTorch 的 API 文档进行查阅,一些较重要的模块如 DataParallel 和 BN/SyncBN 等,都有独立的文章进行介绍。
0 设计
nn.Module 其实是 PyTorch 体系下所有神经网络模块的基类,此处顺带梳理了一下 torch.nn 中的各个组件,他们的关系概览如下图所示。
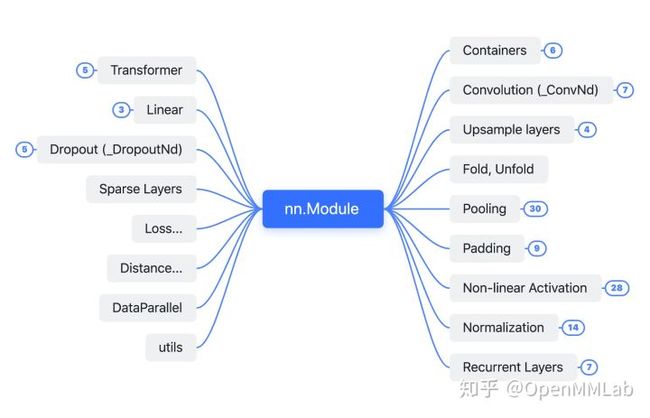
展开各模块后,模块之间的继承关系与层次结构如下图所示:
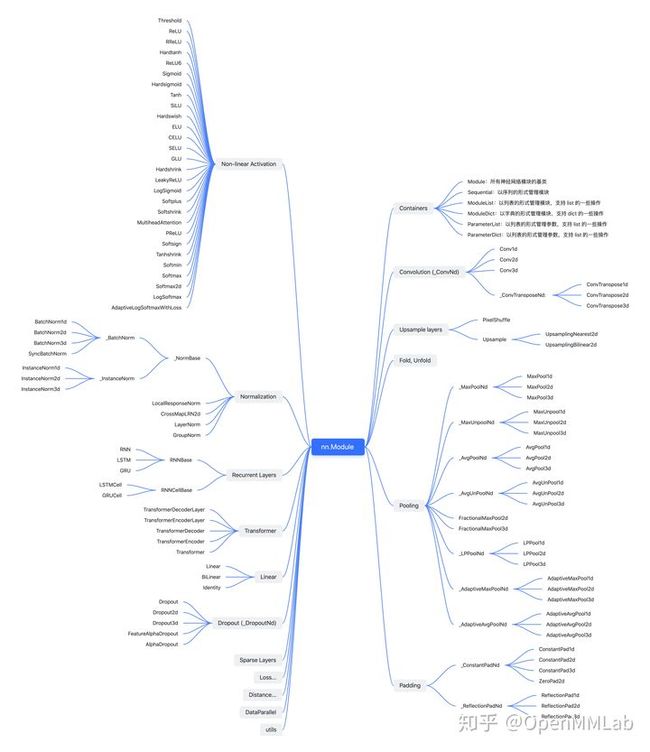
从各模块的继承关系来看,模块的组织和实现有几个常见的特点,供 PyTorch 代码库的开发者参考借鉴:
- 一般有一个基类来定义接口,通过继承来处理不同维度的 input,如:
- Conv1d,Conv2d,Conv3d,ConvTransposeNd 继承自 _ConvNd
- MaxPool1d,MaxPool2d,MaxPool3d 继承自 _MaxPoolNd 等
- 每一个类都有一个对应的 nn.functional 函数,类定义了所需要的 arguments 和模块的 parameters,在 forward 函数中将 arguments 和 parameters 传给 nn.functional 的对应函数来实现 forward 功能。比如:
- 所有的非线性激活函数,都是在 forward 中直接调用对应的 nn.functional 函数
- Normalization 层都是调用的如 F.layer_norm, F.group_norm 等函数
- 继承 nn.Module 的模块主要重载 init、 forward、 和 extra_repr 函数,含有 parameters 的模块还会实现 reset_parameters 函数来初始化参数
1 nn.Module 实现
1.1 常用接口
1.1.1 __init__ 函数
在 nn.Module 的 __init__ 函数中,会首先调用 torch._C._log_api_usage_once("python.nn_module"), 这一行代码是 PyTorch 1.7 的新功能,用于监测并记录 API 的调用,详细解释可见 文档。
在此之后,nn.Module 初始化了一系列重要的成员变量。这些变量初始化了在模块 forward、 backward 和权重加载等时候会被调用的的 hooks,也定义了 parameters 和 buffers,如下面的代码所示:
self.training = True # 控制 training/testing 状态
self._parameters = OrderedDict() # 在训练过程中会随着 BP 而更新的参数
self._buffers = OrderedDict() # 在训练过程中不会随着 BP 而更新的参数
self._non_persistent_buffers_set = set()
self._backward_hooks = OrderedDict() # Backward 完成后会被调用的 hook
self._forward_hooks = OrderedDict() # Forward 完成后会被调用的 hook
self._forward_pre_hooks = OrderedDict() # Forward 前会被调用的 hook
self._state_dict_hooks = OrderedDict() # 得到 state_dict 以后会被调用的 hook
self._load_state_dict_pre_hooks = OrderedDict() # load state_dict 前会被调用的 hook
