【PyG】图神经网络GAT代码自学
图方法分为谱方法和空间方法,空间方法是直接在图上进行操作,代表方法之一GAT;谱方法是将图映射到谱域上,例如拉普拉斯矩阵经过特征分解得到的空间,代表方法之一是GCN。本文介绍GAT的代码实现。
本文参考论文原作者代码https://github.com/PetarV-/GAT
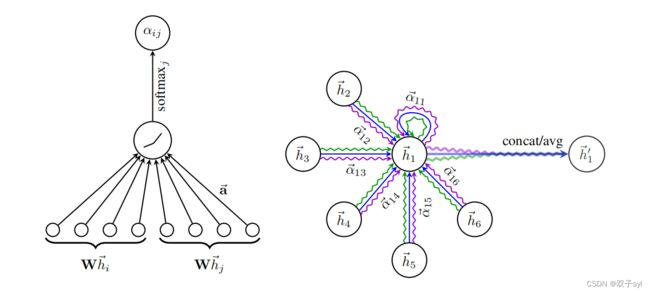
论文原图与核心公式
![]()
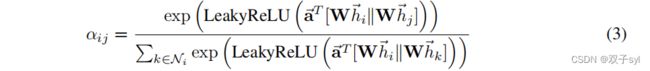

utils相关代码分析
见之前写的GCN那篇博客
https://blog.csdn.net/qq_42859088/article/details/124669794?spm=1001.2014.3001.5501
train相关代码分析
train.py
感觉和之前的gcn没有区别,先setting,再cuda,load_data,然后train,eval,test
from __future__ import division
from __future__ import print_function
import os
import glob
import time
import random
import argparse
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.autograd import Variable
from utils import load_data, accuracy
from models import GAT, SpGAT
# Training settings
parser = argparse.ArgumentParser()
parser.add_argument('--no-cuda', action='store_true', default=False, help='Disables CUDA training.')
parser.add_argument('--fastmode', action='store_true', default=False, help='Validate during training pass.')
parser.add_argument('--sparse', action='store_true', default=False, help='GAT with sparse version or not.')
parser.add_argument('--seed', type=int, default=72, help='Random seed.')
parser.add_argument('--epochs', type=int, default=200, help='Number of epochs to train.')
parser.add_argument('--lr', type=float, default=0.005, help='Initial learning rate.')
parser.add_argument('--weight_decay', type=float, default=5e-4, help='Weight decay (L2 loss on parameters).')
parser.add_argument('--hidden', type=int, default=8, help='Number of hidden units.')
parser.add_argument('--nb_heads', type=int, default=8, help='Number of head attentions.')
parser.add_argument('--dropout', type=float, default=0.6, help='Dropout rate (1 - keep probability).')
parser.add_argument('--alpha', type=float, default=0.2, help='Alpha for the leaky_relu.')
parser.add_argument('--patience', type=int, default=100, help='Patience')
args = parser.parse_args()
args.cuda = not args.no_cuda and torch.cuda.is_available()
random.seed(args.seed)
np.random.seed(args.seed)
torch.manual_seed(args.seed)
if args.cuda:
torch.cuda.manual_seed(args.seed)
# Load data
adj, features, labels, idx_train, idx_val, idx_test = load_data()
# Model and optimizer
args.sparse = False
if args.sparse:
model = SpGAT(nfeat=features.shape[1],
nhid=args.hidden,
nclass=int(labels.max()) + 1,
dropout=args.dropout,
nheads=args.nb_heads,
alpha=args.alpha)
else:
model = GAT(nfeat=features.shape[1],
nhid=args.hidden,
nclass=int(labels.max()) + 1,
dropout=args.dropout,
nheads=args.nb_heads,
alpha=args.alpha)
optimizer = optim.Adam(model.parameters(),
lr=args.lr,
weight_decay=args.weight_decay)
if args.cuda:
model.cuda()
features = features.cuda()
adj = adj.cuda()
labels = labels.cuda()
idx_train = idx_train.cuda()
idx_val = idx_val.cuda()
idx_test = idx_test.cuda()
# features, adj, labels = Variable(features), Variable(adj), Variable(labels)
def train(epoch):
t = time.time()
model.train()
optimizer.zero_grad()
output = model(features, adj) # GAT模块
loss_train = F.nll_loss(output[idx_train], labels[idx_train])
acc_train = accuracy(output[idx_train], labels[idx_train])
loss_train.backward()
optimizer.step()
if not args.fastmode:
# Evaluate validation set performance separately,
# deactivates dropout during validation run.
model.eval()
output = model(features, adj)
loss_val = F.nll_loss(output[idx_val], labels[idx_val])
acc_val = accuracy(output[idx_val], labels[idx_val])
print('Epoch: {:04d}'.format(epoch+1),
'loss_train: {:.4f}'.format(loss_train.data.item()),
'acc_train: {:.4f}'.format(acc_train.data.item()),
'loss_val: {:.4f}'.format(loss_val.data.item()),
'acc_val: {:.4f}'.format(acc_val.data.item()),
'time: {:.4f}s'.format(time.time() - t))
return loss_val.data.item()
def compute_test():
model.eval()
output = model(features, adj)
loss_test = F.nll_loss(output[idx_test], labels[idx_test])
acc_test = accuracy(output[idx_test], labels[idx_test])
print("Test set results:",
"loss= {:.4f}".format(loss_test.item()),
"accuracy= {:.4f}".format(acc_test.item()))
# Train model
t_total = time.time()
loss_values = []
bad_counter = 0
best = args.epochs + 1
best_epoch = 0
for epoch in range(args.epochs):
loss_values.append(train(epoch))
torch.save(model.state_dict(), '{}.pkl'.format(epoch))
if loss_values[-1] < best:
best = loss_values[-1]
best_epoch = epoch
bad_counter = 0
else:
bad_counter += 1
if bad_counter == args.patience:
break
files = glob.glob('*.pkl')
for file in files:
epoch_nb = int(file.split('.')[0])
if epoch_nb < best_epoch:
os.remove(file)
files = glob.glob('*.pkl')
for file in files:
epoch_nb = int(file.split('.')[0])
if epoch_nb > best_epoch:
os.remove(file)
print("Optimization Finished!")
print("Total time elapsed: {:.4f}s".format(time.time() - t_total))
# Restore best model
print('Loading {}th epoch'.format(best_epoch))
model.load_state_dict(torch.load('{}.pkl'.format(best_epoch)))
# Testing
compute_test()
models.py
import torch
import torch.nn as nn
import torch.nn.functional as F
from layers import GraphAttentionLayer, SpGraphAttentionLayer
class GAT(nn.Module):
def __init__(self, nfeat, nhid, nclass, dropout, alpha, nheads):
"""Dense version of GAT."""
super(GAT, self).__init__()
self.dropout = dropout
self.attentions = [GraphAttentionLayer(nfeat, nhid, dropout=dropout, alpha=alpha, concat=True) for _ in range(nheads)]
#nfeat为feature大小也就是idx_features_labels[:, 1:-1]第二列到倒数第二列,nhid自己设定
#for _ in range(nheads)多头注意力机制,这里面nheads为8
for i, attention in enumerate(self.attentions):
self.add_module('attention_{}'.format(i), attention)
#创建8个多头注意力机制模块
self.out_att = GraphAttentionLayer(nhid * nheads, nclass, dropout=dropout, alpha=alpha, concat=False) # 第二层(最后一层)的attention layer
#nhid * nheads输入维度8*8,输出维度当时分的类,这个数据集里面是7个
