世界杯球队分析
文章目录
- 1. 本文思路
- 2.数据介绍
-
- 2.1 results.csv数据集
- 2.2 shootouts.csv数据集
- 3. 数据分析
-
- 3.1 多维度分析
- 3.2 数据分析案例
-
- 3.2.1 导入模块
- 3.2.2 导入数据
-
- 1.遍历目录
- 2.读取数据
- 3.2.3 查看描述数据
-
- 1.查看数据
- 2. 获取所有世界杯比赛的数据
- 3. 查看包含FIFA的类型
- 4. 获取世界杯数据不包含预选赛
- 5. 数据转化时间类型
- 6.计算进球得分数据
- 7. 根据得分数据构造赢球字段
- 3.2.4 获取世界杯主场比赛的比赛结果分析
-
- 1.查看空缺值
- 2.删除空缺值
- 3.添加主场胜负平列
- 4. 获取世界杯主场比赛的比赛结果分析
- 3.3 其它相关分析
- 4. 总结
1. 本文思路
在世界杯⚽️期间,想起一个主题,根据往年的球队信息,进行一些分析,如果可以预测今年球队名次更佳(美滋滋 )。
如果你更感兴趣各种emoji表情的内容,也可以通过emoji官网找到对应的代码,python中也提供了对应的emoji库。
世界杯球队分析:
kaggle上世界杯的数据集
kaggle相关分析参考
CSDN上热门球队夺冠分析
数据分析阶段参考:https://baijiahao.baidu.com/s?id=1750933727392335087
2.数据介绍
本数据集来源于kaggle,CSDN的下载地址为https://download.csdn.net/download/m0_38139250/87231076:
数据集下包含3个文件,分别是:

该数据集包括从1872年第一场正式比赛到2022年的44152场国际足球比赛结果。比赛范围从国际足联世界杯到国际足球联合会野生杯,再到普通的友谊赛。这些比赛严格来说都是男足国际比赛,数据不包括奥运会或至少有一支球队是国家b队、U-23或联赛精选球队的比赛。
2.1 results.csv数据集
数据集截图:
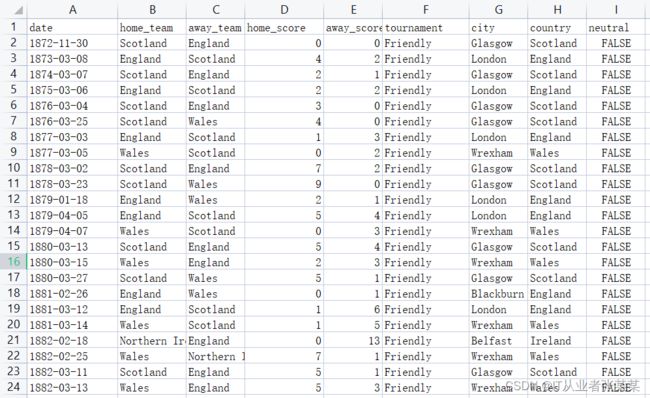
results.csv数据集的字段含义如下:
date - date of the match 比赛日期
home_team - the name of the home team 主队名称
away_team - the name of the away team 客队名称
home_score - full-time home team score including extra time, not including penalty-shootouts 主队进球数 (不含点球)
away_score - full-time away team score including extra time, not including penalty-shootouts 客队进球数 (不含点球
tournament - the name of the tournament 比赛的类型
city - the name of the city/town/administrative unit where the match was played 比赛所在城市
country - the name of the country where the match was played 比赛所在国家
