SVM向量机
文章目录
-
- 1、SVM向量机
-
-
- 1.1、向量机简述
- 1.2、核函数简述
-
- 2、鸢尾花数据集
-
-
- 2.1、数据基础处理
- 2.2、多项式分类函数
- 2.3、高斯核方式
-
- 3、月亮数据集
-
-
- 3.1、多项式分类函数
- 3.2、高斯核方式
-
1、SVM向量机
1.1、向量机简述
1、简介: 支持向量机(support vector machine, SVM):是监督学习中最有影响力的方法之一。类似于逻辑回归,这个模型也是基于线性函数wTx+b的。不同于逻辑回归的是,支持向量机不输出概率,只输出类别。当wTx+b为正时,支持向量机预测属于正类。类似地,当wTx+b为负时,支持向量机预测属于负类。
2、工作原理:将数据映射到高维特征空间,这样即使数据不是线性可分,也可以对该数据点进行分类。
作用:进行线性分类之外,SVM还可以使用所谓的核技巧有效地进行非线性分类,将其输入隐式映射到高维特征空间中。
SVM对偶形式的求解公式为
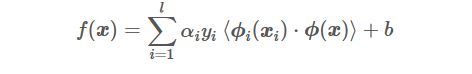
1.2、核函数简述
核函数原理:将原始非线性的样本通过非线性映射映射至高维特征空间,使得在新的空间里样本线性可分,进而可用线性样本的分类理论解决此类问题。
核函数:包括齐次多项式、非齐次多项式、双曲正切、高斯核(Gaussiankernel)、线性核、径向基函数(radialbasis function, RBF)核和、Sigmoid核。
优点 :
1)核函数的引入避免了“维数灾难”,大大减小了计算量。而输入空间的维数n对核
函数矩阵无影响,因此,核函数方法可以有效处理高维输入。
2)无需知道非线性变换函数Φ的形式和参数.
3)核函数的形式和参数的变化会隐式地改变从输入空间到特征空间的映射,进而对
特征空间的性质产生影响,最终改变各种核函数方法的性能。
4)核函数方法可以和不同的算法相结合,形成多种不同的基于核函数技术的方法,
且这两部分的设计可以单独进行,并可以为不同的应用选择不同的核函数和算法。
2、鸢尾花数据集
2.1、数据基础处理
1、导入相关包
import numpy as np
from sklearn import datasets #导入数据集
import matplotlib.pyplot as plt
from sklearn.preprocessing import StandardScaler
from matplotlib.colors import ListedColormap
2、绘制边界函数
import numpy as np
from sklearn import datasets #导入数据集
import matplotlib.pyplot as plt
from sklearn.preprocessing import StandardScaler
from matplotlib.colors import ListedColormap
3、导入测试数据并进行预处理
def plot_decision_boundary(model,axis):
x0,x1=np.meshgrid(
np.linspace(axis[0],axis[1],int((axis[1]-axis[0])*100)).reshape(-1,1),
np.linspace(axis[2],axis[3],int((axis[3]-axis[2])*100)).reshape(-1,1))
# meshgrid函数是从坐标向量中返回坐标矩阵
x_new=np.c_[x0.ravel(),x1.ravel()]
y_predict=model.predict(x_new)#获取预测值
zz=y_predict.reshape(x0.shape)
custom_cmap=ListedColormap(['#EF9A9A','#FFF59D'])
plt.contourf(x0,x1,zz,cmap=custom_cmap)
