高光谱图像分类 HybridSN
使用HybridSN进行高光谱图像分类
文章目录
- 使用HybridSN进行高光谱图像分类
-
- 前言
- 一、高光谱图像分类
- 二、HybridSN
- 三、pytorch实现
-
-
- 1.定义 HybridSN 类
- 2.创建数据集
- 3.模型训练
- 4.模型测试
-
- 总结
-
- 1.论文总结
- 2.思考
前言
本文主要内容是通过使用Hybrid Spectral Network(混合光谱网)对高光谱图像进行分类,同时记录了自己学到一些知识。HybridSN发表在论文《HybridSN: Exploring 3-D–2-D CNN Feature Hierarchy for Hyperspectral Image Classification》上,可以译为《混合网络:探索3-D–2-D CNN特征高光谱图像分类的层次结构》。从题目中可以看出所使用的网络2D、3D卷积两者皆有。
参考(涉及到论文的内容是英语直接翻译得来的,可能存在问题):
人工智能课程
IEEE HybridSN
GitHub HybridSN
一、高光谱图像分类
什么是高光谱图像,引用百度的话说就是:光谱分辨率在10^-2λ数量级范围内的光谱图像称为高光谱图像。
在论文中使用的高光谱图像数据集有一个是Indian Pines,它是最早的用于高光谱图像分类的测试数据。
该数据集总共有21025个像素,但是其中只有10249个像素是地物像素,其余10776个像素均为背景像素,我们需要剔除。最后,我们对着10249个像素进行16-分类。这就是高光谱图像的分类。

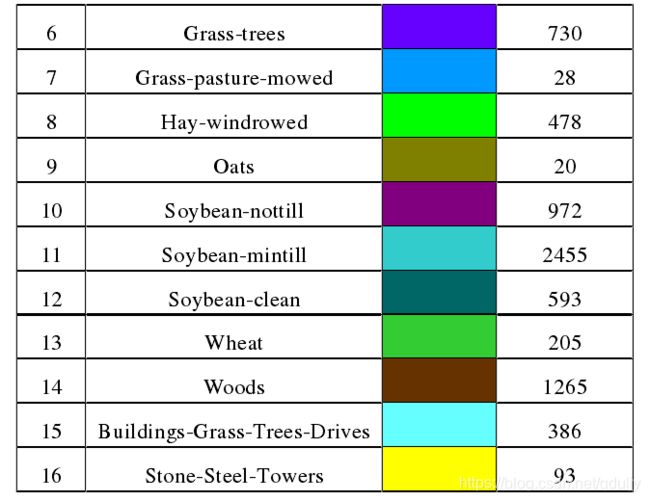 参考:徐敏. 基于深度卷积神经网络的高光谱图像分类[D].西安电子科技大学,2017 2.3.1高光谱图像分类评价 高光谱图像分类的基准数据集部分。
参考:徐敏. 基于深度卷积神经网络的高光谱图像分类[D].西安电子科技大学,2017 2.3.1高光谱图像分类评价 高光谱图像分类的基准数据集部分。
二、HybridSN
通常,HybridSN是频谱空间3-D CNN,然后是空间2-D-CNN。论文中提到,仅使用2-D-CNN或3-D-CNN有一些缺点,例如缺少频道 关系信息或模型非常复杂。这也阻止了这些方法在HSI空间上获得更高的准确性。主要原因是由于HSI是体积数据,也有光谱维度。
单独的2-D-CNN无法从光谱维度上提取良好的区分特征,同样,深 3-D-CNN的计算更加复杂,而论文中提出的HybridSN模型,克服了先前模型的这些缺点。3-D-CNN和2-D-CNN层以推荐的模型组装成合适的网络,充分利用光谱图和空间特征图,最大限度地提高精度。
下图是HybridSN模型:
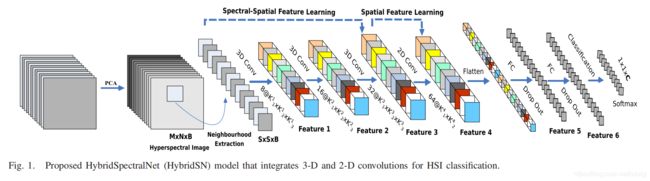
从模型图中可以看到左边第一个箭头写着PCA (对应代码),论文中提到:为了首先消除频谱冗余,将传统主成分分析(PCA)应用于沿光谱带的原始HSI数据。PCA将光谱带的数量从D减少到B,而保持相同的空间尺寸。
其中M是宽度,N是高度,B是PCA之后的光谱带数。
针对模型图左边第二个曲线箭头,论文中提到:为了利用图像分类技术, 将HSI数据立方体划分为小的重叠3-D补丁(对应代码),其真实标签由中心像素的标签决定, 创建三维相邻补丁P∈R^(S×S×B)。
conv1: ( 1, 30, 25, 25), 8个 7x3x3 的卷积核 ==> ( 8, 24, 23, 23)
conv2: ( 8, 24, 23, 23),16个 5x3x3 的卷积核 ==> (16, 20, 21, 21)
conv3: (16, 20, 21, 21),32个 3x3x3 的卷积核 ==> (32, 18, 19, 19)
第六个箭头代表二维卷积,但是从二维到三维,中间需要一个整形的过程,即减少一个维度的参数。
论文中提到,在二维卷积中,第i层的第j个特征映射中空间位置(x,y)的激活值表示为v^(x,y)使用如下等式:

翻译(存疑):其中φ是激活函数,对于第i层的第j个特征图,bi,j是偏置参数,dl-1是第(l − 1)层中的特征图和wi,j是卷积核深度的数目,对于第i层的第j个特征图,宽度为2γ+1为核的宽度,2δ+1是核的高度,wi,j是值第i层第j个特征图的权重参数的取值。
在三维卷积中,第i层第j个特征图的空间位置(x,y,z)的激活值用V^(x,y,z)表示,如下:

这两个激活函数乍一看很吓人,定睛一看似乎是线性映射。
模型图的第七个箭头是Flatten操作。即展开形成一个一维向量。第八、九两个箭头表示做两次全连接操作。最后一个表示分类到不同的类别,可以使用全连接操作映射到不同类别,实现时我们使用的数据集是Indian Pines,分为16个类别。
最后看一下整个网络结构:
 可以明显看出,第一个全连接层产生的参数占比最大。
可以明显看出,第一个全连接层产生的参数占比最大。
三、pytorch实现
实现平台选择Google的colab,使用pytorch实现。colab sharing:HybridSN
! wget http://www.ehu.eus/ccwintco/uploads/6/67/Indian_pines_corrected.mat
! wget http://www.ehu.eus/ccwintco/uploads/c/c4/Indian_pines_gt.mat
! pip install spectral
原本想在colab上跑一跑其他数据集的,提示我RAM超出容量限制?!第一次知道colab还有日志信息记录。此外,还要注意数据集载入时拥有不同的key值。

