基于用户的协同过滤推荐算法的实现--以电影推荐为例
基于用户的协同过滤推荐算法的实现--以电影推荐为例
- 数据集描述
- 余弦相似度
- 实现过程描述
- 完整代码
数据集描述
数据包括:movies.csv和ratings.csv。movies.csv文档中包含三列属性,分别是movieId电影序号、title电影名称和genres电影类型。movies.csv文档中包含四列属性,分别是userId用户序号、movieId电影序号,rating用户评分(0.5-5,分值越高代表越好)第四列属性不用考虑。在该电影系统中使用了610个用户为9742部电影打分,生成了100836行的数据集。

余弦相似度
公式引用了博客园蝈蝈俊的文章《余弦相似度Cosine Similarity相关计算公式 》中写的文章,文末附链接。
假定A和B是两个n维向量,A是 [A1, A2, …, An] ,B是 [B1, B2, …, Bn] ,则A与B的夹角θ的余弦等于:
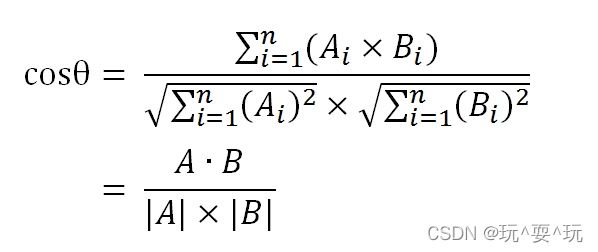
根据公式,我写了计算两用户之间的余弦相似度,代码如下:
def CosFunction(test, user): # 计算两用户之间余弦相似度
sum1 = 0
sum2 = 0
sum3 = 0
for i in range(len(test)):
sum1 = sum1 + test[i] * user[i]
sum2 = sum2 + math.pow(test[i],2)
sum3 = sum3 + math.pow(user[i],2)
CosTotal = sum1/ (math.sqrt(sum2) * math.sqrt(sum3))
# print(CosTotal)
return CosTotal
实现过程描述
首先我们对读取文件,用list二维列表保存电影和用户对电影的评分结果
行表示电影和用户对电影的评分,列为电影的属性和评分结果
用movies,ratings分别存储两个函数返回的结果。
def read_movie(filename):
with open (filename, encoding='utf-8') as f:
reader = csv.reader(f)
movies = [[row[0],row[1],row[2]] for row in reader]
return movies
def read_userRating(filename):
# userId, movieId, rating, timestamp
with open(filename, encoding='utf-8')as f:
reader = csv.reader(f)
ratings = [[row[0], row[1], row[2]] for row in reader]
return ratings
之后我们根据电影和评分列表数据生成每个用户对看过的电影的评分列表
def ratingsArray(movies, ratings): # 生成评分矩阵
user_rating_array = []
number = 0
user_rating_list = []
for userRating in ratings: # 建立用户的评分列表集合
if str(number) == userRating[0]:
user_rating_list.append([userRating[1], userRating[2]])
# print(number,userRating[0],userRating[1], userRating[2])
else:
user_rating_array.append([number, user_rating_list])
# print(number, user_rating_list)
user_rating_list = []
number = number + 1
user_rating_list.append([userRating[1], userRating[2]])
user_rating_array.append([number, user_rating_list]) # 添加最后一个
# print(user_rating_array)
return user_rating_array
评分列表显示如下
在为目标用户选出推荐的电影之前,我们先生成单个用户对所有电影的评分矩阵.
