Pandas基础题一百道(前15)
目录
1、使用List创建Series
2、使用Dict创建Series
3、将Series转换成List
4、将Series转换成DataFrame
5、借助Numpy创建Series
6、转换Series数据类型(要求转换为int)
7、给Series添加新的元素(要求添加物理与化学成绩)
8、Series转换为DataFrame(reset_index)
9、使用字典创建一个DataFrame
10、设置DataFrame索引列
11、生成一个月份的所有天(要求输出2022/3)
12、生成一年的所有周一
13、生成一天当中的所有小时
14、用日期DataFrame
15、使用日期和随机数生成DataFrame
1、使用List创建Series
Series 类似表格中的一个列(column),类似于一维数组,可以保存任何数据类型。
Series构造方法:
pandas.Series( data, index, dtype, name, copy)
-
data:一组数据(ndarray 类型)。
-
index:数据索引标签,如果不指定,默认从 0 开始。
-
dtype:数据类型,默认会自己判断。
-
name:设置名称。
-
copy:拷贝数据,默认为 False。
①:List数据
data=["11","12","45","56"]
②:使用List创建Series
df=pd.Series(data=data)

2、使用Dict创建Series
Series 类似表格中的一个列(column),类似于一维数组,可以保存任何数据类型。
Series构造方法:
pandas.Series( data, index, dtype, name, copy)
-
data:一组数据(ndarray 类型)。
-
index:数据索引标签,如果不指定,默认从 0 开始。
-
dtype:数据类型,默认会自己判断。
-
name:设置名称。
-
copy:拷贝数据,默认为 False。
①:Dict数据
data={
"语文":80,
"数学":90,
"英语":85,
"计算机":100
}
②:使用Dict创建Series
df=pd.Series(data=data)

3、将Series转换成List
Series 类似表格中的一个列(column),类似于一维数组,可以保存任何数据类型。
Series构造方法:
pandas.Series( data, index, dtype, name, copy)
-
data:一组数据(ndarray 类型)。
-
index:数据索引标签,如果不指定,默认从 0 开始。
-
dtype:数据类型,默认会自己判断。
-
name:设置名称。
-
copy:拷贝数据,默认为 False。
①:Series数据
data=pd.Series({
"语文":80,
"数学":90,
"英语":85,
"计算机":100
})
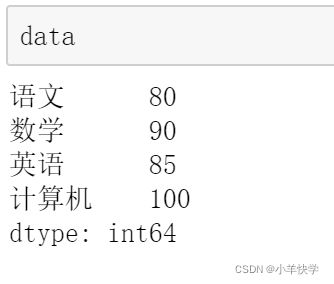
② :将Series转换成List
df=data.tolist()

4、将Series转换成DataFrame
Series:
Series 类似表格中的一个列(column),类似于一维数组,可以保存任何数据类型。
Series构造方法:
pandas.Series( data, index, dtype, name, copy)
-
data:一组数据(ndarray 类型)。
-
index:数据索引标签,如果不指定,默认从 0 开始。
-
dtype:数据类型,默认会自己判断。
-
name:设置名称。
-
copy:拷贝数据,默认为 False。
DataFrame:
DataFrame 是一个表格型的数据结构,它含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔型值)。
DataFrame 既有行索引也有列索引,它可以被看做由 Series 组成的字典(共同用一个索引)。
Pandas DataFrame 是一个二维的数组结构,类似二维数组。
DataFrame构造方法:
pandas.DataFrame( data, index, columns, dtype, copy)
-
data:一组数据(ndarray、series, map, lists, dict 等类型)。
-
index:索引值,或者可以称为行标签。
-
columns:列标签,默认为 RangeIndex (0, 1, 2, …, n) 。
-
dtype:数据类型。
-
copy:拷贝数据,默认为 False。
①:Series数据
data=pd.Series({
"语文":80,
"数学":90,
"英语":85,
"计算机":100
})
②:将Series转换成DataFrame并为列名命名
df=pd.DataFrame(data=data,columns=['grade'])

5、借助Numpy创建Series
Series 类似表格中的一个列(column),类似于一维数组,可以保存任何数据类型。
Series构造方法:
pandas.Series( data, index, dtype, name, copy)
-
data:一组数据(ndarray 类型)。
-
index:数据索引标签,如果不指定,默认从 0 开始。
-
dtype:数据类型,默认会自己判断。
-
name:设置名称。
-
copy:拷贝数据,默认为 False。
import numpy as np
s=pd.Series(
np.arange(10,100,10),
index=np.arange(101,110),
dtype='float'
)

6、转换Series数据类型(要求转换为int)
Series 类似表格中的一个列(column),类似于一维数组,可以保存任何数据类型。
Series构造方法:
pandas.Series( data, index, dtype, name, copy)
-
data:一组数据(ndarray 类型)。
-
index:数据索引标签,如果不指定,默认从 0 开始。
-
dtype:数据类型,默认会自己判断。
-
name:设置名称。
-
copy:拷贝数据,默认为 False。