1.定义 HybridSN 类
定义HybridSN类模块参考:继承nn.Module构造自定义模块参考链接
class_num = 16
windowSize = 25
K = 30 #参考Hybrid-Spectral-Net
rate = 16
class HybridSN(nn.Module):
#定义各个层的部分
def __init__(self):
super(HybridSN, self).__init__()
self.S = windowSize
self.L = K;
#self.conv_block = nn.Sequential()
## convolutional layers
self.conv1 = nn.Conv3d(in_channels=1, out_channels=8, kernel_size=(7, 3, 3))
self.conv2 = nn.Conv3d(in_channels=8, out_channels=16, kernel_size=(5, 3, 3))
self.conv3 = nn.Conv3d(in_channels=16, out_channels=32, kernel_size=(3, 3, 3))
#不懂 inputX经过三重3d卷积的大小
inputX = self.get2Dinput()
inputConv4 = inputX.shape[1] * inputX.shape[2]
# conv4 (24*24=576, 19, 19),64个 3x3 的卷积核 ==>((64, 17, 17)
self.conv4 = nn.Conv2d(inputConv4, 64, kernel_size=(3, 3))
#self-attention
self.sa1 = nn.Conv2d(64, 64//rate, kernel_size=1)
self.sa2 = nn.Conv2d(64//rate, 64, kernel_size=1)
# 全连接层(256个节点) # 64 * 17 * 17 = 18496
self.dense1 = nn.Linear(18496, 256)
# 全连接层(128个节点)
self.dense2 = nn.Linear(256, 128)
# 最终输出层(16个节点)
self.dense3 = nn.Linear(128, class_num)
#让某个神经元的激活值以一定的概率p,让其停止工作,这次训练过程中不更新权值,也不参加神经网络的计算。
#但是它的权重得保留下来(只是暂时不更新而已),因为下次样本输入时它可能又得工作了
#参考: https://blog.csdn.net/yangfengling1023/article/details/82911306
#self.drop = nn.Dropout(p = 0.4)
#改成0.43试试
self.drop = nn.Dropout(p = 0.43)
self.soft = nn.Softmax(dim=1)
pass
#辅助函数,没怎么懂,求经历过三重卷积后二维的一个大小
def get2Dinput(self):
#torch.no_grad(): 做运算,但不计入梯度记录
with torch.no_grad():
x = torch.zeros((1, 1, self.L, self.S, self.S))
x = self.conv1(x)
x = self.conv2(x)
x = self.conv3(x)
return x
pass
#必须重载的部分,X代表输入
def forward(self, x):
#F在上文有定义torch.nn.functional,是已定义好的一组名称
out = F.relu(self.conv1(x))
out = F.relu(self.conv2(out))
out = F.relu(self.conv3(out))
# 进行二维卷积,因此把前面的 32*18 reshape 一下,得到 (576, 19, 19)
out = out.view(-1, out.shape[1] * out.shape[2], out.shape[3], out.shape[4])
out = F.relu(self.conv4(out))
# Squeeze 第三维卷成1了
weight = F.avg_pool2d(out, out.size(2)) #参数为输入,kernel
#参考: https://blog.csdn.net/qq_21210467/article/details/81415300
#参考: https://blog.csdn.net/u013066730/article/details/102553073
# Excitation: sa(压缩到16分之一)--Relu--fc(激到之前维度)--Sigmoid(保证输出为0至1之间)
weight = F.relu(self.sa1(weight))
weight = F.sigmoid(self.sa2(weight))
out = out * weight
# flatten: 变为 18496 维的向量,
out = out.view(out.size(0), -1)
out = F.relu(self.dense1(out))
out = self.drop(out)
out = F.relu(self.dense2(out))
out = self.drop(out)
