ENet
论文下载地址:论文下载地址请点击即可下载
ENet
Abstract
- 面对的问题:深度神经网络需要大量的浮点运算,会影响实时性(FCN,SEGNET)。
- 解决办法:ENet,其专门为低延时设计的,ENet比现存方法最高快18倍,少用了75倍的浮点运算,少了79倍的参数,精度又与现存方法相差无几。
- 在CamVid,Cityscapes,SUN数据集上与当前全新的方法作了比较,并对一个网络在时间和精度上做了权衡。
introduction
- 背景:自动驾驶等应用在移动设备上实时运作的低功耗语义分割(或视觉场景理解)产生了大量的需求。
- 问题:FCN与SEGNET等均是基于VGG,利用粗糙的spatial结果去refine最后结果,但他们均含有大量的参数与推理时间,而实时性的要求是能处理10fps以上的图片。
- 解决办法:Enet有更快的推理能力与很高的精度。

relate work
目前主流的神经网络结构都由两部分组成:
- 编码器和解码器:比如segnet网络结构复杂、参数众多,推理过程比较慢(仍然有全连接过程,编码器对输入像VGG一样对其分类,而解码器是对编码器的输出做上采样)。FCN抛弃了最后的全连接层,但是其仍然无法满足实时分割(the number of floating point operations and memory footprint)
- 另外一种结构:使用更简单的分类器,然后用CRF作为后处理。但是它很可能不会标记占有像素很少的类别。
network architecture
该网络架构如下表所示:

上面的输入图像尺寸是512*512,从上图中我们知道网络结构可以分成几个阶段。
bottleneck
这里采用了ResNets的概念,从一个主干里面分出了一支卷积滤波器,再以元素相加的形式融合回主干。
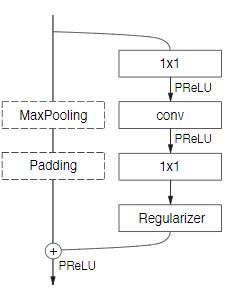
该模块包括三层卷积层:一个1x1映射用于降维,一个主卷积层,和一个1x1的扩张。并且在所有的卷积层后面都使用了Batch Normalization和PReLU。我们叫这个模块为bottleneck模块。如果bottleneck是下采样,那么主干上会加一个max pooling层。同时,第一个1x1的映射用各维度步长均为2的2x2卷积替代。conv可以是普通卷积、空洞卷积或全卷积(也称为反卷积)中的任何一种,滤波器尺寸为3x3(下采样时为3*3)。有时候也会用对称卷积替代,即连续的5x1和1x5卷积。
initial state
初始化阶段包含一个单独的block,如下图所示:

第一个阶段有5个bottleneck块,第二个阶段和第三个阶段相同,但是第三个阶段没有下采样,前三个阶段是编码部分,第四和第五个阶段是解码部分。
注意:文章取消了偏置项却不会降低精度,最后一个上采样使用的是反卷积而不是反池化(因为输入是3通道的,输出应该是类别数那么多的通道,使用反池化只能改变尺寸不能改变通道数,而反卷积可以)
E-Net的思想:
- FCN、Segnet:采用的是segnet思想(采用最大索引上采样,fcn是将编码阶段的特征图与上采样阶段的特征图融合,,而segnet只是存储索引)节约参数;
- 扩张卷积:为了增加上下文学习,还采用了空洞卷积扩大感受野;
- earlying-downsampling:E-Net模型会在初始化阶段大大减少图片尺寸(前期过大分辨率降低并不会对图片有什么改变,比如一张8M大小的图片将其分辨率将为1M后我们仍然可以清楚的看到图像),得益于视觉信息在空间上是高度冗余的;
- decoder-size:segnet是一个对称的结构,而Enet不是对称的,是由一个较大的编码器与较小的解码器组成。作者认为解码器的作用是还原尺寸,对模型只有微调的作用,不必需要大量参数;
- nonlinear-operations:受resnet v2的影响,认为在卷积层前面添加BR与ReLu的效果会更好,但是作者实验发现这种方式却降低了实验精度。ReLu没有起作用的原因是因为网络的深度,Resnet的网络深,而Enet的网络比较浅,较少的层需要快速的过滤信息,故最终使用的是PReLus;
- information-preserving dimensionality changes:将池化操作与卷积操作并行再concat到一起,会将推理阶段的时间加速10倍,同时在下采样时,使用2*2的卷积核,有效的改善了信息的流动和准确率;
- factorizing filters:将nn的卷积核拆成n1与1*n的会减少参数量;
- dilated convolutions:空洞卷积可以提高感受野,其提高了4%的Iou值,空洞卷积是交叉使用的,不是连续使用的;
实验设置

实验结果
推理时间:

- 从上表中我们可以看到,ENet的处理速度明显更快;
- 使用不同的设备,其处理速度是不一样的。
参数及运算量比较:
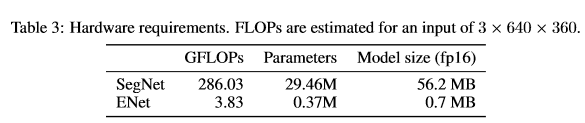
ENet的参数相比之下更少。
实现pytorch代码
import torch.nn as nn
import torch
class InitialBlock(nn.Module):
def __init__(self,
in_channels,
out_channels,
bias=False,
relu=True):
super().__init__()
if relu:
activation = nn.ReLU
else:
activation = nn.PReLU
self.main_branch = nn.Conv2d(
in_channels,
out_channels - 3,
kernel_size=3,
stride=2,
padding=1,
bias=bias)
# Extension branch
self.ext_branch = nn.MaxPool2d(3, stride=2, padding=1)
# Initialize batch normalization to be used after concatenation
self.batch_norm = nn.BatchNorm2d(out_channels)
# PReLU layer to apply after concatenating the branches
self.out_activation = activation()
def forward(self, x):
main = self.main_branch(x)
ext = self.ext_branch(x)
# Concatenate branches
out = torch.cat((main, ext), 1)
# Apply batch normalization
out = self.batch_norm(out)
return self.out_activation(out)
class RegularBottleneck(nn.Module):
def __init__(self,
channels,
internal_ratio=4,
kernel_size=3,
padding=0,
dilation=1,
asymmetric=False,
dropout_prob=0,
bias=False,
relu=True):
