RabbitMQ集群
目录
1、集群分类
1.1 普通集群
1.1.1 集群结构和特征
1.1.2 部署
1.2 镜像集群
1.2.1 集群结构和特征
1.2.2 部署
2、仲裁队列
2.1 部署
2.2 .Java代码创建仲裁队列
2.3 SpringAMQP连接MQ集群
今天我们来学习如何避免单点的MQ故障而导致的不可用问题,这个就要靠MQ的集群去实现了。
1、集群分类
RabbitMQ的是基于Erlang语言编写,而Erlang又是一个面向并发的语言,天然支持集群模式。RabbitMQ的集群有两种模式:
1.1 普通集群
是一种分布式集群,将队列分散到集群的各个节点,从而提高整个集群的并发能力。
这种集群有一个问题,一旦集群中某个节点出现了故障,那这个节点上的队列,以及上面的消息就全都没了,所以它会存在一定的安全问题。
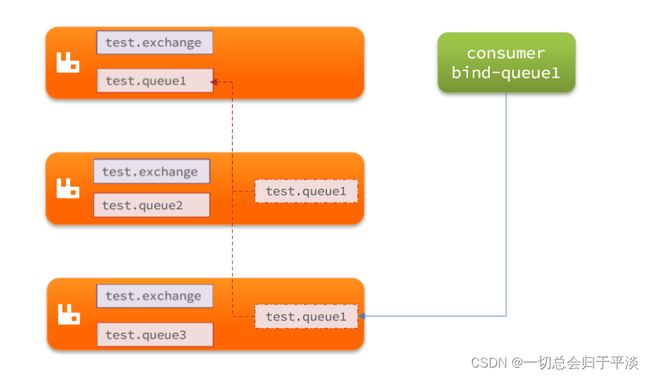
1.1.1 集群结构和特征
普通集群,或者叫标准集群(classic cluster),具备下列特征:
会在集群的各个节点间共享部分数据,包括:交换机、队列元信息(队列的描述信息,包括队列名字,队列节点,队列有什么消息)。不包含消息本身。
当访问集群某节点时,如果队列不在该节点,会从数据所在节点传递到当前节点并返回
队列所在节点宕机,队列中的消息就会丢失
结构如图:
1.1.2 部署
我们的计划部署3节点的mq集群: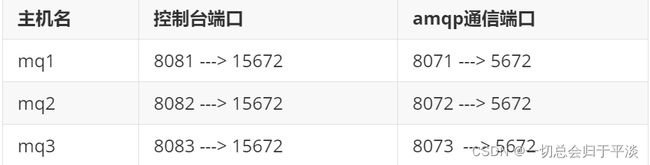
这里三个主机就是三台机器,这里我用三个Docker代替了。
集群中的节点标示默认都是:rabbit@[hostname],因此以上三个节点的名称分别为:
rabbit@mq1
rabbit@mq2
rabbit@mq3
1、获取cookie
RabbitMQ底层依赖于Erlang,而Erlang虚拟机就是一个面向分布式的语言,默认就支持集群模式。集群模式中的每个RabbitMQ 节点使用 cookie 来确定它们是否被允许相互通信。
要使两个节点能够通信,它们必须具有相同的共享秘密,称为Erlang cookie。cookie 只是一串最多 255 个字符的字母数字字符。
每个集群节点必须具有相同的 cookie。实例之间也需要它来相互通信。
我们先启动一个mq容器中获取一个cookie值,作为集群的cookie。执行下面的命令:
docker exec -it mq cat /var/lib/rabbitmq/.erlang.cookie我的之前的mq容器就叫mq。
