【Nature重磅】OpenAI科学家提出全新强化学习算法,推动AI向智能体进化
深度强化学习实验室
官网:http://www.neurondance.com/
论坛:http://deeprl.neurondance.com/
编辑:DeepRL
近年来,人工智能(AI)在强化学习算法的加持下,取得了令人瞩目的成就。比如在围棋、星际争霸 II 和 Dota 2 等诸多策略、竞技类游戏中,AI 都有着世界冠军级的表现,以及在机器人跑步、跳跃和抓握等技能的自主学习方面,也起到了显著的推动作用。
如今,AI 可能要变得更 “聪明” 了。
作为机器学习的一大关键领域,强化学习侧重如何基于环境而行动,其灵感来源于心理学中的行为主义理论,即有机体如何在环境给予的奖励或惩罚的刺激下,逐步形成对刺激的预期,产生能获得最大利益的习惯性行为。
但是,这种算法思路有着明显的短板:许多成功案例都要通过精心设计、信息量大的奖励机制才能实现,当遇到很少给予反馈的复杂环境时,强化学习算法就很容易碰壁。因此,过往的 AI 难以解决探索困难(hard-exploration)的问题,这类问题通常伴随着奖励稀疏(sparse)且会有欺骗性(deceptive)的奖励存在。
今天,一项发表在《自然》(Nature)杂志的研究提出了一类全新的增强学习算法,该算法在雅达利(Atari 2600)经典游戏中的得分超过了人类顶级玩家和以往的 AI 系统,在《蒙特祖马的复仇》(Montezuma’s Revenge)和《陷阱》(Pitfall!)等一系列探索类游戏中达到了目前最先进的水平。

论文的主要作者来分别来自 OpenAI 和 Uber AI Labs,他们将这类算法统称为 Go-Explore,该类算法改善了对复杂环境的探索方式,或是 AI 向真正智能学习体进化迈出的重要一步。事实上,Uber AI Labs 早在 2018 年就对外展示了 Go-Explore 算法在探索游戏中的表现。

图|Go-Explore 在探索游戏中的表现(来源:YouTube)
AI 探索能力受阻的症结
论文的第一作者和通讯作者阿德里安・埃科菲特(Adrien Ecoffet)目前是 OpenAI 的研究科学家,其兴趣是强化学习(特别是探索和质量多样性激发的方法)和人工智能安全(特别是道德一致性),近年来的侧重一直在研究多代理环境中的紧急复杂性,在进入 OpenAI 之前,他还曾在 Uber AI 实验室就职。

图|阿德里安·埃科菲特(Adrien Ecoffet),识别二维码查看更多学者(来源:智慧人才)
想要让强化学习算法更进一步,就需要对症下药。埃科菲特和同事们分析认为,有两个主要问题阻碍了以前算法的探索能力。
第一是 “分离”(detachment),算法过早地停止返回状态空间的某些区域,尽管有证据表明这些区域仍是有希望的。当有多个区域需要探索时,分离尤其可能发生,因为智能体可能会部分探索一个区域,切换到第二个区域,并且忘记如何访问第一个区域。
第二个是 “脱轨”(derailment),算法的探索机制阻止智能体返回到以前访问过的状态,直接阻止探索或迫使将探索机制最小化,从而不会发生有效的探索。
怎么理解这些概念呢?这还得从 Go-Explore 算法推出之前说起。简单来讲,为了解决探索类游戏中奖励稀疏的问题,算法科学家们通常采用内在奖励(intrinsic motivation,IM)的方法,即奖励被人为均匀地分布在整个环境中,以鼓励智能体探索新区域和新状态。

图|“分离” 状态的图解(来源:arXiv)
如上图所示,绿色区域表示内在奖励,白色区域表示没有内在奖励的区域,紫色区域表示算法当前正在探索的区域。