def forward(self, x, adj):
x = F.dropout(x, self.dropout, training=self.training)
x = torch.cat([att(x, adj) for att in self.attentions], dim=1) # 将每层attention拼接
x = F.dropout(x, self.dropout, training=self.training)
x = F.elu(self.out_att(x, adj)) # 第二层的attention layer
return F.log_softmax(x, dim=1)
layers.py
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
class GraphAttentionLayer(nn.Module):
"""
Simple GAT layer, similar to https://arxiv.org/abs/1710.10903
"""
def __init__(self, in_features, out_features, dropout, alpha, concat=True):
super(GraphAttentionLayer, self).__init__()
self.dropout = dropout
self.in_features = in_features
self.out_features = out_features
self.alpha = alpha
self.concat = concat
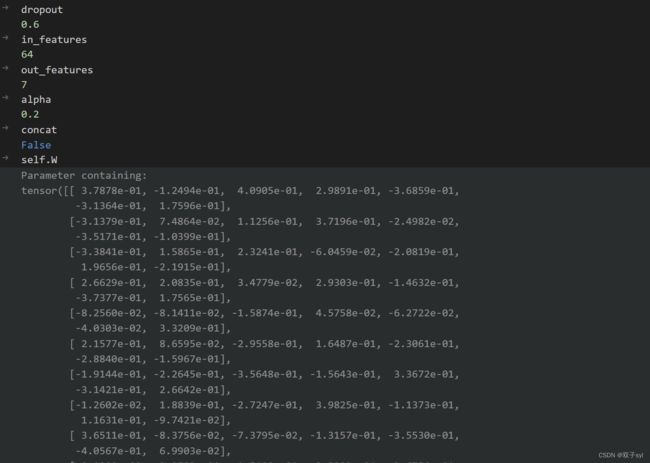
self.W = nn.Parameter(torch.empty(size=(in_features, out_features)))
nn.init.xavier_uniform_(self.W.data, gain=1.414)
#初始化in_features行,out_features列的权重矩阵
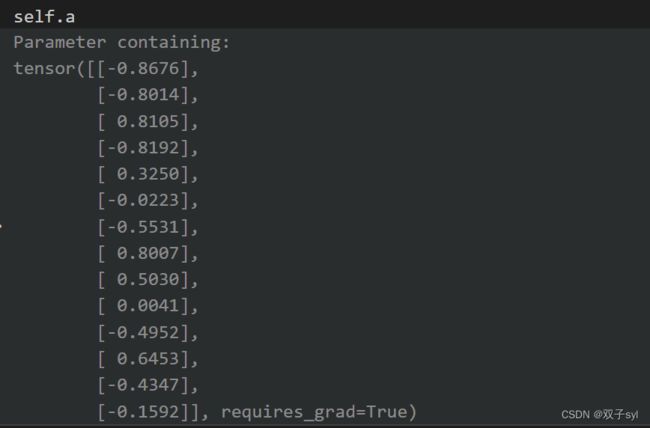
self.a = nn.Parameter(torch.empty(size=(2*out_features, 1))) # concat(V,NeigV)
nn.init.xavier_uniform_(self.a.data, gain=1.414)
#初始化α,大小为两个out_features拼接起来
self.leakyrelu = nn.LeakyReLU(self.alpha)
def forward(self, h, adj):
Wh = torch.mm(h, self.W) # h.shape: (N, in_features), hW.shape: (N, out_features)
a_input = self._prepare_attentional_mechanism_input(Wh) # 每一个节点和所有节点,特征。(Vall, Vall, feature)
e = self.leakyrelu(torch.matmul(a_input, self.a).squeeze(2))
# 之前计算的是一个节点和所有节点的attention,其实需要的是连接的节点的attention系数
zero_vec = -9e15*torch.ones_like(e)
attention = torch.where(adj > 0, e, zero_vec) # 将邻接矩阵中小于0的变成负无穷
attention = F.softmax(attention, dim=1) # 按行求softmax。 sum(axis=1) === 1
attention = F.dropout(attention, self.dropout, training=self.training)
h_prime = torch.matmul(attention, Wh) # 聚合邻居函数
if self.concat:
return F.elu(h_prime) # elu-激活函数
else:
return h_prime
def _prepare_attentional_mechanism_input(self, Wh):
N = Wh.size()[0] # number of nodes
# Below, two matrices are created that contain embeddings in their rows in different orders.
# (e stands for embedding)
# These are the rows of the first matrix (Wh_repeated_in_chunks):
# e1, e1, ..., e1, e2, e2, ..., e2, ..., eN, eN, ..., eN
# '-------------' -> N times '-------------' -> N times '-------------' -> N times
#
# These are the rows of the second matrix (Wh_repeated_alternating):
# e1, e2, ..., eN, e1, e2, ..., eN, ..., e1, e2, ..., eN
# '----------------------------------------------------' -> N times
#
Wh_repeated_in_chunks = Wh.repeat_interleave(N, dim=0) # 复制
Wh_repeated_alternating = Wh.repeat(N, 1)
