基于PyG Temporal的DCRNN(扩散卷积递归神经网络)代码实现

论文名称:Diffusion Convolutional Recurrent Neural Network: Data-Driven Traffic Forecasting
论文下载:https://arxiv.org/abs/1707.01926
论文解读: 论文翻译。由于我们这里主要进行论文代码的展示,论文的解读就不进行详细的讲解。
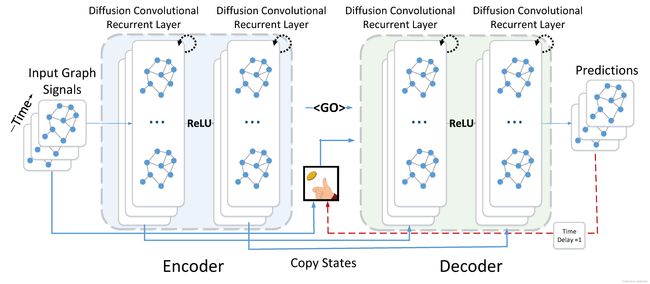
代码
PyG Temporal中提供了大量已经编译好的图卷积递归神经网络模型,DCRNN模型对应的部分如下:

in_channels:代表输入模型进行处理的数据特征的维度,比如想要基于T个历史时间预测T+1时刻道路的交通流量,这里的in_channels=T。
out_channels:经过DCRNN模型处理后输出特征的维度。
K:扩散过程通过在图G上进行随机游走,来聚合节点之间的特征,这个K相当于扩散程度,与GCN中的K相似。
模型主要进行节点的预测任务,给定节点T个时刻的历史特征,通过DCRNN模型来对T+1时刻的节点特征进行预测。节点数为10,节点之间的拓扑结构为随机生成的拓扑结构,通过邻接矩阵A来表示。具体代码实现如下:
import numpy as np
import pandas as pd
import torch
import torch.nn.functional as F
import matplotlib.pyplot as plt
from sklearn.preprocessing import StandardScaler
from sklearn.preprocessing import MinMaxScaler
from torch_geometric_temporal.nn.recurrent import DCRNN
from torch_geometric_temporal import StaticGraphTemporalSignal
from tqdm import tqdm
TRAINING_LENGTH = 72
# 载入节点信息并进行预处理
node_cpu0 = pd.read_csv(r'v.2_data/v.2_CPU.csv', header=None)#(10, 1008)
node_cpu0 = node_cpu0.transpose()#(1008, 10)
node_cpu = np.zeros(node_cpu0.shape, dtype=float)
for j in range(node_cpu0.shape[1]):
for i in range(len(node_cpu0)):
if i == 0:
node_cpu[i, j] = node_cpu0.iloc[i, j]
elif i == len(node_cpu0):
node_cpu[i, j] = node_cpu0.iloc[i, j]
else:
node_cpu[i, j] = np.mean(node_cpu0.iloc[i - 1:i + 2, j])
def clean_train_test_data(traindata, testdata):
# sc = MinMaxScaler()
sc = StandardScaler()
train_data= sc.fit_transform(traindata)
test_data = sc.transform(testdata) # 利用训练集的属性对测试集进行归一化
return train_data, test_data
# 将数据划分为训练集与测试集,前80%的数据作为训练集,后20%的数据作为测试集
train_size = int(len(node_cpu)*0.8)
test_size = len(node_cpu) - train_size
train_data = node_cpu[0:train_size, :]
test_data = node_cpu[train_size:len(node_cpu), :]
train_data, test_data = clean_train_test_data(train_data, test_data)
# print(train_data.shape)(806, 10)
# print(test_data.shape)(202, 10)
train_data = np.array(train_data).transpose()
test_data = np.array(test_data).transpose()
# print(train_data.shape)#(10, 806)
def create_dataset(data, n_sequence):
'''
对数据进行处理
'''
train_X, train_Y = [], []
for i in range(data.shape[1] - n_sequence - 1):
a = data[:, i:(i + n_sequence)]
train_X.append(a)
b = data[:, (i + n_sequence):(i + n_sequence + 1)]
train_Y.append(b.T)
return train_X, train_Y
train_feature, train_target = create_dataset(train_data, 72)
test_feature, test_target = create_dataset(test_data, 72)
edge_index = np.array([[0, 1, 0, 2, 0, 3, 0, 4, 0, 5, 0, 7, 1, 2, 1, 6, 2, 3, 2, 8, 2, 9, 3, 4, 3, 5, 3, 6, 3, 7, 5, 9, 7, 8],
[1, 0, 2, 0, 3, 0, 4, 0, 5, 0, 7, 0, 2, 1, 6, 1, 3, 2, 8, 2, 9, 2, 4, 3, 5, 3, 6, 3, 7, 3, 9, 5, 8, 7]])
