论文详读 - CCS 2019 TokenScope
论文详读 - CCS 2019 TokenScope: Automatically Detecting Inconsistent Behaviors of Cryptocurrency Tokens in Ethereum
-
- 论文
- Background & Motivation
-
- 例子1:UGToken
- 例子2:A Malicious Token
- TokenScope
-
- Basic idea
- Notation
- Workflow
- Stage 1:Trace Recording
- Stage 2: Locating Core Data Structure
- Stage 3: Detecting Inconsistent Behaviors
- Experiments
- Reasons of Inconsistent Behaviors
- Conclusion
论文
今天带来的是 CCS 2019 年的论文 TokenScope,是电子科技大学陈厅老师的工作,主要是自动化检测 Token 的不一致行为。
Background & Motivation
首先是关于Background 和 Motivation。
区块链上的货币有两种,一种是原生货币,另一种是 Token,它是一种在智能合约中实现的加密货币。
因为智能合约的编写非常自由,现在市场上 Token 众多,而 Token 是需要与外部世界进行交互的,用户一般都是通过一些第三方工具(比如 blockchain explorer、 wallet 等)与代币合约进行交互,那么我们就有必要规范化这一交互,于是便有了 Token Standard 的出现,它里面一般是定义了 standard interfaces(methods) 和 standard events,比如 ERC-20 就定义了6个 standard methods 和 2个 standard events。
Token Standard 定义好了之后,第三方工具一般都是通过监听这些 standard interfaces(methods) 和 standard events 来完成用户与 Token 的交互,以此获取 Token 的行为。如下:

ERC-20 是最被广泛使用的 Token Standard ,在本篇论文进行工作时,几乎99%的 Token 都是遵循 ERC-20 标准的。
ERC-20 中定义了3个可选的 standard methods,6个必须实现的 standard methods 和 2个 standard events,它也允许程序员的一些非标准方法和事件的实现。
下面以转账相关的函数和事件举例,这也是本篇论文检测不一致行为所要用到的 standard methods 和 standard events,关于转账的金额和相关账户都如图所示:

此外,ERC-20 除了定义了上面三者之外,还做了这样的规定:
- 只要有 Token 被转移,就必须 emit Transfer
- 只要使用了 transfer() 和 transferFrom(),就必须 fire the Transfer,即使转了0个Token也要如此。
因此,第三方工具只要监控代码中的 transfer() 、 transferFrom() 和 Transfer,得到其中的参数,就可以获取 Token 的行为,比如转了多少钱、转给谁等。
标准都给定义好了,现在关键问题就来了:
Token 的真实行为是否与标准中定义的一致?
因为一旦发生了不一致,即外部世界得到的信息与真实发生的不一致,那么会造成严重的经济损失,下面举两个例子。
例子1:UGToken

如图所示,是一个真实世界中部署在以太坊上的例子 UGToken,这里是它的三个有问题的函数。
首先,第一个函数 transferProxy(),这是一个自定义的非标准函数,可以看到在第二行中的_feeUgt + _value存在一个整数溢出的问题,那么当_feeUgt 和_value很大时,它们的和却很小,。这会导致,第3行和第5行的两个账户增加了很多 Token,而在第7行中,由于整数溢出问题, _from账户只减少了少量的 Token,这就和第4行和第6行的标准事件指示的不一致了,外界监听到的是和4、6行相同的内容,而事实上并不是这样。
其次,第二个函数transfer(),这是一个标准函数,当外界监听到这样一个标准函数时,认为必然发生了如参数中那样的 Token 转移,但是在第10行的else分支中直接return false结束当前函数,而没有发生 Token 转移,这就造成了不一致。
最后,第三个函数allocateToken(),这里12行进行了 Token 的转移,但是没有触发标准事件Transfer,这会导致外部世界无法得知这里发生了 Token 的转移,这也是一种不一致行为。
以上三种问题都可以通过图中阴影部分的代码来替换修改。
例子2:A Malicious Token