可以看到我的cookie值如下:
![]()
接下来,停止并删除当前的mq容器,我们重新搭建集群(记得把cookie值复制保存一下)。
docker rm -f mq
2、准备集群配置
在/tmp目录新建一个配置文件 rabbitmq.conf:
cd /tmp创建文件
touch rabbitmq.conf
文件内容如下:
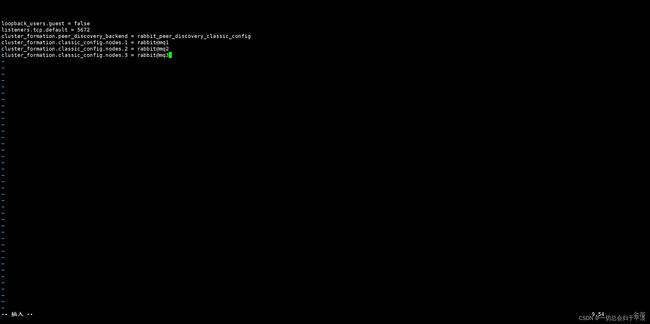
loopback_users.guest = false
listeners.tcp.default = 5672
cluster_formation.peer_discovery_backend = rabbit_peer_discovery_classic_config
cluster_formation.classic_config.nodes.1 = rabbit@mq1
cluster_formation.classic_config.nodes.2 = rabbit@mq2
cluster_formation.classic_config.nodes.3 = rabbit@mq3解析:
loopback_users.guest =false:禁用guest用户,因为RabbitMQ客户端有一个guest用户,所以我们把它禁用掉,防止有些不法分子来访问我们。
listeners.tcp.default = 5672:监听端口,用于消息通信
最重要的是下面三个:
cluster_formation.classic_config.nodes.1 = rabbit@mq1 cluster_formation.classic_config.nodes.2 = rabbit@mq2 cluster_formation.classic_config.nodes.3 = rabbit@mq3
这里配置的分别集群中的节点信息。
再创建一个文件,记录cookie。
cd /tmp创建cookie文件。
touch .erlang.cookie写入cookie
echo "NEHXVEBVVLVHYDWCAFVH" > .erlang.cookie修改cookie文件的权限
chmod 600 .erlang.cookie准备三个目录,mq1、mq2、mq3:
cd /tmp
创建目录
mkdir mq1 mq2 mq3然后拷贝rabbitmq.conf、cookie文件到mq1、mq2、mq3:
cd /tmp拷贝
cp rabbitmq.conf mq1