举个例子,当智能体处在两个迷宫入口之间,它先从左边的迷宫开始随机搜索,由于 IM 算法要求智能体随机尝试新行为以找到更多的内在奖励的机制,在搜索完左边迷宫的 50% 时,智能体可能会在任意时刻开始对右边的迷宫进行搜索。
但是,深度学习自身有着 “灾难性遗忘”(Catastrophic Forgetting)的问题,这指的是利用神经网络学习一个新任务的时候,需要更新网络中的参数,但是上一个任务提取出来的知识也是储存在这些参数上的,于是每当学习新的任务时,智能体就会把学习旧任务得到的知识给遗忘掉,而不能像人类那样在学习中可以利用先前学习过的经验和知识,快速地进行相似技能的学习。
所以,在完成右边的搜索后,智能体并不记得在左边迷宫中探索的事情,更糟糕的情况是,左边迷宫前期的一部分区域已经被探索过了,因而几乎没有可获得的内在奖励去刺激智能体深入探索。研究人员将这种状况总结为:算法从提供内在动机的状态范围分离开了。当智能体认为已经访问过这些区域了,深入探索行为可能就会停滞,因而错过那些仍未探索到的大片区域。
天真地遵循奖励机制可能会导致智能体进入死胡同。因此,探索问题的症结就在于明确避免 “分离” 和 “脱轨” 情况的发生,让智能体通过显式 “记住” 有希望的状态和区域,并在探索新领域前能返回到这些状态。
Go-Explore 的算法逻辑
为了避免分离,Go-Explore 建立了一个智能体在环境中访问过的不同状态的 “档案”,从而确保状态不会被遗忘。如下图,从一个只包含初始状态的存档开始,它不断迭代构建这个存档。
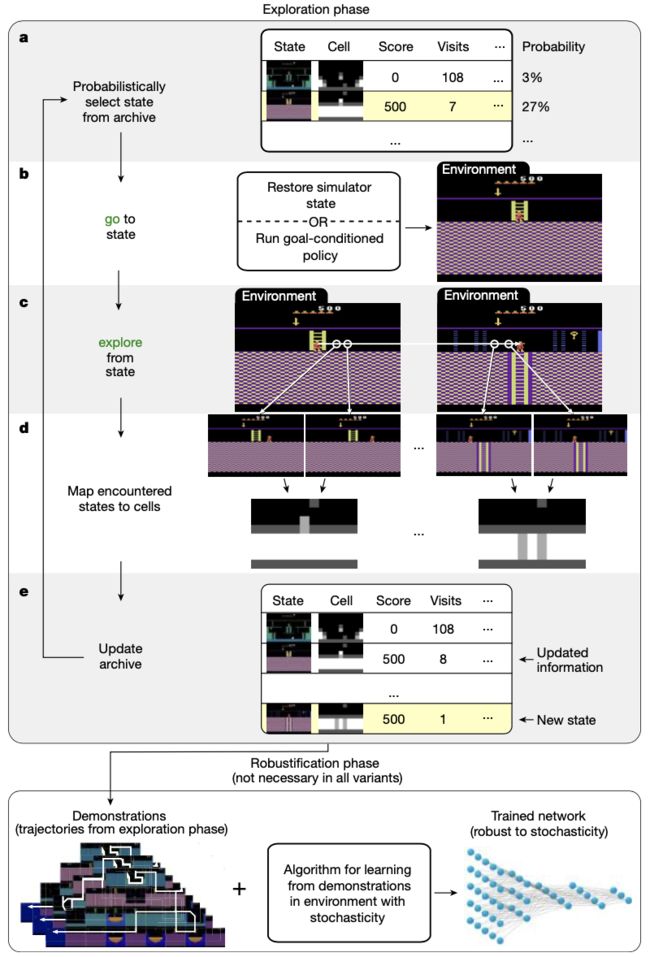
图|Go-Explore 方法概览(来源:Nature)
首先,它可能从存档中选择要返回的状态(a),返回到所选状态(b),然后从该状态探索(c),将返回和探索过程中遇到的每个状态映射到低维单元表示(d),用遇到的所有新状态更新存档(e)。
整个过程让人想起经典的规划算法,在深度强化学习研究中,这些算法的潜力相对未被重视。然而,对于强化学习领域所关注的问题(如上述在 Atari 游戏中的探索困难问题),这些问题是高维的,具有稀疏的奖励和 / 或随机性,没有已知的规划方法是有效的,且由于需要探索的状态空间太大,无法进行彻底搜索,而随机转换使得不可能知道节点是否已经完全扩展。
Go-Explore 可以看作是将规划算法的原理移植到这些具有挑战性的问题上。
以往的强化学习算法并没有将返回和探索分开,而是在整个过程中混合探索,通常是在一小部分时间内添加随机动作,或者从随机 “策略” 中采样 —— 这是一个决定在每个状态下采取哪种动作的函数,通常是一个神经网络。
通过在探索之前先返回,Go-Explore 通过在返回时最小化探索来避免脱轨发生,之后它可以纯粹专注于更深入的探索未知区域。
Go-Explore 还提供了一个独特的机会来实现模拟器在强化学习任务中的可用性和广泛性,模拟机是 “可恢复的环境”,因为以前的状态可以保存并立即返回,从而完全消除了脱轨。
在利用可恢复环境的这一特性时,Go-Explore 在其 “探索阶段” 通过不断恢复(从其档案中的一个状态采取探索行动)以彻底探索环境的各个区域,它最终返回它找到的得分最高的轨迹(动作序列)。
这样的轨迹对随机性或意外的结果并不可靠。例如,机器人可能会滑倒并错过一个关键的转弯,使整个轨迹失效。为了解决这个问题,Go-Explore 还通过 “从演示中学习”(learning from demonstrations,LFD)的方式来训练一个健壮的策略,其中探索阶段的轨迹取代了通常的人类专家演示,在一个具有足够随机性的环境变体中确保健壮性。
成效如何?
