c++上部署tensorflow2.X模型
近期在整理各种框架下模型部署的问题,大多数情况下,模型的设计和训练是在python环境下完成的,但是在实际应用中,由于各种需求,python下训练出来的模型无法直接上线使用。楼主的应用主要是在c++环境中,tf1.x版本的pb模型在c++与opencv环境下部署的教程已经相对比较完善了,但是对于新出的tf2.X版本,还是有些坑的
环境
win7 + vs2017 + tensorflow2.3 + opencv4.4
其他环境匹配还需自行测试,试验过程中有不少错误是因为版本问题,尤其tensorflow用的比较新,刚开始时用的opencv4.1,加载pb文件会出错
Python下工作
模型使用tensorflow教程中的卷积神经网络,数据使用fashion-mnist https://tf.wiki/zh_hans/basic/models.html#cnn
cnn.py 模型定义
#cnn.py
import tensorflow as tf
import numpy as np
class CNN(tf.keras.Model):
def __init__(self):
super().__init__()
self.conv1 = tf.keras.layers.Conv2D(
filters=32, # 卷积层神经元(卷积核)数目
kernel_size=[5, 5], # 感受野大小
padding='same', # padding策略(vaild 或 same)
activation=tf.nn.relu # 激活函数
)
self.pool1 = tf.keras.layers.MaxPool2D(pool_size=[2, 2], strides=2)
self.conv2 = tf.keras.layers.Conv2D(
filters=64,
kernel_size=[5, 5],
padding='same',
activation=tf.nn.relu
)
self.pool2 = tf.keras.layers.MaxPool2D(pool_size=[2, 2], strides=2)
self.flatten = tf.keras.layers.Reshape(target_shape=(7 * 7 * 64,))
self.dense1 = tf.keras.layers.Dense(units=1024, activation=tf.nn.relu)
self.dense2 = tf.keras.layers.Dense(units=10)
@tf.function
def call(self, inputs):
x = self.conv1(inputs) # [batch_size, 28, 28, 32]
x = self.pool1(x) # [batch_size, 14, 14, 32]
x = self.conv2(x) # [batch_size, 14, 14, 64]
x = self.pool2(x) # [batch_size, 7, 7, 64]
x = self.flatten(x) # [batch_size, 7 * 7 * 64]
x = self.dense1(x) # [batch_size, 1024]
x = self.dense2(x) # [batch_size, 10]
output = tf.nn.softmax(x)
return outputdata_pipline.py 数据加载
#data_pipline.py
class MNISTLoader():
def __init__(self):
mnist = tf.keras.datasets.mnist
(self.train_data,self.train_label),(self.test_data, self.test_label) = mnist.load_data()
self.train_data = np.expand_dims(self.train_data.astype(np.float32) / 255.0, axis = -1)
self.test_data = np.expand_dims(self.test_data.astype(np.float32) / 255.0, axis = -1)
self.train_label = self.train_label.astype(np.int32)
self.test_label = self.test_label.astype(np.int32)
self.num_train_data, self.num_test_data = self.train_data.shape[0], self.test_data.shape[0]
def get_batch(self, batch_size):
inx = np.random.randint(0,self.num_train_data,batch_size)
return self.train_data[inx,:],self.train_label[inx]train.py 模型训练和测试,注意保存的模型格式
#train.py
import tensorflow as tf
import numpy as np
from data_pipline import MNISTLoader
from cnn import CNN
import argparse
parser = argparse.ArgumentParser(description='Process some integers')
parser.add_argument('--mode', default='test', help = 'train or test')
parser.add_argument('--num_epochs', default=1)
parser.add_argument('--batch_size', default=50)
parser.add_argument('--learning_rate', default=0.001)
parser.add_argument('--pretraind',default=True)
args = parser.parse_args()
data_loader = MNISTLoader()
def train():
model = CNN()
if args.pretraind ==True:
model = tf.saved_model.load('model')
optimizer = tf.keras.optimizers.Adam(learning_rate = args.learning_rate)
num_batches = int(data_loader.num_train_data//args.batch_size*args.num_epochs)
checkpoint = tf.train.Checkpoint(savedModel = model)
for batch_inx in range(num_batches):
X, y = data_loader.get_batch(args.batch_size)
with tf.GradientTape() as tape:
y_pred = model(X)
loss = tf.keras.losses.sparse_categorical_crossentropy(y_true=y, y_pred=y_pred)
loss = tf.reduce_mean(loss)
print("batch %d: loss %f"%(batch_inx, loss.numpy()))
grads = tape.gradient(loss, model.variables)
optimizer.apply_gradients(grads_and_vars=zip(grads,model.variables))
# path = checkpoint.save('./save/model.ckpt')
# print('model saved to %s'%path)
tf.saved_model.save(model,'model')//要在c++端部署时,需使用该模式进行保存
def test():
#整体模型模式
model = tf.saved_model.load('model')
#ckpt模式
# model = CNN()
# checkpoint = tf.train.Checkpoint(savedModel = model)
# checkpoint.restore(tf.train.latest_checkpoint('./save'))
y_pred = np.argmax(model(data_loader.test_data), axis=-1)
print("test accuracy: %f" % (sum(y_pred == data_loader.test_label) / data_loader.num_test_data))
import time
if __name__ =='__main__':
if args.mode == 'train':
train()
if args.mode =='test':
t1 = time.clock()
test()
print('test time: ',time.clock()-t1)保存,在模型目录下生成如下三个文件

这里需要注意,虽然也有一个pb文件,但是这个文件里面只有模型结构,没有模型参数,参数在“variables”里,而且在opencv中只能加载tf1.x中静态图模式的参数,因此需要将该保存的模型转换成静态图模式的pb文件,代码如下
frozen_graph.py 实现静态图转换,生成一个frozen_graph.pb文件,该文件与tf1.x生成的pb文件类似,里面具备完整的图结构和所有参数
#frozen_graph.py
import tensorflow as tf
from tensorflow.python.framework.convert_to_constants import convert_variables_to_constants_v2
loaded = tf.saved_model.load('model')
infer = loaded.signatures['serving_default']
f = tf.function(infer).get_concrete_function(input_1=tf.TensorSpec(shape=[None, 28, 28, 1], dtype=tf.float32))
f2 = convert_variables_to_constants_v2(f)
graph_def = f2.graph.as_graph_def()
# Export frozen graph
with tf.io.gfile.GFile('frozen_graph.pb', 'wb') as f:
f.write(graph_def.SerializeToString())c++下工作
将frozen_graph.pb放到工作目录下,在c++端进行测试
#include "pch.h"
#include
#include
#include
#include
using namespace cv;
using namespace dnn;
using namespace std;
int main()
{
//String textGraph = "frozen_graph.pbtxt";
String modelWeights = "frozen_graph.pb";
Net net = readNetFromTensorflow(modelWeights);
net.setPreferableBackend(DNN_BACKEND_OPENCV);
net.setPreferableTarget(DNN_TARGET_CPU);
Mat img = imread("1.png",0);
resize(img, img, Size(28, 28));
Mat blob = blobFromImage(img, 1.0 / 255, Size(28, 28), Scalar(0, 0, 0), false, false);
net.setInput(blob);
cout << blob.size << endl;
Mat out;
out = net.forward();
cout << out << endl;
} c++下的输出如下
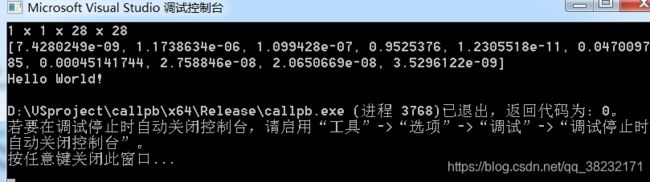
在python下的opencv测试

得到类别结果是一样的,但是输出的概率略有不同,还不知道是什么原因,这个问题是不是普遍存在啊?
目前在试paddle,感觉训练和部署都挺方便的,后续有时间也整理一下