【超分辨率】【深度学习】SRGAN pytorch代码(附详细注释和数据集链接)
SRGAN
- 前言
- 1 数据集预处理
- 2 train.py
- 3 test_image.py
- 4 loss.py
- 5 model.py
- 6 data_utils.py
前言
主要改进部分:
断点恢复(参考train.py的75行)
注释部分代码(提高训练速度,参考train.py的182行)
VGG计算特征损失部分(参考Loss.py的注解)
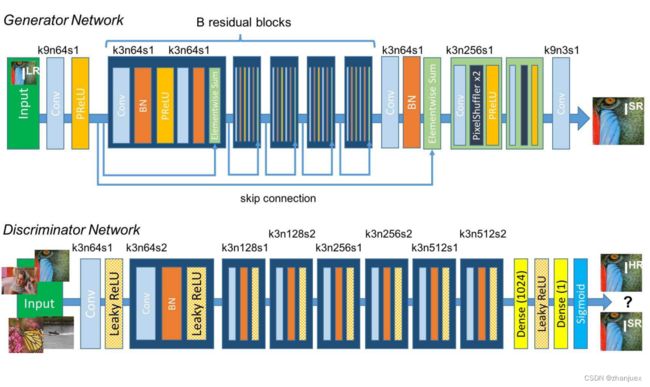
这里主要是对代码进行讲解,对SRGAN不了解的同学可以先去参考其他博文。
原论文链接:Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network
代码转自:https://github.com/leftthomas/SRGAN
对于新学深度学习代码的同学来说,推荐先阅读这一篇文章:
一个完整的Pytorch深度学习项目代码,项目结构是怎样的?
有问题联系:[email protected]
下面是这篇代码的步骤。(这里只介绍怎么训练图片)
1 数据集预处理
首先准备好数据集,这里以DIV2K_train_HR作为训练集,DIV2K_vaild_HR作为测试集。
数据集:
https://www.aliyundrive.com/s/rYWhA8G734y
2 train.py
运行之前记得配置好环境,修改完参数和文件路径后就可以直接运行了。
参数在18行
路径在36、37行
注释以提高速度在182行
import argparse
import os
from math import log10
import pandas as pd
import torch.optim as optim
import torch.utils.data
import torchvision.utils as utils
from torch.autograd import Variable
from torch.utils.data import DataLoader
from tqdm import tqdm
import pytorch_ssim
from data_utils import TrainDatasetFromFolder, ValDatasetFromFolder, display_transform
from loss import GeneratorLoss
from model import Generator, Discriminator
# 参数准备 非常重要
parser = argparse.ArgumentParser(description='Train Super Resolution Models')
# 裁剪大小
parser.add_argument('--crop_size', default=88, type=int, help='training images crop size')
# 放大倍数
parser.add_argument('--upscale_factor', default=4, type=int, choices=[2, 4, 8],
help='super resolution upscale factor')
# 训练轮数
parser.add_argument('--num_epochs', default=1, type=int, help='train epoch number')
if __name__ == '__main__':
opt = parser.parse_args()
CROP_SIZE = opt.crop_size
UPSCALE_FACTOR = opt.upscale_factor
NUM_EPOCHS = opt.num_epochs
# 需要修改以下两个路径
train_set = TrainDatasetFromFolder('data/DIV2K_train_HR', crop_size=CROP_SIZE, upscale_factor=UPSCALE_FACTOR)
val_set = ValDatasetFromFolder('data/DIV2K_valid_HR', upscale_factor=UPSCALE_FACTOR)
# 装载数据
train_loader = DataLoader(dataset=train_set, num_workers=4, batch_size=64, shuffle=True)
val_loader = DataLoader(dataset=val_set, num_workers=4, batch_size=1, shuffle=False)
# 初始化网络
netG = Generator(UPSCALE_FACTOR)
print('# generator parameters:', sum(param.numel() for param in netG.parameters()))
netD = Discriminator()
print('# discriminator parameters:', sum(param.numel() for param in netD.parameters()))
# 生成损失
generator_criterion = GeneratorLoss()
# GPU
if torch.cuda.is_available():
netG.cuda()
netD.cuda()
generator_criterion.cuda()
# 优化函数
optimizerG = optim.Adam(netG.parameters())
optimizerD = optim.Adam(netD.parameters())
# 结果
results = {'d_loss': [], 'g_loss': [], 'd_score': [], 'g_score': [], 'psnr': [], 'ssim': []}
# 开始训练
for epoch in range(1, NUM_EPOCHS + 1):
# 恢复训练 设置开始的轮数
# for epoch in range(?, NUM_EPOCHS + 1):
train_bar = tqdm(train_loader)
running_results = {'batch_sizes': 0, 'd_loss': 0, 'g_loss': 0, 'd_score': 0, 'g_score': 0}
# 恢复训练 加载之前的权重
# netG.load_state_dict(torch.load('netG_epoch_4_75.pth'))
# netD.load_state_dict(torch.load('netD_epoch_4_75.pth'))
# 训练模式
netG.train()
netD.train()
# 训练细节
for data, target in train_bar:
# 这个不太懂,知道的可以评论一下
g_update_first = True
batch_size = data.size(0)
running_results['batch_sizes'] += batch_size
############################
# (1) Update D network: maximize D(x)-1-D(G(z))
# 最大化判别器判别原图(HR)概率,最小化生成图(SR)判别概率
###########################
# HR
real_img = Variable(target)
if torch.cuda.is_available():
real_img = real_img.cuda()
# LR
z = Variable(data)
if torch.cuda.is_available():
z = z.cuda()
# SR
fake_img = netG(z)
#梯度清零
netD.zero_grad()
# 反向传播过程
real_out = netD(real_img).mean()
fake_out = netD(fake_img).mean()
# 损失函数
d_loss = 1 - real_out + fake_out
# 反向传播
d_loss.backward(retain_graph=True)
# 参数更新
optimizerD.step()
############################
# (2) Update G network: minimize 1-D(G(z)) + Perception Loss + Image Loss + TV Loss
# 最小化生成网络中SR被认出概率、感知损失(VGG计算)、图像损失(MSE)、平滑损失
###########################
# 梯度清零
netG.zero_grad()
## The two lines below are added to prevent runetime error in Google Colab ##
fake_img = netG(z)
fake_out = netD(fake_img).mean()
## 计算损失及反向传播
g_loss = generator_criterion(fake_out, fake_img, real_img)
g_loss.backward()
fake_img = netG(z)
fake_out = netD(fake_img).mean()
optimizerG.step()
# loss for current batch before optimization
running_results['g_loss'] += g_loss.item() * batch_size
running_results['d_loss'] += d_loss.item() * batch_size
running_results['d_score'] += real_out.item() * batch_size
running_results['g_score'] += fake_out.item() * batch_size
train_bar.set_description(desc='[%d/%d] Loss_D: %.4f Loss_G: %.4f D(x): %.4f D(G(z)): %.4f' % (
epoch, NUM_EPOCHS, running_results['d_loss'] / running_results['batch_sizes'],
running_results['g_loss'] / running_results['batch_sizes'],
running_results['d_score'] / running_results['batch_sizes'],
running_results['g_score'] / running_results['batch_sizes']))
# 测试模式,无需更新网络。
netG.eval()
# 模型保存
out_path = 'training_results/SRF_' + str(UPSCALE_FACTOR) + '/'
if not os.path.exists(out_path):
os.makedirs(out_path)
# 参数计算
with torch.no_grad():
val_bar = tqdm(val_loader)
valing_results = {'mse': 0, 'ssims': 0, 'psnr': 0, 'ssim': 0, 'batch_sizes': 0}
val_images = []
for val_lr, val_hr_restore, val_hr in val_bar:
batch_size = val_lr.size(0)
valing_results['batch_sizes'] += batch_size
lr = val_lr
hr = val_hr
if torch.cuda.is_available():
lr = lr.cuda()
hr = hr.cuda()
sr = netG(lr)
batch_mse = ((sr - hr) ** 2).data.mean()
valing_results['mse'] += batch_mse * batch_size
batch_ssim = pytorch_ssim.ssim(sr, hr).item()
valing_results['ssims'] += batch_ssim * batch_size
valing_results['psnr'] = 10 * log10((hr.max()**2) / (valing_results['mse'] / valing_results['batch_sizes']))
valing_results['ssim'] = valing_results['ssims'] / valing_results['batch_sizes']
val_bar.set_description(
desc='[converting LR images to SR images] PSNR: %.4f dB SSIM: %.4f' % (
valing_results['psnr'], valing_results['ssim']))
# 拼接三张图片 如果想提高训练速度 下面到 index += 1 可以注释
val_images.extend(
[display_transform()(val_hr_restore.squeeze(0)), display_transform()(hr.data.cpu().squeeze(0)),
display_transform()(sr.data.cpu().squeeze(0))])
val_images = torch.stack(val_images)
val_images = torch.chunk(val_images, val_images.size(0) // 15)
val_save_bar = tqdm(val_images, desc='[saving training results]')
index = 1
for image in val_save_bar:
image = utils.make_grid(image, nrow=3, padding=5)
utils.save_image(image, out_path + 'epoch_%d_index_%d.png' % (epoch, index), padding=5)
index += 1
# save model parameters
torch.save(netG.state_dict(), 'epochs/netG_epoch_%d_%d.pth' % (UPSCALE_FACTOR, epoch))
torch.save(netD.state_dict(), 'epochs/netD_epoch_%d_%d.pth' % (UPSCALE_FACTOR, epoch))
# save loss\scores\psnr\ssim
results['d_loss'].append(running_results['d_loss'] / running_results['batch_sizes'])
results['g_loss'].append(running_results['g_loss'] / running_results['batch_sizes'])
results['d_score'].append(running_results['d_score'] / running_results['batch_sizes'])
results['g_score'].append(running_results['g_score'] / running_results['batch_sizes'])
results['psnr'].append(valing_results['psnr'])
results['ssim'].append(valing_results['ssim'])
# 10轮保存一次
if epoch % 10 == 0 and epoch != 0:
out_path = 'statistics/'
data_frame = pd.DataFrame(
data={'Loss_D': results['d_loss'], 'Loss_G': results['g_loss'], 'Score_D': results['d_score'],
'Score_G': results['g_score'], 'PSNR': results['psnr'], 'SSIM': results['ssim']},
index=range(1, epoch + 1))
data_frame.to_csv(out_path + 'srf_' + str(UPSCALE_FACTOR) + '_train_results.csv', index_label='Epoch')
3 test_image.py
直接输入图片即可进行测试。
4 loss.py
可以改成VGG19
import torch
from torch import nn
# 可以改成VGG19
from torchvision.models.vgg import vgg16
class GeneratorLoss(nn.Module):
def __init__(self):
super(GeneratorLoss, self).__init__()
# 若改成VGG19这里也要改
vgg = vgg16(pretrained=True)
# 用VGG前31层(相当于全部)计算,跟论文有关,具体可以自己数
# 具体参考 blog.csdn.net/zml194849/article/details/112790683
# 其中的卷积层要x2,因为包括激活函数层。之后数出来32层(到第一个全连接层)
loss_network = nn.Sequential(*list(vgg.features)[:31]).eval()
for param in loss_network.parameters():
param.requires_grad = False
self.loss_network = loss_network
self.mse_loss = nn.MSELoss()
self.tv_loss = TVLoss()
def forward(self, out_labels, out_images, target_images):
# Adversarial Loss
adversarial_loss = torch.mean(1 - out_labels)
# Perception Loss
perception_loss = self.mse_loss(self.loss_network(out_images), self.loss_network(target_images))
# Image Loss
image_loss = self.mse_loss(out_images, target_images)
# TV Loss
tv_loss = self.tv_loss(out_images)
return image_loss + 0.001 * adversarial_loss + 0.006 * perception_loss + 2e-8 * tv_loss
class TVLoss(nn.Module):
def __init__(self, tv_loss_weight=1):
super(TVLoss, self).__init__()
self.tv_loss_weight = tv_loss_weight
def forward(self, x):
batch_size = x.size()[0]
h_x = x.size()[2]
w_x = x.size()[3]
count_h = self.tensor_size(x[:, :, 1:, :])
count_w = self.tensor_size(x[:, :, :, 1:])
h_tv = torch.pow((x[:, :, 1:, :] - x[:, :, :h_x - 1, :]), 2).sum()
w_tv = torch.pow((x[:, :, :, 1:] - x[:, :, :, :w_x - 1]), 2).sum()
return self.tv_loss_weight * 2 * (h_tv / count_h + w_tv / count_w) / batch_size
@staticmethod
def tensor_size(t):
return t.size()[1] * t.size()[2] * t.size()[3]
if __name__ == "__main__":
g_loss = GeneratorLoss()
print(g_loss)
5 model.py
import math
import torch
from torch import nn
# 生成器
class Generator(nn.Module):
def __init__(self, scale_factor):
# 上采样块数,8倍就有3个
upsample_block_num = int(math.log(scale_factor, 2))
