分布式全局唯一ID (学习总结---从入门到深化)
目录
分布式全局唯一ID
何为 ID
为什么需要分布式ID
分布式全局唯一ID解决方案
UUID
依靠数据库自增字段生成
号段模式
Redis自增key方案
雪花算法(SnowFlake)
分布式全局唯一ID_什么是雪花算法SonwFlake
雪花算法作用
SnowFlake算法优点
SnowFlake算法的缺点
雪花算法组成
分布式全局唯一ID实现_雪花算法SonwFlake落地实现
Hutool简介
引入相关依赖
Snowflake
雪花算法SpringBoot引用
分布式全局唯一ID实现_雪花算法SonwFlake落地实现之 Mybatis Plus
分布式全局唯一ID

何为 ID
日常开发中,我们需要对系统中的各种数据使用 ID 唯一表示,比如 用户 ID 对应且仅对应一个人,商品 ID 对应且仅对应一件商品,订 单 ID 对应且仅对应一个订单。
为什么需要分布式ID
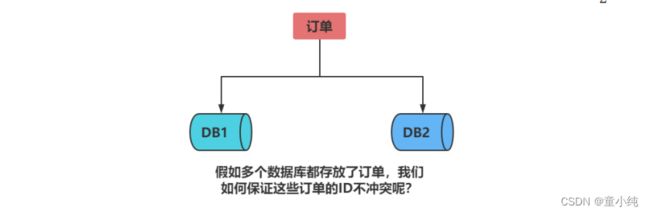
随着系统数据量越来越大,单数据库压力太大无法维持性能,所以 可能就需要变成一主多从这样读写分离,随着继续扩大一主多从也 无法支撑了。这时就需要分库分表,这样的话就会出现不同库表之 间的数据id不能再依赖数据库自增的id,而需要外部一种方式生成全局统一的唯一id。
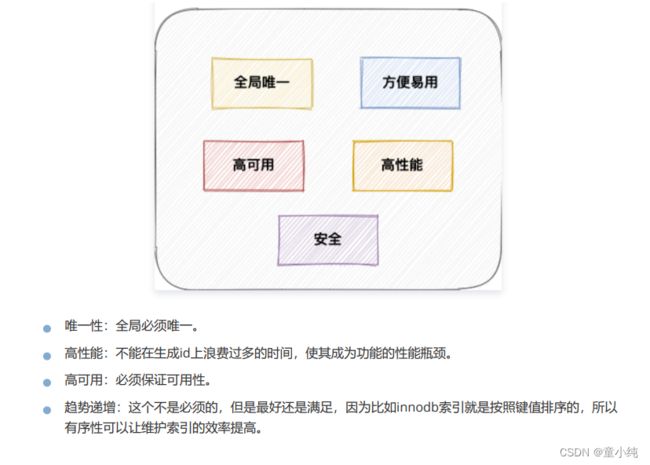
分布式ID需要满足什么条件
分布式全局唯一ID解决方案

UUID
Java本身提供了UUID,这是一个唯一的字符串,它可以不依赖其他 工具在本地生成。

依靠数据库自增字段生成
一个数据库压力大就搞多个数据库,之后搞一个Step步长的概念, 每个数据库的自增起始值不同,但是他们的增长Step相同。如下图所示。
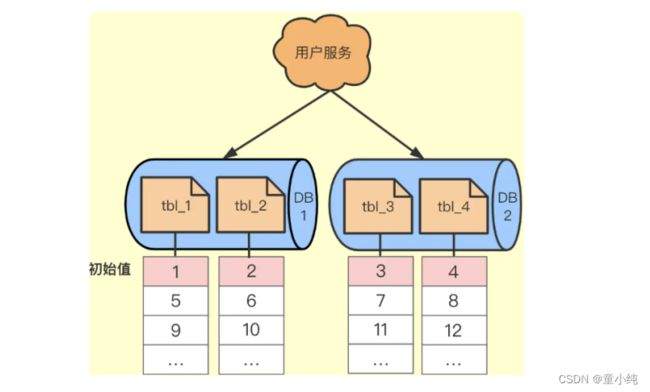
优点
返回的分布式ID是趋势递增的id唯一。解决了单点问题,即使一个 宕机其他的还可以提供服务。
缺点
单点压力还是很大,因为DB本身写操作就耗时间。最主要的问题还 是扩容困难,比如要加一台DB3是很难加进来的,除非停机,将所 有DB的id进行修改,同时修改步长。
号段模式
它没有采用新插入记录返回id的方案,而是一个业务类型就是一行 数据,用一行数据来维护这个业务的自增id。服务来修改这行数据 的max_id,比如当前max_id值是0,那么来给max_id加上1000, 如果返回成功,就代表这个服务获得了1-1000这段分布式id,之后 将这段缓存在服务内部,用光之后再来表中取。
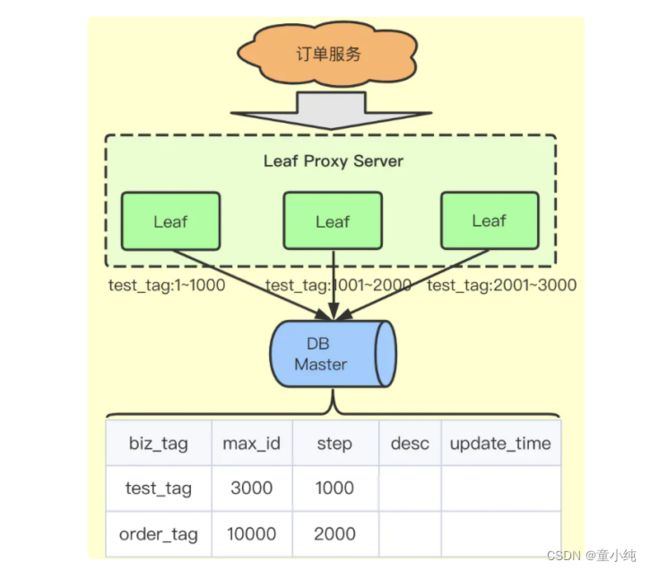
优点
效率很高,db的压力减小,而且一张表可以维护很多业务的分布式 id。
缺点
复杂性提高,需要系统为了这个生成方案对号段进行缓存。
Redis自增key方案
通过incr命令让一个key自增,自增后的值作为分布式id。

