PointRCNN 学习笔记
《PointRCNN: 3D Object Proposal Generation and Detection from Point Cloud》CVPR2019
前言
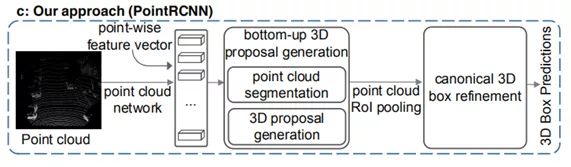
PointRCNN方法示意
PointRCNN是CVPR2019中3D目标检测的文章。该文章使用two-stage方式,利用PointNet++作为主干网络,先完成segmentation任务,判断每个三维点的label。对分为前景的每个点,使用feature生成框。然后对框进行roi crop,进行框的优化。
先前的方法都是在检测到物体的基础上做框,本文中提到的方法是对所有点都进行预测框,然后去除掉背景点预测的框,那么留下的前景点生成的框基本上都包含了检测目标,再从这些框中筛选优化得到最终的预测框。
论文亮点
- 第一个只用输入原始点云的两阶段3d目标检测方法。
- 使用前景点(语义分割得到的有效点)回归检测框,减少了检测框的搜索范围。
- canonical refinement的方法。
- 基于bin的loss。
思路概括
目前作者公布的代码只能对一个类别做检测,假设这个类就是“车”,这也是KITTI数据集中标注最多的类,这个目标检测方法分两个阶段:
(1)第一阶段:生成一大堆很冗余的bounding box。首先,对点云语义分割,对每个点得到一个预测label,比如现在:对所有判断是“车”的点(也叫做前景点),赋予label=1,其他点(也叫做背景点),赋予label=0。
然后,用所有前景点生成bounding box,一个前景点对应一个bounding box。但是必须要保证语义分割结果的准确。然后作者使用了一些去除冗余的方法,继续减少bounding box的数目,这一阶段结束的时候只留下300个bounding box。
(2)第二阶段:继续优化上一阶段生成的bounding box。首先,对前一阶段生成的bounding box做旋转平移,把这些bounding box转换到自己的正规划坐标系下(canonical coordinates)。结合上然后,通过点云池化等操作得到每个bounding box的特征,再结合第一阶段得到的全局语义特征,进行bounding box的修正和置信度的打分,从而到最终的bounding box。
网络框架
作者提出的方法分为两个阶段,第一个阶段是对前景点的分割以及3D预测框的生成,第二阶段则是对第一阶段产生的框的优化。
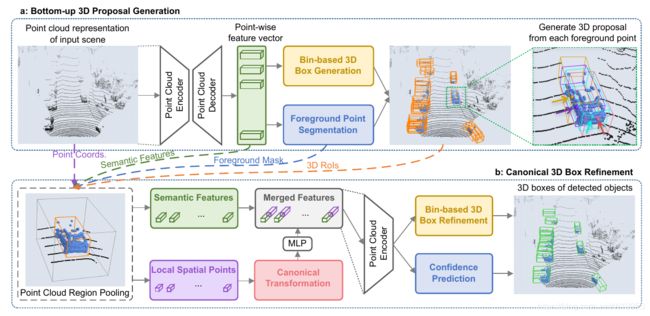
图2. PointRCNN架构,用于从点云进行3D对象检测。整个网络由两部分组成:(a)以自下而上的方式从原始点云生成3D提案。(b)以规范坐标改进3D提案。
第一阶段:自底向上的预选框生成
这个阶段有两个功能:
- 生成预选框(黄色)
- 分割前景点(蓝色)

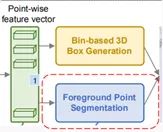
1、特征提取
作者用了PointNet++作为骨干网络来提取特征,同时在论文中指出也可以用其他的网络例如VoxelNet等来替代骨干网络的PointNet++。输入是(bs(batch size), n, 3)的点云,输出是(bs, n, 128)的特征。从图中可以看出,提取特征后,然后接了一个前景点分割网络(蓝色)和一个bin-based box生成网络(黄色)。一是前景点分割,二是生成预测框。分别得到1维向量和76维向量。