self._modules = OrderedDict() # 子神经网络模块各个成员变量的功能在后面还会继续提到,这里先在注释中简单解释。由源码的实现可见,继承 nn.Module 的神经网络模块在实现自己的 __init__ 函数时,一定要先调用 super().__init__()。只有这样才能正确地初始化自定义的神经网络模块,否则会缺少上面代码中的成员变量而导致模块被调用时出错。实际上,如果没有提前调用 super().__init__(),在增加模块的 parameter 或者 buffer 的时候,被调用的 __setattr__ 函数也会检查出父类 nn.Module 没被正确地初始化并报错。(在面试的过程中,我们经常发现面试者在写自定义神经网络模块的时候会忽略掉这一点,看了这篇文章以后可要千万记得哦~)
1.1.2 状态的转换
- 训练与测试
nn.Module 通过 self.training 来区分训练和测试两种状态,使得模块可以在训练和测试时有不同的 forward 行为(如 Batch Normalization)。nn.Module 通过 self.train() 和 self.eval() 来修改训练和测试状态,其中 self.eval 直接调用了 self.train(False),而 self.train() 会修改 self.training 并通过 self.children() 来调整所有子模块的状态。关于 self.children() 的介绍可见下文的 常见的属性访问 章节。
def train(self: T, mode: bool = True) -> T:
self.training = mode
for module in self.children():
module.train(mode)
return self- Example: freeze 部分模型参数
在目标检测等任务中,常见的 training practice 会将 backbone 中的所有 BN 层保留为 eval 状态,即 freeze BN 层中的 running_mean 和 running_var,并且将浅层的模块 freeze。此时就需要重载 detector 类的 train 函数,MMDetection 中 ResNet 的 train 函数实现如下:
def train(self, mode=True):
super(ResNet, self).train(mode)
self._freeze_stages()
if mode and self.norm_eval:
for m in self.modules():
# trick: eval have effect on BatchNorm only
if isinstance(m, _BatchNorm):
m.eval()- 梯度的处理
对于梯度的处理 nn.Module 有两个相关的函数实现,分别是 requires_grad_ 和 zero_grad 函数,他们都调用了 self.parameters() 来访问所有的参数,并修改参数的 requires_grad 状态 或者 清理参数的梯度。
def requires_grad_(self: T, requires_grad: bool = True) -> T:
for p in self.parameters():
p.requires_grad_(requires_grad)
return self
def zero_grad(self, set_to_none: bool = False) -> None:
if getattr(self, '_is_replica', False):
warnings.warn(
"Calling .zero_grad() from a module created with nn.DataParallel() has no effect. "
"The parameters are copied (in a differentiable manner) from the original module. "
"This means they are not leaf nodes in autograd and so don't accumulate gradients. "
"If you need gradients in your forward method, consider using autograd.grad instead.")
