CDC工具之Debezium
前言
在之前的文章中,我们讲到了CDC工具Canal,今天我们来继续聊聊另外一个CDC工具——Debezium。
一、Debezium是什么?
Debezium是一组分布式服务,用于捕获数据库中的更改,以便您的应用程序可以看到这些更改并做出响应。Debezium 将每个数据库表中的所有行级更改记录在更改事件流中,应用程序只需读取这些流即可按照它们发生的相同顺序查看更改事件。
简单来说:Debezium 类似Canal、Flink CDC等组件,也是一款可以监视数据实时变化并捕获数据的组件。可以将数据库中的数据实时同步到其余的组件中(如kafka)。
需要明确的是Debezium是依赖基于日志的CDC(Change Data Capture)技术实现的组件。我们应该知道另外存在基于查询的CDC技术,之前关于Canal的文章中已经简单介绍过,需要回顾的小伙伴可以重新回顾一下。
Debezium支持的数据源类型
当前最新版本支持的数据源类型为:
| MySQL |
| MongoDB |
| PostgreSQL |
| Oracle |
| SQL Server |
| Db2 |
| Cassandra |
| Vitess |
二、Debezium基础架构
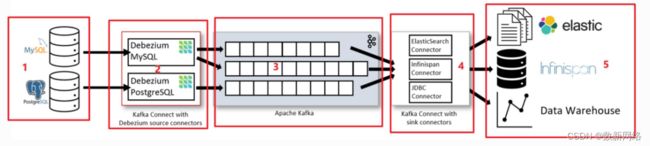
我们分别介绍上图的五个部分:
-
第一部分是我们要捕获的数据来源,一般是类似于MySql、PostgreSQL的数据库组件。或者Oracle、SqlServer等。
-
第二部分是Kafka Connect服务,其中包含Debezium MySQL以及Debezium PostgreSQL,他们是Debezium连接器,交由Kafka Connect服务管理,用来获取数据来源中的变更事件,并将事件发送到Kafka中。
-
第三部分是Apache Kafka组件,是一种高吞吐量的分布式发布订阅消息系统。Debezium连接器将采集到的变更事件存储在Kafka中。
-
第四部分也是Kafka Connect服务,其中包含了额外的连接器也就是JDBC Connector等,他们可以将Kafka中的数据消费写出到其余的组件上。
-
第五部分是常见的数据目的组件,比如elastic、Data Warehouse(数据仓库),第四部分的连接器消费到的消息最终会写入这些组件中。
到这里,我们显然可以看出Kafka Connect服务是Debezium依赖的重要对象,因此我们简单介绍一下Kafka Connect。
Kafka Connect
一句话概括:它是连接器的框架和运行时环境。
Kafka connector是一种处理数据的通用框架:kafka连接器制定了一种标准,用来约束kafka系统与其他系统的集成,简化了kafka连接器的开发、部署和管理过程。
这时候可能又有疑问?连接器是什么?
首先需要明确连接器分为两种:source connector以及sink connector。
source connector又称为源连接器,主要定义数据如何输入到Kafka中;sink connector则是将数据从Kafka中取出并放在其他地方。
而Kafka Connect可以简单理解为管理这些connector的一个服务。
到现在为止,我猜你会认为Debezium是一组源连接器。事实上Debezium的连接器(比如刚刚第二部分中的Debezium MySQL以及Debezium PostgreSQL)确实是属于源连接器,至于为什么会是一组连接器我们接下来会揭晓答案。目前我们只需要知道Debezium的主要内容就是各种连接器,然后我们会将 Debezium 连接器部署到 Kafka Connect 中。如果是 MySQL,他们会订阅 binlog,如果是Postgres,他们会订阅逻辑复制流,然后他们会将这些更改传播到相应的Kafka主题中。默认情况下, 每个捕获的表都有一个主题。
三、Debezium Connector
首先让我们简单介绍下Debezium是如何支持多种数据源的数据变更捕获的。
它本质上是基于事务日志的变更数据捕获,适用于各种数据库。问题是,去事务日志那里获取更改事件的想法很好,但不幸的是,没有单一的 API,没有单一的方法可以为所有数据库执行此操作。相反,我们需要弄清楚,我们如何从 Postgres中获取更改?我们如何将它们从MySQL中取出?这一直是一项原始的工程工作,这就是Debezium要做的事情。如何从这些不同的数据库中获取更改,然后产生更改事件,这些事件相当抽象,也相当通用。所以Debezium依据不同的数据库去封装不同的Connector去做 这个事情。
四、Debezium Architecture
4.1 基于Kafka的部署模式
最常见的情况就是我们之前介绍过的,通过 Apache Kafka Connect部署 Debezium。刚好我们再来简单回顾一下:

如图所示,部署了用于 MySQL 和 PostgresSQL 的 Debezium 连接器来捕获对这两种类型的数据库的更改。每个 Debezium 连接器都建立到其源数据库的连接:
-
MySQL 连接器使用客户端库来访问binlog .