2、前景点分割
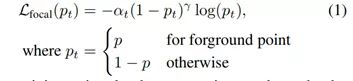
在训练点云分割期间,我们将默认设置αt= 0.25和γ= 2保留为原始论文
前景点分割网络,是由两个卷积层组成。输入是那个(bs, n, 128)的特征,输出是(bs, n, 1)的mask。1表示这个点属于前景点的概率,值越大,则它属于前景点的概率越高。加一个sigmoid限制到(0,1),然后用focal loss计算损失。
1.通过sigmoid函数将值映射到(0,1),设定阈值分割前景点
2.由于前景点的数量通常远小于背景点的数量,因此使用该函数来解决样本不均衡的问题。
3、预测框
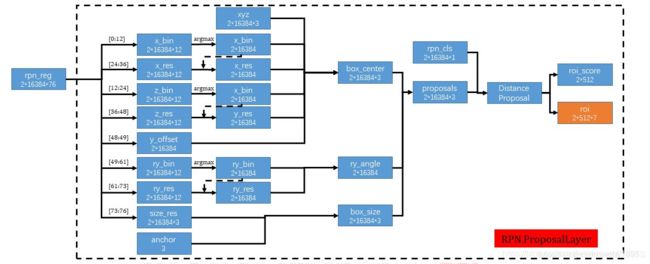
box生成网络,也是由两个卷积层组成。输入是那个(bs, n, 128)的特征,输出是(bs, n, 76)。这个76表示什么呢?就是论文的亮点之一:基于bin的预测。
什么是基于bin的预测呢?
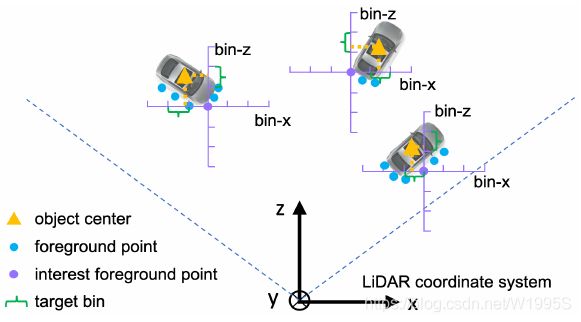
图3.基于bin的本地化的示意图。为了估计对象的中心位置,如图3所示,我们将每个前景点的周围区域沿X和Z轴分成一系列离散的bin。 具体来说,我们为当前前景点的每个X和Z轴设置搜索范围S,并将每个1D搜索范围划分为等长δ的bin,以表示X-Z平面上的不同对象中心(x,z)。 我们观察到,对X和Z轴使用具有交叉熵损失的基于bin的分类,而不是使用平滑的L1损失进行直接回归,会导致更准确和更可靠的中心定位。
这一步网络的输出是 (bs,n,76),也就是说对场景中的每一个点,预测一个bounding box。可以知道这样预测是非常冗余的,所以结合之前分割得到的mask,只考虑前景点的预测结果。
对于3d目标检测里的bounding box,需要7个量来表示:box中心点(x,y,z)box的长,宽,高(w,h,l), 俯视图的旋转角θ。这里用76维度的特征来代表这7个量。
要知道怎么用76个维度的特征来代表bounding box,就先得解决一个问题:什么是bin?bin在上图中用绿色大括号表示,就相当于直尺上的刻度,作者这里设置,在x和z上的bin的大小为0.5m,θ则是将2π划分为12个bin。
作者提出基于bin的预测,不是直接预测每个box中心点的坐标,而是预测每个前景点对于bounding box中心点的偏移,偏移了几个bin。但是这个bin是一个整数,还是无法精确定位,所以还需要预测中心点坐标在一个bin中的偏移量,把这个偏移量叫做res。
开始我很好奇,中心点,兴趣点都是什么,看作者在图上显示的是相对于兴趣点的偏移,但是在看代码的时候发现:
center3d = gt_boxes3d[k][0:3].copy() # (x, y, z)
center3d[1] -= gt_boxes3d[k][3] / 2
reg_label[fg_pt_flag, 0:3] = center3d - fg_pts_rect # 现在 y 是 3d 框的真正中心 20180928
所以其实可以简单的把兴趣点理解为bounding box的中心点。???
