【论文阅读】VulCNN: An Image-inspired Scalable Vulnerability Detection System
论文阅读:VulCNN: An Image-inspired Scalable Vulnerability Detection System
发表:ICSE 2022 - CCF A
领域:代码脆弱性检测 (Vulnerability Detection),卷积神经网络 (CNN)
相关链接:
- Homepage: Yueming Wu
- Paper: https://wu-yueming.github.io/Files/ICSE2022_VulCNN.pdf
- Github: https://github.com/CGCL-codes/VulCNN
文章目录
- 论文阅读:VulCNN: An Image-inspired Scalable Vulnerability Detection System
- Abstract
- 1 Introduction
- 2 Motivation
- 3 System
-
- 3.1 Overview
- 3.2 Graph Extraction and Sentence Embedding
- 3.3 Image Generation
- 3.4 Classification
- 4 EXPERIMENTS
Abstract
为了实现可扩展的漏洞扫描,现有研究直接将源代码视为文本来进行处理。为了实现准确的漏洞检测,还有一些研究考虑将程序语义提炼成图表示,并使用语义图来检测漏洞。在实践中,基于文本的技术是可扩展的,但由于缺乏程序语义而不准确。基于图的方法是准确的,但不可扩展,因为图分析通常很耗时。本文的目标是在扫描大规模源代码漏洞时兼顾可扩展性和准确性。
受基于深度学习的图像分类方法的启发,本文提出了一种新颖的想法,即有效地将源代码转换为"图像",同时保留程序细节。 本文实现了 VulCNN,并在一个包含 13687 个易受攻击函数和 26970 个非易受攻击函数的数据集上对其进行了评估。
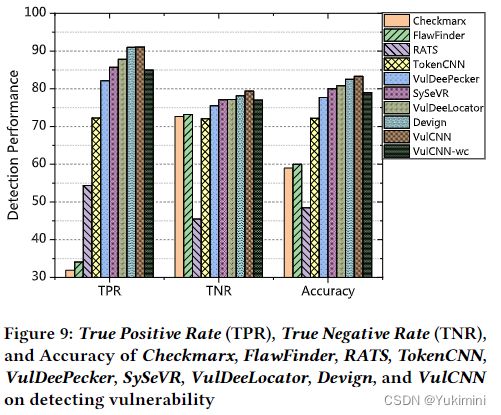
实验结果表明,VulCNN 可以实现比八种最先进的漏洞检测器(即 Checkmarx、FlawFinder、RATS、TokenCNN、VulDeePecker、SySeVR、VulDeeLocator 和 Devign)更好的准确度。至于可扩展性,VulCNN 比 VulDeePecker 和 SySeVR 快约 4 倍,比 VulDeeLocator 快约 15 倍,比 Devign 快约 6 倍。此外,本文还在一个超过 2500 万行的代码上对VulCNN进行评估,结果表明 VulCNN 可以检测到大规模漏洞,通过扫描报告,VulCNN 最终发现了 73 个未在 NVD 中报告的漏洞。
1 Introduction
作为网络空间的重要组成部分,软件系统的漏洞给网络空间带来了严重的安全威胁。 2020 年,Synopsys 开源安全和风险分析 (OSSRA) 检查了来自 1250 多个商业代码库的审计数据,发现这些代码库中 70% 的代码是开源的,并且这些开源代码库中有 75% 包含开源安全漏洞,近一半包含高风险漏洞。因此,迫切需要开展大规模、智能化的软件漏洞检测手段,更好地保护软件安全。
一般来说,源代码漏洞检测方法可以分为两大类,即基于代码相似性的方法和基于模式的方法。基于代码相似度的漏洞检测方法主要用于检测代码克隆产生的漏洞。当用于检测不是由代码克隆产生的漏洞时,会导致较高的误报率。传统的基于模式的漏洞检测方法依靠专家手动定义漏洞规则或特征来描述漏洞,这些方法不仅具有主观性,而且难以同时实现低误报率和低误报率。
近年来,由于深度学习 (DL) 的自动特征提取,被广泛用于检测源代码漏洞。这些基于 DL 的技术属于第二类方法 (即基于模式的方法)。它们不需要专家手动定义功能,并且可以自动生成漏洞模式。例如,一些先前的研究将源代码视为文本,并应用自然语言处理领域的技术来检测漏洞。这些基于文本的方法的检测性能并不理想,因为它们忽略了源代码的程序语义。为了解决这个问题,研究人员进行程序分析,将源代码的程序语义提炼成图形表示,并执行图形分析 (例如,图形神经网络) 来检测漏洞。这些基于图的技术在检测漏洞方面可以实现更高的效率,但是它们的可扩展性比基于文本的方法差得多。此外,几乎所有这些方法都只关注将函数标记为易受攻击或非易受攻击,而无法确定哪些代码行可能更容易受到攻击。在本文中,作者的目标是在检测大规模源代码中的漏洞时同时实现准确性和可扩展性。本文的关键思想源自基于 DL 的图像分类,它可以处理数百万张图像,同时保持高精度,并且分类结果可以通过可视化技术进行解释。具体来说,本文主要解决的一个挑战是:如何在保留程序细节的同时高效地将函数的源代码转换为图像?
