自然语言处理NLP训练营---贪心科技
ai工程师必备的核心功能
现实中的问题—>数学优化问题—>通过合适的工具解决
为什么NLP比CV难?
图片是所见即所得,而语言不只有表面意思,语言还有更加深入的浅层意思
如何解决一词多义?
将词放入上下文(context)中去理解
一个简单的机器翻译系统,如何将图中的一句话翻译出来,下面是翻译的例子,方法只能通过词与词对应人工学习出对应规则,然后猜测翻译的句子。

以上存在的问题
- 翻译速度慢
- 语义不明(歧义)
- 没有考虑上下文
- 翻译后的句子语法不对
- 需要大量的人工规则统计
解决方法:给定一句话,先进行分词,再使用字典将分词的结果进行翻译,翻译结果为(Tonight,of,interesting,the course),这个翻译结果被称为Broken English,然后将翻译的结果进行排列组合,得到4!种候选句子,将这些句子通过LM(Language Model)进行计算每个句子的概率,选出出现概率最大的句子(The course of tonight interseting)作为翻译结果。语言模型判断一句话是否是“人话”

以上的翻译存在的问题
- 计算量太大(4!)
问题的本质在于以上的翻译模型将翻译过程分成了两部分
如何将计算量降低?将以上的两步统一起来,同时避免计算量的升高,使用维特比算法(以后讲)实现。

将这两个部分分别看成翻译模型(对分词进行翻译)和语言模型,一种Decoding 算法可以将两种算法进行合并,即同时实现两种模型的功能,该算法为维特比算法。
翻译模型解决的是给定英语句子,得到中文句子的概率
语言模型计算的是给定中文单词,得出英文句子的概率
维特比算法可直接计算这两个的乘积。使用了贝叶斯公式。

图中的f是c,写错了。维特算法可以将2的n次方的复杂度降低到n的p次方


NLP经典应用
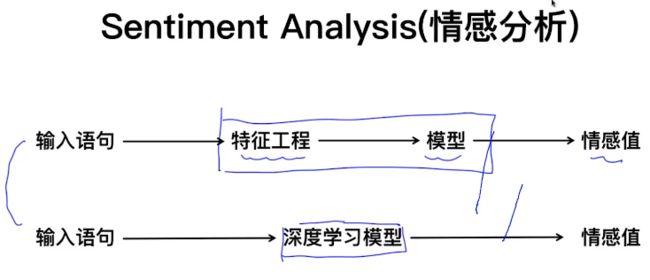
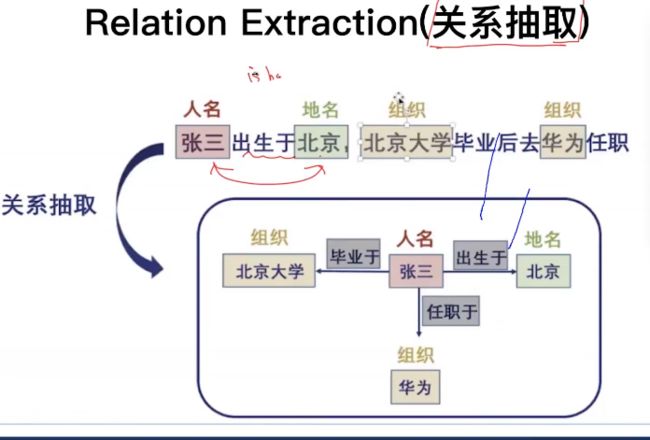
Question Answering(问答系统)、情感分析、机器翻译、自动摘要、聊天机器人、信息抽取:NER、关系抽取
搭建问答系统会有很多种方法
先使用 1. 检索方法弄一个