for p in self.parameters():
if p.grad is not None:
if set_to_none:
p.grad = None
else:
if p.grad.grad_fn is not None:
p.grad.detach_()
else:
p.grad.requires_grad_(False)
p.grad.zero_()1.1.3 参数的转换或转移
nn.Module 实现了如下 8 个常用函数将模块转变成 float16 等类型、转移到 CPU/ GPU上。
- CPU:将所有 parameters 和 buffer 转移到 CPU 上
- type:将所有 parameters 和 buffer 转变成另一个类型
- CUDA:将所有 parameters 和 buffer 转移到 GPU 上
- float:将所有浮点类型的 parameters 和 buffer 转变成 float32 类型
- double:将所有浮点类型的 parameters 和 buffer 转变成 double 类型
- half:将所有浮点类型的 parameters 和 buffer 转变成 float16 类型
- bfloat16:将所有浮点类型的 parameters 和 buffer 转变成 bfloat16 类型
- to:移动模块或/和改变模块的类型
这些函数的功能最终都是通过 self._apply(function) 来实现的, function 一般是 lambda 表达式或其他自定义函数。因此,用户其实也可以通过 self._apply(function) 来实现一些特殊的转换。self._apply() 函数实际上做了如下 3 件事情,最终将 function 完整地应用于整个模块。
- 通过 self.children() 进行递归的调用
- 对 self._parameters 中的参数及其 gradient 通过 function 进行处理
- 对 self._buffers 中的 buffer 逐个通过 function 来进行处理
def _apply(self, fn):
# 对子模块进行递归调用
for module in self.children():
module._apply(fn)
# 为了 BC-breaking 而新增了一个 tensor 类型判断
def compute_should_use_set_data(tensor, tensor_applied):
if torch._has_compatible_shallow_copy_type(tensor, tensor_applied):
# If the new tensor has compatible tensor type as the existing tensor,
# the current behavior is to change the tensor in-place using `.data =`,
# and the future behavior is to overwrite the existing tensor. However,
# changing the current behavior is a BC-breaking change, and we want it
# to happen in future releases. So for now we introduce the
# `torch.__future__.get_overwrite_module_params_on_conversion()`
# global flag to let the user control whether they want the future
# behavior of overwriting the existing tensor or not.
return not torch.__future__.get_overwrite_module_params_on_conversion()
else:
return False
# 处理参数及其gradint
for key, param in self._parameters.items():
if param is not None:
# Tensors stored in modules are graph leaves, and we don't want to
# track autograd history of `param_applied`, so we have to use
# `with torch.no_grad():`
with torch.no_grad():
param_applied = fn(param)
should_use_set_data = compute_should_use_set_data(param, param_applied)
if should_use_set_data:
param.data = param_applied
else:
assert isinstance(param, Parameter)
assert param.is_leaf
self._parameters[key] = Parameter(param_applied, param.requires_grad)
if param.grad is not None:
with torch.no_grad():
grad_applied = fn(param.grad)
should_use_set_data = compute_should_use_set_data(param.grad, grad_applied)
if should_use_set_data:
param.grad.data = grad_applied
else:
assert param.grad.is_leaf
self._parameters[key].grad = grad_applied.requires_grad_(param.grad.requires_grad)
# 处理 buffers
for key, buf in self._buffers.items():
if buf is not None:
self._buffers[key] = fn(buf)
return self1.1.4 Apply 函数
nn.Module 还实现了一个 apply 函数,与 _apply() 函数不同的是,apply 函数只是简单地递归调用了 self.children() 去处理自己以及子模块,如下面的代码所示。
def apply(self: T, fn: Callable[['Module'], None]) -> T:
for module in self.children():
module.apply(fn)
fn(self)
return selfapply 函数和 _apply 函数的区别在于,_apply() 是专门针对 parameter 和 buffer 而实现的一个“仅供内部使用”的接口,但是 apply 函数是“公有”接口 (Python 对类的“公有”和“私有”区别并不是很严格,一般通过单前导下划线来区分)。apply 实际上可以通过修改 fn 来实现 _apply 能实现的功能,同时还可以实现其他功能,如下面给出的重新初始化参数的例子。
- Example: 参数重新初始化
可以自定义一个 init_weights 函数,通过 net.apply(init_weights) 来初始化模型权重。
@torch.no_grad()