super(Generator, self).__init__()
# 连接卷积层和激活函数层
self.block1 = nn.Sequential(
# 3个通道,64个卷积核,卷积大小为9,需要扩充
nn.Conv2d(3, 64, kernel_size=9, padding=4),
nn.PReLU()
)
# 残差层
self.block2 = ResidualBlock(64)
self.block3 = ResidualBlock(64)
self.block4 = ResidualBlock(64)
self.block5 = ResidualBlock(64)
self.block6 = ResidualBlock(64)
self.block7 = nn.Sequential(
nn.Conv2d(64, 64, kernel_size=3, padding=1),
# BN层
nn.BatchNorm2d(64)
)
# 上采样层
block8 = [UpsampleBLock(64, 2) for _ in range(upsample_block_num)]
block8.append(nn.Conv2d(64, 3, kernel_size=9, padding=4))
self.block8 = nn.Sequential(*block8)
def forward(self, x):
block1 = self.block1(x)
block2 = self.block2(block1)
block3 = self.block3(block2)
block4 = self.block4(block3)
block5 = self.block5(block4)
block6 = self.block6(block5)
block7 = self.block7(block6)
block8 = self.block8(block1 + block7)
return (torch.tanh(block8) + 1) / 2
# 判别器,较为简单,VGG在计算损失时使用,这里没有。
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.net = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=3, padding=1),
nn.LeakyReLU(0.2),
nn.Conv2d(64, 64, kernel_size=3, stride=2, padding=1),
nn.BatchNorm2d(64),
nn.LeakyReLU(0.2),
nn.Conv2d(64, 128, kernel_size=3, padding=1),
nn.BatchNorm2d(128),
nn.LeakyReLU(0.2),
nn.Conv2d(128, 128, kernel_size=3, stride=2, padding=1),
nn.BatchNorm2d(128),
nn.LeakyReLU(0.2),
nn.Conv2d(128, 256, kernel_size=3, padding=1),
nn.BatchNorm2d(256),
nn.LeakyReLU(0.2),
nn.Conv2d(256, 256, kernel_size=3, stride=2, padding=1),
nn.BatchNorm2d(256),
nn.LeakyReLU(0.2),
nn.Conv2d(256, 512, kernel_size=3, padding=1),
nn.BatchNorm2d(512),
nn.LeakyReLU(0.2),
nn.Conv2d(512, 512, kernel_size=3, stride=2, padding=1),
nn.BatchNorm2d(512),
nn.LeakyReLU(0.2),
nn.AdaptiveAvgPool2d(1),
nn.Conv2d(512, 1024, kernel_size=1),
nn.LeakyReLU(0.2),
nn.Conv2d(1024, 1, kernel_size=1)
)
def forward(self, x):
batch_size = x.size(0)
return torch.sigmoid(self.net(x).view(batch_size))
# 残差块
class ResidualBlock(nn.Module):
def __init__(self, channels):
super(ResidualBlock, self).__init__()
self.conv1 = nn.Conv2d(channels, channels, kernel_size=3, padding=1)
self.bn1 = nn.BatchNorm2d(channels)
self.prelu = nn.PReLU()
self.conv2 = nn.Conv2d(channels, channels, kernel_size=3, padding=1)
self.bn2 = nn.BatchNorm2d(channels)
def forward(self, x):
residual = self.conv1(x)
residual = self.bn1(residual)
residual = self.prelu(residual)
residual = self.conv2(residual)
residual = self.bn2(residual)
return x + residual
# 用pixelShuffle进行上采样,详情参考ESPCN
class UpsampleBLock(nn.Module):
def __init__(self, in_channels, up_scale):
super(UpsampleBLock, self).__init__()
self.conv = nn.Conv2d(in_channels, in_channels * up_scale ** 2, kernel_size=3, padding=1)
self.pixel_shuffle = nn.PixelShuffle(up_scale)
self.prelu = nn.PReLU()
def forward(self, x):
x = self.conv(x)
x = self.pixel_shuffle(x)
x = self.prelu(x)
return x
6 data_utils.py
from os import listdir
from os.path import join
from PIL import Image
from torch.utils.data.dataset import Dataset
from torchvision.transforms import Compose, RandomCrop, ToTensor, ToPILImage, CenterCrop, Resize
def is_image_file(filename):