注意,只有在预测中心点x,z轴坐标和bounding box的旋转角θ时,用这种基于bin的思想。
下图表示的是由76维的向量预测框,前12维预测x方向上的bin,12-24预测z方向上的bin,24-36预测x方向的残差res,36-48预测z方向的残差res,48-49预测y方向的距离,49-61预测角度的bin,61-73预测角度上的残差res,73-76对长宽高做出预测。基于bin的预测参数x,z,θ,我们首先选择具有最高预测信度的bin中心,并添加预测残差以获得重新定义的参数。其他参数则没有使用基于bin的预测方法。

知道每个点对于中心点的偏移量之后,加上已知这个点本身的坐标,就可以得到中心点的坐标,因为:
![]()
所以只用知道一大堆前景点里面预测最准确的点就可以知道这个bounding box了。
衡量x,z坐标的时候是物理尺度上划分了几个bin,旋转角也用这种基于bin的方法预测,是把2π划分成若干个bin。(作者设置12)
为什么y就不用这种基于bin的方法预测呢?因为y轴是垂直于地面的,车啊人啊之类的检测目标都是贴着地面走的,飞不起来,就是路面的高度差会有不一样而已。
![]()
目标定位公式:
公式计算的是在ground-truth中bin所表示的含义
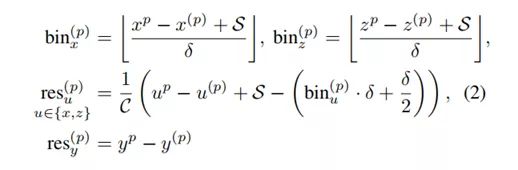
实际上就是计算偏差的公式。其中(x(p),y(p), z(p))是感兴趣的前景点的坐标,(xp,yp, zp)是其相应目标的中心坐标,bin(p)x和bin(p)z是沿X和Z轴的ground-truth bin assignments。 res(p)x和res(p)z是ground-truth residual,可用于在assigned bin中进一步细化位置,C是归一化的bin长度。S是前景点的search range,每个1D search range均分为相同长度δ的bin,以表示X-Z平面上不同目标的中心(x,z)。
第一阶段整体框回归的损失
- 我们使用focal loss2来处理类不平衡问题(前景点分割)

- 3D边界框回归损失
X 轴和 Z 轴的基于 bin 的分类损失,用cross-entropy loss。X或Z轴的(localization loss)定位损失由两个项组成,一个是沿每个X和Z轴的bin classification,另一个是classified bin中的residual regression。 对于沿垂直Y轴的中心位置y,我们直接利用smooth L1 loss进行回归,因为大多数目标的y值都在很小的范围内。
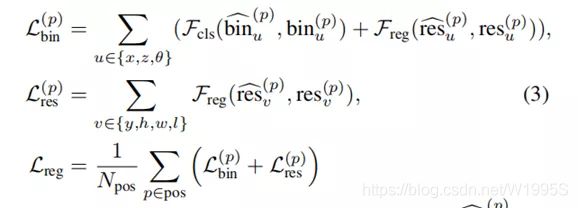
其中Npos是前景点的数量,bin^(p)u是预测的bin assignments,res^(p)u是前景点p的残差,bin(p)u和res(p)u是ground-truth目标 按照上面的公式(2)计算的实际偏差,Fcls表示交叉熵分类损失,Freg表示平滑的L1损失。
4、减少预测框的数量
这样7个bounding box检测的关键量都得到了,但是就算是每个前景点预测一个bounding box,也还是有很多个bounding box。
对于每一个点都预测一个框,利用前景点分割的结果去除一部分框,留下由前景点预测的框。这时,由于点云是密集的,所以依然有很多冗余的框,作者利用基于鸟瞰图的IoU进行非最大值抑制(NMS),以生成少量高质量提案。所以作者用了NMS来减少bounding box。
