cuda线程的索引index怎么算呢??
#include "cuda_runtime.h"
#include"device_launch_parameters.h"
#include> > (A, B, C);
return 0;
}
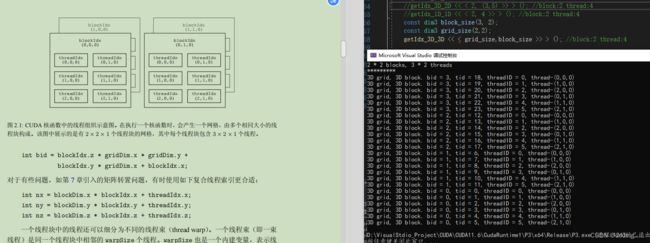
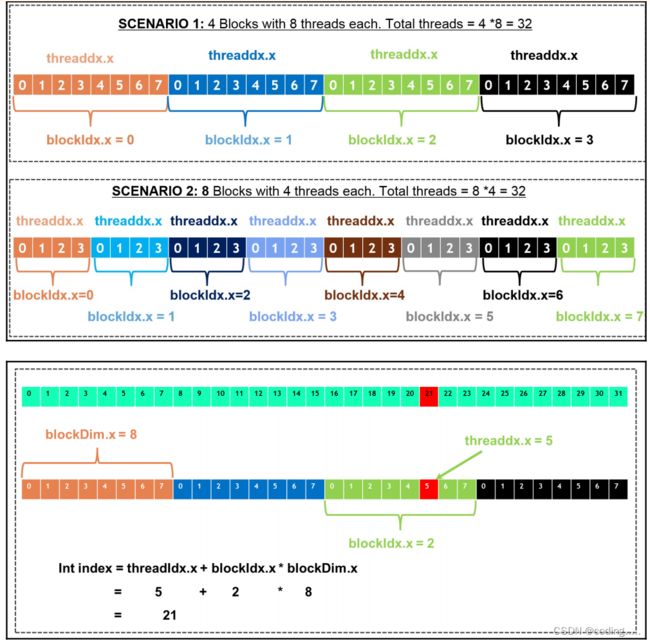
如果代码没错,tid全局索引好像是 线程索引threadID+块内的偏移??