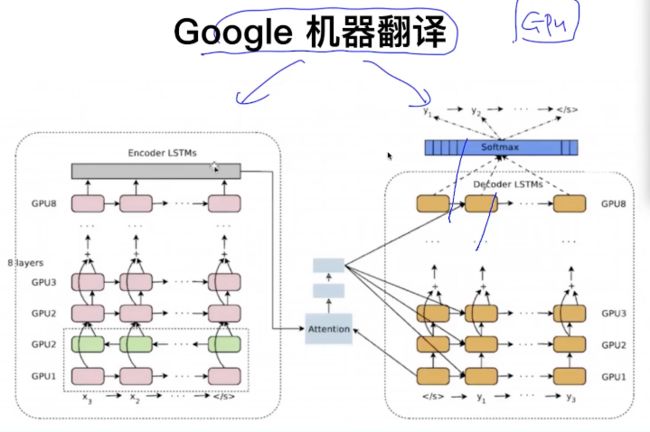


NLP关键技术
自然语言处理技术的四个维度(由深到浅)
- Semantic(语义),最终目标即是理解语义,通过一个算法理解语言即NLU,
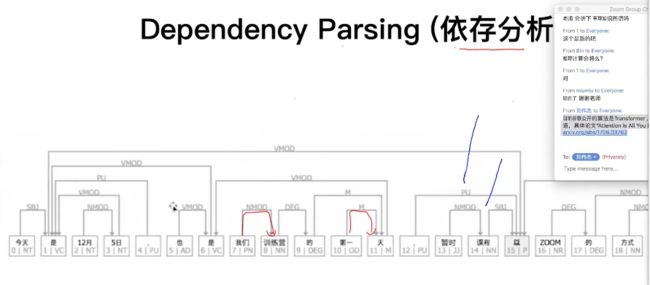
- Suntax(句子结构),技术:句法分词、依存分析(Dependency parse,分析每个单词之间的潜在联系)
- Morphology(单词),单词层面的技术:分词、POS(词性标记)、NER(命名实体识别)
- Phonetics(声音)



KG的最大价值:将各个领域串起来,将其应用于业务
句法分析会讲一个CYK算法

看NLP最新的进展:https://www.quora.com/What-are-the-major-open-problems-in-natural-language-understanding
第7节课
时间复杂度表示运行算法需要多长的时间
空间复杂度表示运行算法占据多少的内存
O():o
一个程序中用到了两个变量,这两个变量即是从1遍历到1000,那也是只用到了两个变量,它的空间复杂度为O(1),即常数复杂度(constant space complexity)
2个单位的内存空间 = O(1)
这一节可以弄个专题 视频中谈到的链接:参考[NLPCamp] 时间复杂度与空间复杂度-算法工程师不可忽略的重要指标
案例搭建一个智能客服系统
1.首先需要一个语料库,即图中的11个问题
用户输入的问题和语料库中的问题计算相似性,将相似性最高的问题对应的答案返回出去就是客服的答案。
相似度的计算:1.正则(没有数据的时候采用这种方法)、2字符串之间的相似度计算

为什么举英文的例子?
英文的例子中有的可能不适合中文的,所以这样讲的方法多一点。
流程
句子**(How do you like NLPCamp?)
—>分词(Word Segmention)
—>预处理(1.拼写纠错spell correction,2.对单词还原词型,3.去除停用词stopwords,4.去除一些其他词如#、< a >即word filtering,5.在匹配时可以替换同义词,6.。。。)
—>文本表示(将文本表示为向量,即将文本转为结构化的数据(房事有:boolean vector即one hot表示、content vector(1,2,0,2)即其中的数表示这个词在文本中出现的次数 )、ti-idf的表示(0.3,0.7,0.1,0.2),word2vec(0.1,0.3,0.2,0.1)、seq2seq)
—>计算文本之间的相似度(给定两个向量计算):方法有欧式距离、cos距离、不知道说的啥相似度
—>根据相似度进行排序
—>返回结果
如果文本特别多的时候会加个倒排表(inverted index),从而将复杂度降低。

问答系统
-----现在的方法(文本表示、相似度计算)
-----知识图谱(实体抽取、关系抽取)

任务18:Review 一只狗和两只猫的故事—心理学与DL、RL-01
任务19:Review 一只狗和两只猫的故事—心理学与DL、RL-02
任务20:文本处理流程(Pipeline)
Normalization标准化(英文常用):Stemming、Lemmazation
就是将单复数都转为单数、去时态


Word Segmentation Tools分词常用工具
Jieba分词:https://github.com/ fxsjy/jieba
SnowNLP:https:// github.com/ isnowfy/snownlp
哈工大LTP: http:/ /www.ltp-cloud.com/
HanNLP:https://github.com/hankcs/HanL P/
FwdanNLP…
分词算法:
- 前向最大匹配算法(forward-max matching)(是个贪心的算法,一旦匹配到了单词就不再往下分了)
- 后向最大匹配算法(是个贪心的算法)
- 双向最大匹配算法(是个贪心的算法)