cp rabbitmq.conf mq2
cp rabbitmq.conf mq3
cp .erlang.cookie mq1
cp .erlang.cookie mq2
cp .erlang.cookie mq33、启动集群
创建一个网络:
docker network create mq-net![]()
运行命令
mq1:
docker run -d --net mq-net \
-v ${PWD}/mq1/rabbitmq.conf:/etc/rabbitmq/rabbitmq.conf \
-v ${PWD}/.erlang.cookie:/var/lib/rabbitmq/.erlang.cookie \
-e RABBITMQ_DEFAULT_USER=jie \
-e RABBITMQ_DEFAULT_PASS=123456 \
--name mq1 \
--hostname mq1 \
-p 8071:5672 \
-p 8081:15672 \
rabbitmq:3.8-managementmq2:
docker run -d --net mq-net \
-v ${PWD}/mq2/rabbitmq.conf:/etc/rabbitmq/rabbitmq.conf \
-v ${PWD}/.erlang.cookie:/var/lib/rabbitmq/.erlang.cookie \
-e RABBITMQ_DEFAULT_USER=jie \
-e RABBITMQ_DEFAULT_PASS=123456 \
--name mq2 \
--hostname mq2 \
-p 8072:5672 \
-p 8082:15672 \
rabbitmq:3.8-managementmq3:
docker run -d --net mq-net \
-v ${PWD}/mq3/rabbitmq.conf:/etc/rabbitmq/rabbitmq.conf \
-v ${PWD}/.erlang.cookie:/var/lib/rabbitmq/.erlang.cookie \
-e RABBITMQ_DEFAULT_USER=jie \
-e RABBITMQ_DEFAULT_PASS=123456 \
--name mq3 \
--hostname mq3 \
-p 8073:5672 \
-p 8083:15672 \
rabbitmq:3.8-management打开浏览器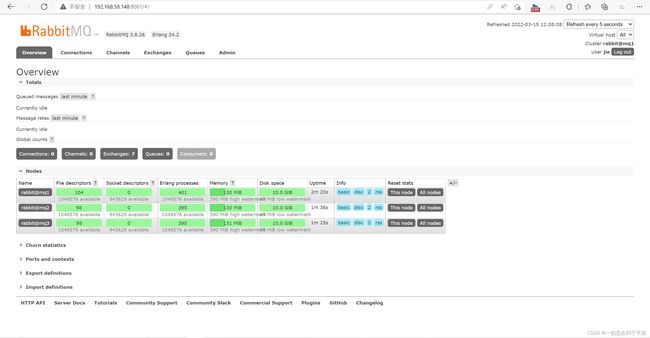