优点
1、有序递增,可读性强
2、性能较高
缺点
1、占用带宽,依赖Redis
雪花算法(SnowFlake)
SnowFlake生成的是一个Long类型的值,Long类型的数据占用8个 字节,也就是64位。SnowFlake将64进行拆分,每个部分具有不同 的含义,当然机器码、序列号的位数可以自定义也可以。

优点
本地生成,不依赖中间件。 生成的分布式id足够小,只有8个字节,而且是递增的。
缺点
时钟回拨问题,强烈依赖于服务器的时间,如果时间出现时间回拨 就可能出现重复的id。
分布式全局唯一ID_什么是雪花算法SonwFlake

Snowflake常称为雪花算法,是Twitter开源的分布式ID生成算法, 生成后是一个64bit的long型数值,组成部分引入了时间戳,基本保持了自增。
雪花算法作用

SnowFlake算法优点

SnowFlake算法的缺点
依赖系统时间,如果系统时间被回调,或者改变,可能会造成ID冲 突或者重复
雪花算法组成


分布式全局唯一ID实现_雪花算法SonwFlake落地实现

Hutool简介
Hutool是一个小而全的Java工具类库,通过静态方法封装,降低相 关API的学习成本,提高工作效率,使Java拥有函数式语言般的优 雅,让Java语言也可以“甜甜的”。
引入相关依赖
hutool工具包已经提供雪花算法ID生成的工具类。
cn.hutool
hutool-all
5.7.13
Snowflake
分布式系统中,有一些需要使用全局唯一ID的场景,有些时候我们 希望能使用一种简单一些的ID,并且希望ID能够按照时间有序生 成。Twitter的Snowflake 算法就是这种生成器。
//参数1为机器标识
//参数2为数据标识
Snowflake snowflake = IdUtil.getSnowflake(1,1);
long id = snowflake.nextId();
//简单使用
long id = IdUtil.getSnowflakeNextId();
String id = snowflake.getSnowflakeNextIdStr();
雪花算法SpringBoot引用
config文件
package com.example.demo.config;
import cn.hutool.core.lang.Snowflake;
import cn.hutool.core.net.NetUtil;
import cn.hutool.core.util.IdUtil;
import lombok.extern.slf4j.Slf4j;
import org.springframework.stereotype.Component;
import javax.annotation.PostConstruct;
@Slf4j
@Component
public class IdGeneratorSnowflake {
private long workerId = 0; //第几号机房
private long datacenterId = 1; //第几号机器
private Snowflake snowflake = IdUtil.getSnowflake(workerId, datacenterId);
@PostConstruct //构造后开始执行,加载初始化工作
public void init(){
try{
//获取本机的ip地址编码
workerId = NetUtil.ipv4ToLong(NetUtil.getLocalhostStr());
log.info("当前机器的workerId: " + workerId);
}catch (Exception e){
e.printStackTrace();
log.warn("当前机器的workerId获取失败 ----> " + e);
workerId = NetUtil.getLocalhostStr().hashCode();
}
}
/**
* 生成id
* @return
*/
public synchronized long snowflakeId(){
return snowflake.nextId();
}
}
分布式全局唯一ID实现_雪花算法SonwFlake落地实现之 Mybatis Plus

初始化工程
org.springframework.boot
spring-boot-starter
org.projectlombok
lombok
true
com.baomidou
mybatis-plus-boot-starter
3.4.2
mysql
mysql-connector-java
org.springframework.boot
spring-boot-starter-test
test
org.junit.vintage
junit-vintage-engine
开启MapperScan扫描
在 Spring Boot 启动类中添加 @MapperScan 注解,扫描 Mapper 文件 夹:
@SpringBootApplication
@MapperScan("com.itbaizhan.sonwflake.mapper")
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class,args);
}
}
编码
编写实体类 User.java
@Data
public class User {
@TableId(type = IdType.ASSIGN_ID)// 雪花算法
private Long id;
private String name;
private Integer age;
private String email;
}编写Mapper
public interface UserMapper extends
BaseMapper {
} 添加测试类
@Test
void createUser() {
User user = new User();
user.setName("张三");
user.setAge(18);
user.setEmail("[email protected]");
userMapper.insert(user);
}