neutral - TRUE/FALSE column indicating whether the match was played at a neutral venue 比赛是否在中立场地进行
2.2 shootouts.csv数据集
数据集截图:
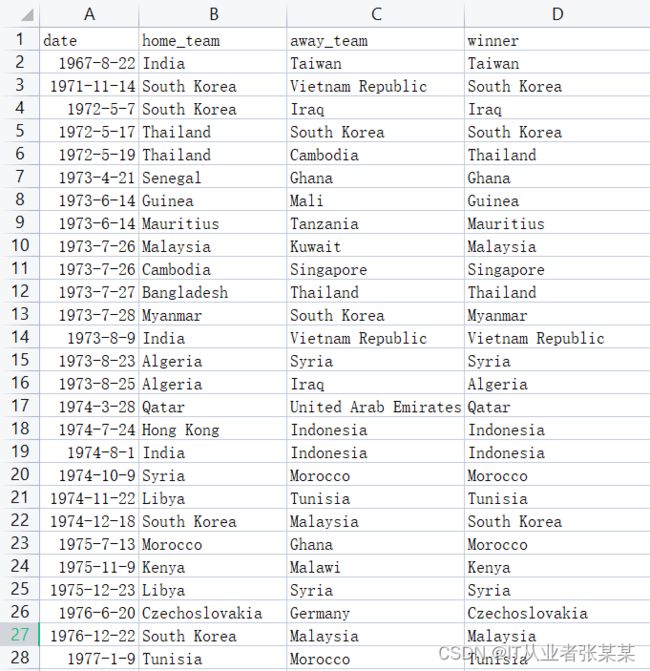
shootouts.csv 点球大战数据集 包含如下的字段:
date - date of the match 比赛日期
home_team - the name of the home team 主场球队名称
away_team - the name of the away team 客场球队名称
winner - winner of the penalty-shootout 点球大战的胜利者
关于球队和国家名称:
主队和客场队都使用了球队当前的队名。例如,1882年,一支自称爱尔兰的球队与英格兰队比赛,在这个数据集中,它被称为北爱尔兰,因为现在的北爱尔兰队是1882年爱尔兰队的继承者。这样做是为了更容易跟踪团队的历史和统计数据。
对于国家名称,使用比赛时的国家名称。所以当加纳在20世纪50年代在黄金海岸的阿克拉比赛时,尽管主队和国家队的名字并不匹配
3. 数据分析
3.1 多维度分析
数据分析时,如果选择有效的切入点呢,一般而言,多维度分析是切实可行的方法。
多维度分析实质是细分分析,多维度分析对精细化运营的作用非常重要。多维度分析主要基于两个地方展开,一个是指标的细化,一个是维度的多元,比如时间维度,竞品维度等。管理层通常看的是综合指标,总值。但是这些总值无法真正发现问题。而运营通常需要根据具体的、细分的数据来支撑决策。比如从用户角度看,每天访问用户100万,每天购买的用户1万,但这100万个用户是通过什么渠道知道平台的,在平台哪个模块停留时间长,哪个模块转化率高需要通过指标细分,才能下结论。
3.2 数据分析案例
3.2.1 导入模块
from mpl_toolkits.mplot3d import Axes3D # 绘制3D图像
from sklearn.preprocessing import StandardScaler # 数据预处理标准化
import matplotlib.pyplot as plt # 绘图
import numpy as np # 线性代数
import os # 访问目录结果
import pandas as pd # 数据读取与处理
3.2.2 导入数据
1.遍历目录
for dirname, _, filenames in os.walk(r'F:\公司\20221124XX大学\世界杯数据集'):
for filename in filenames:
print(os.path.join(dirname, filename))
输出为:
F:\公司\20221124XX大学\世界杯数据集\goalscorers.csv
F:\公司\20221124XX大学\世界杯数据集\results.csv
F:\公司\20221124XX大学\世界杯数据集\shootouts.csv
os.walk()函数参考链接
2.读取数据
nRowsRead = None # 如果为None,则读取整个文件
# results.csv 有 40839 行数据
df1 = pd.read_csv(r'F:\公司\20221124XX大学\世界杯数据集\results.csv', delimiter=',', nrows = nRowsRead)
df1.dataframeName = 'results.csv'