# 判断文件后缀
return any(filename.endswith(extension) for extension in ['.png', '.jpg', '.jpeg', '.PNG', '.JPG', '.JPEG'])
def calculate_valid_crop_size(crop_size, upscale_factor):
# 有效裁剪片段
return crop_size - (crop_size % upscale_factor)
def train_hr_transform(crop_size):
# Compose 组合多个操作 下同
return Compose([
# 随机裁剪
RandomCrop(crop_size),
# 变为张量
ToTensor(),
])
def train_lr_transform(crop_size, upscale_factor):
return Compose([
# 变为图片
ToPILImage(),
# 整除下采样
Resize(crop_size // upscale_factor, interpolation=Image.BICUBIC),
ToTensor()
])
def display_transform():
return Compose([
ToPILImage(),
Resize(400),
CenterCrop(400),
ToTensor()
])
class TrainDatasetFromFolder(Dataset):
def __init__(self, dataset_dir, crop_size, upscale_factor):
super(TrainDatasetFromFolder, self).__init__()
# 获取图片
self.image_filenames = [join(dataset_dir, x) for x in listdir(dataset_dir) if is_image_file(x)]
# 有效裁剪尺寸
crop_size = calculate_valid_crop_size(crop_size, upscale_factor)
# 随机裁剪原图像
self.hr_transform = train_hr_transform(crop_size)
# 将裁剪好的图像处理成低分辨率的图片
self.lr_transform = train_lr_transform(crop_size, upscale_factor)
def __getitem__(self, index):
hr_image = self.hr_transform(Image.open(self.image_filenames[index]))
lr_image = self.lr_transform(hr_image)
return lr_image, hr_image
def __len__(self):
return len(self.image_filenames)
class ValDatasetFromFolder(Dataset):
def __init__(self, dataset_dir, upscale_factor):
super(ValDatasetFromFolder, self).__init__()
self.upscale_factor = upscale_factor
# 获取图片
self.image_filenames = [join(dataset_dir, x) for x in listdir(dataset_dir) if is_image_file(x)]
def __getitem__(self, index):
# 打开图片
hr_image = Image.open(self.image_filenames[index])
# 获取长宽并进行有效裁剪
w, h = hr_image.size
crop_size = calculate_valid_crop_size(min(w, h), self.upscale_factor)
# 缩小函数
lr_scale = Resize(crop_size // self.upscale_factor, interpolation=Image.BICUBIC)
# 放大函数
hr_scale = Resize(crop_size, interpolation=Image.BICUBIC)
hr_image = CenterCrop(crop_size)(hr_image)
# 双三次插值缩小后放大
lr_image = lr_scale(hr_image)
hr_restore_img = hr_scale(lr_image)
return ToTensor()(lr_image), ToTensor()(hr_restore_img), ToTensor()(hr_image)
def __len__(self):
return len(self.image_filenames)
class TestDatasetFromFolder(Dataset):
def __init__(self, dataset_dir, upscale_factor):
super(TestDatasetFromFolder, self).__init__()
self.lr_path = dataset_dir + '/SRF_' + str(upscale_factor) + '/data/'
self.hr_path = dataset_dir + '/SRF_' + str(upscale_factor) + '/target/'
self.upscale_factor = upscale_factor
self.lr_filenames = [join(self.lr_path, x) for x in listdir(self.lr_path) if is_image_file(x)]
self.hr_filenames = [join(self.hr_path, x) for x in listdir(self.hr_path) if is_image_file(x)]
def __getitem__(self, index):
image_name = self.lr_filenames[index].split('/')[-1]
lr_image = Image.open(self.lr_filenames[index])
w, h = lr_image.size
hr_image = Image.open(self.hr_filenames[index])
hr_scale = Resize((self.upscale_factor * h, self.upscale_factor * w), interpolation=Image.BICUBIC)
hr_restore_img = hr_scale(lr_image)
return image_name, ToTensor()(lr_image), ToTensor()(hr_restore_img), ToTensor()(hr_image)
def __len__(self):
return len(self.lr_filenames)