4、测试
在mq1这个节点上添加一个队列:
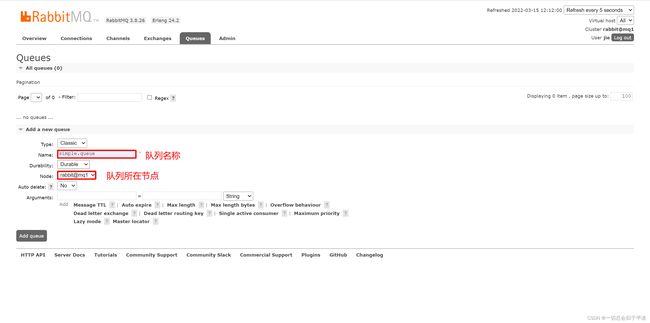
然后我们去mq2和mq3那里也能看到这个队列。
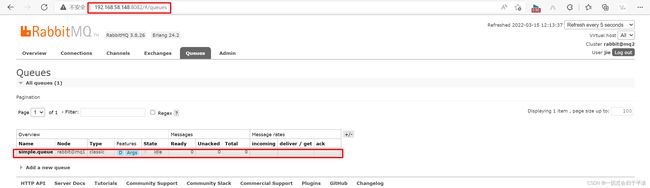
4.1 数据共享测试
点击这个队列,进入管理页面:

然后利用控制台发送一条消息到这个队列: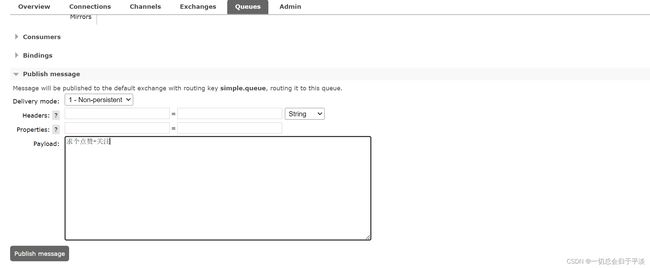
结果在mq2、mq3上都能看到这条消息:
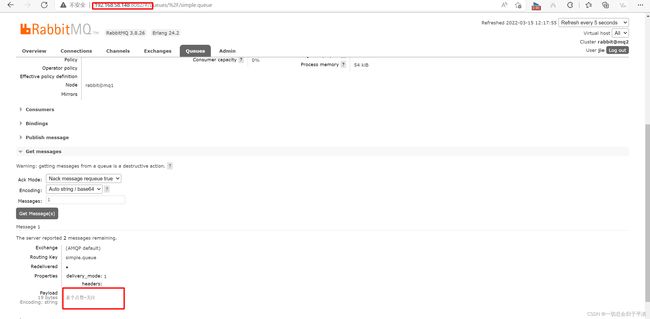
4.2 可用性测试
我们让其中一台节点mq1宕机:
docker stop mq1
然后登录mq2或mq3的控制台,发现simple.queue也不可用了:
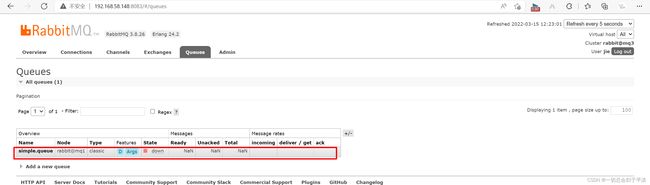
说明数据并没有拷贝到mq2和mq3。
1.2 镜像集群
在刚刚的案例中,一旦创建队列的主机宕机,队列就会不可用。不具备高可用能力。如果要解决这个问题,必须使用官方提供的镜像集群方案。
官方文档地址:Classic Queue Mirroring — RabbitMQ
镜像集群是一种主从集群,普通集群的基础上,添加了主从备份功能,提高集群的数据可用性。
这种集群有一个问题,主从数据源要同步,要从主节点同步到从节点,但是这个主从同步它不是强一致的,存在一定的延迟,如果在主从同步期间出现了一点故障,就可能导致数据丢失。
因此在RabbitMQ的3.8版本以后,推出了新的功能:仲裁队列来代替镜像集群,底层采用Raft协议确保主从的数据一致性。
1.2.1 集群结构和特征
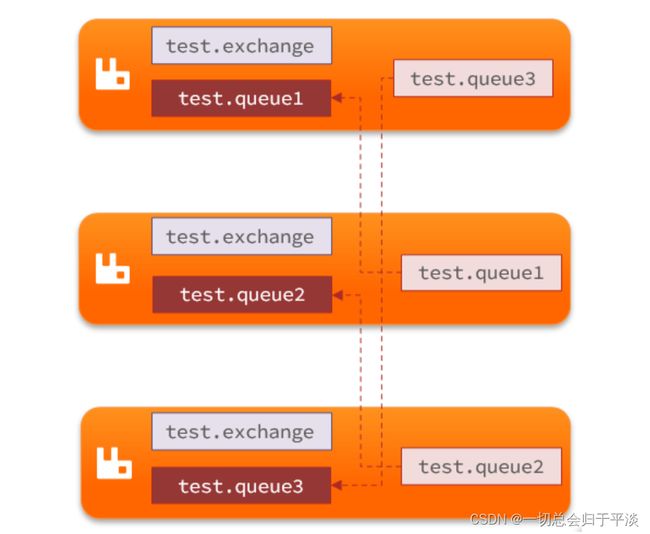
交换机、队列、队列中的消息会在各个mq的镜像节点之间同步备份。
创建队列的节点被称为该队列的主节点,备份到的其它节点叫做该队列的镜像节点。
一个队列的主节点可能是另一个队列的镜像节点。
不具备负载均衡功能,因为所有操作都是主节点完成,然后同步给镜像节点。
主宕机后,镜像节点会替代成新的主节点。
结构如图:
1.2.2 部署
镜像集群的配置有3种模式:

这里我们以rabbitmqctl命令作为案例来讲解配置语法。
语法示例:
1、exactly模式
首先进入任意一个节点
docker exec -it mq1 bash![]()
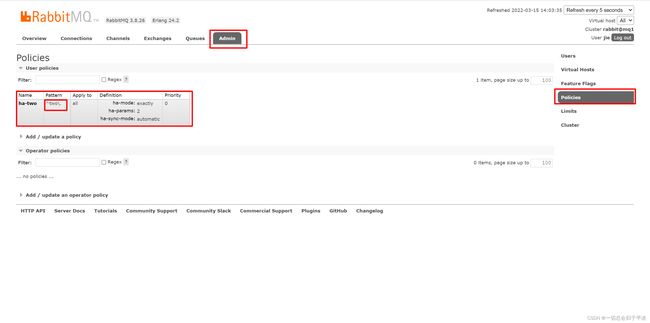