# Wh_repeated_in_chunks.shape == Wh_repeated_alternating.shape == (N * N, out_features)
# The all_combination_matrix, created below, will look like this (|| denotes concatenation):
# e1 || e1
# e1 || e2
# e1 || e3
# ...
# e1 || eN
# e2 || e1
# e2 || e2
# e2 || e3
# ...
# e2 || eN
# ...
# eN || e1
# eN || e2
# eN || e3
# ...
# eN || eN
all_combinations_matrix = torch.cat([Wh_repeated_in_chunks, Wh_repeated_alternating], dim=1)
# all_combinations_matrix.shape == (N * N, 2 * out_features)
return all_combinations_matrix.view(N, N, 2 * self.out_features)
def __repr__(self):
return self.__class__.__name__ + ' (' + str(self.in_features) + ' -> ' + str(self.out_features) + ')'
原始GAT代码debug调试
GAT初始化
第一层初始化结果
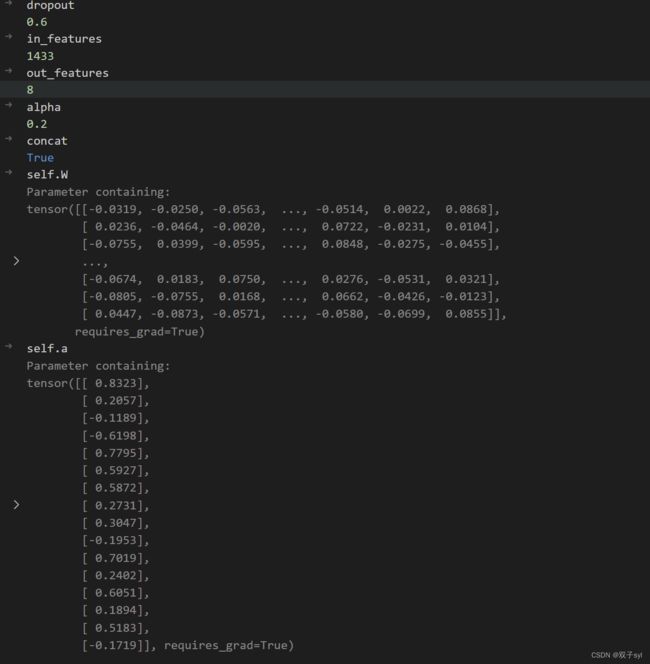
第二层初始化结果
此时多头注意力机制生成8个attention
![]()
第一次训练结果
此时代码debug到layers.py的class GraphAttentionLayer(nn.Module)中forward(self, h, adj)函数
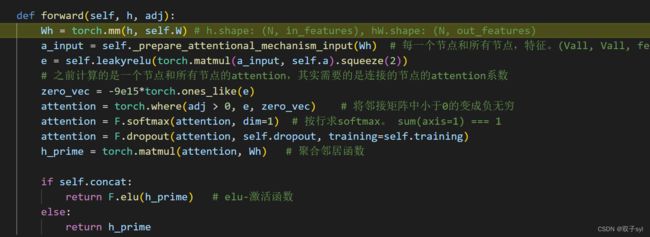
wh为两个矩阵相乘,h.shape: (N, in_features), hW.shape: (N, out_features)

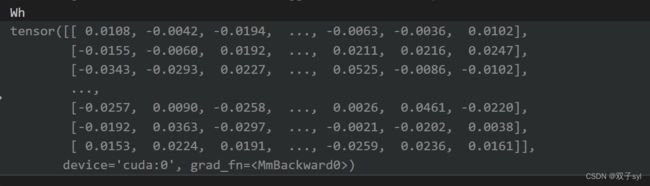
_prepare_attentional_mechanism_input这个函数做的是矩阵拼接操作,每一个节点和所有节点,特征。(Vall, Vall, feature)
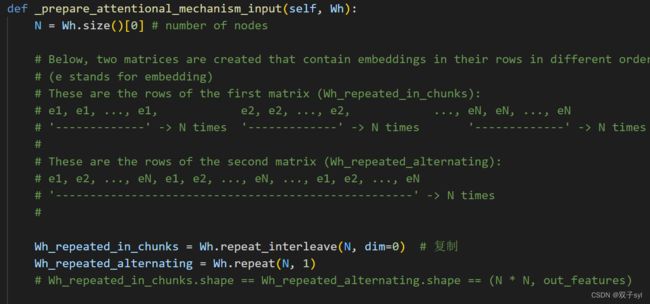
各变量结果如下,此段代码实现了矩阵的拼接,得到矩阵torch.Size([2708, 2708, 16])



e = self.leakyrelu(torch.matmul(a_input, self.a).squeeze(2)), 之前计算的是一个节点和所有节点的attention,其实需要的是连接的节点的attention系数
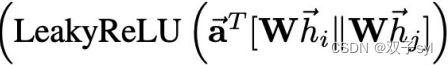

第一个attention将邻接矩阵中小于0的变成负无穷

第二个attention,按行求softmax,sum(axis=1) === 1
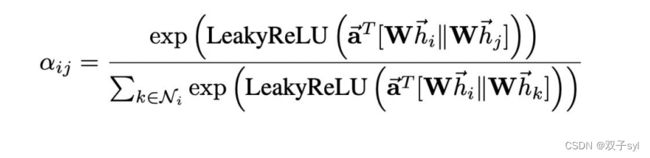
第三个attention聚合邻居函数,h_prime经过激活函数激活的结果