解决方案:
- 首先进行程序分析,将函数的程序语义提炼成程序依赖图 (PDG),其中包含源代码的控制流和数据流细节。
- 把 PDG 当作一个社交网络,对网络进行中心性分析,将图结构信息附加到每一行代码中。本文利用三种不同的中心性:度中心性 、katz 中心性和接近中心性。
- 给定生成的图像,训练卷积神经网络模型并使用它来检测漏洞。
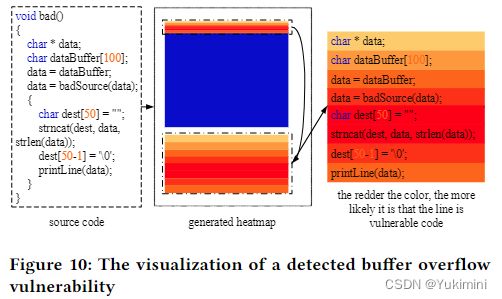
- 为了查明函数中易受攻击的代码行,本文在图像上使用深度可视化技术 (即类激活图) 来获取相应的热图,这些热图可以帮助安全分析师理解为什么函数被标记为脆弱性。
为什么使用三个中心性分析:
- 在社交网络分析中,中心性分析已被提出来衡量网络中节点的重要性。
- 不同的中心性可以从不同的方面维护图的属性。
- 图像通常具有三个通道 (即红色、绿色和蓝色),它们共同作用以产生完整的图像。中心性分析的输出是一张图像,同时从三个方面保留了图的细节。
本文实现了 VulCNN 并在 40657 个函数的数据集上对其进行评估,其中包括 13687 个易受攻击的函数和 26970 个非易受攻击的函数。评估结果表明,VulCNN 可以比 8 个比较漏洞检测器(即 Checkmarx、FlawFinder、RATS、TokenCNN、VulDeePecker、SySeVR、VulDeeLocator 和 Devign。此外,VulCNN 比最先进的基于图的漏洞检测工具 Devign 快六倍以上。为了验证 VulCNN 在大规模漏洞扫描方面的能力,本文对超过 2500 万行代码进行了案例研究。通过扫描报告,最终发现了 73 个未在 NVD 中报告的漏洞。其中,17个已被厂商在对应产品的最新版本中“默默”修补,4个漏洞已被删除,其余52个仍存在于产品中。作者已将这些漏洞报告给他们的供应商,并希望它们能够尽快得到修补。
2 Motivation
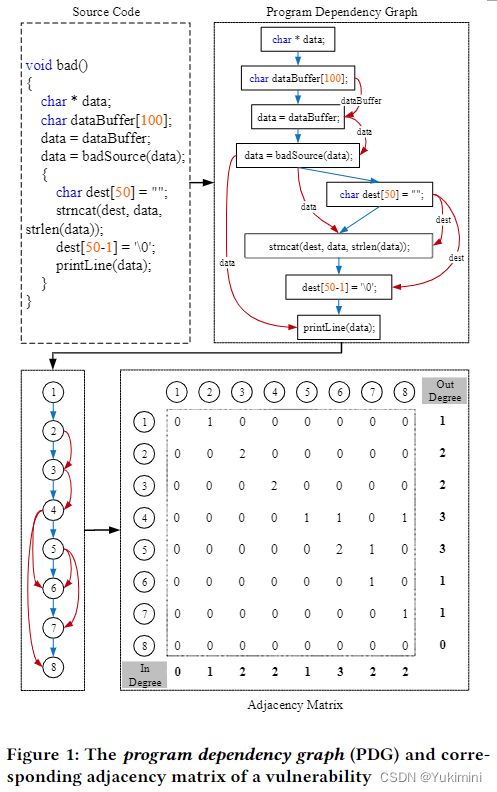
程序依赖图 (PDG) 是一种图形表示,它包含源代码的数据流和控制流详细信息。PDG 中的每个节点对应于漏洞中的一行代码。红线和蓝线分别表示函数中不同代码行之间的数据流和控制流。为了简单地显示漏洞的 PDG,本文将每一行代码替换为带编号的圆形节点。函数中的 8 行代码对应 8 个圆形节点,如图 1 所示。在图论中,邻接矩阵是一个方阵,用于表示一个有限图。为了表示漏洞的 PDG,本文计算相应的邻接矩阵并在图 1 中进行描述。矩阵的元素表示图中节点对是否相邻。由于 PDG 是有向图,因此一个元素表示两个不同节点之间的有向边数。例如,节点 3 有两条边指向节点 4,而节点 4 没有边指向节点 3。因此,矩阵中节点 3 和节点 4 的对应值分别为 2 和 0。
一句话描述,一个图可以用它的邻接矩阵来表示,这个矩阵可以用所有节点的度来描述。因此,计算函数中的代码度数可能是保留图形细节的绝佳选择。在实践中,图中节点的度数最初是用来量化其重要性的。它已广泛用于社交网络分析。学历越高,人越重要。同时,不同的代码行有不同的程度。如果我们把每一行代码看成一个人,把控制流和数据流关系看成人与人之间的交流,那么对应的 PDG 就可以看成一个社交网络。一个人的等级越高,与他交流的人越多,他在 PDG 社交网络中的重要性就越大。因此,可以利用一行代码的重要性作为程序语义贡献的一种形式。换句话说,一行代码越重要,它对实现函数的程序语义(即功能)的贡献就越大。基于观察,本文通过分析所有代码行的重要性来设计 VulCNN。
3 System
3.1 Overview
如图所示,VulCNN 主要由四个阶段组成:图提取 Graph Extraction 、句子嵌入 Sentence Embedding、图像生成 Image Generation 和分类 Classification。
- Graph Extraction:给定一个函数的源代码,首先对其进行归一化,然后进行静态分析,提取函数的程序依赖图 (PDG)。
