5. 线性回归的从零开始实现
1.生成数据集
# num_examples 表示样本数量,也就是房屋数量
# w是权重向量
def synthetic_data(w, b, num_examples): #@save
"""生成y=Xw+b+噪声"""
# X是一个从独立的正态分布中抽取的随机数的张量,正态分布的平均值为0、标准差为1
# 第三项则表示矩阵X的形状:有num_examples行,len(w)列
# 也就是说,对于矩阵X,每一行表示一个样本,每一列表示一个影响房屋价格的因素,有两个因素
X = torch.normal(0, 1, (num_examples, len(w)))
# torch.matual即时执行矩阵相乘
y = torch.matmul(X, w) + b
# 给y加入均值为0,标准差为0.01的噪音,噪音的形状和y的长度是一样的
y += torch.normal(0, 0.01, y.shape)
# reshape(-1,1),1表示把y向量转成1列,另一个维度,即行,是-1,那么就自动计算
return X, y.reshape((-1, 1))
# 真实的w和b
true_w = torch.tensor([2, -3.4])
true_b = 4.2
# 调用函数,得到特征X和标签y
features, labels = synthetic_data(true_w, true_b, 1000)
在这里,关于reshape的两个的两个参数是用来调整矩阵的形状的,第一个表示行,第二个表示列,当为-1时,表示根据另一维度的固定值自动计算。如reshape(2,3)表示调整为2行3列,reshape(3,-1)表示调整为三行,列数根据行数自动计算
由传入函数的最后一个参数可知:传入1000表示1000个样本,那么矩阵X又或者是最后得到的features 就是一个1000*2的矩阵,2表示影响房价的两个因素。
接下来,打印输出第0个样本的数据以及对应标签:
print('features:',features[0],'\nlabel:',labels[0])

可以看出:第0个样本是一个长为2的向量,也就是和w的长度一样,而对应的标签是一个标量。其他样本同理。
接下来,可以把特征的第一列和label画出来:
d2l.set_figsize()
d2l.plt.scatter(features[:,1].detach().numpy(),
labels.detach().numpy(),1);
把特征第1列(从第0列算起),也就是第2个特征拎出来和labels以图像形式呈现,scatter函数的最后一个参数1的意思是:绘制点直径的大小。
并且因为features是一个1000*2的矩阵,取出第一列,则代表取出1000个数,那么下图中有1000个点。
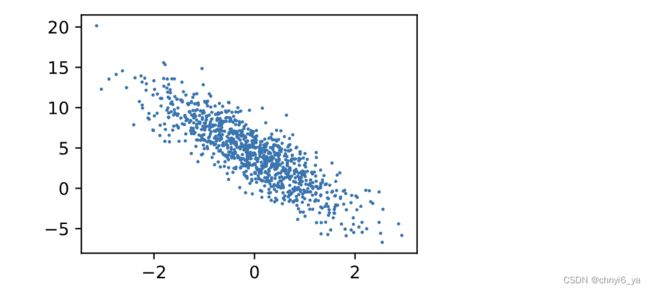
可以看到是有相关性的,并且是负相关,因为w中第二个标量是-3.4.同理,如果把X矩阵的第0列和labels画出来,结果应该是正相关的,因为w中第一个标量是2
2. 读取数据集
接下来,定义一个data_iter函数,该函数接受批量大小,特征矩阵和标签向量作为输入,生成大小为batch_size的小批量,目的是为了:从全样本集中抽取部分样本,以用来训练后面创建的模型
def data_iter(batch_size,features,labels):
# features是1000*2的矩阵,len()这一函数表示其第一维度(行)的长度,也就是样本数量
# 因为一行代表一个样本
num_examples = len(features) # 样本数量
indices = list(range(num_examples)) # 生成对于每个样本的index索引,从0~999
# 这些样本是随机读取的,没有特定的顺序
random.shuffle(indices) # 这一函数是为了把indices这一个列表打乱,才能为后面实现随机读取
for i in range(0,num_examples,batch_size):
# 从样本0开始,直到最后一个样本,每一次跳batch_size的大小
batch_indices = torch.tensor(indices[i:min(i+
batch_size,num_examples)])
# ps: 在这里,batch_indices索引可以是tensor,也可以是list
# 为什么要加上min这一函数呢?
# 因为假设1000个样本,如果batch_size=15,那么最后一次取的时候是不足15的
# 也就是最后一个batch不够,直接用剩余的即可。
# features[]中放的是索引,返回的是一组索引对象
yield features[batch_indices],labels[batch_indices]
batch_size = 10
for x,y in data_iter(batch_size,features,labels):
print(X,'\n',y)
break
打印的结果如下:

解释:在调用了data_iter()函数的for循环中,有一个break,即:只打印了第一个batch,就退出循环了。也正好对应了batch_size=10,而X的第一个batch的样本,都是随机的,每一个样本都是一个二维的行向量。
3. 初始化参数模型
# w是一个长为2的列向量,将其随之初始化成均值为0,标准差为0.01的正态分布,并且需要计算梯度
w = torch.normal(0,0.01,size=(2,1),requires_grad=True)
# 对于偏差b而言,直接初始化为0,“1”表示标量,需要对偏差进行更新,所以requires_grad也等于True
b = torch.zeros(1,requires_grad=True)
4. 定义线性回归模型
将模型的输入和参数同模型的输出关联起来。要计算线性模型的输出, 我们只需计算输入特征X和模型权重w的矩阵-向量乘法后加上偏置b。 注意,上面的Xw是一个向量,而b是一个标量
回想一下广播机制,当我们用一个向量加一个标量时,标量会被加到向量的每个分量上。
def linreg(X,w,b):
'''线性回归模型'''
return torch.matmul(X,w)+b
5. 定义损失函数
因为需要计算损失函数的梯度,所以我们应该先定义损失函数。 在实现中,我们需要将真实值y的形状转换为和预测值y_hat的形状相同.
def squared_loss(y_hat,y):
'''均方误差'''
return (y_hat-y.reshape(y_hat.shape))**2 / 2
6. 定义优化算法
在每一步中,使用从数据集中随机抽取的一个小批量,然后根据参数计算损失的梯度。
接下来,朝着减少损失的方向更新我们的参数(w和b)。 下面的函数实现小批量随机梯度下降更新。
该函数接受模型参数集合、学习速率和批量大小作为输入。每 一步更新的大小由学习速率lr决定。 因为我们计算的损失是一个批量样本的总和,所以我们用批量大小(batch_size) 来规范化步长,这样步长大小就不会取决于我们对批量大小的选择。
# params是list,包括w和b
def sgd(params,lr,batch_size):
'''小批量随机梯度下降'''
# 禁用梯度计算以加快计算速度
# 当确保下文不用backward()函数计算梯度时可以用,用于禁用梯度计算功能,以加快计算速度
with torch.no_grad(): # 不需要计算梯度,更新的时候不需要参与梯度计算
for param in params:
param -= lr * param.grad / batch_size
param.grad.zero_() # 梯度清零
# pytorch会不断地累积变量的梯度,所以每更新一次参数,就要让其对应的梯度清零
7. 训练
现在我们已经准备好了模型训练所有需要的要素,可以实现主要的训练过程部分了。 理解这段代码至关重要,因为从事深度学习后, 你会一遍又一遍地看到几乎相同的训练过程。
在每次迭代中,我们读取一小批量训练样本,并通过我们的模型来获得一组预测。 计算完损失后,我们开始反向传播,存储每个参数的梯度。 最后,我们调用优化算法sgd来更新模型参数。
lr = 0.03 # 学习率为0.03
num_epochs = 3 # 对整个数据集进行三次扫描
net = linreg # 线性回归
loss = squared_loss
for epoch in range(num_epochs):
for X,y in data_iter(batch_size,features,labels): # 拿出一个batch_size的X和y
# net(X,w,b) 把X,w,b放入net中,用来做预测
# loss(net(X,w,b),y) :把预测的y和真实的y来做损失
l = loss(net(X,w,b),y)
# 得到的l是一个长为batch_size的列向量
# l中的所有元素被加到一起,并以此计算关于[w,b]的梯度
l.sum().backward()
sgd([w,b],lr,batch_size) # 使用参数的梯度更新参数
with torch.no_grad():
train_1 = loss(net(features,w,b),labels)
print(f'epoch{epoch+1},loss{float(train_1.mean()):f}')

因为我们使用的是自己合成的数据集,所以我们知道真正的参数是什么。 因此,我们可以通过比较真实参数和通过训练学到的参数来评估训练的成功程度。 事实上,真实参数和通过训练学到的参数确实非常接近。
print(f'w的估计误差:{true_w-w.reshape(true_w.shape)}')
print(f'b的估计误差:{true_b-b}')