第二个例子是由作者团队为了进行测试而实现并部署的一个恶意合约。
由图可以看到,该合约在第7行实现标准函数 transfer,指示着msg.sender 转移_value Token 给 _to。但是该合约偷偷添加了一个fee(第5行),并每次进行 transfer 是都向 hacker 账户转 feeToken(第11行),同时用一个 mapping 变量 victim进行记录每个受害账户的损失数。再通过函数balanceOf向用户返回虚假的余额,以此掩盖窃取 Token 的行为。
这里就发生了真实 Token 转移与标准事件、标准方法指示的不一致。
TokenScope
因此,为了检测这种不一致的 Token 转账行为,本工作提出了 TokenScope。
Basic idea
将真实的 Token 转账行为与 standard methods 和 standard events 指示的行为进行比较。如果其中任何两个不匹配,就认为发生了不一致的行为。
如果调用了 non-standard methods,我们只需将真实的 Token 转账行为与 standard events 指示的行为进行比较。
Notation
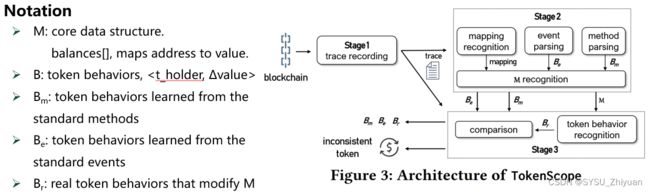
涉及到的符号含义如图所示:
M: 核心数据结构。balance[]
B: token行为,<t_holder,∆value>
Bm: 从 standard methods 中得到的 token 行为
Be: 从 standard events 中得到的 token 行为
Br: 对 M 进行了修改的真实 token 行为
Workflow
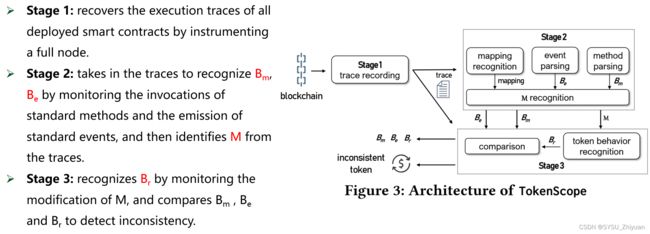
TokenScope 的整体工作流程如图所示,一共分为三步:
第一阶段:通过对一个区块链全节点进行插桩重放,来恢复所有已部署智能合约的执行 traces。
第二阶段:通过监听 standard methods 和 standard events 来识别得到 Bm 和 Be,然后记录 mapping 变量,根据三者联系得到核心数据结构 M。
第三阶段:通过监听 M 的变化来识别 Br,比较 Bm、Be 和 Br,发现不一致。
Stage 1:Trace Recording
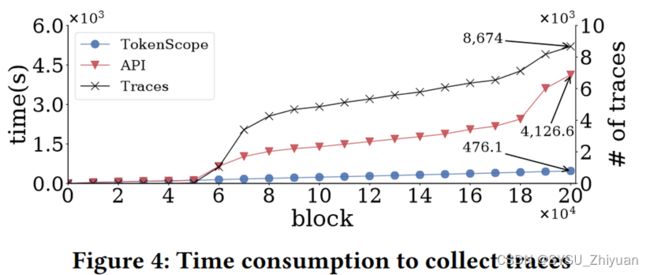
第一步 获取 trace
以太坊原生的方法debug.traceTransaction,运行速度过慢。
故本工作插桩一个以太坊全节点,因为区块链的每个节点将下载所有的块,并在同步期间重放所有的交易。
两方法速度对比如下:
第二步 记录 trace
如下图,一条 trace 分为四方面内容,分别是对应外部交易的哈希、交易接收者(即被调用的智能合约)的地址、交易携带的数据(指定被调用的方法和参数),以及所有被调用的智能合约按顺序执行的EVM操作。
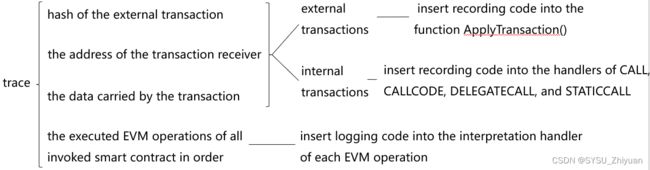
其中,前三者在面对外部交易和内部交易时,分别以不同的方式获取。
EVM 的操作通过 Log 获取。
Stage 2: Locating Core Data Structure
第二阶段主要有四步。

第一步 定位 mapping 变量
第一步的挑战在于:没有 Token 的源代码,EVM字节码中没有显式的映射结构。因此难以定位mapping 变量。
本工作的解决方法是:通过少量具有源码的 Token,总结 mapping 的一般 pattern,从而推及到所有 Token中。
于是,最终总结出四种 mapping 变量的 pattern。
Type-I.

Type-II.

