DeFCN 训练前向传播过程
目录
一、 大致流程
1. 入口
2. 得到backbone的feature
3. head运算以及3dmaxfilter
4. 获得标签
5. 计算损失函数
6. 回到主线
二、debug注释
1. base_runner.py
2. fcos.py
1) forward
2) preprocess_image
3) FCOSHead
3. fpn.py
三、max3d
四、标签的建立
1. shifts的创建
1) _create_grid_offsets
2. POTO 计算标签的质量
3. 计算loss
五、 与跟踪不同的地方
1. 回归标签的建立
一、 大致流程
1. 入口
执行 base_runner.py ---87
self.run_step()跳转到同文件下的
class SimpleRunner(RunnerBase):
类下的run_step函数中
base_runner.py -----188
loss_dict = self.model(data)跳转到 fcos.py 的 forward函数中
2. 得到backbone的feature
fcos.py -----132
features = self.backbone(images.tensor)images.tensor如下所示

接着跳转到fpn.py ---132 forward函数中
fpn.py -----146
bottom_up_features = self.bottom_up(x)
得到resnet的输出,最后返回到fcos.py文件的forward函数中,得到features

3. head运算以及3dmaxfilter
fcos.py ---- 134
box_cls, box_delta, box_filter = self.head(features)跳转到fcos.py 中的类 FCOSHead的前向传播 forward函数中
"""
Arguments:
features (list[Tensor]): FPN feature map tensors in high to low resolution.
Each tensor in the list correspond to different feature levels.
Returns:
logits (list[Tensor]): #lvl tensors, each has shape (N, K, Hi, Wi).
The tensor predicts the classification probability
at each spatial position for each of the K object classes.
bbox_reg (list[Tensor]): #lvl tensors, each has shape (N, 4, Hi, Wi).
The tensor predicts 4-vector (dl,dt,dr,db) box
regression values for every shift. These values are the
relative offset between the shift and the ground truth box.
filter (list[Tensor]): #lvl tensors, each has shape (N, 1, Hi, Wi).
The tensor predicts the centerness at each spatial position.
"""可以看出 filter 就是中心质量分支
3dmaxfilter
fcos.py -----571
filters = [self.filter(x) for x in self.max3d(filter_subnet)]4. 获得标签
if self.training: # True
gt_classes, gt_shifts_reg_deltas = self.get_ground_truth(
shifts, gt_instances, box_cls, box_delta, box_filter)fcos.py ----138
跳转到 fcos.py ----- get_ground_truth函数中
def get_ground_truth(self, shifts, targets, box_cls, box_delta, box_filter):
"""
Args:
shifts (list[list[Tensor]]): a list of N=#image elements. Each is a
list of #feature level tensors. The tensors contains shifts of
this image on the specific feature level.
targets (list[Instances]): a list of N `Instances`s. The i-th
`Instances` contains the ground-truth per-instance annotations
for the i-th input image. Specify `targets` during training only.
Returns:
gt_classes (Tensor):
An integer tensor of shape (N, R) storing ground-truth
labels for each shift.
R is the total number of shifts, i.e. the sum of Hi x Wi for all levels.
Shifts in the valid boxes are assigned their corresponding label in the
[0, K-1] range. Shifts in the background are assigned the label "K".
Shifts in the ignore areas are assigned a label "-1", i.e. ignore.
gt_shifts_deltas (Tensor):
Shape (N, R, 4).
The last dimension represents ground-truth shift2box transform
targets (dl, dt, dr, db) that map each shift to its matched ground-truth box.
The values in the tensor are meaningful only when the corresponding
shift is labeled as foreground.
"""5. 计算损失函数
fcos.py -----140
return self.losses(gt_classes, gt_shifts_reg_deltas, box_cls,
box_delta, box_filter)6. 回到主线
base_runner.py ----188
loss_dict = self.model(data)
losses = sum([
metrics_value for metrics_value in loss_dict.values()
if metrics_value.requires_grad
])二、debug注释
1. base_runner.py
self
data
2. fcos.py
1) forward
batched_inputs
gt_instances

features ----(from backbone)

