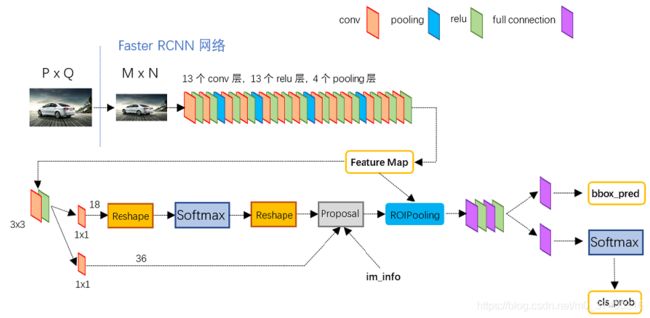
faster rcnn代码讲解
faster rcnn forward
def forward(self, imgs, bboxes, labels, scale):
"""Forward Faster R-CNN and calculate losses.
Here are notations used.
* :math:`N` is the batch size.
* :math:`R` is the number of bounding boxes per image.
Currently, only :math:`N=1` is supported.
Args:
imgs (~torch.autograd.Variable): A variable with a batch of images.
bboxes (~torch.autograd.Variable): A batch of bounding boxes.
Its shape is :math:`(N, R, 4)`.
labels (~torch.autograd..Variable): A batch of labels.
Its shape is :math:`(N, R)`. The background is excluded from
the definition, which means that the range of the value
is :math:`[0, L - 1]`. :math:`L` is the number of foreground
classes.
scale (float): Amount of scaling applied to
the raw image during preprocessing.
Returns:
namedtuple of 5 losses
"""
n = bboxes.shape[0]
if n != 1:
raise ValueError('Currently only batch size 1 is supported.')
_, _, H, W = imgs.shape
img_size = (H, W)
features = self.faster_rcnn.extractor(imgs)
# scale=scale.data.cpu().numpy()
rpn_locs, rpn_scores, rois, roi_indices, anchor = \
self.faster_rcnn.rpn(features, img_size, scale)
# Since batch size is one, convert variables to singular form
bbox = bboxes[0]
label = labels[0]
rpn_score = rpn_scores[0]
rpn_loc = rpn_locs[0]
roi = rois
#proposal_target_creator 通过对过滤后的box(20000-->2000)进一步与gt box进行iou计算
#通过阈值设置来设置对对应的pos neg box
#作用是用来输出roi信息并未进行Roi pooling准备。
sample_roi, gt_roi_loc, gt_roi_label = self.proposal_target_creator(
roi,
at.tonumpy(bbox),
at.tonumpy(label),
self.loc_normalize_mean,
self.loc_normalize_std)
# NOTE it's all zero because now it only support for batch=1 now
sample_roi_index = t.zeros(len(sample_roi))
#生成 roi pooling 后并fc后的score和loc
roi_cls_loc, roi_score = self.faster_rcnn.head(
features,
sample_roi,
sample_roi_index)
# ------------------ RPN losses -------------------#
#见下完anchor_target_creator介绍:
#gt_rpn_loc经过过滤和iou比较后的剩余box
#gt_rpn_label 与上述box对应的labe(0 1 -1)
gt_rpn_loc, gt_rpn_label = self.anchor_target_creator(
at.tonumpy(bbox),
anchor,
img_size)
gt_rpn_label = at.totensor(gt_rpn_label).long()
gt_rpn_loc = at.totensor(gt_rpn_loc)
rpn_loc_loss = _fast_rcnn_loc_loss(
rpn_loc,
gt_rpn_loc,
gt_rpn_label.data,
self.rpn_sigma)