Type-III.
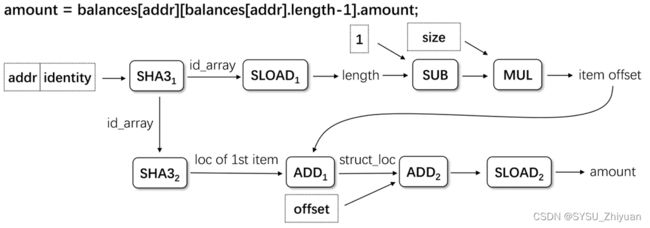
Type-IV. Two maps
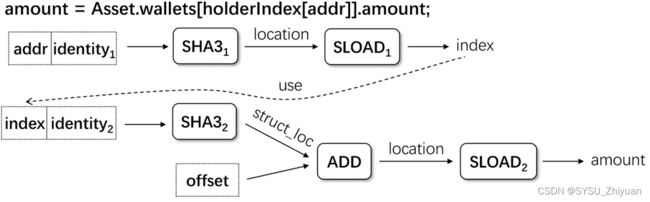
第二步 解析 standard methods
通过解析 standard methods 来获取 Bm:
- 对于外部交易,使用 TransitionDb()
- 对于内部交易,通过插桩 opCall() 获取
第三步 解析 standard events
通过对交易日志的解析定位 standard events 来获取 Be:
- 对于每个日志操作,获取第三个 32-byte 值(event ID)
- 根据 ID 定位 Transfer 事件
- 记录 Be
第四步 识别核心数据结构 M
挑战:Token 合约中可能有多个 mapping 变量。
如下图,有两个 mapping 变量,我们知道若想识别 Token 的真实转移,需要的是 balances[],但是机器不知道。

方法:将 mapping 与 standard methods 或 standard events 关联起来。
如果存在 mapping 变量的修改与 standard methods 或 standard events 一致的 trace,则将 mapping 变量视为M。
简单来说,如上图, balances[] 中修改的参数(_value)与 standard methods 或 standard events 中的参数更相关,而 victim[] 涉及的fee就没那么相关,所以将 balances[] 视为 M。
Stage 3: Detecting Inconsistent Behaviors
第一步 Br 识别
通过监听 M 的修改来识别真实的 Token 行为 Br。
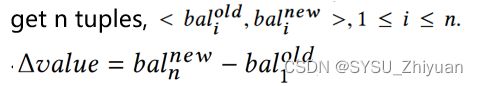
第二步 对比
对比分两种情况:
当调用标准方法时,对比是否 Bm ≠ Be, or Bm ≠ Br, or Br ≠ Be
当调用非标准方法时,对比是否 Br ≠ Be
Experiments
进行大规模的实验,涉及:
从以太坊发布(2015年7月30日)到2018年8月1日,共606,793个区块。
所有7,123,729个部署了智能合约,以及所有282,342,715个外部交易,119,245,201个发送到智能合约。
结果如图,约13%的 Token 是不一致的,后续验证其精度达到99%,只有一个 FP 还是由于硬编码导致的。
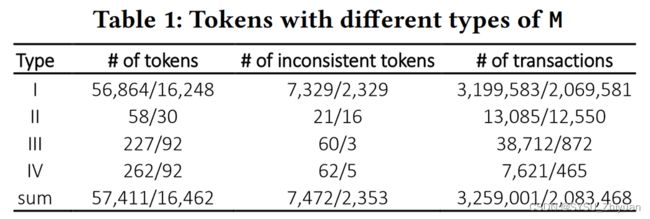
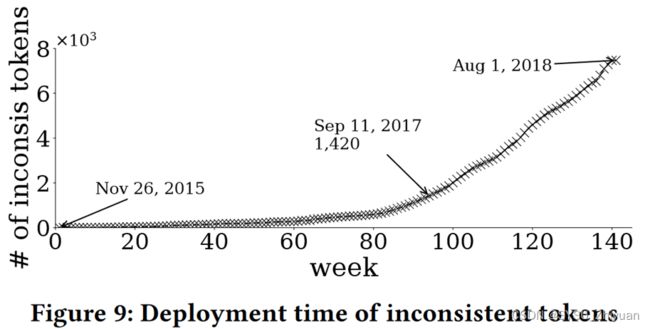
不一致 Token 合约随时间的增长变化,ERC-20 标准确立后仍有许多不一致的 Token 。
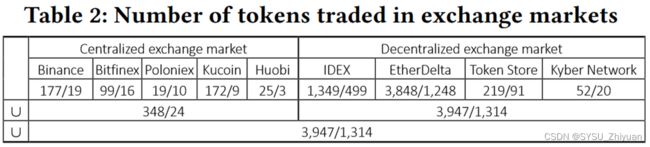
五个 CEX 和四个 DEX 中都存在着很多有不一致问题的 Token。
因此,不一致的 Token 可能导致严重的经济损失,因为许多不一致的 Token 在市场上进行交易。
Reasons of Inconsistent Behaviors
总结了共11种会导致不一致问题的原因。

Conclusion
1、提出了一种新的方法,并开发了一个名为 TokenScope 的新工具来自动检测 Token 不一致的行为。
2、应用 TokenScope 来检查发送到所有部署 Token 的所有交易,我们发现3259,001个交易触发了不一致的行为,7,472个不一致的 Token ,且精度非常高。
3、对所有开源不一致 Token 的调查揭示了不一致行为背后的11个主要原因。
PS:图片来自论文或我自己做的PPT,实验部分结果都在数据上,文字没有写太细(懒),有问题建议看原文。