def init_weights(m):
print(m)
if type(m) == nn.Linear:
m.weight.fill_(1.0)
print(m.weight)
net = nn.Sequential(nn.Linear(2, 2), nn.Linear(2, 2))
net.apply(init_weights)1.2 属性的增删改查
1.2.1 属性设置
对 nn.Module 属性的修改有一下三个函数,函数以及对应功能如下
- add_module:增加子神经网络模块,更新 self._modules
- register_parameter:增加通过 BP 可以更新的 parameters (如 BN 和 Conv 中的 weight 和 bias ),更新 self._parameters
- register_buffer:增加不通过 BP 更新的 buffer(如 BN 中的 running_mean 和 running_var),更新 self._buffers,如果 buffer 不是 persistant 的,还会同时更新到 self._non_persistent_buffers_set 中。buffer 是否 persistant 的区别在于这个 buffer 是否会能被放入 self.state_dict 中被保存下来。 这 3 个函数都会先检查
self.__dict__中是否包含对应的属性字典以确保 nn.Module 被正确初始化,然后检查属性的 name 是否合法,如不为空 string 且不包含“.”,同时还会检查他们是否已经存在于要修改的属性字典中。
在日常的代码开发过程中,更常见的用法是直接通过 http://self.xxx = xxx 的方式来增加或修改子神经网络模块、parameters、buffers 以及其他一般的 attribute。这种方式本质上会调用 nn.Module 重载的函数 __setattr__ ,详细的代码如下:
def __setattr__(self, name: str, value: Union[Tensor, 'Module']):
def remove_from(*dicts_or_sets):
for d in dicts_or_sets:
if name in d:
if isinstance(d, dict):
del d[name]
else:
d.discard(name)
params = self.__dict__.get('_parameters')
if isinstance(value, Parameter):
if params is None:
raise AttributeError(
"cannot assign parameters before Module.__init__() call")
remove_from(self.__dict__, self._buffers, self._modules, self._non_persistent_buffers_set)
self.register_parameter(name, value)
elif params is not None and name in params:
if value is not None:
raise TypeError("cannot assign '{}' as parameter '{}' "
"(torch.nn.Parameter or None expected)"
.format(torch.typename(value), name))
self.register_parameter(name, value)
else:
modules = self.__dict__.get('_modules')
if isinstance(value, Module):
if modules is None:
raise AttributeError(
"cannot assign module before Module.__init__() call")
remove_from(self.__dict__, self._parameters, self._buffers, self._non_persistent_buffers_set)
modules[name] = value
elif modules is not None and name in modules:
if value is not None:
raise TypeError("cannot assign '{}' as child module '{}' "
"(torch.nn.Module or None expected)"
.format(torch.typename(value), name))
modules[name] = value
else:
buffers = self.__dict__.get('_buffers')
if buffers is not None and name in buffers:
if value is not None and not isinstance(value, torch.Tensor):
raise TypeError("cannot assign '{}' as buffer '{}' "
"(torch.Tensor or None expected)"
.format(torch.typename(value), name))
buffers[name] = value
else:
object.__setattr__(self, name, value)从源码中我们还有如下观察:
- 在第 14 行和 28 行,函数检查了继承 nn.Module 的自定义模块是否有正确地初始化父类 nn.Module,这也说明了 super().__init__() 的必要性
- 在增加 self._parameters,self._modules 的时候,会预先调用 remove_from 函数 (15 和 29 行)从其余私有属性中删除对应的 name,这说明 self.dict,self._buffers,self._parameters,self._modules 中的属性应该是互斥的
- 如果要给模块增加 buffer,self.register_buffer 是唯一的方式,
__setattr__只能将 self._buffers 中已有的 buffer 重新赋值为 None 或者 tensor 。这是因为 buffer 的初始化类型就是 torch.Tensor 或者 None,而不像 parameters 和 module 分别是 nn.Parameter 和 nn.Module 类型 - 除了其他普通的 attribute,最终 parameters 还是会在
__setattr__中通过 register_parameter 来增加,但是子神经网络模块和 buffer 是直接修改的 self._modules 和 self._buffers - 由第三点和前文所述的 _apply 实现可以得出 self.xxxx = torch.Tensor() 是一种不被推荐的行为,因为这样新增的 attribute 既不属于 self._parameters,也不属于 self._buffers,而会被视为普通的 attribute ,在将模块进行状态转换的时候,self.xxxx 会被遗漏进而导致 device 或者 type 不一样的 bug
1.2.2 属性删除
属性的删除通过重载的 __delattr__ 来实现,详细代码如下:
def __delattr__(self, name):
if name in self._parameters:
del self._parameters[name]
elif name in self._buffers:
del self._buffers[name]
self._non_persistent_buffers_set.discard(name)
elif name in self._modules:
del self._modules[name]
else:
object.__delattr__(self, name)__delattr__ 会挨个检查 self._parameters、self._buffers、self._modules 和普通的 attribute 并将 name 从中删除。
1.2.3 常见的属性访问
nn.Module 中的常用函数包括下面 8 个,他们都会返回一个迭代器用于访问模块中的 buffer,parameter,子模块等。他们的功能与区别如下
- parameters:调用 self.named_parameters 并返回模型参数,被应用于 self.requires_grad_ 和 self.zero_grad 函数中
- named_parameters:返回 self._parameters 中的 name 和 parameter 元组,如果 recurse=True 还会返回子模块中的模型参数
- buffers:调用 self.named_buffers 并返回模型参数
- named_buffers:返回 self._buffers 中的 name 和 buffer 元组,如果 recurse=True 还会返回子模块中的模型 buffer
- children:调用 self.named_children,只返回 self._modules 中的模块,被应用于 self.train 函数中
- named_children:只返回 self._modules 中的 name 和 module 元组
- modules:调用 self.named_modules 并返回各个 module 但不返回 name
- named_modules:返回 self._modules 下的 name 和 module 元组,并递归调用和返回 module.named_modules
def _named_members(self, get_members_fn, prefix='', recurse=True):
memo = set()
modules = self.named_modules(prefix=prefix) if recurse else [(prefix, self)]
for module_prefix, module in modules:
members = get_members_fn(module)
for k, v in members:
if v is None or v in memo:
continue
memo.add(v)
name = module_prefix + ('.' if module_prefix else '') + k
yield name, v
def parameters(self, recurse: bool = True) -> Iterator[Parameter]:
for name, param in self.named_parameters(recurse=recurse):
yield param
def named_parameters(self, prefix: str = '', recurse: bool = True) -> Iterator[Tuple[str, Tensor]]:
gen = self._named_members(
lambda module: module._parameters.items(),
prefix=prefix, recurse=recurse)
for elem in gen:
yield elem
def buffers(self, recurse: bool = True) -> Iterator[Tensor]:
for name, buf in self.named_buffers(recurse=recurse):
yield buf
def named_buffers(self, prefix: str = '', recurse: bool = True) -> Iterator[Tuple[str, Tensor]]:
gen = self._named_members(
lambda module: module._buffers.items(),
prefix=prefix, recurse=recurse)
for elem in gen:
yield elem
def children(self) -> Iterator['Module']:
for name, module in self.named_children():
yield module
def named_children(self) -> Iterator[Tuple[str, 'Module']]:
memo = set()
for name, module in self._modules.items():
if module is not None and module not in memo:
memo.add(module)
yield name, module
def modules(self) -> Iterator['Module']:
for name, module in self.named_modules():
yield module
def named_modules(self, memo: Optional[Set['Module']] = None, prefix: str = ''):
if memo is None:
memo = set()
if self not in memo:
memo.add(self)
yield prefix, self
for name, module in self._modules.items():
if module is None:
continue
submodule_prefix = prefix + ('.' if prefix else '') + name
for m in module.named_modules(memo, submodule_prefix):
yield mnamed_parameters 和 named_buffers 都是调用的 self._named_members 实现的,named_modules 和 named_children 虽然有自己的实现,但和 self._named_members 一样,都是通过 set 类型的 memo 来记录已经抛出的模块,如果 member 不在 memo 中,才会将 member 抛出并将 member 放入 memo 中,因此 named_parameters、named_buffers、named_modules 和named_children 都不会返回重复的 parameter、 buffer 或 module。
nn.Module 重载了 __dir__ 函数,重载的 __dir__ 函数会将 self._modules、self._parameters 和 self._buffers 中的 attributes 给暴露出来。