---(list)

shifts
![]()
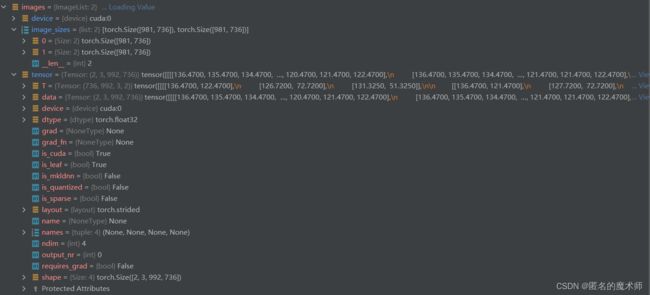
2) preprocess_image
images --- first

----- second
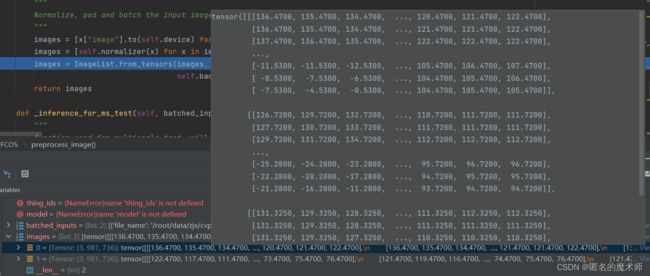
----- third
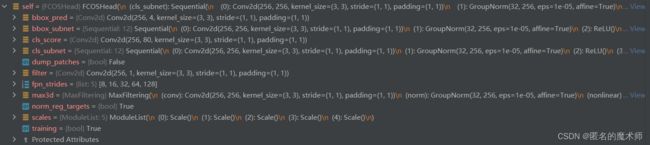
3) FCOSHead
self
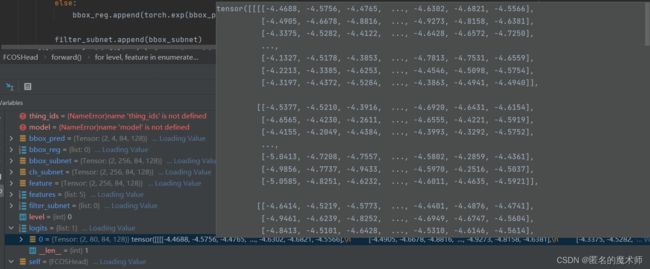
logits
bbox_pred
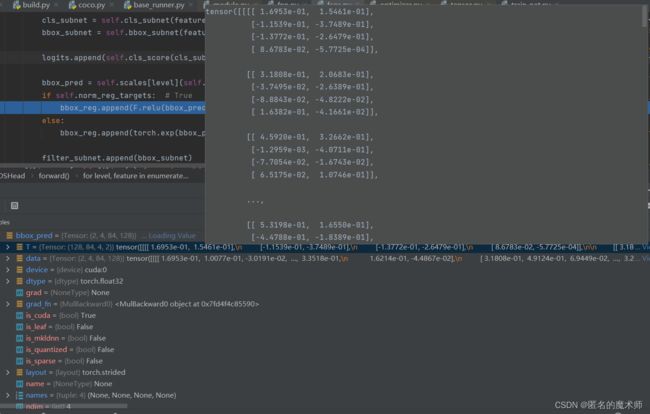
box_reg