out = self.dense3(out)
#添加此语句后出现LOSS不下降的情况,参考:https://www.e-learn.cn/topic/3733809
#原因是CrossEntropyLoss()=softmax+负对数损失(已经包含了softmax)。如果多写一次softmax,则结果会发生错误
#out = self.soft(out)
#out = F.log_softmax(out)
return out
pass
其原因是计算LOSS = CrossEntropyLoss() = softmax + 负对数损失(已经包含了softmax),所以多写一次softmax,结果会发生错误。
参考:HybridSN
2.创建数据集
首先对高光谱数据实施PCA降维;然后创建 keras 方便处理的数据格式;然后随机抽取 10% 数据做为训练集,剩余的做为测试集。首先定义基本函数: 四个函数分别进行主成分分析、零填充、创建patch和划分数据集,在上文中我们提到过主成分分析以及patch。
# 对高光谱数据 X 应用 PCA 变换
def applyPCA(X, numComponents):
newX = np.reshape(X, (-1, X.shape[2]))
pca = PCA(n_components=numComponents, whiten=True)
newX = pca.fit_transform(newX)
newX = np.reshape(newX, (X.shape[0], X.shape[1], numComponents))
return newX
# 对单个像素周围提取 patch 时,边缘像素就无法取了,因此,给这部分像素进行 padding 操作
def padWithZeros(X, margin=2):
newX = np.zeros((X.shape[0] + 2 * margin, X.shape[1] + 2* margin, X.shape[2]))
x_offset = margin
y_offset = margin
newX[x_offset:X.shape[0] + x_offset, y_offset:X.shape[1] + y_offset, :] = X
return newX
# 在每个像素周围提取 patch ,然后创建成符合 keras 处理的格式
def createImageCubes(X, y, windowSize=5, removeZeroLabels = True):
# 给 X 做 padding
margin = int((windowSize - 1) / 2)
zeroPaddedX = padWithZeros(X, margin=margin)
# split patches
patchesData = np.zeros((X.shape[0] * X.shape[1], windowSize, windowSize, X.shape[2]))
patchesLabels = np.zeros((X.shape[0] * X.shape[1]))
patchIndex = 0
for r in range(margin, zeroPaddedX.shape[0] - margin):
for c in range(margin, zeroPaddedX.shape[1] - margin):
patch = zeroPaddedX[r - margin:r + margin + 1, c - margin:c + margin + 1]
patchesData[patchIndex, :, :, :] = patch
patchesLabels[patchIndex] = y[r-margin, c-margin]
patchIndex = patchIndex + 1
if removeZeroLabels:
patchesData = patchesData[patchesLabels>0,:,:,:]
patchesLabels = patchesLabels[patchesLabels>0]
patchesLabels -= 1
return patchesData, patchesLabels
def splitTrainTestSet(X, y, testRatio, randomState=345):
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=testRatio, random_state=randomState, stratify=y)
return X_train, X_test, y_train, y_test
# 地物类别
class_num = 16
X = sio.loadmat('Indian_pines_corrected.mat')['indian_pines_corrected']
y = sio.loadmat('Indian_pines_gt.mat')['indian_pines_gt']
# 用于测试样本的比例
test_ratio = 0.90
# 每个像素周围提取 patch 的尺寸
patch_size = 25
# 使用 PCA 降维,得到主成分的数量
pca_components = 30
print('Hyperspectral data shape: ', X.shape)
print('Label shape: ', y.shape)
print('\n... ... PCA tranformation ... ...')