super().__init__()
internal_channels = channels // internal_ratio
if relu:
activation = nn.ReLU
else:
activation = nn.PReLU
# 1x1 projection convolution
self.ext_conv1 = nn.Sequential(
nn.Conv2d(
channels,
internal_channels,
kernel_size=1,
stride=1,
bias=bias), nn.BatchNorm2d(internal_channels), activation())
if asymmetric:
self.ext_conv2 = nn.Sequential(
nn.Conv2d(
internal_channels,
internal_channels,
kernel_size=(kernel_size, 1),
stride=1,
padding=(padding, 0),
dilation=dilation,
bias=bias), nn.BatchNorm2d(internal_channels), activation(),
nn.Conv2d(
internal_channels,
internal_channels,
kernel_size=(1, kernel_size),
stride=1,
padding=(0, padding),
dilation=dilation,
bias=bias), nn.BatchNorm2d(internal_channels), activation())
else:
self.ext_conv2 = nn.Sequential(
nn.Conv2d(
internal_channels,
internal_channels,
kernel_size=kernel_size,
stride=1,
padding=padding,
dilation=dilation,
bias=bias), nn.BatchNorm2d(internal_channels), activation())
# 1x1 expansion convolution
self.ext_conv3 = nn.Sequential(
nn.Conv2d(
internal_channels,
channels,
kernel_size=1,
stride=1,
bias=bias), nn.BatchNorm2d(channels), activation())
self.ext_regul = nn.Dropout2d(p=dropout_prob)
# PReLU layer to apply after adding the branches
self.out_activation = activation()
def forward(self, x):
# Main branch shortcut
main = x
# Extension branch
ext = self.ext_conv1(x)
ext = self.ext_conv2(ext)
ext = self.ext_conv3(ext)
ext = self.ext_regul(ext)
# Add main and extension branches
out = main + ext
return self.out_activation(out)
class DownsamplingBottleneck(nn.Module):
def __init__(self,
in_channels,
out_channels,
internal_ratio=4,
return_indices=False,
dropout_prob=0,
bias=False,
relu=True):
super().__init__()
# Store parameters that are needed later
self.return_indices = return_indices
internal_channels = in_channels // internal_ratio
if relu:
activation = nn.ReLU
else:
activation = nn.PReLU
# Main branch - max pooling followed by feature map (channels) padding
self.main_max1 = nn.MaxPool2d(
2,
stride=2,
return_indices=return_indices)
# 2x2 projection convolution with stride 2
self.ext_conv1 = nn.Sequential(
nn.Conv2d(
in_channels,
internal_channels,
kernel_size=2,
stride=2,
bias=bias), nn.BatchNorm2d(internal_channels), activation())
# Convolution
self.ext_conv2 = nn.Sequential(
nn.Conv2d(
internal_channels,
internal_channels,
kernel_size=3,
stride=1,
padding=1,
bias=bias), nn.BatchNorm2d(internal_channels), activation())
# 1x1 expansion convolution
self.ext_conv3 = nn.Sequential(
nn.Conv2d(
internal_channels,
out_channels,
kernel_size=1,
stride=1,
bias=bias), nn.BatchNorm2d(out_channels), activation())
self.ext_regul = nn.Dropout2d(p=dropout_prob)
# PReLU layer to apply after concatenating the branches
self.out_activation = activation()
def forward(self, x):
# Main branch shortcut
if self.return_indices:
main, max_indices = self.main_max1(x)
else:
main = self.main_max1(x)
# Extension branch
ext = self.ext_conv1(x)
ext = self.ext_conv2(ext)
ext = self.ext_conv3(ext)
ext = self.ext_regul(ext)
# Main branch channel padding
n, ch_ext, h, w = ext.size()
ch_main = main.size()[1]
padding = torch.zeros(n, ch_ext - ch_main, h, w)