方法一:astype方法
s=s.astype(int)
方法二:map方法
s=s.map(int)
区别:astype方法里的int是int类型,map方法里的int是一个函数
7、给Series添加新的元素(要求添加物理与化学成绩)

data.append(pd.Series({
"物理":20,"化学":10
}))

8、Series转换为DataFrame(reset_index)
DataFrame 是一个表格型的数据结构,它含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔型值)。
DataFrame 既有行索引也有列索引,它可以被看做由 Series 组成的字典(共同用一个索引)。
Pandas DataFrame 是一个二维的数组结构,类似二维数组。
DataFrame构造方法:
pandas.DataFrame( data, index, columns, dtype, copy)
-
data:一组数据(ndarray、series, map, lists, dict 等类型)。
-
index:索引值,或者可以称为行标签。
-
columns:列标签,默认为 RangeIndex (0, 1, 2, …, n) 。
-
dtype:数据类型。
-
copy:拷贝数据,默认为 False。
①:将Series转换为DataFrame(用.reset_index()方法)
df=data.reset_index()

②:更换列名 (用columns方法)
df.columns=["course","grade"]

9、使用字典创建一个DataFrame
data=pd.DataFrame({
"姓名":["小杨","小孙","小陈"],
"年龄":[18,18,18]
})

注意:
也可以创建一列一行的DataFrame,数据外面的中括号不可省略。

10、设置DataFrame索引列

data=pd.DataFrame({
"姓名":["小杨","小孙","小陈"],
"年龄":[18,18,18],
"爱好":["打蠢蠢","吃饭","打游戏"]
})# inplace=True表示直接在data数据上修改输出,inplace=False表示返回一个新的data输出
data.set_index("姓名",inplace=True)

11、生成一个月份的所有天(要求输出2022/3)
date_range()是pandas中常用的函数,用于生成一个固定频率的DatetimeIndex时间索引
date_range()语法:
date_range(start=None, end=None, periods=None, freq=None, tz=None, normalize=False, name=None, closed=None, **kwargs)
start:生成日期的左侧边界(开始日期)
end:生成日期的右侧边界(结束日期)
periods:生成周期(多少天)
freq:频率
tz:返回本地化的DatetimeIndex时区名
normalize:生成日期之前,将开始/结束时间初始化为午夜
name:产生的DatetimeIndex的名字
closed:使区间相对于给定频率左闭合、右闭合、双向闭合(默认的None)
**kwargs:为了兼容性,对结果没有影响
date_range方法的第一种参数用法:
date_range=pd.date_range(start="2022-3-1",end="2022-3-31")

date_range方法的第二种参数用法:
date_range=pd.date_range(start="2022-3-1",periods=31)
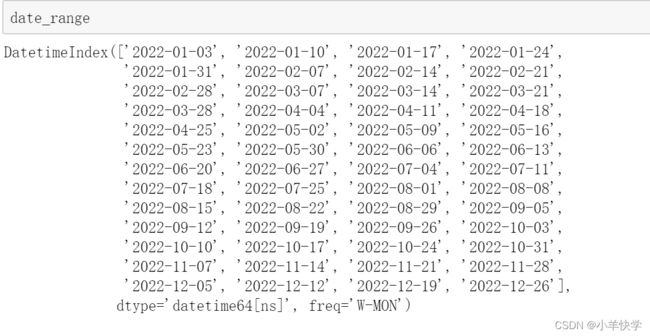
12、生成一年的所有周一
星期一:Monday
星期二:TuesDay
星期三:Wednesday
星期四:Thursday
星期五:Friday
星期六:Saturday
星期日:Sunday
date_range()语法:
date_range(start=None, end=None, periods=None, freq=None, tz=None, normalize=False, name=None, closed=None, **kwargs)
start:生成日期的左侧边界(开始日期)
end:生成日期的右侧边界(结束日期)
periods:生成周期(多少天)
freq:频率
date_range=pd.date_range(start="2022-1-1",end="2022-12-31",freq="W-MON")
13、生成一天当中的所有小时
date_range()语法:
date_range(start=None, end=None, periods=None, freq=None, tz=None, normalize=False, name=None, closed=None, **kwargs)
start:生成日期的左侧边界(开始日期)
end:生成日期的右侧边界(结束日期)
periods:生成周期(多少天)
freq:频率
date_range=pd.date_range(start="2022-1-1",periods=24,freq="H")
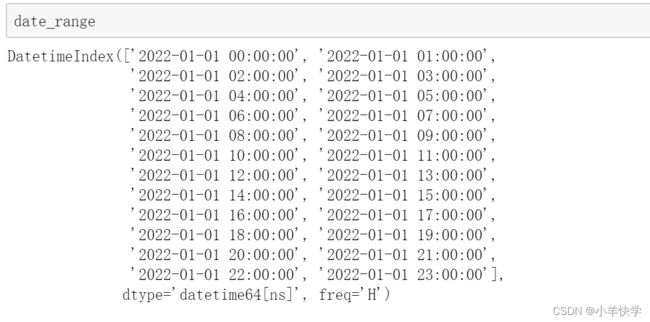
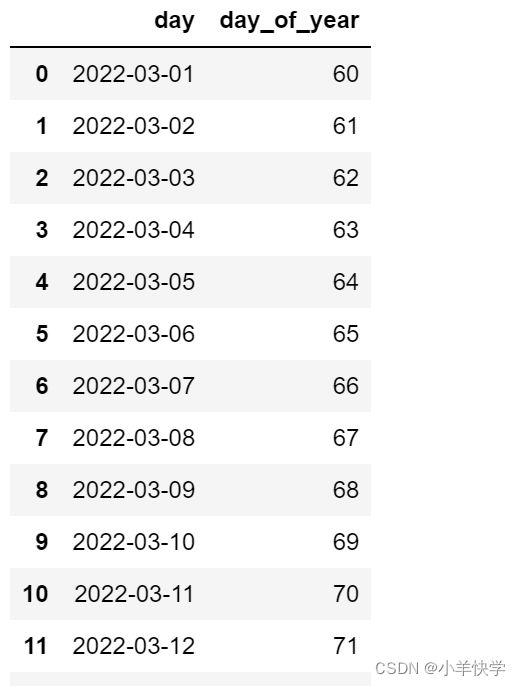
14、用日期DataFrame
①:使用date_range()生成日期
date_range=pd.date_range(start="2022-3-1",periods=31)