rabbitmqctl set_policy ha-two "^two\." '{"ha-mode":"exactly","ha-params":2,"ha-sync-mode":"automatic"}'
rabbitmqctl set_policy`:固定写法
ha-two:策略名称,自定义
"^two\.":匹配队列的正则表达式,符合命名规则的队列才生效,这里是任何以two.开头的队列名称
'{"ha-mode":"exactly","ha-params":2,"ha-sync-mode":"automatic"}': 策略内容
"ha-mode":"exactly":策略模式,此处是exactly模式,指定副本数量
"ha-params":2:策略参数,这里是2,就是副本数量为2,1主1镜像
"ha-sync-mode":"automatic":同步策略,默认是manual,即新加入的镜像节点不会同步旧的消息。如果设置为automatic,则新加入的镜像节点会把主节点中所有消息都同步,会带来额外的网络开销
然后退出 exit,我们进入浏览器查看。
我们创建一个新的队列: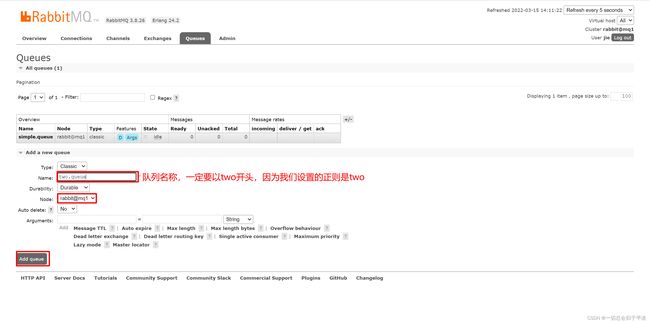
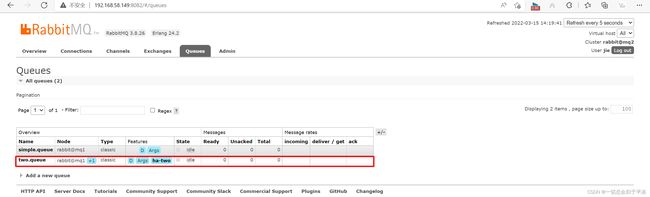
在任意一个mq控制台查看队列:
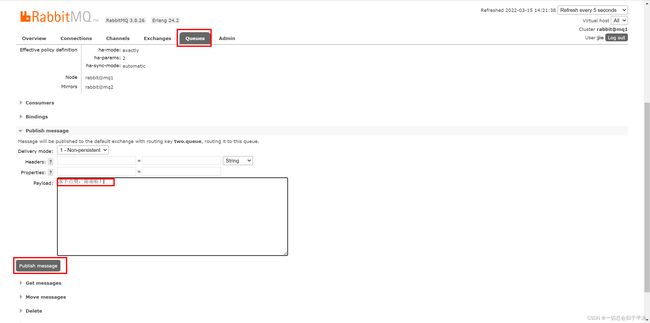
测试数据共享,给two.queue发送一条消息:
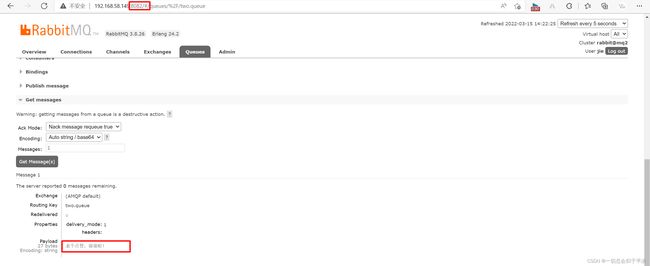
然后在mq1、mq2、mq3的任意控制台查看消息:
测试高可用,现在,我们让two.queue的主节点mq1宕机:
docker stop mq1然后我们先看集群状态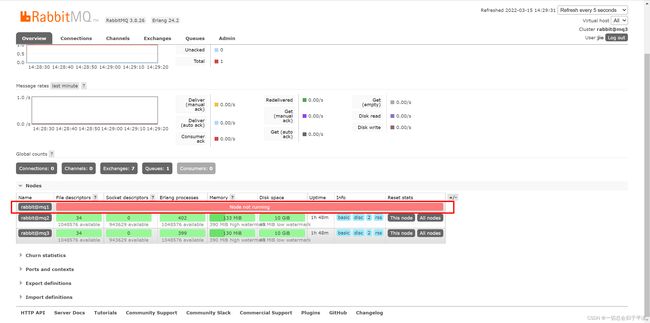
再看队列状态: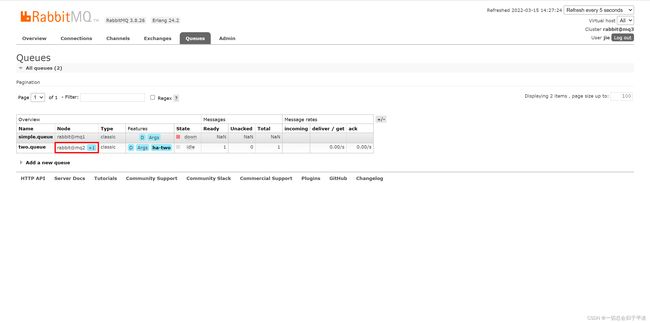
发现依然是健康的!并且其主节点切换到了rabbit@mq2上。
剩下的模式,大家可以自己去试试,大同小异。
2、all模式
rabbitmqctl set_policy ha-all "^all\." '{"ha-mode":"all"}'
ha-all:策略名称,自定义
"^all\.":匹配所有以all.开头的队列名
'{"ha-mode":"all"}':策略内容
"ha-mode":"all":策略模式,此处是all模式,即所有节点都会称为镜像节点