前向和后向分出来的结果大约在90%是一样的,10%是不一样的。
最大匹配缺点:只找到了局部最优、效率低、时间复杂度低、没有考虑到语义,只考虑了单词

任务023:分词-考虑语言模型

对数函数不改变概率函数的单调性

任务024:分词-维特比算法
使用上面的方法的时间复杂度太高了。将两个步骤进行结合,即维特比算法,维特比算法还是DP算法(动态规划算法)

负对数之后就是要找到值最小的数。

维护这个表在代码实现的时候会记住每个节点是如何计算过来的,即维持了索引。即
使用数学表达式去表示以上的计算过程

总结一下任务024的知识点:
- List item

任务025:拼写错误纠正Spell Correction
编辑距离也是DP算法
拼写错误纠正是很多搜索网站需要使用到的。
拼写错误分为两种
- 打出来的字错误(天启—>天气)
- 字没有错误,但是写出的句子是有语法错误的(I am go home —>I am going home)
怎么触发即发现这些错误?
3. 字典中没有这样的词即认为是拼写错误啦
4. 可能是使用语言模型发现的

编辑距离(edit distance)指的是需要多少操作才能将错误的单词改为目标单词,分为insert、delete、replace
therr—>there(1replace),edit distance = 1
therr—>their(1replace),edit distance = 1
therr—>thesis(2replace+1add),edit distance = 3
therr—>theirs(1replace+1add),edit distance = 2
therr—>the(2delete),edit distance = 2

DP算法的练习题给了是个左右的题均来自Leetcode(建议全部做一下,gitlab登不上先停这儿)

任务026:拼写纠错(2)
在计算候选单词的时候,是对用户的输入的单词和词典中的所有词进行计算,这样的时间复杂度为O(n),现在的方法是根据用户的输入生成编辑距离是1,2的字符串,按照Delete、Add、Replace三种方法科可以生成多种编辑距离为1的单词,然后在这些词的基础上再生成编辑距离为2的单词。
为什么只生成编辑距离为1,2的单词呢?
答:在现实情景中用户想要表达的单词与输入的单词的编辑距离最多为2,绝大部分会落入2的范围内。

任务027:拼写纠错(3)
生成了这么多的字符串,数量级如下图所示,如何过滤出合适的单词呢?

使用了贝叶斯定理,p(s)可以认为是不会变化的,因为候选的单词的概率都是一样的。
p©这是观察之后统计出来的,它表示的意思就是一个单词c在所有的文档中出现的概率。
p(apple)>p(applx),假设applx也是一个正常的单词,可能在appl找编辑距离为1的单词时就会因为p(apple)>p(applx),所以在公式3中而将appl的编辑距离为1的最合适单词选择为apple

任务028:停用词过滤,Stemming操作

一般场景中可能会选择过滤“好”,而情感分析中就不能过滤“好”。一般的做法是将别人定义好的停用词词典进行过滤,最后在这个基础上再进行修改
假设:在NLTK中去除一些觉着有用的停用词,加入一些人为觉着需要去除的单词。

可以去除出现次数小于10或20的单词

Stemming并不保证会把单词还原为原型,会按照一定的规则进行还原,只是还原为原型的可能会多一点。
Lemmazation生成单词的规则会更加严格,还原成的单词会更加符合语法的规则。这是两者的区别。

Porter Stemmer中的一些规则实例

在编写这些规则的时候程序员还需要一些语言学家的帮助。
任务029:文本的表示
One-hot表示:这种方式表示是boolean(布尔式儿的) Representation

句子表示的时候,碰见句子中出现两次“又”的,不需要将其对应的维度那里写成2,不然就不是Boolean Representation(只能是0和1的表示)

Count-based Representation:这种方式表示基于计数的,即这种表示考虑了单词出现的词频

任务030:文本的相似度Eentence Similarity


denied:拒绝
这个词本应是占比重最大的词,然而在句向量中却不是


任务031:TF-IDF文本表示
N/N(w)即N(w)越小,N/N(w)这个值越大,说明即这个单词w越重要

tf-idf向量的构建


任务032:词向量介绍
One-hot representation
1.使用欧氏距离计算两个词向量的相似度,发现都是一样的。
2.使用余弦相似度距离计算两个词向量的相似度,发现都是一样的。
使用One-hot representation表达单词之间的相似度时不可行的!