iris = datasets.load_iris()
data_x = iris.data[:, :2]
data_y = iris.target
scaler=StandardScaler()# 标准化
data_x = scaler.fit_transform(data_x)#计算训练数据的均值和方差
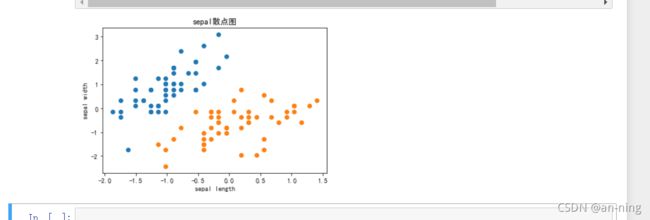
绘制基本鸢尾花数据集
plt.rcParams["font.sans-serif"] = ['SimHei'] # 用来正常显示中文标签,SimHei是字体名称,字体必须在系统中存在,字体的查看方式和安装第三部分
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.scatter(data_x[data_y==0, 0],data_x[data_y==0, 1]) # 选取y所有为0的+X的第一列
plt.scatter(data_x[data_y==1, 0],data_x[data_y==1, 1]) # 选取y所有为1的+X的第一列
plt.xlabel('sepal length') # 设置横坐标标注xlabel为sepal width
plt.ylabel('sepal width') # 设置纵坐标标注ylabel为sepal length
plt.title('sepal散点图') # 设置散点图的标题为sepal散点图
plt.show()
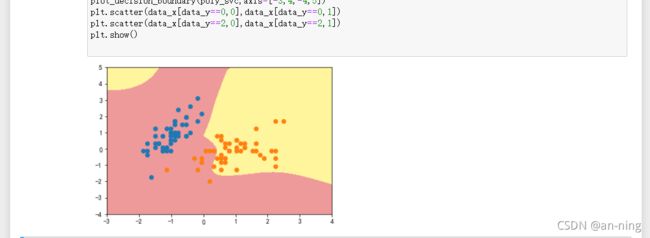
2.2、多项式分类函数
多项式核进行处理
from sklearn.preprocessing import PolynomialFeatures #导入多项式回归
from sklearn.pipeline import Pipeline #导入python里的管道
from sklearn.svm import LinearSVC
def PolynomialSVC(degree,c=5):#多项式svm
"""
:param d:阶数
:param C:正则化常数
:return:一个Pipeline实例
"""
return Pipeline([
# 将源数据 映射到 3阶多项式
("poly_features", PolynomialFeatures(degree=degree)),
# 标准化
("scaler", StandardScaler()),
# SVC线性分类器
("svm_clf", LinearSVC(C=c, loss="hinge", random_state=10,max_iter=100000))
])
poly_svc=PolynomialSVC(degree=5)
poly_svc.fit(data_x,data_y)
plot_decision_boundary(poly_svc,axis=[-3,4,-4,5])
plt.scatter(data_x[data_y==0,0],data_x[data_y==0,1])
plt.scatter(data_x[data_y==2,0],data_x[data_y==2,1])
plt.show()
2.3、高斯核方式
定义RBF核的SVM函数
y=1(只需要修改gamma的值即可)
from sklearn.svm import SVC #导入svm
def RBFKernelSVC(gamma=1.0):
return Pipeline([
('std_scaler',StandardScaler()),
('svc',SVC(kernel='rbf',gamma=gamma))
])
svc=RBFKernelSVC(gamma=42)#gamma参数很重要,gamma参数越大,支持向量越小
svc.fit(data_x,data_y)
plot_decision_boundary(svc,axis=[-3,3,-3,4])