3. fpn.py
self

bottom_up_features
三、max3d
filters = [self.filter(x) for x in self.max3d(filter_subnet)]首先转到 fcos.py 中的 MaxFiltering类中
class MaxFiltering(nn.Module):
def __init__(self, in_channels: int, kernel_size: int = 3, tau: int = 2):
super().__init__()
self.conv = nn.Conv2d(
in_channels,
in_channels,
kernel_size=3,
stride=1,
padding=1
)
self.norm = nn.GroupNorm(32, in_channels)
self.nonlinear = nn.ReLU()
self.max_pool = nn.MaxPool3d(
kernel_size=(tau + 1, kernel_size, kernel_size),
padding=(tau // 2, kernel_size // 2, kernel_size // 2),
stride=1
)
self.margin = tau // 2
def forward(self, inputs):
features = []
for l, x in enumerate(inputs):
features.append(self.conv(x))
outputs = []
for l, x in enumerate(features):
func = lambda f: F.interpolate(f, size=x.shape[2:], mode="bilinear")
feature_3d = []
for k in range(max(0, l - self.margin), min(len(features), l + self.margin + 1)): # 0~1, 0~2, 1~3, 2~4, 3~4
feature_3d.append(func(features[k]) if k != l else features[k])
feature_3d = torch.stack(feature_3d, dim=2)
max_pool = self.max_pool(feature_3d)[:, :, min(l, self.margin)]
output = max_pool + inputs[l]
outputs.append(self.nonlinear(self.norm(output)))
return outputs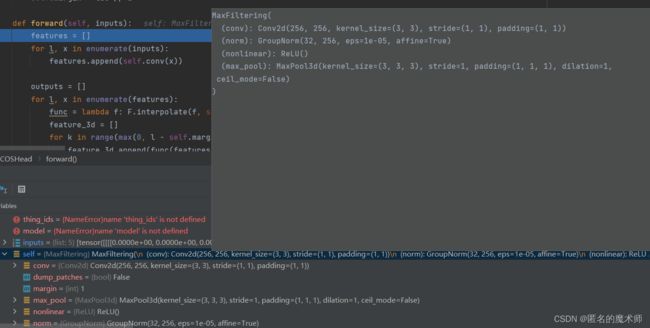
inputs

feature_3d ---(l=0, first)
![]()
---(second)

四、标签的建立
1. shifts的创建
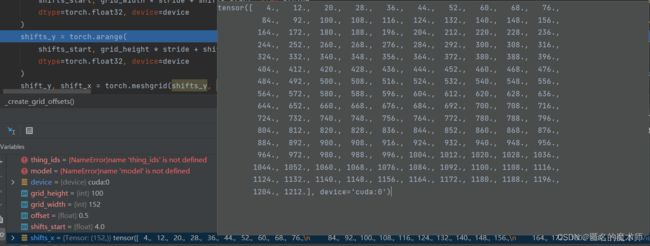
跳转到 cvpods/modeling/anchor_generator.py 中的ShiftGenerator类中的forward函数
self

1) _create_grid_offsets
sgifts_x
2. POTO 计算标签的质量
fcos.py ---262
quality = prob ** (1 - self.poto_alpha) * iou ** self.poto_alpha2) forward
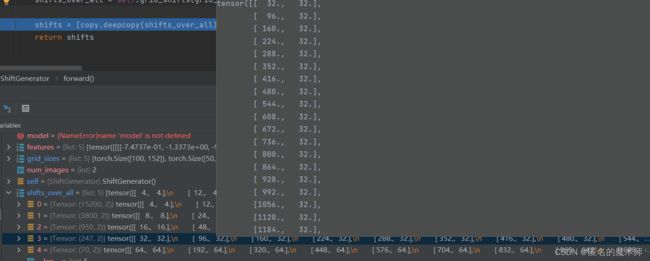
shifts_over_all

一维是x的一维是y的
target_per_image

get_boxes

prob

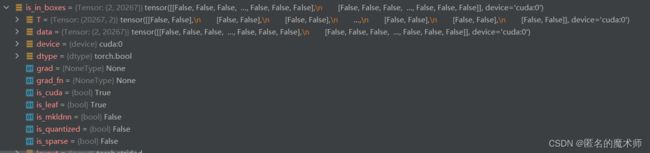
is_in_boxes
2.
def permute_to_N_HWA_K(tensor, K):
"""
Transpose/reshape a tensor from (N, (A x K), H, W) to (N, (HxWxA), K)
"""
assert tensor.dim() == 4, tensor.shape
N, _, H, W = tensor.shape
tensor = tensor.view(N, -1, K, H, W)
tensor = tensor.permute(0, 3, 4, 1, 2)
tensor = tensor.reshape(N, -1, K) # Size=(N,HWA,K)
return tensor传进来的参数 都是list:5,来自fpn的输出
![]()
box_cls最终的得分由 下面得到,它是通过sigmoid函数将输出得分转到0到1之间
box_cls = box_cls.sigmoid_() * box_filter.sigmoid_()3. 计算loss
gt_class
五、 与跟踪不同的地方
1. 回归标签的建立
因为 检测时直接resize,然后直接进行下采样,而跟踪需要以目标为中心进行裁剪,所以在设置标签时比检测时会多步骤,就是从裁剪的图片还原到原图片的过程。