Python爬取豆瓣短评
暑假用python爬取了豆瓣上33部关于病毒、疾病题材电影的短评,并尝试了下词频统计、可视化、词云O(∩_∩)O哈哈~
1、爬取
电影清单如下:

构造访问URL
一条条确认电影的豆瓣ID┓(;´_`)┏
知道了电影的豆瓣ID后,就可以构造访问豆瓣短评界面的URL了
base_url = ‘https://movie.douban.com/subject/’ + moveID + ‘/comments’
翻页
知道翻页后URL变化的规律后可以构造下一页的URL。而我用的方法是直接在当前界面中用XPATH选择器找到翻页的按钮,获取对应的link内容,构造下一页的URL进行访问。
html_elem = etree.HTML(html)
url = html_elem.xpath(’//div[@id=“paginator”]/a[@class=“next”]/@href’)
定位短评
同样使用XPATH选择器,这种方法相较于正则表达式容错和效率更高。
contents = html.xpath(’//div[@class="comment-item "]/div[2]/p/span/text()’)
保存到.txt文件

2、词频统计
import jieba
import collections
使用jieba库进行分词:
cut_text = jieba.cut(f, cut_all=False)
自定义滤词库
直接分词之后,有些语气词、称谓词虽然出现次数频繁但没有什么实际意义,需要进行一轮过滤good

使用collection库进行词频统计
当然也可以用字典的方法。
word_counts = collections.Counter(scn_text)
word_counts_top = word_counts.most_common(30)
将统计结果保存到.txt文件
3、制作词云
from wordcloud import WordCloud, STOPWORDS, ImageColorGenerator
这里使用的是wordcloud库,这个库的安装比较折腾,大家可以找一些资料看看very good!
wordcloud = WordCloud(font_path='C:/Windows/Fonts/HGY4_CNKI.TTF',background_color="white",height=880,width=1000).generate_from_frequencies(word_counts)
效果图:


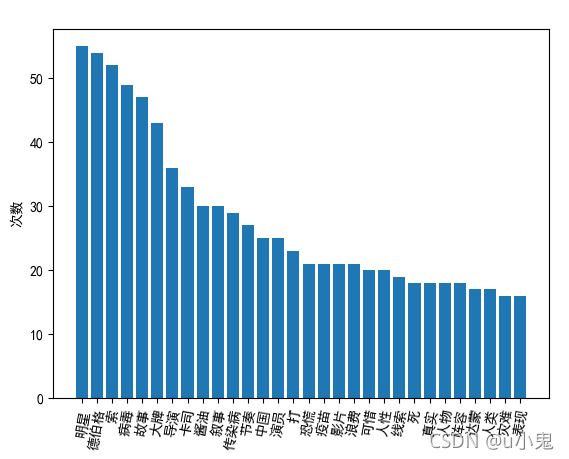
4、使用matplotlib制作柱状图
import matplotlib.pyplot as plt
plt.clf()
plt.title("")
x = []
y = []
for one in word_counts_top:
x.append(one[0])
y.append(one[1])
plt.bar(x, y)
plt.xlabel(“词汇”)
plt.ylabel(“次数”)
plt.xticks(rotation=80)
效果图:
5、源码获取
https://download.csdn.net/download/qq_23096319/21790452?spm=1001.2014.3001.5501