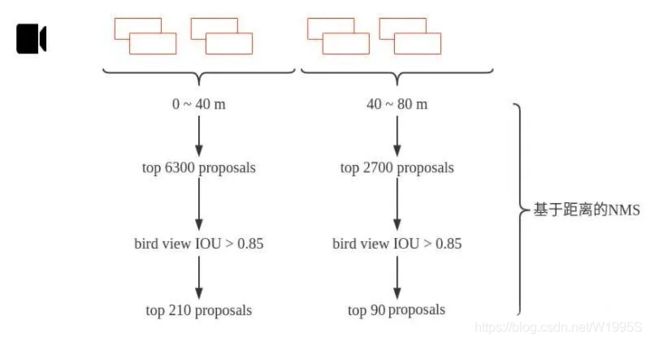
来解释一下上面的方法,训练时在相机0~40m距离内的bounding box,先取得分类得分最高的6300个,然后计算bird view IOU,把IOU大于0.85的都删掉,到这里bounding box 又少了一点。然后再取得分最高的210个。在距离相机40~80m的范围内用同样的方法取90个。这样第一阶段结束的时候只剩下300个bounding box了。
300个bounding box也还是很多。于是有了第二阶段置信度打分和bounding box优化。
而在实际预测时,使用具有IOU阈值0.8的定向NMS,并且只保留前100个bounding box。
第二阶段:再筛选和优化bounding box
这一阶段的输入是之前那300个proposal bounding box,大小表示为(bs,300,7)。然后300个也很多啊,作者又用sample和设置阈值的方法把box减少到128个。
把在每个bounding box proposal 内部的点聚集起来(池化),就得到大小为(bs,m,512,c)的数据。其中bs表示batch size, m表示每个batch中有多少个bounding box(比如上面提到的128), 512表示每个bounding box里面有多少个point。
然后作者设计了一些数据增强操作。先不细说。
接下来把每个bounding box内的points转换到局部坐标系(作者叫做canonical 转换)下。如下图。这也是本文的一个亮点。
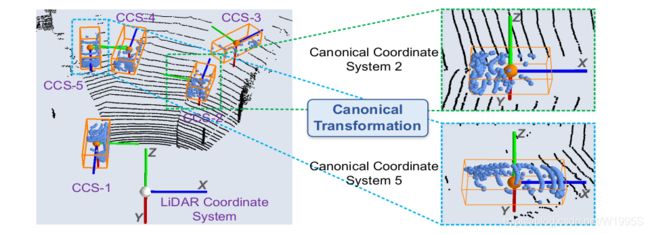
规范转换的插图。 属于每个proposal的池化后的点被转换为相应的规范坐标系,以便更好地进行每个proposal的局部空间特征学习,其中CCS表示规范坐标系。
什么是canonical 转换?
具体就是,新坐标系的坐标原点是bbox的中心点,局部的X’轴和Y’轴大致平行于地面,X’轴指向建议的头部方向,另一个Z’轴垂直于X’轴,使用规范的坐标系能使得预测框在改进阶段能够更好的学习局部特征。规范后的中心点坐标:
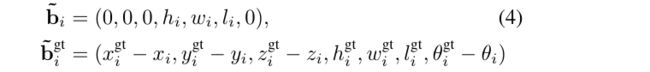
第i个 box proposal中心位置的训练目标, (bini∆x,bini∆z, resi∆x,resi∆z,resi∆y), 设置方法与公式(2)相同,只是我们使用较小的搜索范围S来重新定义3D proposal的位置。我们仍然直接回归大小残差 (resi∆h,resi∆w,resi∆l) w.r.t.训练集中每个类的平均对象大小,因为合并的稀疏点通常无法提供提议大小(hi,wi,li)的足够信息
第二阶段会结合第一阶段预测得到的大小为(bs,n,128)的全局语义feature。
具体就是,把大小为(bs,n,1)的mask,每个点距离相机的距离depth,每个点的反射强度(从雷达相机直接可以得到的值),每个点的坐标(x,y,z)。把这些特征concat在一起作为一个新的local feature,上采样到128维度,和第一阶段预测得到的128维的global feature结合得到新的特征。新特征为256维。
