车道线识别 tusimple 数据集介绍
1、tusimple 数据集介绍
标注json 文件中每一行包括三个字段 :
raw_file : 每一个数据段的第20帧图像的的 path 路径
lanes 和 h_samples 是数据具体的标注内容,为了压缩,h_sample 是纵坐标(等分确定),lanes 是每个车道的横坐标,是个二维数组。-2 表示这个点是无效的点。
标注的过程应该是,将图片的下半部分如70%*height 等分成N份。然后取车道线(如论虚实)与该标注线交叉的点


上面的数据就有 4 条车道线,第一条车道线的第一个点的坐标是(632,280)。
2、下载数据集
LaneNet车道线检测使用的是Tusimple数据集,下载它
https://github.com/TuSimple/tusimple-benchmark/issues/3

3、样本处理
利用以下脚本可以处理得到标注的数据,这个脚本稍微改动下也可以作为深度学习输入的图像。
# -*- coding: utf-8 -*-
import cv2
import json
import numpy as np
import os
base_path = r"C:\Users\Downloads"
file = open(base_path + '\label_data_0601.json', 'r')
image_num = 0
for line in file.readlines():
data = json.loads(line)
# print data['raw_file']
# 取第 29 帧 看一下处理的效果
if image_num == 2:
image = cv2.imread(os.path.join(base_path, data['raw_file']))
# 二进制图像数组初始化
binaryimage = np.zeros((image.shape[0], image.shape[1], 1), np.uint8)
# 实例图像数组初始化
instanceimage = binaryimage.copy()
arr_width = data['lanes']
arr_height = data['h_samples']
width_num = len(arr_width) # 标注的道路条数
height_num = len(arr_height)
# print width_num
# print height_num
# 遍历纵坐标
for i in range(height_num):
lane_hist = 40
# 遍历各个车道的横坐标
for j in range(width_num):
# 端点坐标赋值
if arr_width[j][i - 1] > 0 and arr_width[j][i] > 0:
binaryimage[int(arr_height[i]), int(arr_width[j][i])] = 255 # 255白色,0是黑色
instanceimage[int(arr_height[i]), int(arr_width[j][i])] = lane_hist
if i > 0:
# 画线,线宽10像素
cv2.line(binaryimage, (int(arr_width[j][i - 1]), int(arr_height[i - 1])),
(int(arr_width[j][i]), int(arr_height[i])), 255, 10)
cv2.line(instanceimage, (int(arr_width[j][i - 1]), int(arr_height[i - 1])),
(int(arr_width[j][i]), int(arr_height[i])), lane_hist, 10)
lane_hist += 50
# cv2.imshow('image.jpg', image)
# cv2.waitKey()
# cv2.imshow('binaryimage.jpg', binaryimage)
# cv2.waitKey()
# cv2.imshow('instanceimage.jpg', instanceimage)
# cv2.waitKey()
string1 = base_path + "\\" + str(image_num+10) + ".png"
string2 = base_path + "\\" + str(image_num+11) + ".png"
string3 = base_path + "\\" + str(image_num+12) + ".png"
cv2.imwrite(string1, binaryimage)
cv2.imwrite(string2, instanceimage)
cv2.imwrite(string3, image)
break
image_num = image_num + 1
file.close()
print("total image_num:" + str(image_num))
处理完之后图片输出如下所示:
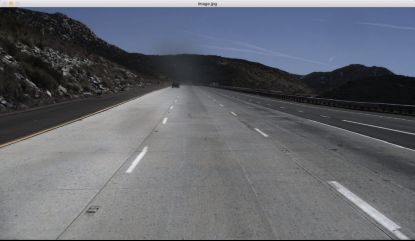