3、nodes模式
rabbitmqctl set_policy ha-nodes "^nodes\." '{"ha-mode":"nodes","ha-params":["rabbit@nodeA", "rabbit@nodeB"]}'
rabbitmqctl set_policy:固定写法
ha-nodes:策略名称,自定义
"^nodes\.":匹配队列的正则表达式,符合命名规则的队列才生效,这里是任何以nodes.开头的队列名称
'{"ha-mode":"nodes","ha-params":["rabbit@nodeA", "rabbit@nodeB"]}': 策略内容
"ha-mode":"nodes":策略模式,此处是nodes模式
"ha-params":["rabbit@mq1", "rabbit@mq2"]:策略参数,这里指定副本所在节点名称
2、仲裁队列
从RabbitMQ 3.8版本开始,引入了新的仲裁队列,他具备与镜像队里类似的功能,但使用更加方便,它具备以下特征。
-
与镜像队列一样,都是主从模式,支持主从数据同步
-
使用非常简单,没有复杂的配置
-
主从同步基于Raft协议,强一致
2.1 部署
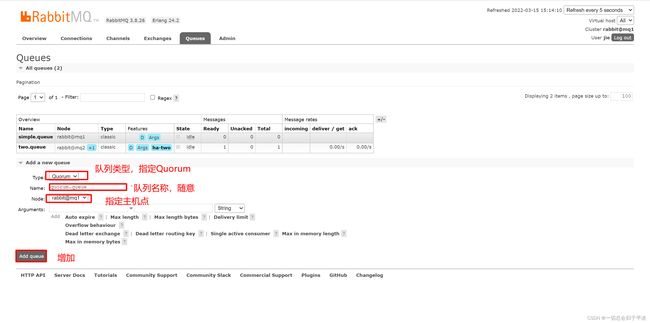
在任意控制台添加一个队列,一定要选择队列类型为Quorum类型。
在任意控制台查看队列:
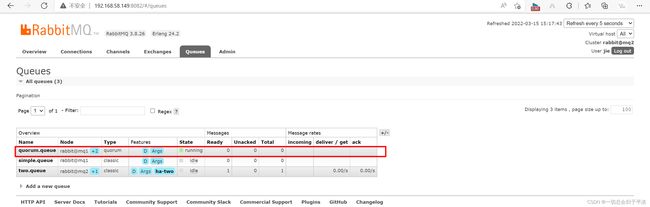
可以看到,仲裁队列的 + 2字样。代表这个队列有2个镜像节点。
因为仲裁队列默认的镜像数为5。如果你的集群有7个节点,那么镜像数肯定是5;而我们集群只有3个节点,因此镜像数量就是3.
测试参考镜像集群的方式,效果是一样的。
2.2 .Java代码创建仲裁队列
要创建仲裁队列记得先去配置集群。
@Bean
public Queue quorumQueue() {
return QueueBuilder
.durable("quorum.queue") // 持久化
.quorum() // 仲裁队列
.build();
}2.3 SpringAMQP连接MQ集群
注意,这里用address来代替host、port方式
spring:
rabbitmq:
addresses: 192.168.58.149:8071, 192.168.58.149:8072, 192.168.58.149:8073
username: jie
password: 123456
virtual-host: /