# Before concatenating, check if main is on the CPU or GPU and
# convert padding accordingly
if main.is_cuda:
padding = padding.cuda()
# Concatenate
main = torch.cat((main, padding), 1)
# Add main and extension branches
out = main + ext
return self.out_activation(out), max_indices
class UpsamplingBottleneck(nn.Module):
def __init__(self,
in_channels,
out_channels,
internal_ratio=4,
dropout_prob=0,
bias=False,
relu=True):
super().__init__()
internal_channels = in_channels // internal_ratio
if relu:
activation = nn.ReLU
else:
activation = nn.PReLU
# Main branch - max pooling followed by feature map (channels) padding
self.main_conv1 = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=1, bias=bias),
nn.BatchNorm2d(out_channels))
# Remember that the stride is the same as the kernel_size, just like
# the max pooling layers
self.main_unpool1 = nn.MaxUnpool2d(kernel_size=2)
# 1x1 projection convolution with stride 1
self.ext_conv1 = nn.Sequential(
nn.Conv2d(
in_channels, internal_channels, kernel_size=1, bias=bias),
nn.BatchNorm2d(internal_channels), activation())
# Transposed convolution
self.ext_tconv1 = nn.ConvTranspose2d(
internal_channels,
internal_channels,
kernel_size=2,
stride=2,
bias=bias)
self.ext_tconv1_bnorm = nn.BatchNorm2d(internal_channels)
self.ext_tconv1_activation = activation()
# 1x1 expansion convolution
self.ext_conv2 = nn.Sequential(
nn.Conv2d(
internal_channels, out_channels, kernel_size=1, bias=bias),
nn.BatchNorm2d(out_channels), activation())
self.ext_regul = nn.Dropout2d(p=dropout_prob)
# PReLU layer to apply after concatenating the branches
self.out_activation = activation()
def forward(self, x, max_indices, output_size):
# Main branch shortcut
main = self.main_conv1(x)
main = self.main_unpool1(
main, max_indices, output_size=output_size)
# Extension branch
ext = self.ext_conv1(x)
ext = self.ext_tconv1(ext, output_size=output_size)
ext = self.ext_tconv1_bnorm(ext)
ext = self.ext_tconv1_activation(ext)
ext = self.ext_conv2(ext)
ext = self.ext_regul(ext)
# Add main and extension branches
out = main + ext
return self.out_activation(out)
class ENet(nn.Module):
def __init__(self, n_classes, encoder_relu=False, decoder_relu=True):
super().__init__()
self.initial_block = InitialBlock(3, 16, relu=encoder_relu)
# Stage 1 - Encoder
self.downsample1_0 = DownsamplingBottleneck(
16,
64,
return_indices=True,
dropout_prob=0.01,
relu=encoder_relu)
self.regular1_1 = RegularBottleneck(
64, padding=1, dropout_prob=0.01, relu=encoder_relu)
self.regular1_2 = RegularBottleneck(
64, padding=1, dropout_prob=0.01, relu=encoder_relu)
self.regular1_3 = RegularBottleneck(
64, padding=1, dropout_prob=0.01, relu=encoder_relu)
self.regular1_4 = RegularBottleneck(
64, padding=1, dropout_prob=0.01, relu=encoder_relu)
# Stage 2 - Encoder
self.downsample2_0 = DownsamplingBottleneck(
64,
128,
return_indices=True,
dropout_prob=0.1,
relu=encoder_relu)
self.regular2_1 = RegularBottleneck(
128, padding=1, dropout_prob=0.1, relu=encoder_relu)
self.dilated2_2 = RegularBottleneck(
128, dilation=2, padding=2, dropout_prob=0.1, relu=encoder_relu)
self.asymmetric2_3 = RegularBottleneck(
128,
kernel_size=5,
padding=2,
asymmetric=True,
dropout_prob=0.1,