X_pca = applyPCA(X, numComponents=pca_components)
print('Data shape after PCA: ', X_pca.shape)
print('\n... ... create data cubes ... ...')
X_pca, y = createImageCubes(X_pca, y, windowSize=patch_size)
print('Data cube X shape: ', X_pca.shape)
print('Data cube y shape: ', y.shape)
print('\n... ... create train & test data ... ...')
Xtrain, Xtest, ytrain, ytest = splitTrainTestSet(X_pca, y, test_ratio)
print('Xtrain shape: ', Xtrain.shape)
print('Xtest shape: ', Xtest.shape)
# 改变 Xtrain, Ytrain 的形状,以符合 keras 的要求
Xtrain = Xtrain.reshape(-1, patch_size, patch_size, pca_components, 1)
Xtest = Xtest.reshape(-1, patch_size, patch_size, pca_components, 1)
print('before transpose: Xtrain shape: ', Xtrain.shape)
print('before transpose: Xtest shape: ', Xtest.shape)
# 为了适应 pytorch 结构,数据要做 transpose
Xtrain = Xtrain.transpose(0, 4, 3, 1, 2)
Xtest = Xtest.transpose(0, 4, 3, 1, 2)
print('after transpose: Xtrain shape: ', Xtrain.shape)
print('after transpose: Xtest shape: ', Xtest.shape)
""" Training dataset"""
class TrainDS(torch.utils.data.Dataset):
def __init__(self):
self.len = Xtrain.shape[0]
self.x_data = torch.FloatTensor(Xtrain)
self.y_data = torch.LongTensor(ytrain)
def __getitem__(self, index):
# 根据索引返回数据和对应的标签
return self.x_data[index], self.y_data[index]
def __len__(self):
# 返回文件数据的数目
return self.len
""" Testing dataset"""
class TestDS(torch.utils.data.Dataset):
def __init__(self):
self.len = Xtest.shape[0]
self.x_data = torch.FloatTensor(Xtest)
self.y_data = torch.LongTensor(ytest)
def __getitem__(self, index):
# 根据索引返回数据和对应的标签
return self.x_data[index], self.y_data[index]
def __len__(self):
# 返回文件数据的数目
return self.len
# 创建 trainloader 和 testloader
trainset = TrainDS()
testset = TestDS()
train_loader = torch.utils.data.DataLoader(dataset=trainset, batch_size=128, shuffle=True, num_workers=2)
test_loader = torch.utils.data.DataLoader(dataset=testset, batch_size=128, shuffle=False, num_workers=2)
3.模型训练
# 使用GPU训练,可以在菜单 "代码执行工具" -> "更改运行时类型" 里进行设置
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# 网络放到GPU上