用户传入单个用户对看过电影评分的列表,根据所有电影生成用户对所有电影的评分矩阵。
def GetAllMovieRating(user_rating, movies): # 单个用户对九千多部电影的评分矩阵
userAllMovieRating = []
# print(user_rating)
for movie in movies:
movieId = movie[0]
userRating = 0
for userMovieId, userMovieRating in user_rating:
if movieId == userMovieId:
userRating = float(userMovieRating)
break
userAllMovieRating.append(userRating)
userAllMovieRating[0] = 0 # 把下标为0项置为0 下标为0不代表是电影
return userAllMovieRating
评分结果显示如下,对于没看过的电影,评分为0。一行为一个用户对所有电影的评分。

我们选取用户id为10的用户作为目标用户,根据所有用户的评分数据集,找到与目标用户相似的前20个用户,为目标用户选出推荐的电影。代码思想如下:
首先遍历610个用户,为每个用户生成评分矩阵,并根据每个用户的评分向量求该用户与目标用户的余弦相似度 。用列表保存每个用户的id和该用户与目标用户余弦相似度结果,根据余弦相似度结果排序,选取前20个用户。并用这20个用户的id再一次生成他们对所有电影的评分矩阵,用它们的余弦相似度求和并开平方,方便后面计算推荐电影评分。
def CosSimilarity(UserId, user_rating_list, movies):
testAllMovieRating = GetAllMovieRating(user_rating_list[UserId][1], movies)
print(UserId, testAllMovieRating)
resCos = []
for id in range(len(user_rating_list)):
if id == UserId or id == 0:
continue
userAllMovieRating = GetAllMovieRating(user_rating_list[id][1], movies)
print(id, userAllMovieRating)
# 计算余弦相似度
Cos = CosFunction(testAllMovieRating, userAllMovieRating)
resCos.append([id, Cos])
print(resCos)
# key=(lambda x:x[1]),reverse=True
res1 = sorted(resCos, key = (lambda x:x[1]), reverse = True) # 取前20个与目标用户相似的用户
res1 = res1[:20]
print(res1)
# 求前20个用户的所有电影评分矩阵
res1AllMovieRating = []
for item in res1:
userAllMovieRating = GetAllMovieRating(user_rating_list[item[0]][1], movies)
print(item[0], userAllMovieRating)
res1AllMovieRating.append([item[0], userAllMovieRating])
# 前20个用户的Cos余弦相似度求和
sum2 = 0
for i in range(len(res1)):
sum2 = sum2 + math.sqrt(res1[i][1])
# sum2 = math.sqrt(sum2)
print(sum2)
# 求所有电影对目标用户的推荐评分,目标用户看过的电影推荐评分设置为0
MovieRecommend = []
for i in range(len(testAllMovieRating)):
recommend = 0
sum1 = 0
for j in range(len(res1)):
sum1 = sum1 + res1[j][1] * float(res1AllMovieRating[j][1][i])
recommend = sum1 / sum2
if testAllMovieRating[i] != 0:
recommend = 0
MovieRecommend.append([i,recommend])
print(MovieRecommend)
MovieTop = sorted(MovieRecommend, key = (lambda x:x[1]), reverse=True) # 根据推荐评分对电影排序
print(MovieTop)
Recommend = MovieTop[:20]
print(Recommend)
return Recommend
余弦相似度结果如图所示,我们发现,用户id为159,143的用户和id为10的目标用户比较相似。

推荐评分结果如下图所示,第7373个电影的推荐评分为1.4.