def __dir__(self):
module_attrs = dir(self.__class__)
attrs = list(self.__dict__.keys())
parameters = list(self._parameters.keys())
modules = list(self._modules.keys())
buffers = list(self._buffers.keys())
keys = module_attrs + attrs + parameters + modules + buffers
# Eliminate attrs that are not legal Python variable names
keys = [key for key in keys if not key[0].isdigit()]
return sorted(keys)还有一种常见的属性访问是通过 module.attribute 来进行的。这种调用等价于 getattr(module, 'attribute')。和 nn.Module 对 __delattr__ 以及 __setattr__ 的重载类似,为了确保 getattr 能访问到所有的属性,nn.Module 也重载了 __getattr__ 函数,以访问 self._parameters,self._buffers,self._modules 中的属性。
根据 Python 对实例属性的查找规则,当我们调用 module.attribute 的时候,Python 会首先查找 module 的 类及其基类的 __dict__,然后查找这个 object 的 __dict__,最后查找 __getattr__ 函数。因此,虽然 nn.Module 的 __getattr__ 只查找了 self._parameters,self._buffers,self._modules 三个成员变量,但是 getattr(module, 'attribute') 覆盖的范围和 __dir__ 暴露的范围是一致的。
def __getattr__(self, name: str) -> Union[Tensor, 'Module']:
if '_parameters' in self.__dict__:
_parameters = self.__dict__['_parameters']
if name in _parameters:
return _parameters[name]
if '_buffers' in self.__dict__:
_buffers = self.__dict__['_buffers']
if name in _buffers:
return _buffers[name]
if '_modules' in self.__dict__:
modules = self.__dict__['_modules']
if name in modules:
return modules[name]
raise ModuleAttributeError("'{}' object has no attribute '{}'".format(
type(self).__name__, name))1.3 Forward & Backward
1.3.1 Hooks
在 nn.Module 的实现文件中,首先实现了 3 个通用的 hook 注册函数,用于注册被应用于全局的 hook。这 3 个函数会将 hook 分别注册进 3 个全局的 OrderedDict,使得所有的 nn.Module 的子类实例在运行的时候都会触发这些 hook。每个 hook 修改的 OrderedDict 如下所示:
- register_module_backward_hook:_global_backward_hooks
- register_module_forward_pre_hook:_global_forward_pre_hooks
- register_module_forward_hook:_global_forward_hooks
同样的,nn.Module 也支持注册只被应用于自己的 forward 和 backward hook,通过 3 个函数 来管理 自己的 3 个属性并维护 3 个 attribute,他们的类型也是 OrderedDict,每个 hook 修改的 OrderedDict 如下所示:
- self.register_backward_hook: self._backward_hooks
- self.register_forward_pre_hook: self._forward_pre_hooks
- self.register_forward_hook: self._forward_hooks
1.3.2 运行逻辑
nn.Module 在被调用的时候,一般是以 module(input) 的形式,此时会首先调用 self.__call__,接下来这些 hooks 在模块被调用时候的执行顺序如下图所示:

_call_impl 的代码实现如下。注意到 _call_impl 在定义以后被直接赋值给了 __call__ 。同时我们注意到在 torch._C._get_tracing_state() 为 True 的时候,nn.Module 会通过 _slow_forward() 来调用 forward 函数而非直接调用 forward 函数,这一功能主要用于 JIT。
def _call_impl(self, *input, **kwargs):
for hook in itertools.chain(
_global_forward_pre_hooks.values(),
self._forward_pre_hooks.values()):
result = hook(self, input)
if result is not None:
if not isinstance(result, tuple):
result = (result,)
input = result
if torch._C._get_tracing_state():
result = self._slow_forward(*input, **kwargs)
else:
result = self.forward(*input, **kwargs)
for hook in itertools.chain(
_global_forward_hooks.values(),
self._forward_hooks.values()):
hook_result = hook(self, input, result)
if hook_result is not None:
result = hook_result
if (len(self._backward_hooks) > 0) or (len(_global_backward_hooks) > 0):
var = result
while not isinstance(var, torch.Tensor):
if isinstance(var, dict):
var = next((v for v in var.values() if isinstance(v, torch.Tensor)))
else:
var = var[0]
grad_fn = var.grad_fn
if grad_fn is not None:
for hook in itertools.chain(
_global_backward_hooks.values(),
self._backward_hooks.values()):