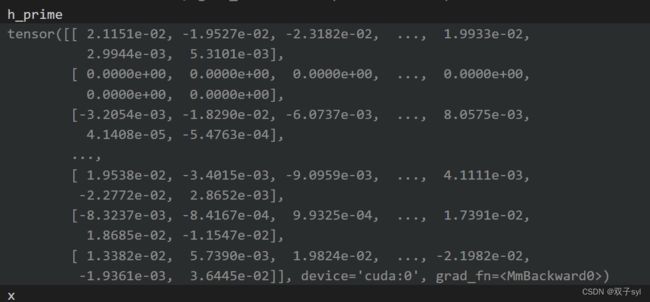
上方代码运行8次,然后拼接起来,此时gpu内存溢出报错,转为使用SpGAT代码。
SpGAT代码
models.py
class SpGAT(nn.Module):
def __init__(self, nfeat, nhid, nclass, dropout, alpha, nheads):
"""Sparse version of GAT."""
super(SpGAT, self).__init__()
self.dropout = dropout
self.attentions = [SpGraphAttentionLayer(nfeat,
nhid,
dropout=dropout,
alpha=alpha,
concat=True) for _ in range(nheads)]
for i, attention in enumerate(self.attentions):
self.add_module('attention_{}'.format(i), attention)
self.out_att = SpGraphAttentionLayer(nhid * nheads,
nclass,
dropout=dropout,
alpha=alpha,
concat=False)
def forward(self, x, adj):
x = F.dropout(x, self.dropout, training=self.training)
x = torch.cat([att(x, adj) for att in self.attentions], dim=1)
x = F.dropout(x, self.dropout, training=self.training)
x = F.elu(self.out_att(x, adj))
return F.log_softmax(x, dim=1)
layers.py
class SpecialSpmmFunction(torch.autograd.Function):
"""Special function for only sparse region backpropataion layer."""
@staticmethod
def forward(ctx, indices, values, shape, b):
assert indices.requires_grad == False
a = torch.sparse_coo_tensor(indices, values, shape)
ctx.save_for_backward(a, b)
ctx.N = shape[0]
return torch.matmul(a, b)
@staticmethod
def backward(ctx, grad_output):
a, b = ctx.saved_tensors
grad_values = grad_b = None
if ctx.needs_input_grad[1]:
grad_a_dense = grad_output.matmul(b.t())
edge_idx = a._indices()[0, :] * ctx.N + a._indices()[1, :]
grad_values = grad_a_dense.view(-1)[edge_idx]