Atari benchmark 套件是强化学习算法的一个重要基准,是 Go-Explore 的一个合适的测试平台,因为它包含了一系列不同级别的奖励稀疏性和欺骗性的游戏。
在测试中,Go-Explore 的平均表现都是 “超级英雄”,在 11 个游戏比赛测试中都超过了之前算法的最高水平。在 Montezuma’s Revenge 中,Go-Explore 的战绩是此前最先进分数的四倍;在 Pitfall! 中,Go-Explore 的探索能力超过了人类的平均表现,而以前的诸多算法根本无法得分,实验结果展现出了实质性的突破,这是强化学习多年来研究的焦点。
图|Go-Explore 在游戏 Montezuma’s Revenge 中的表现(来源:YouTube)
图|Go-Explore 在游戏 Pitfall! 中的表现(来源:YouTube)
值得关注的是,不同的算法需要使用不同的计算能力。Go-Explore 处理的帧数(300 亿)与其他分布式强化学习算法,比如 Ape-X(220 亿)和 NGU(350 亿)很相似,尽管旧的算法处理的帧数通常较少,但其中许多算法显示出收敛的迹象(这意味着预计不会有进一步的进展),而且对于其中的许多算法来说,尚不清楚它们是否能够在合理的时间内处理数十亿帧。
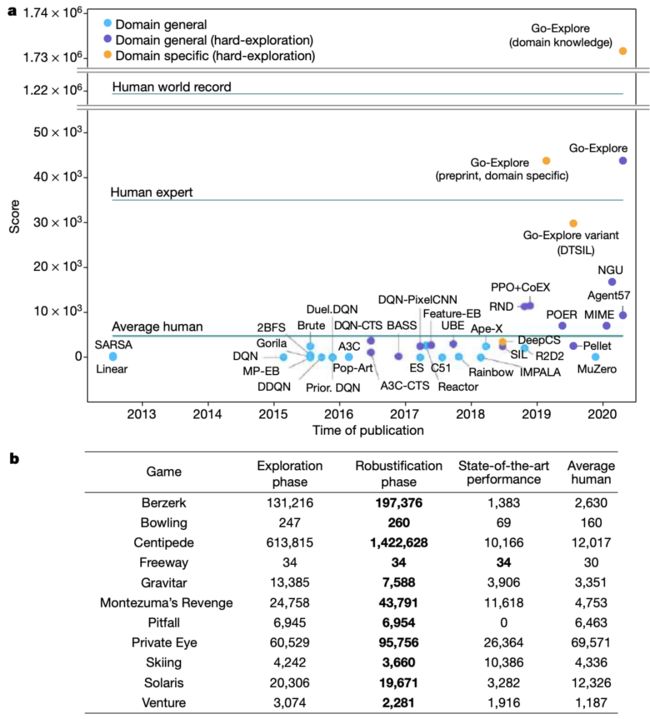
图|Go-Explore 在 Atari 平台游戏中的强力表现(来源:Nature)
此外,Go-Explore 的能力不仅限于困难的探索问题,它也为 OpenAI gym 提供的所有 55 款 Atari 游戏找到了具有超人得分的轨迹,这是前所未有的壮举,在这些游戏中,85.5% 的游戏轨迹得分高于此前最先进的强化学习算法。
研究人员表示,在实际应用中,通常可以根据领域知识定义有用的特征,Go-Explore 可以利用这些易于提供的领域知识,通过构造只包含与探索相关的功能单元来显著提高性能,Go-Explore 生成的策略,在 Montezuma’s Revenge 中平均得分超过 170 万,超过了现有技术的 150 倍。
不仅在探索类游戏中的表现突出,Go-Explore 还能用于机器人。
机器人技术是强化学习一个很有前途的应用,通常很容易定义机器人任务的高层次目标(比如,将杯子放在橱柜中),但定义一个足够密集的奖励函数要困难得多(比如,奖赏所有低级别的运动指令,以便形成向杯子移动、抓住杯子等操作)。
而 Go-Explore 允许放弃这样一个密集的奖励函数,只考虑高级任务的稀疏奖励函数。

图|Go-Explore 可以解决一个具有挑战性的、稀疏奖励的模拟机器人任务(来源:Nature)
研究人员通过一个机械臂模拟实验,演示了 Go-Explore 可以解决一个实际的艰难探索任务:机器人手臂必须拿起一个物体并将其放在四个架子中的一个架子内,其中两个架子在闩锁的门后,只有当物品被放入指定的目标货架时,才会给予奖励。
用于连续控制的最先进的强化学习算法近端策略优化(PPO)在这种环境中训练了 10 亿帧后,不会遇到任何奖励,显示了这个任务的艰难探索性质,而 Go-Explore 在探索阶段就能快速而可靠地发现将物体放入四个架子的轨迹,通过对 Go-Explore 发现的轨迹进行稳健性分析,发现可以在 99% 的情况下产生稳健的策略。
视频|Go-Explore 在更多游戏中的表现(来源:YouTube)
更多可能性
基于策略的 Go-Explore 还包括促进探索和稳定学习的其他创新,其中最重要的例如自模仿学习、动态熵增加、软轨迹和动态事件限制,在论文方法部分进行了详细讨论。