最后返回推荐电影的结果,根据推荐电影的下标号输出推荐电影的名称
对目标用户10推荐结果如下,我们从推荐结果可以看到,该用户比较喜欢看动作类和冒险类的电影。
完整代码
import math
import csv
def read_movie(filename):
with open (filename, encoding='utf-8') as f:
reader = csv.reader(f)
movies = [[row[0],row[1],row[2]] for row in reader]
return movies
def read_userRating(filename):
# userId, movieId, rating, timestamp
with open(filename, encoding='utf-8')as f:
reader = csv.reader(f)
ratings = [[row[0], row[1], row[2]] for row in reader]
return ratings
def ratingsArray(movies, ratings): # 生成评分矩阵
user_rating_array = []
number = 0
user_rating_list = []
for userRating in ratings: # 建立用户的评分列表集合
if str(number) == userRating[0]:
user_rating_list.append([userRating[1], userRating[2]])
# print(number,userRating[0],userRating[1], userRating[2])
else:
user_rating_array.append([number, user_rating_list])
# print(number, user_rating_list)
user_rating_list = []
number = number + 1
user_rating_list.append([userRating[1], userRating[2]])
user_rating_array.append([number, user_rating_list]) # 添加最后一个
# print(user_rating_array)
return user_rating_array
def CosSimilarity(UserId, user_rating_list, movies):
# test_rating_list = user_rating_list[UserId][1]
testAllMovieRating = GetAllMovieRating(user_rating_list[UserId][1], movies)
print(UserId, testAllMovieRating)
# print(test_rating_list)
# print(len(user_rating_list)) # 611个,包含下标0
resCos = []
for id in range(len(user_rating_list)):
if id == UserId or id == 0:
continue
userAllMovieRating = GetAllMovieRating(user_rating_list[id][1], movies)
# print(id, userAllMovieRating)
# 计算余弦相似度
Cos = CosFunction(testAllMovieRating, userAllMovieRating)
resCos.append([id, Cos])
print(resCos)
# key=(lambda x:x[1]),reverse=True
res1 = sorted(resCos, key = (lambda x:x[1]), reverse = True) # 取前20个与目标用户相似的用户
res1 = res1[:20]
print(res1)
# 求前20个用户的所有电影评分矩阵
res1AllMovieRating = []
for item in res1:
userAllMovieRating = GetAllMovieRating(user_rating_list[item[0]][1], movies)
print(item[0], userAllMovieRating)
res1AllMovieRating.append([item[0], userAllMovieRating])
# 前20个用户的Cos余弦相似度求和
sum2 = 0
for i in range(len(res1)):
sum2 = sum2 + math.sqrt(res1[i][1])
# sum2 = math.sqrt(sum2)
print(sum2)
# 求所有电影对目标用户的推荐评分,目标用户看过的电影推荐评分设置为0
MovieRecommend = []
for i in range(len(testAllMovieRating)):
recommend = 0
sum1 = 0
for j in range(len(res1)):
sum1 = sum1 + res1[j][1] * float(res1AllMovieRating[j][1][i])
recommend = sum1 / sum2
if testAllMovieRating[i] != 0:
recommend = 0
MovieRecommend.append([i,recommend])
print(MovieRecommend)
MovieTop = sorted(MovieRecommend, key = (lambda x:x[1]), reverse=True) # 根据推荐评分对电影排序
print(MovieTop)
Recommend = MovieTop[:20]
print(Recommend)
return Recommend
def CosFunction(test, user): # 计算两用户之间余弦相似度
sum1 = 0
sum2 = 0
sum3 = 0
for i in range(len(test)):
sum1 = sum1 + test[i] * user[i]
sum2 = sum2 + math.pow(test[i],2)
sum3 = sum3 + math.pow(user[i],2)
CosTotal = sum1/ (math.sqrt(sum2) * math.sqrt(sum3))
# print(CosTotal)
return CosTotal
def GetAllMovieRating(user_rating, movies): # 单个用户对九千多部电影的评分矩阵
userAllMovieRating = []
# print(user_rating)
for movie in movies:
movieId = movie[0]
userRating = 0
for userMovieId, userMovieRating in user_rating:
if movieId == userMovieId:
userRating = float(userMovieRating)
break
userAllMovieRating.append(userRating)
userAllMovieRating[0] = 0 # 把下标为0项置为0 下标为0不代表是电影
return userAllMovieRating
def RecommendMovies(movies, recommend):
for item, item2 in recommend:
print(movies[item][1], '\t' , movies[item][2])
if __name__=='__main__':
movies = read_movie('movies.csv')
ratings = read_userRating('ratings.csv')
user_rating_list = ratingsArray(movies, ratings)
recommend = CosSimilarity(10, user_rating_list,movies)
RecommendMovies(movies, recommend)
相关链接
https://www.cnblogs.com/ghj1976/p/yu-xian-xiang-shi-ducosine-similarity-xiang-guan-j.html