wrapper = functools.partial(hook, self)
functools.update_wrapper(wrapper, hook)
grad_fn.register_hook(wrapper)
return result
__call__ : Callable[..., Any] = _call_impl1.4 模块存取
1.4.1 Hooks
nn.Module 还有两个相关的 hook 是关于模型参数的加载和存储的,分别是:
- _register_state_dict_hook:在self.state_dict()的最后对模块导出的 state_dict 进行修改
- _register_load_state_dict_pre_hook:在 _load_from_state_dict 中最先执行
1.4.2 功能实现
nn.Module 使用 state_dict() 函数来进行获得当前的完整状态,用于在模型训练中储存 checkpoint。 模块的 _version 信息会首先存入 metadata 中,用于模型的版本管理,然后会通过 _save_to_state_dict() 将 self._parameters 以及 self._buffers 中的 persistent buffer 进行保存。 用户可以通过重载 _save_to_state_dict 函数来满足特定的需求。
nn.Module 使用 load_state_dict() 函数来读取 checkpoint。load_state_dict() 会通过调用每个子模块的_load_from_state_dict 函数来加载他们所需的权重,如下面代码的 55-63 行所示。而 _load_from_state_dict 才是真正负责加载 parameter 和 buffer 的函数。这也说明了每个模块可以自行定义他们的 _load_from_state_dict 函数来满足特殊需求,实际上这也是 PyTorch 官方推荐的做法。在后面的两个例子中,我们也给出了 _load_from_state_dict 的使用例子。
def _load_from_state_dict(self, state_dict, prefix, local_metadata, strict,
missing_keys, unexpected_keys, error_msgs):
for hook in self._load_state_dict_pre_hooks.values():
hook(state_dict, prefix, local_metadata, strict, missing_keys, unexpected_keys, error_msgs)
persistent_buffers = {k: v for k, v in self._buffers.items() if k not in self._non_persistent_buffers_set}
local_name_params = itertools.chain(self._parameters.items(), persistent_buffers.items())
local_state = {k: v for k, v in local_name_params if v is not None}
for name, param in local_state.items():
key = prefix + name
if key in state_dict:
input_param = state_dict[key]
# Backward compatibility: loading 1-dim tensor from 0.3.* to version 0.4+
if len(param.shape) == 0 and len(input_param.shape) == 1:
input_param = input_param[0]
if input_param.shape != param.shape:
# local shape should match the one in checkpoint
error_msgs.append('size mismatch for {}: copying a param with shape {} from checkpoint, '
'the shape in current model is {}.'
.format(key, input_param.shape, param.shape))
continue
try:
with torch.no_grad():
param.copy_(input_param)
except Exception as ex:
error_msgs.append('While copying the parameter named "{}", '
'whose dimensions in the model are {} and '
'whose dimensions in the checkpoint are {}, '
'an exception occurred : {}.'
.format(key, param.size(), input_param.size(), ex.args))
elif strict:
missing_keys.append(key)
if strict:
for key in state_dict.keys():
if key.startswith(prefix):
input_name = key[len(prefix):]
input_name = input_name.split('.', 1)[0] # get the name of param/buffer/child
if input_name not in self._modules and input_name not in local_state:
unexpected_keys.append(key)
def load_state_dict(self, state_dict: Union[Dict[str, Tensor], Dict[str, Tensor]], strict: bool = True):
missing_keys = []
unexpected_keys = []
error_msgs = []
# copy state_dict so _load_from_state_dict can modify it
metadata = getattr(state_dict, '_metadata', None)
state_dict = state_dict.copy()
if metadata is not None:
state_dict._metadata = metadata
def load(module, prefix=''):
local_metadata = {} if metadata is None else metadata.get(prefix[:-1], {})
module._load_from_state_dict(
state_dict, prefix, local_metadata, True, missing_keys, unexpected_keys, error_msgs)
for name, child in module._modules.items():
if child is not None:
load(child, prefix + name + '.')
load(self)
load = None # break load->load reference cycle
if strict:
if len(unexpected_keys) > 0:
error_msgs.insert(
0, 'Unexpected key(s) in state_dict: {}. '.format(
', '.join('"{}"'.format(k) for k in unexpected_keys)))
if len(missing_keys) > 0:
error_msgs.insert(
0, 'Missing key(s) in state_dict: {}. '.format(
', '.join('"{}"'.format(k) for k in missing_keys)))
if len(error_msgs) > 0:
raise RuntimeError('Error(s) in loading state_dict for {}:\n\t{}'.format(
self.__class__.__name__, "\n\t".join(error_msgs)))
return _IncompatibleKeys(missing_keys, unexpected_keys)1.4.3 _load_from_state_dict 妙用
- Example: 避免 BC-breaking
在模型迭代的过程中,module 很容易出现 BC-breaking ,PyTorch 通过 _version 和 _load_from_state_dict 来处理的这类问题(这也是 PyTorch 推荐的方式)。 下面的代码是 _NormBase 类避免 BC-breaking 的方式。在 PyTorch 的开发过程中,Normalization layers 在某个新版本中 引入了 num_batches_tracked 这个 key,给 BN 记录训练过程中经历的 batch 数,为了兼容旧版本训练的模型,PyTorch 修改了 _version,并修改了 _load_from_state_dict。
def _load_from_state_dict(self, state_dict, prefix, local_metadata, strict,
missing_keys, unexpected_keys, error_msgs):
version = local_metadata.get('version', None)
if (version is None or version < 2) and self.track_running_stats:
# at version 2: added num_batches_tracked buffer
# this should have a default value of 0
num_batches_tracked_key = prefix + 'num_batches_tracked'
if num_batches_tracked_key not in state_dict:
state_dict[num_batches_tracked_key] = torch.tensor(0, dtype=torch.long)
super(_NormBase, self)._load_from_state_dict(
state_dict, prefix, local_metadata, strict,
missing_keys, unexpected_keys, error_msgs)这里再举一个 MMCV 中的例子,DCN 经历了一次重构,属性的名字经过了重命名。
def _load_from_state_dict(self, state_dict, prefix, local_metadata, strict,
missing_keys, unexpected_keys, error_msgs):
version = local_metadata.get('version', None)
if version is None or version < 2:
# the key is different in early versions
# In version < 2, DeformConvPack loads previous benchmark models.
if (prefix + 'conv_offset.weight' not in state_dict
and prefix[:-1] + '_offset.weight' in state_dict):
state_dict[prefix + 'conv_offset.weight'] = state_dict.pop(
prefix[:-1] + '_offset.weight')
if (prefix + 'conv_offset.bias' not in state_dict
and prefix[:-1] + '_offset.bias' in state_dict):
state_dict[prefix +
'conv_offset.bias'] = state_dict.pop(prefix[:-1] +
'_offset.bias')
if version is not None and version > 1:
print_log(
f'DeformConv2dPack {prefix.rstrip(".")} is upgraded to '
'version 2.',
logger='root')
super()._load_from_state_dict(state_dict, prefix, local_metadata,
strict, missing_keys, unexpected_keys,
error_msgs)- Example: 模型无痛迁移
如果在 MMDetection 中训练了一个 detector,MMDetection3D 中的多模态检测器想要加载这个预训练的检测器,很多权重名字对不上,又不想写一个脚本手动来转,可以使用 _load_from_state_dict 来进行。通过这种方式,MMDetection3D 可以加载并使用 MMDetection 训练的任意一个检测器。
def _load_from_state_dict(self, state_dict, prefix, local_metadata, strict,
missing_keys, unexpected_keys, error_msgs):
# override the _load_from_state_dict function
# convert the backbone weights pre-trained in Mask R-CNN
# use list(state_dict.keys()) to avoid
# RuntimeError: OrderedDict mutated during iteration
for key_name in list(state_dict.keys()):
key_changed = True
if key_name.startswith('backbone.'):
new_key_name = f'img_backbone{key_name[8:]}'
elif key_name.startswith('neck.'):
new_key_name = f'img_neck{key_name[4:]}'
elif key_name.startswith('rpn_head.'):
new_key_name = f'img_rpn_head{key_name[8:]}'
elif key_name.startswith('roi_head.'):
new_key_name = f'img_roi_head{key_name[8:]}'
else:
key_changed = False
if key_changed:
logger = get_root_logger()
print_log(
f'{key_name} renamed to be {new_key_name}', logger=logger)
state_dict[new_key_name] = state_dict.pop(key_name)
super()._load_from_state_dict(state_dict, prefix, local_metadata,
strict, missing_keys, unexpected_keys,
error_msgs)Reference
- Pytorch nn.Module 文档
- MMCV 中 DCN 的实现
- MMDetection3D