使用One-hot representation具有稀疏性

使用分布式表示方法去解决One-hot表示方法的这两个缺点
分布式表示方法的单词向量的维度是自定义的,这解决了稀疏性。
为什么起名叫分布式表示方法?(后来会讲)
分布式表示方法的两个特点:
5. 维度是自定义的
6. 基本上每一维上的数字都不是0


思考一下下面的问题.
思考题答案:
介入分布式表示中的每一维可以只使用0/1来表示,那将有2的100次方中表示向量

任务033:学习词向量

essence:本质
词向量在某种意义上可以理解为词的意思。希望词向量可以更好的表达词的意思。



句向量的表示:
- Average法则(给定词向量平均词向量得到句向量)
- RNN/LSTM

任务034:倒排表
基于QA系统的检索
在知识库中检索出与问题最相似的问题,将对应的答案输出出来
查询与问题最相似的的问题的时间复杂度为
O(N)每次相似度计算的复杂度
如果知识库中句子太多,是时间复杂度会很高

How to Reduce Time Complexity?
解决方法的核心思想是:层次过滤思想
过滤器1:时间复杂度要低
过滤器2:稍微复杂一点的过滤器
过滤器3:这个过滤器的时间复杂度可能是最高的
这几个过虑器的时间复杂度是需要逐渐升高的

下面图中蓝色部分表示最终筛选的答案对,即参与最终相似度计算的答案对。计算相似度的时间复杂度为10余弦相似度+100*过滤器的时间复杂度,假设过滤器的时间复杂度很低,则总体的时间复杂度由后面的余弦相似度的时间复杂度所解决。
此时总体的时间复杂度就降为了之前的1/10,因为语料变少了

倒排列表(Inverted Index)
从网上爬了四个文档,分别有以下这些词。使用倒排表
“我们”出现在了【Doc1、Doc2】等。。。见下图
百度的搜索引擎
输入“运动”,则返回Doc1、Doc2作为候选选择,然后再使用PageRank的方法将文档进行排序。
假设用户输入:“我们上课”
搜索引擎会选择我们出现的文档Doc1、Doc2
选择“上课”出现的文档Doc3、Doc4
此时文档并没有重叠,就将Doc1、Doc2、Doc3、Doc4返回。

使用倒排表的话在之前过滤与问题类似的问题时可以将问题进行分词,然后看哪些问题中含有分词之后的结果,这样会快速搜到与问题相关的问题。最后将筛选出的问题与问题计算相似度,从而筛选出与问题最相关的问题。
加入这样的筛选方式能筛选出相当多的问题来,可以再设置一个过滤器,这个过滤器更加严格,比如筛选同时含有两个或者两个以上词的问题作为筛选结果。核心思想就是:层次筛选。
任务035:Noisy Channel Model()
Noisy Channel Model指的就是下图中的公式

以上的这些任务的共同点:把一个信号转换成文本。
机器翻译:英文—>中文
p(中文 | 英文)等比于p(英文 | 中文)* p(中文)
翻译模型 * 语言模型
拼写纠错:
p(正确的写法 | 错误的写法)等比于 p(错误的写法 | 正确的写法)* p(正确的写法)
p(错误的写法 | 正确的写法)看作为编辑距离
p(正确的写法):语言模型
以上的都可以看作是以下的公式

语音识别(输入是语音信号)
密码破解(输入一个加密后的字符串如abcdefg…)同样如此

任务036:Language Model (LM)

LM从概率上去判断字符串出现的概率从而判断句子在语法上是否通顺。

任务037:Chain Rule(链式法则)and Markov Assumption(马尔科夫假设)


从给定的文档中可以计算出P(休息 | 今天,是,春节,我们,都)= 1/2
其实比较长的一句话在文章中是很难找到的,这种问题称为Sparsity (稀疏性问题)

Markov Assumption(马尔科夫假设)
这个假设是去估计一个概率以下概率可以近似为以下公式
只考虑之前多少个单词可分为不同的Markov Assumption:
- 1st order Markov Assumption
- 2nd Markov Assumption
- 3rd Markov Assumption