# NOTE: default value of ignore_index is -100 ...
rpn_cls_loss = F.cross_entropy(rpn_score, gt_rpn_label.cuda(), ignore_index=-1)
# ------------------ ROI losses (fast rcnn loss) -------------------#
n_sample = roi_cls_loc.shape[0]
roi_cls_loc = roi_cls_loc.view(n_sample, -1, 4)
roi_loc = roi_cls_loc[t.arange(0, n_sample).long().cuda(), \
at.totensor(gt_roi_label).long()]
gt_roi_label = at.totensor(gt_roi_label).long()
gt_roi_loc = at.totensor(gt_roi_loc)
#通过proposal_target_creator后的gt roi与head后 的roi进行loss
roi_loc_loss = _fast_rcnn_loc_loss(
roi_loc.contiguous(),
gt_roi_loc,
gt_roi_label.data,
self.roi_sigma)
roi_cls_loss = nn.CrossEntropyLoss()(roi_score, gt_roi_label.cuda())
# self.roi_cm.add(at.totensor(roi_score, False), gt_roi_label.data.long())
losses = [rpn_loc_loss, rpn_cls_loss, roi_loc_loss, roi_cls_loss]
losses = losses + [sum(losses)]
return LossTuple(*losses)
**
anchor_target_creator
**
img_H, img_W = img_size
n_anchor = len(anchor)
inside_index = _get_inside_index(anchor, img_H, img_W)
anchor = anchor[inside_index]
argmax_ious, label = self._create_label(
inside_index, anchor, bbox)
# compute bounding box regression targets
loc = bbox2loc(anchor, bbox[argmax_ious])
# map up to original set of anchors
label = _unmap(label, n_anchor, inside_index, fill=-1) #无用的框label全部置-1
loc = _unmap(loc, n_anchor, inside_index, fill=0)##无用的框为【0,0,0,0】
return loc, label
_create_label
def _create_label(self, inside_index, anchor, bbox):
# label: 1 is positive, 0 is negative, -1 is dont care
label = np.empty((len(inside_index),), dtype=np.int32)#过滤后的box inside_index
label.fill(-1)
argmax_ious, max_ious, gt_argmax_ious = \
self._calc_ious(anchor, bbox, inside_index)
label[max_ious < self.neg_iou_thresh] = 0#iou小于预设的box label置0
label[gt_argmax_ious] = 1#与gt box接近box label置1
# positive label: above threshold IOU
label[max_ious >= self.pos_iou_thresh] = 1 #与gt box 大于预设box label置1
# subsample positive labels if we have too many
n_pos = int(self.pos_ratio * self.n_sample)
pos_index = np.where(label == 1)[0]
if len(pos_index) > n_pos:
disable_index = np.random.choice(
pos_index, size=(len(pos_index) - n_pos), replace=False)
label[disable_index] = -1 #控制postive box的数目 多余的为-1
# subsample negative labels if we have too many
n_neg = self.n_sample - np.sum(label == 1)
neg_index = np.where(label == 0)[0]
if len(neg_index) > n_neg:
disable_index = np.random.choice(
neg_index, size=(len(neg_index) - n_neg), replace=False)
label[disable_index] = -1 #控制negtive box的数目 多余的为-1
#此时,label存在三种box pos为1 neg为0 无用为-1
return argmax_ious, label
_calc_ious
def _calc_ious(self, anchor, bbox, inside_index):
# ious between the anchors and the gt boxes
ious = bbox_iou(anchor, bbox)
argmax_ious = ious.argmax(axis=1)
max_ious = ious[np.arange(len(inside_index)), argmax_ious]
gt_argmax_ious = ious.argmax(axis=0)
gt_max_ious = ious[gt_argmax_ious, np.arange(ious.shape[1])]
gt_argmax_ious = np.where(ious == gt_max_ious)[0]
#argmax_ious 过滤后的box与哪个gt最接近
#max_iou过滤后的box与之对应的iou值
#gt_argmax_ious每个gt可能包含多个box
return argmax_ious, max_ious, gt_argmax_ious
bbox2loc
def bbox2loc(src_bbox, dst_bbox):
"""Encodes the source and the destination bounding boxes to "loc".
Given bounding boxes, this function computes offsets and scales
to match the source bounding boxes to the target bounding boxes.
Mathematcially, given a bounding box whose center is
:math:`(y, x) = p_y, p_x` and
size :math:`p_h, p_w` and the target bounding box whose center is
:math:`g_y, g_x` and size :math:`g_h, g_w`, the offsets and scales
:math:`t_y, t_x, t_h, t_w` can be computed by the following formulas.
* :math:`t_y = \\frac{(g_y - p_y)} {p_h}`
* :math:`t_x = \\frac{(g_x - p_x)} {p_w}`
* :math:`t_h = \\log(\\frac{g_h} {p_h})`
* :math:`t_w = \\log(\\frac{g_w} {p_w})`
The output is same type as the type of the inputs.
The encoding formulas are used in works such as R-CNN [#]_.