if ctx.needs_input_grad[3]:
grad_b = a.t().matmul(grad_output)
return None, grad_values, None, grad_b
class SpecialSpmm(nn.Module):
def forward(self, indices, values, shape, b):
return SpecialSpmmFunction.apply(indices, values, shape, b)
class SpGraphAttentionLayer(nn.Module):
"""
Sparse version GAT layer, similar to https://arxiv.org/abs/1710.10903
"""
def __init__(self, in_features, out_features, dropout, alpha, concat=True):
super(SpGraphAttentionLayer, self).__init__()
self.in_features = in_features
self.out_features = out_features
self.alpha = alpha
self.concat = concat
self.W = nn.Parameter(torch.zeros(size=(in_features, out_features)))
nn.init.xavier_normal_(self.W.data, gain=1.414)
self.a = nn.Parameter(torch.zeros(size=(1, 2*out_features)))
nn.init.xavier_normal_(self.a.data, gain=1.414)
self.dropout = nn.Dropout(dropout)
self.leakyrelu = nn.LeakyReLU(self.alpha)
self.special_spmm = SpecialSpmm()
def forward(self, input, adj):
dv = 'cuda' if input.is_cuda else 'cpu'
N = input.size()[0]
edge = adj.nonzero().t()
h = torch.mm(input, self.W)
# h: N x out
assert not torch.isnan(h).any()
# Self-attention on the nodes - Shared attention mechanism
edge_h = torch.cat((h[edge[0, :], :], h[edge[1, :], :]), dim=1).t()
# edge: 2*D x E
edge_e = torch.exp(-self.leakyrelu(self.a.mm(edge_h).squeeze()))
assert not torch.isnan(edge_e).any()
# edge_e: E
e_rowsum = self.special_spmm(edge, edge_e, torch.Size([N, N]), torch.ones(size=(N,1), device=dv))
# e_rowsum: N x 1
edge_e = self.dropout(edge_e)