②:转成DataFrame
data=pd.DataFrame(data=date_range,columns=['day'])

③在此基础上扩展:基于日期时间的数据中的一年的序号(比如3月1号是2022年的第六十天)
.dt.dayofyear属性
data['day_of_year']=data['day'].dt.dayofyear
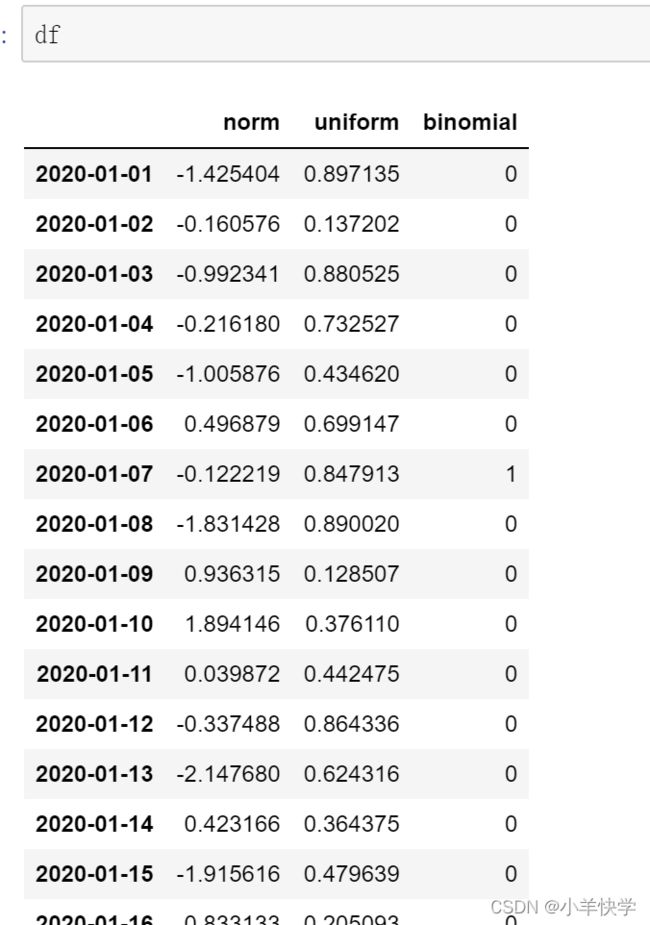
15、使用日期和随机数生成DataFrame
要求:输出一个DataFarame,包含三列
- 正态分布:1000个随机数,loc=0,scale=1
- 均匀分布:1000个随机数,low=0,high=1
- 二项分布:1000个随机数,n=1,p=0.2
①:数据
date_range=pd.date_range(start="2020-1-1",periods=1000)

②: 输出一个DataFrame,包含三列
data={
'norm':np.random.normal(loc=0,scale=1,size=1000),
'uniform':np.random.uniform(low=0,high=1,size=1000),
'binomial':np.random.binomial(n=1,p=0.2,size=1000)
}df=pd.DataFrame(data=data,index=date_range)