研究人员表示,这项工作提出的 Go-Explore 算法家族的有效性表明,它将在许多领域取得进展,包括机器人技术、语言理解和药物设计等,论文中提到的实例只代表了 Go-Explore 可能实现的一小部分能力,为未来的算法研究打开许多令人兴奋的可能性。
据论文描述,未来工作的一个关键方向是改进学习单元表征,比如通过基于压缩的方法、对比预测编码或辅助任务,这将使 Go-Explore 能够推广到更复杂的领域。
此外,Go-Explore 探索阶段的规划性质也突出了将其他强大的规划算法(如 MCTS、RRT 等)移植到高维状态空间的潜力,这些新的思路结合提供了丰富的可能性,以提高算法的通用性、性能、鲁棒性和效率。
这项工作中提出的见解让人们发现,记忆以前发现的状态,回到它们,然后从中探索的简单逻辑对于人工智能算法不可或缺,这可能是智能体进阶的一个基本特征。这些见解,无论是在 Go-Explore 内部还是外部,对于人类创建更强 AI 系统的能力都有新的启示作用。
参考资料:
https://www.nature.com/articles/s41586-020-03157-9
https://www.youtube.com/watch?v=u6_Ng2oFzEY&feature
https://towardsdatascience.com/a-short-introduction-to-go-explore-c61c2ef201f0
https://eng.uber.com/go-explore/
https://arxiv.org/abs/1901.10995
https://adrien.ecoffet.com/
完
总结1:周志华 || AI领域如何做研究-写高水平论文
总结2:全网首发最全深度强化学习资料(永更)
总结3: 《强化学习导论》代码/习题答案大全
总结4:30+个必知的《人工智能》会议清单
总结5:2019年-57篇深度强化学习文章汇总
总结6: 万字总结 || 强化学习之路
总结7:万字总结 || 多智能体强化学习(MARL)大总结
总结8:深度强化学习理论、模型及编码调参技巧
完
第100篇:Alchemy: 元强化学习(meta-RL)基准环境
第99篇:NeoRL:接近真实世界的离线强化学习基准
第98篇:全面总结(值函数与优势函数)的估计方法
第97篇:MuZero算法过程详细解读
第96篇: 值分布强化学习(Distributional RL)总结
第95篇:如何提高"强化学习算法模型"的泛化能力?
第94篇:多智能体强化学习《星际争霸II》研究
第93篇:MuZero在Atari基准上取得了新SOTA效果
第92篇:谷歌AI掌门人Jeff Dean获冯诺依曼奖
第91篇:详解用TD3算法通关BipedalWalker环境
第90篇:Top-K Off-Policy RL论文复现
第89篇:腾讯开源分布式多智能TLeague框架
第88篇:分层强化学习(HRL)全面总结
第87篇:165篇CoRL2020 accept论文汇总
第86篇:287篇ICLR2021深度强化学习论文汇总
第85篇:279页总结"基于模型的强化学习方法"
第84篇:阿里强化学习领域研究助理/实习生招聘
第83篇:180篇NIPS2020顶会强化学习论文
第82篇:强化学习需要批归一化(Batch Norm)吗?
第81篇:《综述》多智能体强化学习算法理论研究
第80篇:强化学习《奖励函数设计》详细解读
第79篇: 诺亚方舟开源高性能强化学习库“刑天”
第78篇:强化学习如何tradeoff"探索"和"利用"?