# edge_e: E
h_prime = self.special_spmm(edge, edge_e, torch.Size([N, N]), h)
assert not torch.isnan(h_prime).any()
# h_prime: N x out
h_prime = h_prime.div(e_rowsum)
# h_prime: N x out
assert not torch.isnan(h_prime).any()
if self.concat:
# if this layer is not last layer,
return F.elu(h_prime)
else:
# if this layer is last layer,
return h_prime
def __repr__(self):
return self.__class__.__name__ + ' (' + str(self.in_features) + ' -> ' + str(self.out_features) + ')'
SpGAT代码debug调试
SpGAT初始化
和GAT基本一致,最后一步多了SpecialSpmm类调用SpecialSpmmFunction方法。
第一次训练第一层结果
N = input.size()[0]#行数 2708
edge = adj.nonzero().t()#稀疏矩阵coo创建,edge[0]代表行,edge[1]代表列
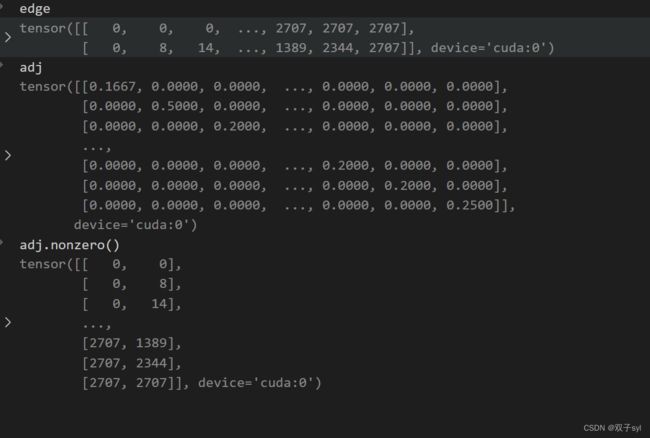
h = torch.mm(input, self.W)# 等价于求Wh
# h: N x out
assert not torch.isnan(h).any(),'可以提示h里面有空值'

# Self-attention on the nodes - Shared attention mechanism
edge_h = torch.cat((h[edge[0, :], :], h[edge[1, :], :]), dim=1).t()
# edge: 2*D x E
edge_h做的是下图矩阵拼接
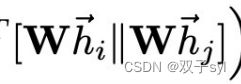
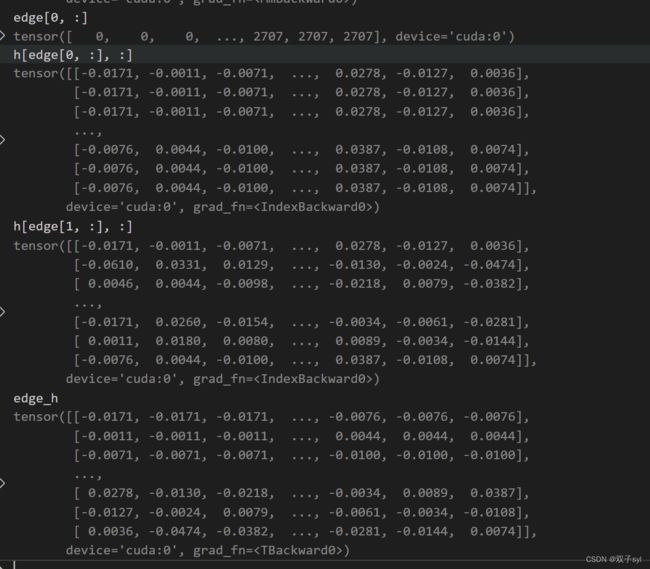
edge_e = torch.exp(-self.leakyrelu(self.a.mm(edge_h).squeeze()))#squeeze把维度=1的压缩
assert not torch.isnan(edge_e).any()
# edge_e: E
这段代码实现的是下图:
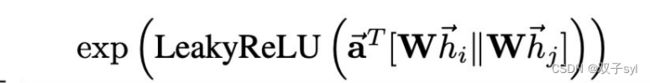
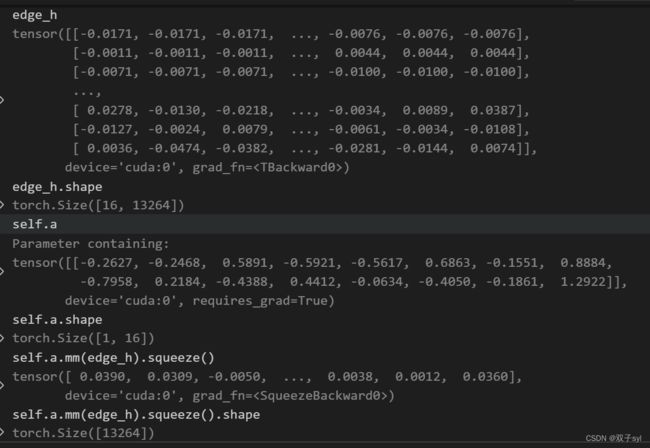
仅针对稀疏区域反向传播层的特殊功能
class SpecialSpmmFunction(torch.autograd.Function):
"""Special function for only sparse region backpropataion layer."""
@staticmethod
def forward(ctx, indices, values, shape, b):