用pointnet++的SA module(set abstraction 点集抽象层)(如果不知道就得看一下pointnet++,是一个采样,分组,特征提取模块),得到高级特征,继续对这个特征进行卷积操作,得到一个 (m,1,512)的特征,表示一个场景中有m个bounding box, 一个512维的向量来代表这个bbox。
最后分别接一个reg_layer和一个cls_layer(其实也都还是conv1d)改变特征通道。得到(m,46)的bbox相关的预测结果和(m,1)的置信度结果。
这个46也是基于bin的预测,跟之前的76是一个内涵,只是现在0-6表示x_bin。
到这里网络的训练已经结束了。
如何从128个bbox中结合预测得到的confidence筛选出最后的bbox呢?这就是测试阶段考虑的问题了。
第二阶段总体损失
为了细化方向,我们假设角差 w.r.t. 基于建议与其真实值框之间的 3D IoU 至少为 0.55 的事实,真实值方向 θgt i - θi 处于 [− π /4, π/4 ] 范围内。 因此,我们将 π/2 划分为 bin 大小为 ω 的离散 bin,并将基于 bin 的方向目标预测为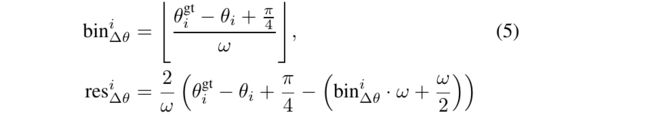
因此,阶段2子网络的整体损失可以表示为

其中B是来自阶段1的3D proposals集合,Bpos存储了回归的positive proposals (正样本),probi是~bi的估计置信度,而labeli是相应的标签,Fcls是用于监督预测信度的交叉熵损失,~Lbin和 ~Lres类似于公式(3)中的 Lpbin和 Lpres。如上所述由~bi和 ~bgti计算的新目标。
训练过程
PointRCNN是two-stage结构的网络,所以训练过程也是先训练RPN,再训练RCNN。
RPN
label:在通过dataloader构建训练数据的同时,构建label
cls_label:将gt_box内的点置1,gt_box之外extended_gt_box之内的点置-1(表示忽略)
reg_label:计算gt_box之内的点的reg量
loss:SigmoidFocalLoss + Full-bin Loss(CrossEntropyLoss + SmoothL1Loss)
RCNN
label:
cls_label:在RCNN.ProposalTargetLayer中的batch_cls_mask为label
reg_label:使用RCNN.ProposalTargetLayer中的roi_gt_boxes计算
loss:SigmoidFocalLoss + Full-bin Loss(CrossEntropyLoss + SmoothL1Loss)
实验
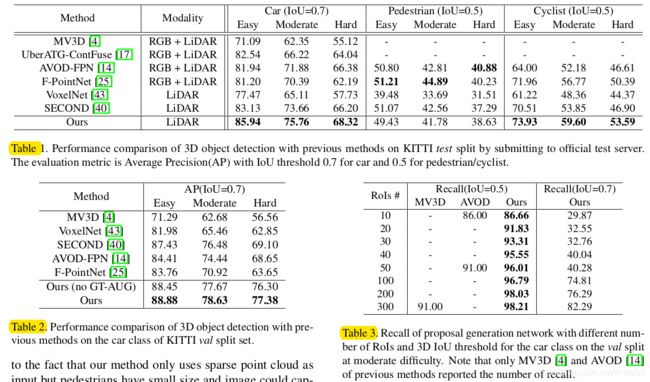
PointRCNN是一种用于从原始点云中检测3D物体的新型3D物体探测器。拟议的第一阶段网络以自下而上的方式直接从点云生成3D提案,与以前的提案生成方法相比,实现了更高的召回率。阶段2网络通过组合语义特征和局部空间特征来确定规范坐标中的提案。实验表明,PointRCNN在KITTI数据集的具有挑战性的3D检测基准上具有显著的优势。
参考(感谢)
https://blog.csdn.net/wqwqqwqw1231/article/details/90788500