net = HybridSN().to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(net.parameters(), lr=0.00037)
# 开始训练
net.train()
total_loss = 0
for epoch in range(200):
for i, (inputs, labels) in enumerate(train_loader):
inputs = inputs.to(device)
labels = labels.to(device)
# 优化器梯度归零
optimizer.zero_grad()
# 正向传播 + 反向传播 + 优化
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
total_loss += loss.item()
print('[Epoch: %d] [loss avg: %.4f] [current loss: %.4f]' %(epoch + 1, total_loss/(epoch+1), loss.item()))
print('Finished Training')

模型在训练集上使用model.train()可以启用BatchNormalization和Dropout,同时在测试集上必须有model.eval()(我自己也没有理解透彻,有时间得翻翻pytorch官方教程,先给出一个参考链接:model.train and model.eval)。
关于训练时为什么要梯度归零,再温习一下。
4.模型测试
count = 0
net.eval()
# 模型测试
for inputs, _ in test_loader:
inputs = inputs.to(device)
outputs = net(inputs)
outputs = np.argmax(outputs.detach().cpu().numpy(), axis=1)
if count == 0:
y_pred_test = outputs
count = 1
else:
y_pred_test = np.concatenate( (y_pred_test, outputs) )
# 生成分类报告
classification = classification_report(ytest, y_pred_test, digits=4)
print(classification)

总结
1.论文总结
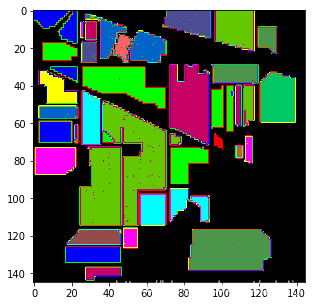
论文介绍了一种用于HSI分类的混合三维和二维模型。所提出的HybridSN模型基本上将空间光谱和光谱的互补信息分别以三维和二维卷积的形式结合起来。代码部分借用了已整理好的数据集直接使用,仅仅在一个数据集上测试,论文中在三个基准数据集的实验证实了该方法的优越性。该模型比三维CNN模型更具有计算效率。 最后是高光谱图分类结果:
2.思考
论文中使用了2D、3D卷积,可以看出的是3D卷积明显多一个维度,对应的激活函数也多一个维度。此外,2D conv的卷积核其实是(c, k_h, k_w),3D conv的卷积核就是(c, k_d, k_h, k_w),其中k_d就是多出来的第三维,根据具体应用,在视频中就是时间维,在CT图像中就是层数维。并且,论文中先进行3维卷积,再进行二维卷积,这说明它们适用的场景不同,我们容易减少数据集的维度,但不容易增加数据集维度,所以应当先进行高维的卷积。另外,上面有关网络结构的表中,我们可以看到,三维卷积产生的参数比二维卷积要少 得 多(不知道为什么)。
我们在启用dropout后(默认开启了model.train()),会进行随机采样,可能会导致网络在测试时分类结果不一样,准确率可能会受到影响。加入model.eval()可以固定住dropout(有时候,我们的模型会产生随机数,可能也会导致分类结果不同)。
为了提升网络的性能,我们使用自注意力机制:
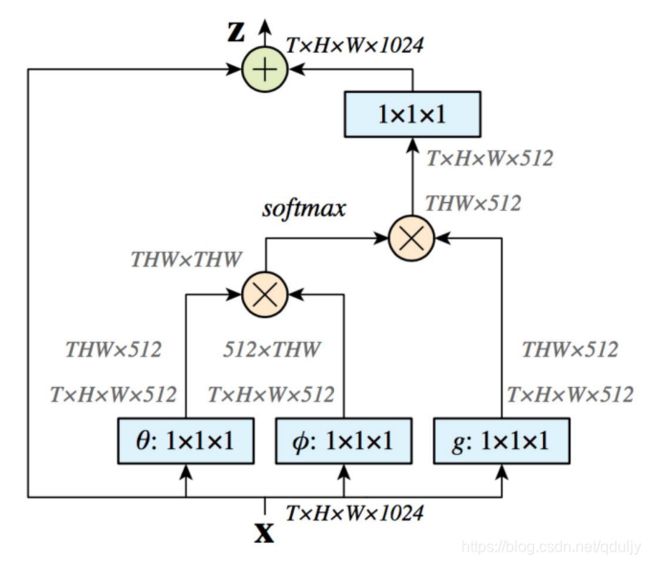
代码中使用下面两部分实现自注意力机制:
#attention
self.sa1 = nn.Conv2d(64, 64//rate, kernel_size=1)
self.sa2 = nn.Conv2d(64//rate, 64, kernel_size=1)
weight = F.relu(self.sa1(weight))
weight = F.sigmoid(self.sa2(weight))
out = out * weight