nRow, nCol = df1.shape
print(f'该数据集有{nRow} 行,{nCol} 列')
3.2.3 查看描述数据
1.查看数据
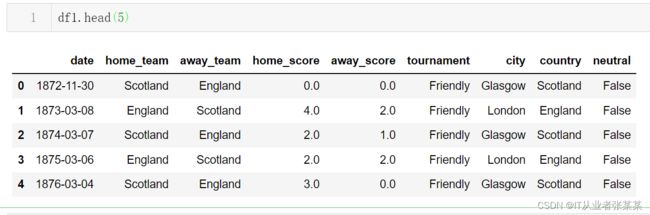
查看前5条
df1.head(5)
输出为:
查看数据类型等信息
df1.info()
输出为:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 44206 entries, 0 to 44205
Data columns (total 9 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 date 44206 non-null object
1 home_team 44206 non-null object
2 away_team 44206 non-null object
3 home_score 44202 non-null float64
4 away_score 44202 non-null float64
5 tournament 44206 non-null object
6 city 44206 non-null object
7 country 44206 non-null object
8 neutral 44206 non-null bool
dtypes: bool(1), float64(2), object(6)
memory usage: 2.7+ MB
2. 获取所有世界杯比赛的数据
# 获取比赛类型包含FIFA世界杯的数据
df_FIFA_all = df1[df1['tournament'].str.contains('FIFA', regex=True)]
df_FIFA_all
输出为:
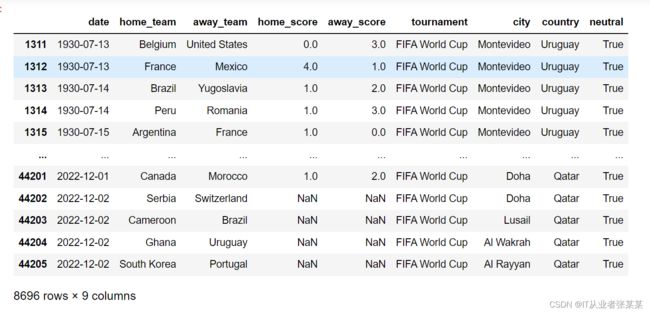
3. 查看包含FIFA的类型
df_FIFA_all['tournament'].unique()
输出为:
array(['FIFA World Cup', 'FIFA World Cup qualification',
'FIFA 75th Anniversary Cup'], dtype=object)
4. 获取世界杯数据不包含预选赛
df_FIFA = df_FIFA_all[df_FIFA_all['tournament']=='FIFA World Cup']
df_FIFA
输出为:
5. 数据转化时间类型
转换时间格式,生成新的年份数据
df_FIFA.loc[:,'date'] = pd.to_datetime(df_FIFA.loc[:,'date'])
df_FIFA['year'] = df_FIFA['date'].dt.year
df_FIFA
输出为:
6.计算进球得分数据
df_FIFA['diff_score'] = df_FIFA['home_score']-df_FIFA['away_score']
df_FIFA['diff_score'] = pd.to_numeric(df_FIFA['diff_score'])
df_FIFA
输出为:
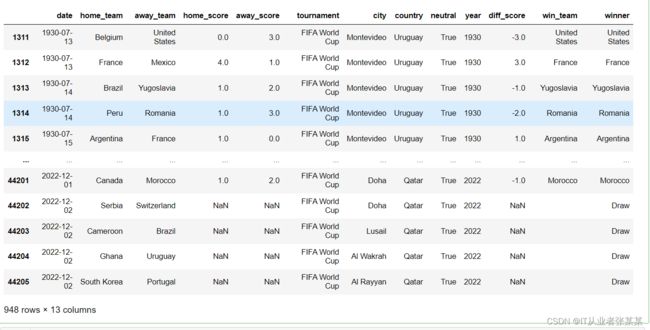
7. 根据得分数据构造赢球字段
df_FIFA['win_team'] = ''