plt.scatter(data_x[data_y==0,0],data_x[data_y==0,1])
plt.scatter(data_x[data_y==2,0],data_x[data_y==2,1])
plt.show()
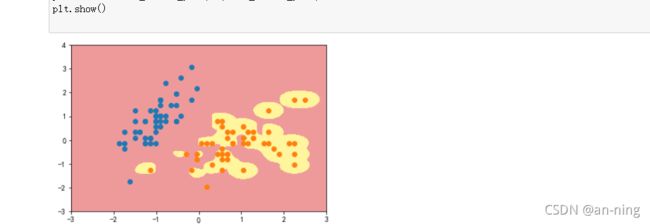
y=10
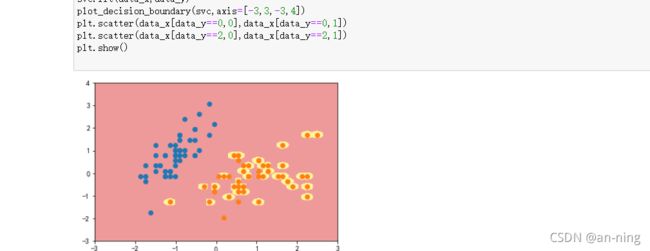
y=100
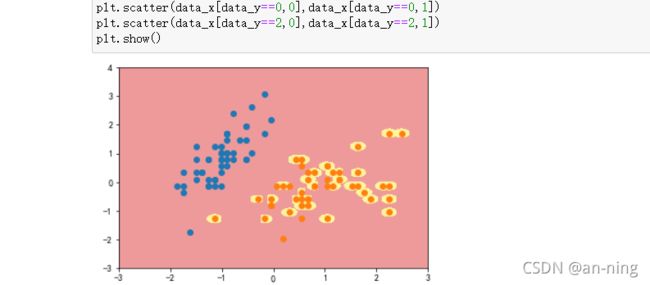
可以看到,γ 取值越大,就是高斯分布的钟形图越窄,这里相当于每个样本点都形成了钟形图。很明显这样是过拟合的
3、月亮数据集
3.1、多项式分类函数
1、导入需要的包和月亮数据集并进行处理可视化
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.preprocessing import PolynomialFeatures,StandardScaler
from sklearn.svm import LinearSVC
from sklearn.pipeline import Pipeline
from sklearn.svm import SVC
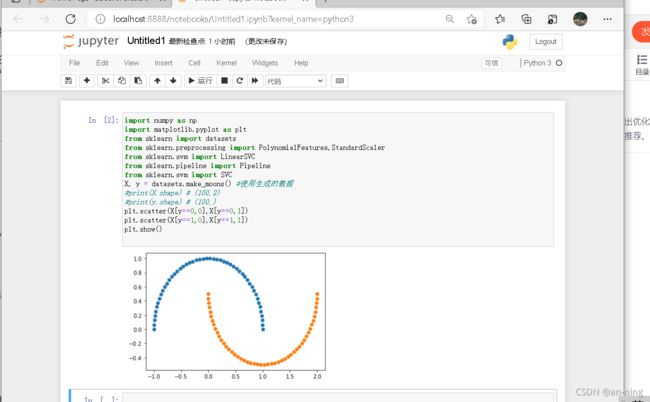
X, y = datasets.make_moons() #使用生成的数据
#print(X.shape) # (100,2)
#print(y.shape) # (100,)
plt.scatter(X[y==0,0],X[y==0,1])
plt.scatter(X[y==1,0],X[y==1,1])
plt.show()
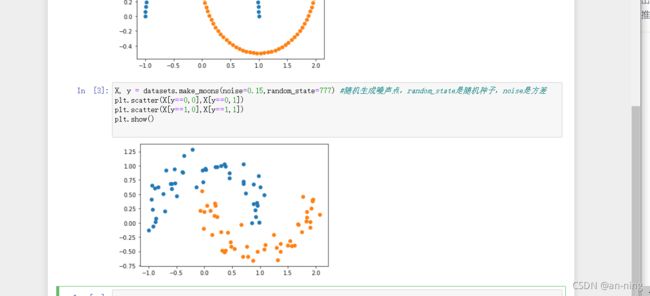
2、生成噪声点(数据集中的干扰数据(对场景描述不准确的数据),即测量变量中的随机误差或方差)并实现可视化。
X, y = datasets.make_moons(noise=0.15,random_state=777) #随机生成噪声点,random_state是随机种子,noise是方差
plt.scatter(X[y==0,0],X[y==0,1])
plt.scatter(X[y==1,0],X[y==1,1])
plt.show()
3、定义非线性SVM函数
def PolynomialSVC(degree,C=1.0):
return Pipeline([
("poly",PolynomialFeatures(degree=degree)),#生成多项式
("std_scaler",StandardScaler()),#标准化
("linearSVC",LinearSVC(C=C))#最后生成svm
])
5、调用PolynomialSVC函数进行分类可视化
调用非线性SVM分类,实例化SVC
# 边界绘制函数
def plot_decision_boundary(model,axis):
x0,x1=np.meshgrid(
np.linspace(axis[0],axis[1],int((axis[1]-axis[0])*100)).reshape(-1,1),
np.linspace(axis[2],axis[3],int((axis[3]-axis[2])*100)).reshape(-1,1))
# meshgrid函数是从坐标向量中返回坐标矩阵
x_new=np.c_[x0.ravel(),x1.ravel()]
y_predict=model.predict(x_new)#获取预测值
zz=y_predict.reshape(x0.shape)
custom_cmap=ListedColormap(['#EF9A9A','#FFF59D','#90CAF9'])
plt.contourf(x0,x1,zz,cmap=custom_cmap)
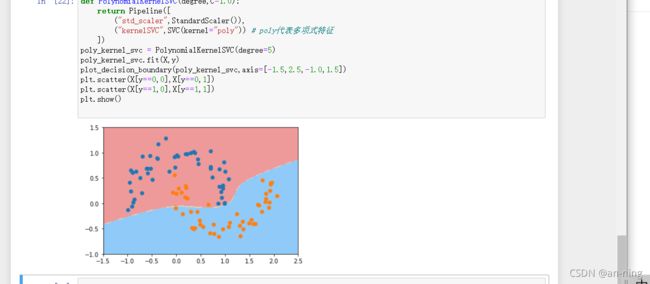