train_dataset = StaticGraphTemporalSignal(edge_index=edge_index, edge_weight=np.ones(edge_index.shape[1]), features=train_feature, targets=train_target)
test_dataset = StaticGraphTemporalSignal(edge_index=edge_index, edge_weight=np.ones(edge_index.shape[1]), features=test_feature, targets=test_target)
# train_dataset, test_dataset = temporal_signal_split(dataset, train_ratio=0.75)
# print("Number of train buckets: ", len(set(train_dataset)))
# print("Number of test buckets: ", len(set(test_dataset)))
class RecurrentGCN(torch.nn.Module):
def __init__(self, in_channel, out_channel, K):
super(RecurrentGCN, self).__init__()
self.recurrent = DCRNN(in_channel, out_channel, K)
self.linear = torch.nn.Sequential(
torch.nn.Linear(out_channel, out_channel // 2),
torch.nn.ReLU(inplace=True),
torch.nn.Linear(out_channel // 2, out_channel // 4),
torch.nn.ReLU(inplace=True),
torch.nn.Linear(out_channel // 4, 1))
def forward(self, x, edge_index, edge_weight):
h = self.recurrent(x, edge_index, edge_weight)
h = F.relu(h)
h = F.dropout(h, training=self.training)
h = self.linear(h)
return h
model = RecurrentGCN(in_channel=72, out_channel=36, K=1)
optimizer = torch.optim.Adam(model.parameters(), lr=0.01, weight_decay=5e-4)
cost_list = []
model.train()
'''time为train size'''
for epoch in tqdm(range(300)):
cost = 0
for time, snapshot in enumerate(train_dataset):
y_hat = model(snapshot.x, snapshot.edge_index, snapshot.edge_attr)
y_hat = y_hat.T
cost = cost + torch.mean((y_hat - snapshot.y) ** 2)
# cost = cost + regular_loss(model, lamda=1.5e-3)
cost = cost / (time + 1)
cost_list.append(cost.item())
cost.backward()
optimizer.step()
optimizer.zero_grad()
cost = cost.item()
print("training MSE: {:.4f}".format(cost))
plt.plot(cost_list)
plt.xlabel("Epoch")
plt.ylabel("MSE")
plt.title("average of Training cost for 10 nodes")
plt.show()
model.eval()
cost = 0
test_real = []
test_pre = []
cha = []
for time, snapshot in enumerate(test_dataset):
y_hat = model(snapshot.x, snapshot.edge_index, snapshot.edge_attr)
y_hat = y_hat.T
test_pre.append(y_hat.detach().numpy())
test_real.append(snapshot.y.detach().numpy())
cost = cost + torch.mean((y_hat - snapshot.y) ** 2)
cost = cost / (time + 1)
cost = cost.item()
print("test MSE: {:.4f}".format(cost))
test_real = np.array(test_real)
test_real = test_real.reshape([test_real.shape[0], test_real.shape[2]])
test_pre = np.array(test_pre)
test_pre = test_pre.reshape([test_pre.shape[0], test_pre.shape[2]])
plt.figure(1)
for i in range(test_real.shape[1]):
plt.subplot(3, 4, 1+i)
plt.plot(test_real[:, i].T, label='real data')
plt.plot(test_pre[:, i].T, label='pre data')
plt.xlabel("Time steps")
plt.ylabel("Normalized Value")
plt.suptitle("prediction against truth")
plt.legend()
plt.show()损失函数:

预测结果:
