理论
| 类别classi | 非类别classi | |
| 包含单词wordj的文档数 | A | B |
| 不包含单词wordj的文档数 | C | D |
卡方特征提取主要度量类别classi和单词wordj之间的依赖关系。计算公式如下
![]()
其中N是文档总数,A是包含单词wordj且属于classi的文档数,B是包含单词wordj但不属classi的文档数,C是不包含单词wordj但属于classi的文档数,D是不包含单词wordj且不属于classi的文档数。值得注意的是
![]()
最终单词wordj的CHI值计算公式如下,其中P(classi)表示属于类别 classi的文档在所有文档中出现的概率,k为总的类别数
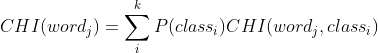
代码
下面以二分类为例介绍一段python代码:第一个参数是文档列表,包含若干个文档,每个文档由若干个单词通过空格拼接而成;第二个参数是标签列表,对应每个文档的类别;第三个参数用来确定选取前百分之多少的单词。
# documents = [document_1, document_2, document_3, ...]
# document_i = "word_1 word_2 word_3"
# labels is a list combined with 0 and 1
def feature_word_select(documents:list, labels:list, percentage:float):
# get all words
word_set = set()
for document in documents:
words = document.split()
word_set.update(words)
word_list = list(word_set)
word_list.sort()
sorted_words = chi(word_list, documents, labels)
top_k_words = sorted_words[:int(percentage * len(sorted_words))]
return top_k_words
这段代码首先创建一个集合word_set,接着遍历所有的文档,对每一个文档,使用split()函数对其进行切分,得到一个words列表,再将列表中的所有元素输入到集合word_set中,word_set由于集合的特性会过滤集合中已有的单词。收集完毕后,通过word_set生成一个单词列表word_list。
将单词列表,文档列表和标签列表输入chi函数,得到通过卡方值降序排列的单词列表sorted_words。
最后选取前百分之percentage的单词最为最后的特征单词。
下面这个函数cal_chi_word_class()用来计算 CHI(word, 0)和CHI(word, 1)。这里的A1表示属于类别1的A,A0表示属于类别0的A。
值得说明的是,在二分类问题中,A1实际上等于B0,C1实际上等于D0。因此,仅计算A1,B1,C1,D1即可推导出A0,B0,C0,D0。
此外,由于文档总数N对于CHI(word, 0)和CHI(word, 1)来说属于公共的分子且保持不变,所以可以不参与计算;A1+C1=B0+D0,B1+D1=A0+C0,所以CHI(word, 0)和CHI(word, 1)的分母部分可以进行简化
# calculate chi(word,1) and chi(word,0)
def cal_chi_word_class(word, labels, documents):
N = len(documents)
A1, B1, C1, D1 = 0., 0., 0., 0.
A0, B0, C0, D0 = 0., 0., 0., 0.
for i in range(len(documents)):
if word in documents[i].split():
if labels[i] == 1:
A1 += 1
B0 += 1
else:
B1 += 1
A0 += 1
else:
if labels[i] == 1:
C1 += 1
D0 += 1
else:
D1 += 1
C0 += 1
chi_word_1 = N * (A1*D1-C1*B1)**2 / ((A1+C1)*(B1+D1)*(A1+B1)*(C1+D1))
chi_word_0 = N * (A0*D0-C0*B0)**2 / ((A0+C0)*(B0+D0)*(A0+B0)*(C0+D0))
return chi_word_1, chi_word_0
简化后
# calculate chi(word,1) and chi(word,0)
def cal_chi_word_class(word, labels, documents):
A1, B1, C1, D1 = 0., 0., 0., 0.
for i in range(len(documents)):
if word in documents[i].split():
if labels[i] == 1:
A1 += 1
else:
B1 += 1
else:
if labels[i] == 1:
C1 += 1
else:
D1 += 1
A0, B0, C0, D0 = B1, A1, D1, C1
chi_word_1 = (A1*D1-C1*B1)**2 / ((A1+B1)*(C1+D1))
chi_word_0 = (A0*D0-C0*B0)**2 / ((A0+B0)*(C0+D0))
return chi_word_1, chi_word_0
在chi函数中调用cal_chi_word_class函数,即可计算每个单词的卡方值,以字典的形式保存每个单词的卡方值,最后对字典的所有值进行排序,并提取出排序后的单词。
def chi(word_list, documents, labels):
P1 = labels.count(1) / len(documents)
P0 = 1 - P1
dic = {}
for word in word_list:
chi_word_1, chi_word_0 = cal_chi_word_class(word, labels, documents)
chi_word = P0 * chi_word_0 + P1 * chi_word_1
dic[word] = chi_word
sorted_list = sorted(dic.items(), key=lambda x:x[1], reverse=True)
sorted_chi_word = [x[0] for x in sorted_list]
return sorted_chi_word
测试代码。这里我略过了数据处理环节,documents列表中的每一个元素document_i都是有若干个单词或符号通过空格拼接而成。
def main():
documents = ["today i am happy !", "she is not happy at all", "let us go shopping !",
"mike was so sad last night", "amy did not love it", "it is so amazing !"
]
labels = [1, 0, 1, 0, 0, 1]
words = feature_word_select(documents, labels, 0.3)
print(words)
if __name__ == '__main__':
main()
运行结果如下
['!', 'not', 'all', 'am', 'amazing', 'amy', 'at']
进一步,可以在chi函数里输出sorted_list(每个单词对应的卡方值),结果如下。这里输出的并不是真实的卡方值,是经过化简的,如需输出原始值,请使用完整版的cal_chi_word_class()函数。
[('!', 9.0), ('not', 4.5), ('all', 1.8), ('am', 1.8), ('amazing', 1.8), ('amy', 1.8), ('at', 1.8), ('did', 1.8), ('go', 1.8), ('i', 1.8), ('last', 1.8), ('let', 1.8), ('love', 1.8), ('mike', 1.8), ...]
完整代码
# calculate chi(word,1) and chi(word,0)
def cal_chi_word_class(word, labels, documents):
A1, B1, C1, D1 = 0., 0., 0., 0.
for i in range(len(documents)):
if word in documents[i].split():
if labels[i] == 1:
A1 += 1
else:
B1 += 1
else:
if labels[i] == 1:
C1 += 1
else:
D1 += 1
A0, B0, C0, D0 = B1, A1, D1, C1
chi_word_1 = (A1*D1-C1*B1)**2 / ((A1+B1)*(C1+D1))
chi_word_0 = (A0*D0-C0*B0)**2 / ((A0+B0)*(C0+D0))
return chi_word_1, chi_word_0
def chi(word_list, documents, labels):
P1 = labels.count(1) / len(documents)
P0 = 1 - P1
dic = {}
for word in word_list:
chi_word_1, chi_word_0 = cal_chi_word_class(word, labels, documents)
chi_word = P0 * chi_word_0 + P1 * chi_word_1
dic[word] = chi_word
sorted_list = sorted(dic.items(), key=lambda x:x[1], reverse=True)
sorted_chi_word = [x[0] for x in sorted_list]
return sorted_chi_word
# documents = [document_1, document_2, document_3, ...]
# document_i = "word_1 word_2 word_3"
# labels is a list combined with 0 and 1
def feature_word_select(documents:list, labels:list, percentage:float):
# get all words
word_set = set()
for document in documents:
words = document.split()
word_set.update(words)
word_list = list(word_set)
word_list.sort()
sorted_words = chi(word_list, documents, labels)
top_k_words = sorted_words[:int(percentage * len(sorted_words))]
return top_k_words
def main():
documents = ["today i am happy !", "she is not happy at all", "let us go shopping !",
"mike was so sad last night", "amy did not love it", "it is so amazing !"
]
labels = [1, 0, 1, 0, 0, 1]
words = feature_word_select(documents, labels, 0.3)
print(words)
if __name__ == '__main__':
main()
题外话
卡方特征选择仅考虑单词是否在文档中出现,并没有考虑单词出现的次数,因此选择出的特征单词可能并不准确。
到此这篇关于Python利用卡方Chi特征检验实现提取关键文本特征的文章就介绍到这了,更多相关Python提取关键文本特征内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!