#对应ctx,edge, edge_e, torch.Size([N, N]), torch.ones(size=(N,1), device=dv)
assert indices.requires_grad == False
a = torch.sparse_coo_tensor(indices, values, shape)#创建coo格式的稀疏矩阵
ctx.save_for_backward(a, b)#反向传播用的
ctx.N = shape[0]#batchsize
return torch.matmul(a, b)
@staticmethod
def backward(ctx, grad_output):
a, b = ctx.saved_tensors
grad_values = grad_b = None
if ctx.needs_input_grad[1]:
grad_a_dense = grad_output.matmul(b.t())
edge_idx = a._indices()[0, :] * ctx.N + a._indices()[1, :]
grad_values = grad_a_dense.view(-1)[edge_idx]
if ctx.needs_input_grad[3]:
grad_b = a.t().matmul(grad_output)
return None, grad_values, None, grad_b
e_rowsum = self.special_spmm(edge, edge_e, torch.Size([N, N]), torch.ones(size=(N,1), device=dv))
# e_rowsum: N x 1

edge_e = self.dropout(edge_e)#丢一点特征,相当于正则化,防止过拟合
# edge_e: E

h_prime = self.special_spmm(edge, edge_e, torch.Size([N, N]), h)
#实现αWh
assert not torch.isnan(h_prime).any()
# h_prime: N x out
h_prime = h_prime.div(e_rowsum)
#相当于归一化
# h_prime: N x out
assert not torch.isnan(h_prime).any()
if self.concat:
# if this layer is not last layer,
return F.elu(h_prime)
else:
# if this layer is last layer,
return h_prime
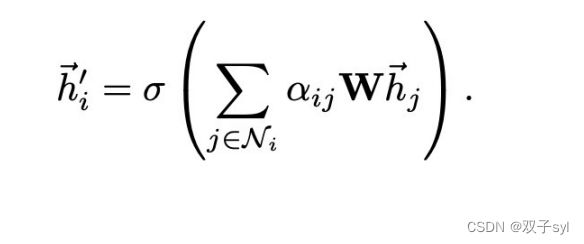
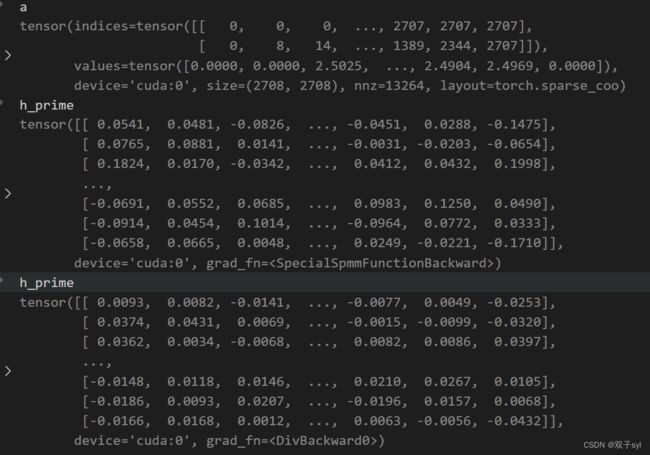
self.attentions.shape=8,将上述过程进行8次,结果如下:
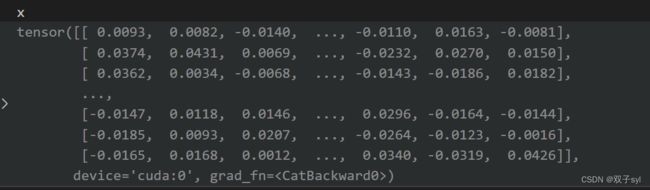
第一次训练第二层结果
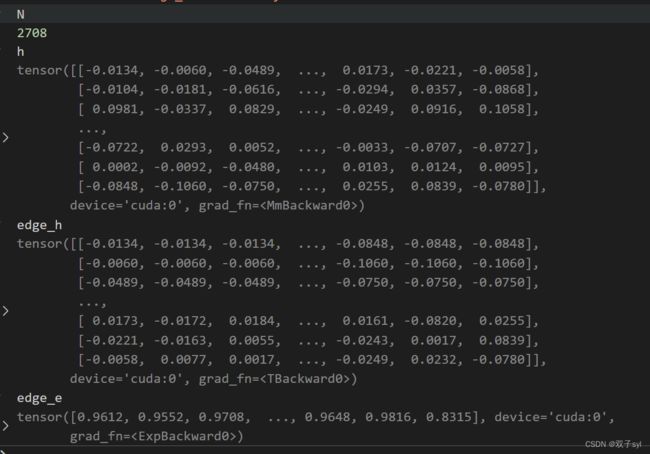
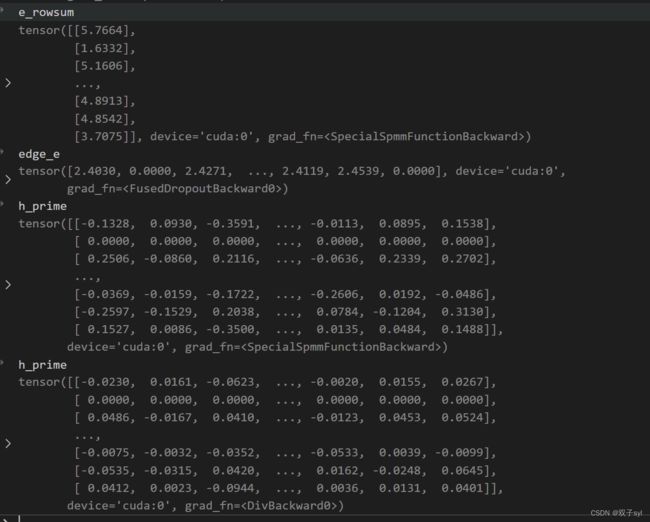
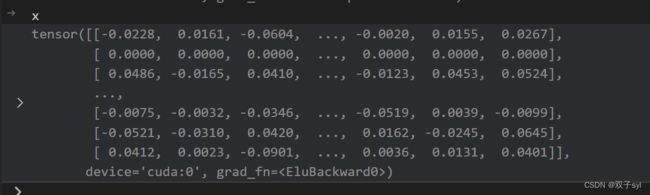
之后反向传播循环epoch次。
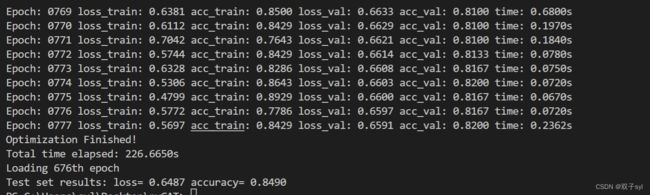
实验结果