-
PostgreSQL 连接器从逻辑复制流中读取。
Kafka Connect 作为 Kafka broker之外的单独服务运行。
默认情况下,来自同一个数据库表的更改将写入名称与表名相对应的 Kafka 主题。如果需要,我们可以通过配置 Debezium 的主题路由转换来调整目标主题名称。例如,我们可以:
-
将记录路由到名称与表名不同的主题,比如说A表原本同步到Kafka的A主题,但是我们可以通过修改配置使A表同步到Kafka的B主题。
-
将多个表的更改事件记录流式传输到单个主题中,比如说原本默认A表同步到Kafka的A主题,B表默认同步到Kafka的B主题,我们也可以通过修改配置使A表和B表的变更事件全部同步到Kafka的C主题。
更改事件记录在 Apache Kafka 中后,Kafka Connect 生态系统中的不同连接器可以将记录流式传输到其他系统和数据库中,例如 Elasticsearch、数据仓库和分析系统,或 Infinispan等缓存。
4.2 Debezium Server
部署 Debezium 的另一种方法是使用Debezium Server。Debezium Server是一个可配置的、即用型的应用程序,它将更改事件从源数据库流式传输到各种消息传递基础设施之上。
该模式的变更数据捕获管道的架构大概如下:
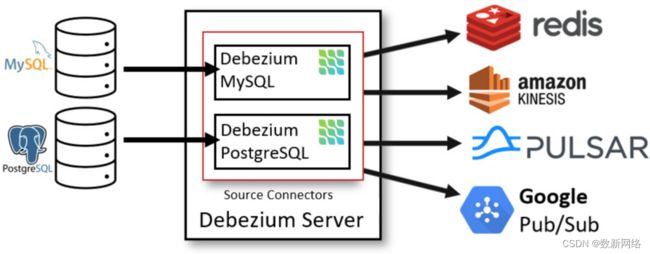
Debezium 服务器配置为使用Debezium连接器之一从源数据库捕获更改。更改事件可以序列化为不同的格式,如 JSON 或 Apache Avro,然后将事件发送到各种消息传递基础设施之上,如 Amazon Kinesis、Google Cloud Pub/Sub 或 Apache Pulsar。
4.3 Embedded Engine
另外一种使用Debezium连接器的方法是Embedded Engine。在这种情况下,Debezium 将不会通过Kafka Connect运行,而是作为嵌入到我们的自定义 Java 应用程序中的库。这对于在应用程序本身中使用更改事件(无需部署完整的Kafka和Kafka Connect集群)或将更改流式传输到 Amazon Kinesis 等替代消息传递代理非常有用。
五、Debezium 特性
Debezium连接器使用一系列相关功能和选项捕获数据更改:
快照:可选的,如果连接器已启动并且并非所有日志仍然存在,则可以拍摄数据库当前状态的初始快照。通常,当数据库已经运行了一段时间并且丢弃了事务恢复或复制不再需要的事务日志时,就会出现这种情况。执行快照有不同的模式,包括支持增量快照,可以在连接器运行时触发。
简单提一下快照的概念。首先我们知道事务日志存在于数据库中主要有两个原因,即事务恢复和复制。这意味着如果数据库表示“我不再需要这些日志”,它将丢弃它们。这意味着如果我们的数据库已经运行了一段时间,现在我们将设置 CDC,而它不会有两年前的事务日志文件,这就是快照的用武之地。当需要时Debezium将对当前数据进行一致的快照,然后,一旦快照完成,它将自动转到日志读取模式并继续从该确切时间点读取事务日志。
-
过滤器:我们可以使用包含/排除列表过滤器来配置捕获的模式、表和列的集合。也就是说我们可以指定需要同步哪些表及列等。
-
屏蔽:可以屏蔽来自特定列的值,例如,当它们包含敏感数据时。
-
监控:大多数连接器都可以使用JMX进行监控。
-
用于消息路由、过滤、事件扁平化等的即用型消息转换。
结语:
本篇主要内容到这里就结束了,本篇文章的主要目的在于帮助各位小伙伴了解Debezium大概是个什么东西,揭开它的神秘面纱,如果看到这里有个大概的了解,说明学习已经到位了。如果还是不太清楚,可能是由于本人功力不够深厚,没有说的通俗易懂,欢迎各位提出意见,thank you!
由于篇幅原因,本篇文章没有深入介绍相关特性,如果有需要,后期会详细介绍各种特性以及Debezium连接器的实现细节等。