poly_svc = PolynomialSVC(degree=5)
poly_svc.fit(X,y)
plot_decision_boundary(poly_svc,axis=[-1.5,2.5,-1.0,1.5])
plt.scatter(X[y==0,0],X[y==0,1])
plt.scatter(X[y==1,0],X[y==1,1])
plt.show()
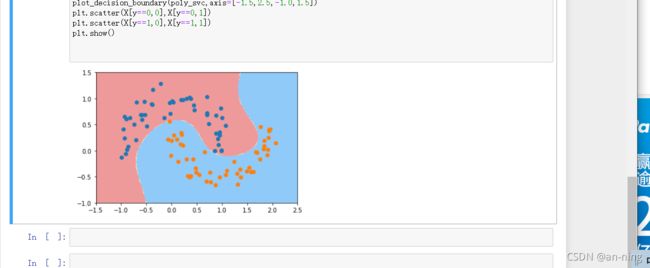
6、进行核处理
def PolynomialKernelSVC(degree,C=1.0):
return Pipeline([
("std_scaler",StandardScaler()),
("kernelSVC",SVC(kernel="poly")) # poly代表多项式特征
])
poly_kernel_svc = PolynomialKernelSVC(degree=5)
poly_kernel_svc.fit(X,y)
plot_decision_boundary(poly_kernel_svc,axis=[-1.5,2.5,-1.0,1.5])
plt.scatter(X[y==0,0],X[y==0,1])
plt.scatter(X[y==1,0],X[y==1,1])
plt.show()
可以看到已经非常接近线性了
3.2、高斯核方式
1、导入需要的包和月亮数据集并输出
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVC
from sklearn.pipeline import Pipeline
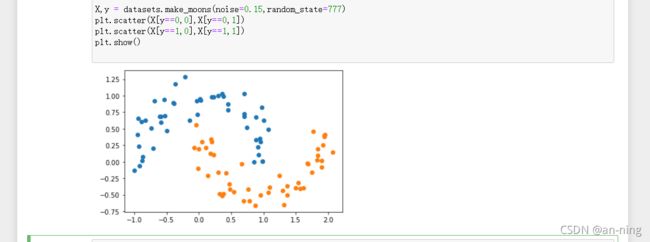
X,y = datasets.make_moons(noise=0.15,random_state=777)
plt.scatter(X[y==0,0],X[y==0,1])
plt.scatter(X[y==1,0],X[y==1,1])
plt.show()
2、定义RBF核的SVM函数
并且实例化向γ传递参
y=0.1:
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVC
from sklearn.pipeline import Pipeline
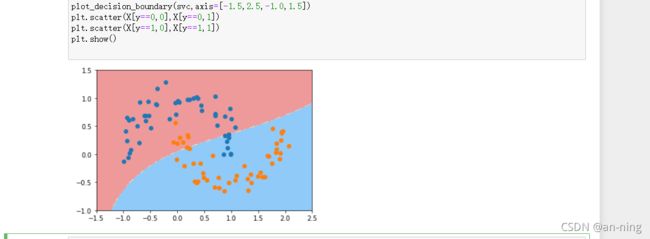
def RBFKernelSVC(gamma=0.1):
return Pipeline([ ('std_scaler',StandardScaler()), ('svc',SVC(kernel='rbf',gamma=gamma)) ])
svc = RBFKernelSVC()
svc.fit(X,y)
plot_decision_boundary(svc,axis=[-1.5,2.5,-1.0,1.5])
plt.scatter(X[y==0,0],X[y==0,1])
plt.scatter(X[y==1,0],X[y==1,1])
plt.show()
y=1(只需要修改gamma的值即可):
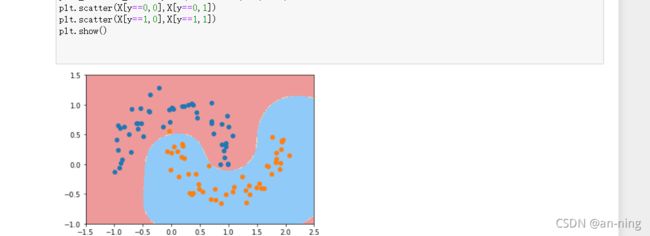
y=10:
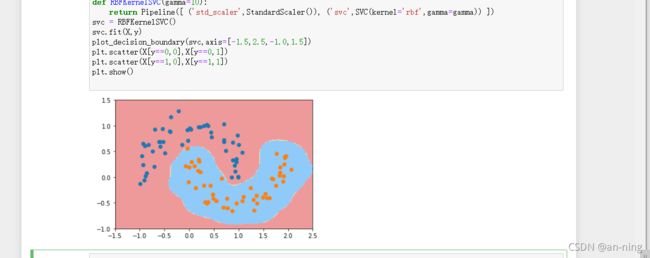
y=100:
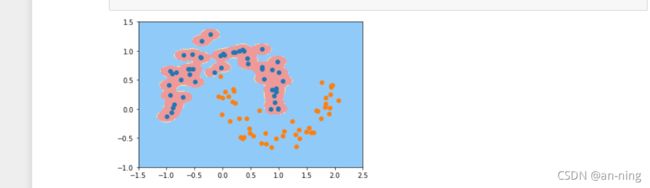
可以看到,γ 取值越大,就是高斯分布的钟形图越窄,这里相当于每个样本点都形成了钟形图。很明显这样是过拟合的
参考:
https://blog.csdn.net/fengbingchun/article/details/78326704
https://blog.csdn.net/weixin_47554309/article/details/121120120
https://blog.csdn.net/weixin_46129506/article/details/121100833