- Sentence Embedding:PDG 中的每个节点对应函数中的一行代码,作者将一行代码视为一个句子,并将它们嵌入到一个向量中。
- Image Generation:在句子嵌入之后,应用中心性分析来获得所有代码行的重要性并且将它们与向量一一相乘。此阶段的输出是图像。
- Classification:给定生成的图像,首先训练一个 CNN 模型,然后用它来检测漏洞。

3.2 Graph Extraction and Sentence Embedding
由于文件级漏洞检测的粒度较粗,故本文检测函数级别的漏洞。首先对源代码进行抽象和规范化,然后再提取函数的图形表示。
本文使用了三个级别的规范化,这使得 VulCNN 能够适应常见的代码修改,同时保留程序语义。
- 第 1 步:删除源代码中的注释,因为它们与程序语义无关。
- 第 2 步:以一对一的方式将用户定义的变量映射到符号名称(例如,VAR1)。
- 第 3 步:以一对一的方式将用户定义的函数映射到符号名称(例如,FUN1)。
在对源代码进行抽象之后,本文利用 C/C++ 的开源代码分析平台 Joern 来提取函数的程序依赖图 (PDG)。 PDG 中的每个节点对应于函数中的一行代码。本文将一行代码视为一个句子,并应用句子嵌入将其转换为固定长度的向量。具体来说,本文利用 sent2vec 来完成句子嵌入。它采用简单但有效的无监督目标来训练句子的分布式表示。使用 sent2vec 模型,可以将一行代码转换为其相应的向量表示,在论文中其维度为 128。为了更好地说明本文提出的方法中涉及的详细步骤,作者在图 5 中提供了一个示例。图 5 中的红线和蓝线分别表示函数中不同代码行之间的数据流和控制流。


3.3 Image Generation
在图提取和句子嵌入之后,可以得到一个新的 PDG,其中每个节点都是一个向量表示。接下来,本文将 PDG 视为一个社交网络,并应用社交网络中心性分析来获得所有代码行的重要性。
因为图像通常具有三个通道(即红色、绿色和蓝色),它们共同作用以产生完整的图像。故本文选择三个不同的中心性(即Degree centrality、Katz centrality 和 Closeness centrality)来对应三个通道。这三个中心可以从三个不同的方面计算一个函数中所有代码行的重要性。这样,就可以全面考虑不同代码行对函数程序语义的贡献。算法 1 展示了 VulCNN 如何将函数转换为图像的整个过程。如图 5 和算法 1 所示,首先对新 PDG 中的所有节点进行度中心性分析,以收集所有节点(即向量)的度中心性。然后将所有向量乘以相应的度中心性后根据代码行数一一排列。作者将这些排列好的新向量称为"度数通道"。同理,对新的 PDG 应用Katz centrality 和 Closeness centrality 后,就可以得到另外两个通道,分别是 “katz channel” 和 “closeness channel”。最后,这三个通道用于生成图像。
简而言之,图像生成阶段的输入是一个新的 PDG,其中每个节点是一个嵌入向量,输出是具有所有代码行重要性的图像。
3.4 Classification
在图像生成阶段之后,将函数的源代码转换为图像。给定一张图像,本文通过训练 CNN 模型来检测漏洞。由于 CNN 以相同大小的图像作为输入,而不同功能的代码行数不同,故需要进行调整。为了找到更合适的阈值来生成固定大小的图像,作者选择第 4 节中的实验数据集(即 40,657 个函数)作为测试对象,并记录所有这些函数的代码行数。结果显示超过 99% 的函数的代码行数少于 200 行。故本文输入的图像大小为 3∗100∗128,其中 3 对应三个通道,100 对应于代码行的阈值,以及 128 表示句子向量的维度。
4 EXPERIMENTS
以下为本文提出的 VulCNN 模型结果与目前 SOTA 模型结果的对比。最后一幅图展示了本文的另一贡献,即通过热图为程序员判断函数中哪一行代码更易受攻击提供参考。