Tusimple 数据的标注特点:
1、车道线实际上不只是道路上的标线,虚线被当作了一种实线做处理的。这里面双实线、白线、黄线这类信息也是没有被标注的。
2、每条线实际上是点序列的坐标集合,而不是区域集合
4、创建自己的tusimple数据集格式
第一步:原始数据集标注
1、使用labelme进行数据标注:
在conda里使用指令进行安装labelme
pip install labelme2、在环境下使用指令进行启动labelme
labelme3、进入界面后选择图片,进行线段标记
在顶部edit菜单栏中选择不同的标记方案,依次为:多边形(默认),矩形,圆、直线,点。点击 Create Point,回到图片,左键点击会生成一个点,标记完成后,会形成一个标注区域,同时弹出labelme的框,输入标注名,点击ok,标注完成
注意:要标注的车道线,一般会有多条,需要不同的命名加以区分,lane1,lane2等
标注完成后,会生成一个json文件。
4、将json转换为dataset
labelme_json_to_dataset xxx.json生成一个文件夹,里面包含五个文件(只能转换一个json)
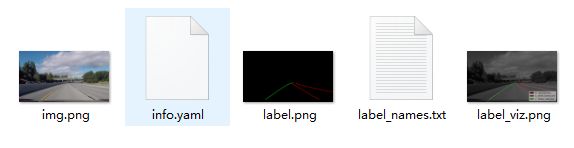
批量转换json:
在labelme的安装目录下可以看到json_to_dataset文件,默认只提供单个文件转换,我们只需要修改此代码,修改为批量转换
import argparse
import json
import os
import os.path as osp
import warnings
import PIL.Image
import yaml
from labelme import utils
import base64
#批量转换代码
def main():
warnings.warn("This script is aimed to demonstrate how to convert the\n"
"JSON file to a single image dataset, and not to handle\n"
"multiple JSON files to generate a real-use dataset.")
parser = argparse.ArgumentParser()
parser.add_argument('json_file')
parser.add_argument('-o', '--out', default=None)
args = parser.parse_args()
json_file = args.json_file
if args.out is None:
out_dir = osp.basename(json_file).replace('.', '_')
out_dir = osp.join(osp.dirname(json_file), out_dir)
else:
out_dir = args.out
if not osp.exists(out_dir):
os.mkdir(out_dir)
count = os.listdir(json_file)
for i in range(0, len(count)):
path = os.path.join(json_file, count[i])
if os.path.isfile(path):
data = json.load(open(path))
if data['imageData']:
imageData = data['imageData']
else:
imagePath = os.path.join(os.path.dirname(path), data['imagePath'])
with open(imagePath, 'rb') as f:
imageData = f.read()
imageData = base64.b64encode(imageData).decode('utf-8')
img = utils.img_b64_to_arr(imageData)
label_name_to_value = {'_background_': 0}
for shape in data['shapes']:
label_name = shape['label']
if label_name in label_name_to_value:
label_value = label_name_to_value[label_name]
else:
label_value = len(label_name_to_value)
label_name_to_value[label_name] = label_value
# label_values must be dense
label_values, label_names = [], []
for ln, lv in sorted(label_name_to_value.items(), key=lambda x: x[1]):
label_values.append(lv)
label_names.append(ln)
assert label_values == list(range(len(label_values)))
lbl = utils.shapes_to_label(img.shape, data['shapes'], label_name_to_value)
captions = ['{}: {}'.format(lv, ln)
for ln, lv in label_name_to_value.items()]
lbl_viz = utils.draw_label(lbl, img, captions)
out_dir = osp.basename(count[i]).replace('.', '_')
out_dir = osp.join(osp.dirname(count[i]), out_dir)
if not osp.exists(out_dir):
os.mkdir(out_dir)
PIL.Image.fromarray(img).save(osp.join(out_dir, 'img.png'))
#PIL.Image.fromarray(lbl).save(osp.join(out_dir, 'label.png'))
utils.lblsave(osp.join(out_dir, 'label.png'), lbl)
PIL.Image.fromarray(lbl_viz).save(osp.join(out_dir, 'label_viz.png'))
with open(osp.join(out_dir, 'label_names.txt'), 'w') as f:
for lbl_name in label_names:
f.write(lbl_name + '\n')
warnings.warn('info.yaml is being replaced by label_names.txt')
info = dict(label_names=label_names)
with open(osp.join(out_dir, 'info.yaml'), 'w') as f:
yaml.safe_dump(info, f, default_flow_style=False)
print('Saved to: %s' % out_dir)
if __name__ == '__main__':
main()进入到保存json文件的目录,执行labelme_json_to_dataset path
将标注之后的数据批量处理之后,生成文件夹形式如下图所示
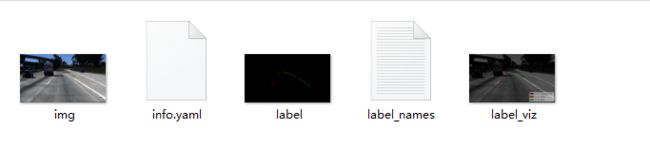
打开文件夹里面有五个文件,分别是
5、数据格式转换
根据tuSimple数据集形式,需要得到二值化和实例化后的图像数据,也就是gt_binary_image和gt_instance_image文件中的显示结果。需要将标注之后的数据进行转换
import cv2
from skimage import measure, color
from skimage.measure import regionprops
import numpy as np
import os
import copy
def skimageFilter(gray):
binary_warped = copy.copy(gray)
binary_warped[binary_warped > 0.1] = 255
gray = (np.dstack((gray, gray, gray))*255).astype('uint8')
labels = measure.label(gray[:, :, 0], connectivity=1)
dst = color.label2rgb(labels,bg_label=0, bg_color=(0,0,0))
gray = cv2.cvtColor(np.uint8(dst*255), cv2.COLOR_RGB2GRAY)
return binary_warped, gray
def moveImageTodir(path,targetPath,name):
if os.path.isdir(path):
image_name = "gt_image/"+str(name)+".png"
binary_name = "gt_binary_image/"+str(name)+".png"
instance_name = "gt_instance_image/"+str(name)+".png"
train_rows = image_name + " " + binary_name + " " + instance_name + "\n"
origin_img = cv2.imread(path+"/img.png")
origin_img = cv2.resize(origin_img, (1280,720))
cv2.imwrite(targetPath+"/"+image_name, origin_img)
img = cv2.imread(path+'/label.png')
img = cv2.resize(img, (1280,720))
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
binary_warped, instance = skimageFilter(gray)
cv2.imwrite(targetPath+"/"+binary_name, binary_warped)
cv2.imwrite(targetPath+"/"+instance_name, instance)
print("success create data name is : ", train_rows)
return train_rows
return None
if __name__ == "__main__":
count = 1
with open("./train.txt", 'w+') as file:
for images_dir in os.listdir("./images"):
dir_name = os.path.join("./images", images_dir + "/annotations")
for annotations_dir in os.listdir(dir_name):
json_dir = os.path.join(dir_name, annotations_dir)
if os.path.isdir(json_dir):
train_rows = moveImageTodir(json_dir, "./", str(count).zfill(4))
file.write(train_rows)
count += 1
转换之后的显示结果:

由于lanenet模型处理需要按照tusimple数据进行,首先需要将上一步处理的数据生成tfrecords格式,调用laneNet中lanenet_data_feed_pipline.py文件。
python data_provider/lanenet_data_feed_pipline.py
--dataset_dir ../dataset/lane_detection_dataset/
--tfrecords_dir ../dataset/lane_detection_dataset/tfrecords欢迎关注公众号:算法工程师的学习日志