# 如果分数差为正 则赢的队为主队
df_FIFA.loc[df_FIFA['diff_score']> 0, 'win_team'] = df_FIFA.loc[df_FIFA['diff_score']> 0, 'home_team']
# 如果分数差为负 则赢的队为客队
df_FIFA.loc[df_FIFA['diff_score']< 0, 'win_team'] = df_FIFA.loc[df_FIFA['diff_score']< 0, 'away_team']
# 如果分数差为0 则平局
df_FIFA.loc[df_FIFA['diff_score']== 0, 'win_team'] = 'Draw'
df_FIFA
输出为:
3.2.4 获取世界杯主场比赛的比赛结果分析
1.查看空缺值
df_FIFA[['home_team','diff_score']].isna().sum()
输出为:
home_team 0
diff_score 4
dtype: int64
2.删除空缺值
df_FIFA_no_na = df_FIFA[['home_team','diff_score']].dropna()
df_FIFA_no_na
3.添加主场胜负平列
df_FIFA_no_na['主场赢'] = ""
df_FIFA_no_na.loc[:,'主场赢'].loc[df_FIFA_no_na['diff_score']<0] = "胜"
df_FIFA_no_na.loc[:,'主场赢'].loc[df_FIFA_no_na['diff_score']>0] = "负"
df_FIFA_no_na.loc[:,'主场赢'].loc[df_FIFA_no_na['diff_score']==0]= "平"
df_FIFA_no_na['主场赢'].value_counts()
输出为:
负 427
胜 308
平 209
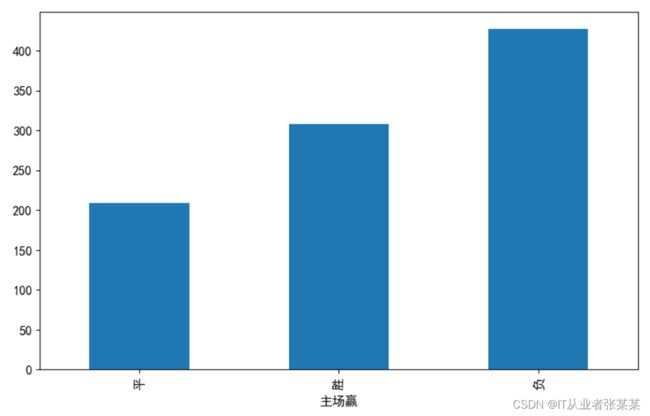
4. 获取世界杯主场比赛的比赛结果分析
s = df_FIFA_no_na.groupby('主场赢')['主场赢'].count()
# s.sort_values(ascending=False, inplace=True)
s
输出为:
主场赢
平 209
胜 308
负 427
Name: 主场赢, dtype: int64
可视化分析
import matplotlib
%matplotlib inline
font = {
'family':'SimHei',
'weight':'bold',
'size':12
}
matplotlib.rc("font", **font)
matplotlib.rcParams['axes.unicode_minus']=False
s.plot(kind = 'bar', figsize=(10, 6))
输出为:
3.3 其它相关分析
针对这些数据,还可以进行其它分析,看你的创意啦~~~
在研究数据时,可以遵循以下几个方向:
1.谁是有史以来最好的球队
2.哪些球队统治着不同的足球时代
3.历史上国际足球的发展趋势是什么——主场优势、总进球数、球队实力分布等等
4.我们能从足球赛程中谈谈地缘政治吗?国家的数量是如何变化的?哪些球队喜欢彼此比赛
5.哪些国家举办的比赛最多,而他们自己却不参加
6.举办一场大型赛事对一个国家的世界杯机会有多大帮助
4. 总结
可以针对这份数据集,进行如下操作:
1.使用爬虫获取csdn中的下载数据
2.加载数据
3.数据处理
4.数据分析
5.数据可视化
6.数据挖掘预测,预测今年谁是冠军吧