第77篇:深度强化学习工程师/研究员面试指南
第76篇:DAI2020 自动驾驶挑战赛(强化学习)
第75篇:Distributional Soft Actor-Critic算法
第74篇:【中文公益公开课】RLChina2020
第73篇:Tensorflow2.0实现29种深度强化学习算法
第72篇:【万字长文】解决强化学习"稀疏奖励"
第71篇:【公开课】高级强化学习专题
第70篇:DeepMind发布"离线强化学习基准“
第69篇:深度强化学习【Seaborn】绘图方法
第68篇:【DeepMind】多智能体学习231页PPT
第67篇:126篇ICML2020会议"强化学习"论文汇总
第66篇:分布式强化学习框架Acme,并行性加强
第65篇:DQN系列(3): 优先级经验回放(PER)
第64篇:UC Berkeley开源RAD来改进强化学习算法
第63篇:华为诺亚方舟招聘 || 强化学习研究实习生
第62篇:ICLR2020- 106篇深度强化学习顶会论文
第61篇:David Sliver 亲自讲解AlphaGo、Zero
第60篇:滴滴主办强化学习挑战赛:KDD Cup-2020
第59篇:Agent57在所有经典Atari 游戏中吊打人类
第58篇:清华开源「天授」强化学习平台
第57篇:Google发布"强化学习"框架"SEED RL"
第56篇:RL教父Sutton实现强人工智能算法的难易
第55篇:内推 || 阿里2020年强化学习实习生招聘
第54篇:顶会 || 65篇"IJCAI"深度强化学习论文
第53篇:TRPO/PPO提出者John Schulman谈科研
第52篇:《强化学习》可复现性和稳健性,如何解决?
第51篇:强化学习和最优控制的《十个关键点》
第50篇:微软全球深度强化学习开源项目开放申请
第49篇:DeepMind发布强化学习库 RLax
第48篇:AlphaStar过程详解笔记
第47篇:Exploration-Exploitation难题解决方法
第46篇:DQN系列(2): Double DQN 算法
第45篇:DQN系列(1): Double Q-learning
第44篇:科研界最全工具汇总
第43篇:起死回生|| 如何rebuttal顶会学术论文?
第42篇:深度强化学习入门到精通资料综述
第41篇:顶会征稿 || ICAPS2020: DeepRL
第40篇:实习生招聘 || 华为诺亚方舟实验室
第39篇:滴滴实习生|| 深度强化学习方向
第38篇:AAAI-2020 || 52篇深度强化学习论文
第37篇:Call For Papers# IJCNN2020-DeepRL
第36篇:复现"深度强化学习"论文的经验之谈
第35篇:α-Rank算法之DeepMind及Huawei改进
第34篇:从Paper到Coding, DRL挑战34类游戏
第33篇:DeepMind-102页深度强化学习PPT
第32篇:腾讯AI Lab强化学习招聘(正式/实习)
第31篇:强化学习,路在何方?
第30篇:强化学习的三种范例
第29篇:框架ES-MAML:进化策略的元学习方法
第28篇:138页“策略优化”PPT--Pieter Abbeel
第27篇:迁移学习在强化学习中的应用及最新进展
第26篇:深入理解Hindsight Experience Replay
第25篇:10项【深度强化学习】赛事汇总
第24篇:DRL实验中到底需要多少个随机种子?
第23篇:142页"ICML会议"强化学习笔记
第22篇:通过深度强化学习实现通用量子控制
第21篇:《深度强化学习》面试题汇总
第20篇:《深度强化学习》招聘汇总(13家企业)
第19篇:解决反馈稀疏问题之HER原理与代码实现
第18篇:"DeepRacer" —顶级深度强化学习挑战赛
第17篇:AI Paper | 几个实用工具推荐
第16篇:AI领域:如何做优秀研究并写高水平论文?
第15篇:DeepMind开源三大新框架!
第14篇:61篇NIPS2019DeepRL论文及部分解读
第13篇:OpenSpiel(28种DRL环境+24种DRL算法)
第12篇:模块化和快速原型设计Huskarl DRL框架
第11篇:DRL在Unity自行车环境中配置与实践
第10篇:解读72篇DeepMind深度强化学习论文
第9篇:《AutoML》:一份自动化调参的指导
第8篇:ReinforceJS库(动态展示DP、TD、DQN)
第7篇:10年NIPS顶会DRL论文(100多篇)汇总
第6篇:ICML2019-深度强化学习文章汇总
第5篇:深度强化学习在阿里巴巴的技术演进
第4篇:深度强化学习十大原则
第3篇:“超参数”自动化设置方法---DeepHyper
第2篇:深度强化学习的加速方法
第1篇:深入浅出解读"多巴胺(Dopamine)论文"、环境配置和实例分析