relu=encoder_relu)
self.dilated2_4 = RegularBottleneck(
128, dilation=4, padding=4, dropout_prob=0.1, relu=encoder_relu)
self.regular2_5 = RegularBottleneck(
128, padding=1, dropout_prob=0.1, relu=encoder_relu)
self.dilated2_6 = RegularBottleneck(
128, dilation=8, padding=8, dropout_prob=0.1, relu=encoder_relu)
self.asymmetric2_7 = RegularBottleneck(
128,
kernel_size=5,
asymmetric=True,
padding=2,
dropout_prob=0.1,
relu=encoder_relu)
self.dilated2_8 = RegularBottleneck(
128, dilation=16, padding=16, dropout_prob=0.1, relu=encoder_relu)
# Stage 3 - Encoder
self.regular3_0 = RegularBottleneck(
128, padding=1, dropout_prob=0.1, relu=encoder_relu)
self.dilated3_1 = RegularBottleneck(
128, dilation=2, padding=2, dropout_prob=0.1, relu=encoder_relu)
self.asymmetric3_2 = RegularBottleneck(
128,
kernel_size=5,
padding=2,
asymmetric=True,
dropout_prob=0.1,
relu=encoder_relu)
self.dilated3_3 = RegularBottleneck(
128, dilation=4, padding=4, dropout_prob=0.1, relu=encoder_relu)
self.regular3_4 = RegularBottleneck(
128, padding=1, dropout_prob=0.1, relu=encoder_relu)
self.dilated3_5 = RegularBottleneck(
128, dilation=8, padding=8, dropout_prob=0.1, relu=encoder_relu)
self.asymmetric3_6 = RegularBottleneck(
128,
kernel_size=5,
asymmetric=True,
padding=2,
dropout_prob=0.1,
relu=encoder_relu)
self.dilated3_7 = RegularBottleneck(
128, dilation=16, padding=16, dropout_prob=0.1, relu=encoder_relu)
# Stage 4 - Decoder
self.upsample4_0 = UpsamplingBottleneck(
128, 64, dropout_prob=0.1, relu=decoder_relu)
self.regular4_1 = RegularBottleneck(
64, padding=1, dropout_prob=0.1, relu=decoder_relu)
self.regular4_2 = RegularBottleneck(
64, padding=1, dropout_prob=0.1, relu=decoder_relu)
# Stage 5 - Decoder
self.upsample5_0 = UpsamplingBottleneck(
64, 16, dropout_prob=0.1, relu=decoder_relu)
self.regular5_1 = RegularBottleneck(
16, padding=1, dropout_prob=0.1, relu=decoder_relu)
self.transposed_conv = nn.ConvTranspose2d(
16,
n_classes,
kernel_size=3,
stride=2,
padding=1,
bias=False)
def forward(self, x):
# Initial block
input_size = x.size()
x = self.initial_block(x)
# Stage 1-Encoder
stage1_input_size = x.size()
x, max_indices1_0 = self.downsample1_0(x)
x = self.regular1_1(x)
x = self.regular1_2(x)
x = self.regular1_3(x)
x = self.regular1_4(x)
# Stage2 -Encoder
stage2_input_size = x.size()
x, max_indices2_0 = self.downsample2_0(x)
x = self.regular2_1(x)
x = self.dilated2_2(x)
x = self.asymmetric2_3(x)
x = self.dilated2_4(x)
x = self.regular2_5(x)
x = self.dilated2_6(x)
x = self.asymmetric2_7(x)
x = self.dilated2_8(x)
# Stage3-Encoder
x = self.regular3_0(x)
x = self.dilated3_1(x)
x = self.asymmetric3_2(x)
x = self.dilated3_3(x)
x = self.regular3_4(x)
x = self.dilated3_5(x)
x = self.asymmetric3_6(x)
x = self.dilated3_7(x)
# Stage4 -Decoder
x = self.upsample4_0(x, max_indices2_0, output_size=stage2_input_size)
x = self.regular4_1(x)
x = self.regular4_2(x)
# Stage5-Decoder
x = self.upsample5_0(x, max_indices1_0, output_size=stage1_input_size)
x = self.regular5_1(x)
x = self.transposed_conv(x, output_size=input_size)
return x
if __name__ == '__main__':
inputs = torch.randn((1, 3, 512, 512))
model = ENet(n_classes=12)
out = model(inputs)
print(out.size())