.. [#] Ross Girshick, Jeff Donahue, Trevor Darrell, Jitendra Malik. \
Rich feature hierarchies for accurate object detection and semantic \
segmentation. CVPR 2014.
Args:
src_bbox (array): An image coordinate array whose shape is
:math:`(R, 4)`. :math:`R` is the number of bounding boxes.
These coordinates are
:math:`p_{ymin}, p_{xmin}, p_{ymax}, p_{xmax}`.
dst_bbox (array): An image coordinate array whose shape is
:math:`(R, 4)`.
These coordinates are
:math:`g_{ymin}, g_{xmin}, g_{ymax}, g_{xmax}`.
Returns:
array:
Bounding box offsets and scales from :obj:`src_bbox` \
to :obj:`dst_bbox`. \
This has shape :math:`(R, 4)`.
The second axis contains four values :math:`t_y, t_x, t_h, t_w`.
"""
height = src_bbox[:, 2] - src_bbox[:, 0]
width = src_bbox[:, 3] - src_bbox[:, 1]
ctr_y = src_bbox[:, 0] + 0.5 * height
ctr_x = src_bbox[:, 1] + 0.5 * width
base_height = dst_bbox[:, 2] - dst_bbox[:, 0]
base_width = dst_bbox[:, 3] - dst_bbox[:, 1]
base_ctr_y = dst_bbox[:, 0] + 0.5 * base_height
base_ctr_x = dst_bbox[:, 1] + 0.5 * base_width
eps = xp.finfo(height.dtype).eps
height = xp.maximum(height, eps)
width = xp.maximum(width, eps)
dy = (base_ctr_y - ctr_y) / height
dx = (base_ctr_x - ctr_x) / width
dh = xp.log(base_height / height)
dw = xp.log(base_width / width)
loc = xp.vstack((dy, dx, dh, dw)).transpose()
return loc
_fast_rcnn_loc_loss
def _smooth_l1_loss(x, t, in_weight, sigma):
sigma2 = sigma ** 2
diff = in_weight * (x - t)# 只有pos框,其它全为0
abs_diff = diff.abs()
flag = (abs_diff.data < (1. / sigma2)).float()
y = (flag * (sigma2 / 2.) * (diff ** 2) +
(1 - flag) * (abs_diff - 0.5 / sigma2))
return y.sum()
def _fast_rcnn_loc_loss(pred_loc, gt_loc, gt_label, sigma):
in_weight = t.zeros(gt_loc.shape).cuda()
in_weight[(gt_label > 0).view(-1, 1).expand_as(in_weight).cuda()] = 1
#gt_label 大于0的pos box,为1
loc_loss = _smooth_l1_loss(pred_loc, gt_loc, in_weight.detach(), sigma)
# Normalize by total number of negtive and positive rois.
loc_loss /= ((gt_label >= 0).sum().float()) # ignore gt_label==-1 for rpn_loss
#计算pos l1 loss,平均pos和neg。忽视-1的box
return loc_loss
self.faster_rcnn.rpn
n, _, hh, ww = x.shape
#_enumerate_shifted_anchor 构建box
anchor = _enumerate_shifted_anchor(
np.array(self.anchor_base),
self.feat_stride, hh, ww)
n_anchor = anchor.shape[0] // (hh * ww)
h = F.relu(self.conv1(x))
rpn_locs = self.loc(h)
# UNNOTE: check whether need contiguous
# A: Yes
rpn_locs = rpn_locs.permute(0, 2, 3, 1).contiguous().view(n, -1, 4)
rpn_scores = self.score(h)
rpn_scores = rpn_scores.permute(0, 2, 3, 1).contiguous()
rpn_softmax_scores = F.softmax(rpn_scores.view(n, hh, ww, n_anchor, 2), dim=4)
rpn_fg_scores = rpn_softmax_scores[:, :, :, :, 1].contiguous()
rpn_fg_scores = rpn_fg_scores.view( n, -1)
rpn_scores = rpn_scores.view(n, -1, 2)
rois = list()
roi_indices = list()
#proposal_layer 按大小比例等和nms box的softmax值等条件进行过滤box
#如原始20000 box---->6000 box
for i in range(n):
roi = self.proposal_layer(
rpn_locs[i].cpu().data.numpy(),
rpn_fg_scores[i].cpu().data.numpy(),
anchor, img_size,
scale=scale)
batch_index = i * np.ones((len(roi),), dtype=np.int32)
rois.append(roi)
roi_indices.append(batch_index)
rois = np.concatenate(rois, axis=0)
roi_indices = np.concatenate(roi_indices, axis=0)
return rpn_locs, rpn_scores, rois, roi_indices, anchor
self.proposal_layer
if self.parent_model.training:
n_pre_nms = self.n_train_pre_nms
n_post_nms = self.n_train_post_nms
else:
n_pre_nms = self.n_test_pre_nms
n_post_nms = self.n_test_post_nms
# Convert anchors into proposal via bbox transformations.
# roi = loc2bbox(anchor, loc)
roi = loc2bbox(anchor, loc)#yxyx
# Clip predicted boxes to image.
roi[:, slice(0, 4, 2)] = np.clip(
roi[:, slice(0, 4, 2)], 0, img_size[0])
roi[:, slice(1, 4, 2)] = np.clip(
roi[:, slice(1, 4, 2)], 0, img_size[1])
# Remove predicted boxes with either height or width < threshold.
min_size = self.min_size * scale
hs = roi[:, 2] - roi[:, 0]
ws = roi[:, 3] - roi[:, 1]
keep = np.where((hs >= min_size) & (ws >= min_size))[0]
roi = roi[keep, :]
score = score[keep]
# Sort all (proposal, score) pairs by score from highest to lowest.
# Take top pre_nms_topN (e.g. 6000).
order = score.ravel().argsort()[::-1]
if n_pre_nms > 0:
order = order[:n_pre_nms]
roi = roi[order, :]
score = score[order]
# Apply nms (e.g. threshold = 0.7).
# Take after_nms_topN (e.g. 300).
# unNOTE: somthing is wrong here!
# TODO: remove cuda.to_gpu
keep = nms(
torch.from_numpy(roi).cuda(),
torch.from_numpy(score).cuda(),
self.nms_thresh)
if n_post_nms > 0:
keep = keep[:n_post_nms]
roi = roi[keep.cpu().numpy()]
return roi
proposal_target_creator
n_bbox, _ = bbox.shape
roi = np.concatenate((roi, bbox), axis=0)
pos_roi_per_image = np.round(self.n_sample * self.pos_ratio)
iou = bbox_iou(roi, bbox)
gt_assignment = iou.argmax(axis=1)
max_iou = iou.max(axis=1)
# Offset range of classes from [0, n_fg_class - 1] to [1, n_fg_class].
# The label with value 0 is the background.
gt_roi_label = label[gt_assignment] + 1
# Select foreground RoIs as those with >= pos_iou_thresh IoU.
pos_index = np.where(max_iou >= self.pos_iou_thresh)[0]
pos_roi_per_this_image = int(min(pos_roi_per_image, pos_index.size))
if pos_index.size > 0:
pos_index = np.random.choice(
pos_index, size=pos_roi_per_this_image, replace=False)
# Select background RoIs as those within
# [neg_iou_thresh_lo, neg_iou_thresh_hi).
neg_index = np.where((max_iou < self.neg_iou_thresh_hi) &
(max_iou >= self.neg_iou_thresh_lo))[0]
neg_roi_per_this_image = self.n_sample - pos_roi_per_this_image
neg_roi_per_this_image = int(min(neg_roi_per_this_image,
neg_index.size))
if neg_index.size > 0:
neg_index = np.random.choice(
neg_index, size=neg_roi_per_this_image, replace=False)
# The indices that we're selecting (both positive and negative).
keep_index = np.append(pos_index, neg_index)
gt_roi_label = gt_roi_label[keep_index]
gt_roi_label[pos_roi_per_this_image:] = 0 # negative labels --> 0
sample_roi = roi[keep_index]
# Compute offsets and scales to match sampled RoIs to the GTs.
gt_roi_loc = bbox2loc(sample_roi, bbox[gt_assignment[keep_index]])
gt_roi_loc = ((gt_roi_loc - np.array(loc_normalize_mean, np.float32)
) / np.array(loc_normalize_std, np.float32))
return sample_roi, gt_roi_loc, gt_roi_label
参考代码
- https://github.com/chenyuntc/simple-faster-rcnn-pytorch.git