例子:

任务038:Unigram,Bigram,N-gram
针对不同的马尔科夫假设,可以得到不同的语言模型
Unigram(最简单的语言模型):每个单词的概率都是独立的。
假如Unigram模型很优秀的,它应该是可以判断出P(今天,是,春节,我们都,休息)是大于P(今天,春节,是,都,我们,休息)的,然而从盖伦出计算公式上看Unigram并没有实现这样的判断功能,所以这个模型还是需要改进的。即Unigram的缺点是没有考虑单词的顺序的。

Bigram来自于一阶的马尔科夫假设。在某种程度上Bigram考虑了词的顺序。至少考虑了前一个单词。

更高阶gram称为N-gram

任务039:估计语言模型的概率


在语料库中没有出现句子中的单词,可以使用平滑的方法



这种方法都有一个缺点就是一旦一个项的概率为零,整个概率就会都变成0,因此需要平滑项。
任务040:评估语言模型Perplexity
A可能是Unigram,B可能是Bigram
即从这两种语言模型中选择看哪个模型的效果更好。这种成本比较高,因为得先选择任务,再分别训练语言模型,再评估结果,如果可以不再任务上训练,在任务外就开始选择模型,选择出较好的模型之后,将模型运用到任务上会更加减少消耗。

不依赖任务,直接比较模型

训练出来的LM,应用在训练集或验证集上或测试集上,计算x,希望x越大越好,Perplexity越小越好。

计算Perplexity的实例:

一种统计结果:

平滑方法:
复习出现概率为0的情况:

任务041:Add-one Smoothing
四种方法:
Add-one Smoothing(又称为Laplace Smoothing,在朴素贝叶斯经常会用到)
Add-K Smoothing
Interpolation
Good-Turning Smoothing

思考为什么,分母不加2V,3V,100,1000?

举个例子:

从计算结果来看,这样算出来的和为1
K是超参数,可使用模型学出来哪一个K比较好
优化的方法找到K

将训练好的语言模型应用于验证集,计算出Perplexity,这是一个关于K的函数,可以最小化这个函数来解出来K值

任务043:Interpolation:插值
为什么会提出这样的方法?
在Trigram中考虑了Unigram的情况,即因为在语料库中kitchen出现的次数较多,而arboretum未出现过,所以在直觉上来看P(kitchen | in the) 要大于P(arboretum | in the)



任务051:04专家系统与基于概率统计学习
符号主义(基于规则,称为专家系统)、连接主义(基于概率)
根据数据量的大小来决定是否使用专家系统
大量数据就使用基于概率统计的系统
意图识别分类器

任务052:05专家系统介绍
AI系统:可以帮助人类做决策或替代用户去决策
BI系统:商业(Busniess)系统,人根据BI分析出的结果做决策。

知识是专家系统中的核心
所以需要专家
专家输出自己的经验,(知识图谱工程师)需要将经验转为被计算机识别的格式,将转换的知识放在知识库,系统工程师/算法工程师要让专家系统具有推理功能。user interface 用户界面。

任务:搭建金融的知识图谱
需要金融领域的专家将知识告诉工程师
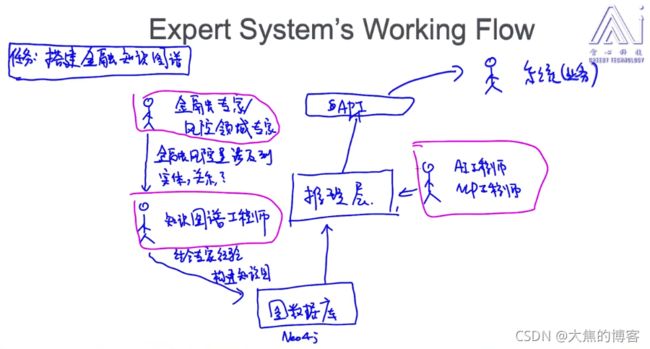
专家系统的特点:
1处理不确定性(就是从不确定中找到答案,例如选取概率最大的那个答案)
2知识表示(经典的方式:知识图谱,将非结构化的知识转为结构化的知识)
3可解释性(对模型判断的结果进行解释;专家系统是基于规则的,所以解释性非常强。解释为啥做出这样的决策的理由非常使人信服)
4可以做知识推理(在知识的基础上搭建推理引擎(后面会讲))

任务053:06逻辑推理

介绍两个算法:Forword Training、
通过两次循环证明出来了D is true

证明D is true 需要证明A and B is true

专家系统的优点:1.在数据量小的时候比较好用,直接定义规则就好。2.可解释性强。
专家系统的缺点:
1.需要设计大量的规则(规则来自专家经验,规则时间可能会有冲突)
2.需要领域专家来主导(专家很稀缺)
3.可移植性差(领域之间的知识很难迁移,例如儿科与耳鼻喉科)
4.学习能力差(知识是人工标记好的,推理属于锦上添花)
5.人能考虑的范围是有限的(专家系统严重依赖经验,经验不足时就会导致模型的预测出错,人不可能精通各个方面)

任务054:07Case Study 风控
解决的问题是根据用户的信息决定要不要放贷
深度学习绝不是解决任何问题都靠谱的东西

任务055:08解决一些难题的思路
规则可能有冗余,即有些规则是重复的,选取最小规则的子集就很必要。
方法:一个一个规则的删掉,看删掉之后有没有影响

解一个难题的思路
1.找出一个类似经典问题例如:最小集合问题
2.查找一些文献例如:关于最小集合问题的文献
在阅读文献的过程中会了解很多与最小集合问题相关的变种,所以会一步一步的找到与难题最相关的问题,此时就有思路了。

任务056:09机器学习介绍01
机器学习就是取学出一种映射关系,这个模型可以是线性回归、逻辑回归、决策树、神经网络。。。

专家系统靠人工,机器学习靠算法学习

机器学习算法的分类
生成模型、判别模型、监督学习、无监督学习
朴素贝叶斯用于文本分类
逻辑回归(面试常问)
条件随机场用于命名实体识别
HMM用于语音识别
LDA用于文本分析,将文本抽取出主题分布
GMM用于聚类
判别模型需要条件概率,而无监督模型没有标签信息,无法计算条件概率

实际应用中监督学习最多
在监督学习中最重要的是学出这个映射




例如
任务057:10机器学习介绍02
MF:矩阵分解,用于推荐系统
LDA是LSA的高级版

生成模型会将两类动物的各种特点都记住,从而判断一个动物是猫的概率是多少,是狗的概率是多少,从而将动物分类
最大化的P(x)
判别模型将两类动物的的区别记住,
最大化的是条件概率P(y|x)

建模流程:
数据—>清洗数据—>特征工程(认为提取有价值的特征,特征工程占据的时间成本非常高,特征决定了系统效果的上限,特征定了剩下就是选择模型)—>建模—>预测
特征工程人力成本很高,而且有巨大的挑战,既需要对一定想象力才能设计比较好的特征。
去掉特征工程就是端到端的方法。


任务058:11朴素贝叶斯介绍
任务:分类垃圾邮件和正常邮件
任务059:
任务060:
任务043:Interpolation:插值
任务043:Interpolation:插值
任务043:Interpolation:插值
任务043:Interpolation:插值
任务043:Interpolation:插值
任务043:Interpolation:插值
任务043:Interpolation:插值
任务043:Interpolation:插值
任务043:Interpolation:插值
任务043:Interpolation:插值
任务043:Interpolation:插值
任务043:Interpolation:插值
任务043:Interpolation:插值
任务043:Interpolation:插值
任务043:Interpolation:插值
任务043:Interpolation:插值
任务043:Interpolation:插值
任务043:Interpolation:插值
任务043:Interpolation:插值
任务043:Interpolation:插值
任务043:Interpolation:插值
任务043:Interpolation:插值
任务043:Interpolation:插值
任务043:Interpolation:插值
任务043:Interpolation:插值
任务043:Interpolation:插值
任务043:Interpolation:插值
任务043:Interpolation:插值
任务043:Interpolation:插值
任务043:Interpolation:插值
任务043:Interpolation:插值
任务043:Interpolation:插值
任务043:Interpolation:插值
任务043:Interpolation:插值
任务043:Interpolation:插值
任务043:Interpolation:插值
任务043:Interpolation:插值