R语言初学者做完这100题,编程就像按计算器一样简单
众所周知,编程是一个工具,就好像工具箱里的锤子斧头一样。你不能仅仅通过看书,就能熟练掌握锤子斧头的使用方法,同样的,编程作为一个工具,也是需要经常拿在手里使用,才能熟练掌握,所以就有了这次的约稿。
我们发现,有很多非工科大类的本科高年级、研究生们,因为科研的需要,会猝不及防地被要求“学一下R”然后分分钟就要你火速上岗,使用这个编程工具干活。
而相对应的是,市面上,要不就是好几百页的书,要不就是2,30个视频的教程,非得拉着你讲来龙去脉,实在拖沓。
结合以上2点,我们给出了新的解决方案:使用ModelWhale工具,开箱即用,直接100题上手R语言,在练中学,学完就成熟练工!
直接运行请点击如下链接:
100题带你上手R语言基本操作 https://www.heywhale.com/mw/project/6131fb0bbc40120017e9cec7
https://www.heywhale.com/mw/project/6131fb0bbc40120017e9cec7
第一部分:R的数据结构
参考配套知识点的第一章,想了解更全面的知识点,可以看这【R语言知识点详细总结】中的第一章 R的数据结构;
1.定义值为4的一个向量
x <- 4 #也可用=赋值 print(x)2.查看向量x的数据类型
typeof(x)3.判断x是否是一个向量
is.vector(x)4.定义多个元素向量:包含88,5,12,13
y <- c(88,5,12,13)
print(y)
print(typeof(y))
print(is.vector(y))5.创建一个包含从1到5的向量
# 方法一:c()函数
x1 <- c(1,2,3,4,5)
print(x1)
# 方法二:运算符创建向量
x2 <- 1:5
print(x2)6.创建一个从12到30步长为3的向量
seq(from = 12, to = 30, by = 3)7.创建一个从1.1到2长度为10的向量
seq(from=1.1, to=2, length=10)8.创建包含4个8的向量
# 方法一:reo()函数
rep(8,4)
# 方法二:c()函数
c(8,8,8,8)9.在索引为4的位置上对y向量添加元素168
y <- c(y[1:3], 168, y[4])
print(y)10.从索引为4的位置上对y向量添加多个元素(56,24,35,10,5,7)
y <- c(y[1:3], c(56,24,35,10,5,7), y[4])
print(y)11.获取y向量的长度
length(y)12.计算c(1,2,4)和c(5,0,-1)的加减乘除后的结果
c(1,2,4) + c(5,0,-1)
c(1,2,4) - c(5,0,-1)
c(1,2,4) * c(5,0,-1)
c(1,2,4) / c(5,0,-1)13.访问y向量的第2个元素
y[2]14.访问y向量的第2个到第4个元素
y[2:4]15.将y向量的第2个到第4个元素修改为(8,14,67)
print(y)
y[2:4] = c(8,14,67)
print(y)16.访问y向量除了前3个元素外的其他元素
print(y)
print(y[-c(1:3)])
# 或者
b=(1:3)
y[-b]17.如下列,创建一个矩阵
> X = c(1,1,1)
> Y = c(2,2,2)
> temp = c(14.7,18.5,25.9)
> RH = c(66,73,41)
> wind = c(2.7,8.5,3.6)
> rain = c(0,0,0)
> area = c(0,0,0)
> rank = c(1,2,3)
X = c(1,1,1)
Y = c(2,2,2)
temp = c(14.7,18.5,25.9)
RH = c(66,73,41)
wind = c(2.7,8.5,3.6)
rain = c(0,0,0)
area = c(0,0,0)
rank = c(1,2,3)
ForeData = cbind(X,Y,temp,RH,wind,rain,area,rank)
print(ForeData)
print(is.matrix(ForeData)) # 判断是否为矩阵18.给出向量c(1,2,3,11,12,13),创建2行3列的矩阵,行命名为(row1, row2), 列命名为(C.1, C.2, C.3)
mdat <- matrix(c(1,2,3,11,12,13), nrow = 2, ncol = 3, byrow = TRUE, dimnames = list(c("row1", "row2"), c("C.1", "C.2", "C.3")))
print(mdat)19.先创建2行2列的空矩阵,然后按照列的方式依次给每个位置赋值1,2,3,4
x = matrix(nrow = 2, ncol = 2) # 注意:不能写成matrix(2,3)
x[1,1] = 1
x[2,1] = 2
x[1,2] = 3
x[2,2] = 4
print(x)20.对上述创建的x矩阵的行列进行重命名,行命名为('1', '2'),列命名为('a', 'b')
colnames(x) = c('a','b')
rownames(x) = c('1','2')
print(x)21.访问ForeData矩阵的第2行第3列的元素
print(ForeData[2,3])22.访问ForeData矩阵的第1到2行,第1到3列的元素
print(ForeData[1:2, 1:3])23.访问ForeData矩阵的第1到2行,第1列和第3列的元素(注意与22题的区别)
print(ForeData[1:2, c(1,3)])24.定义一个4行5列的三维数组,数值为1:60, 行命名为c('R1','R2','R3','R4'),列命名为c('C1','C2','C3','C4','C5'),维度命名为c('T1','T2','T3')
a = c(1:60)
dim1 = c('R1','R2','R3','R4')
dim2 = c('C1','C2','C3','C4','C5')
dim3 = c('T1','T2','T3')
f = array(a,c(4,5,3),dimnames = list(dim1,dim2,dim3))
print(f)25.根据下面给定的列,创建一个数据框
> X = c(1,1,1)
> Y = c(2,2,2)
> temp = c(14.7,18.5,25.9)
> RH = c(66,73,41)
> wind = c(2.7,8.5,3.6)
> rain = c(0,0,0)
> area = c(0,0,0)
> month = c('aug','aug','aug')
> day = c('fri','fri','fri')
X = c(1,1,1)
Y = c(2,2,2)
temp = c(14.7,18.5,25.9)
RH = c(66,73,41)
wind = c(2.7,8.5,3.6)
rain = c(0,0,0)
area = c(0,0,0)
month = c('aug','aug','aug')
day = c('fri','fri','fri')
ForeDataFrm = data.frame(FX = X,FY = Y, Fmonth = month,Fday = day, Ftemp = temp,FRH = RH,Fwind = wind, Frain = rain, Farea = area)
print(ForeDataFrm)26.查看ForeDataFrm数据框的列名
names(ForeDataFrm)27.判断ForeDataFrm是否是数据框类型
is.data.frame(ForeDataFrm)28.访问ForeDataFrm数据框的第1列和第3列
# 方法一:
print(ForeDataFrm[,c(1,3)])
# 方法二:
print(ForeDataFrm[,c('FX','Fmonth')])29.访问ForeDataFrm中Fwind这一列
# 方法一:
ForeDataFrm$Fwind
# 方法二:
ForeDataFrm[['Fwind']]
# 方法三:
ForeDataFrm[[7]]30.判断a=123.4和b='123.4'是否为数值型,整数型,字符串型,布尔型
a <- 123.4
is.numeric(a)
is.integer(a)
is.character(a)
is.logical(a)
b <- "123.4"
is.numeric(b)
is.integer(b)
is.character(b)
is.logical(b)31.查看向量a和b的数据类型
typeof(a)
typeof(b)32.将a转换为字符串类型,将b转换为浮点型
a <- as.character(a)
b <- as.double(b)
typeof(a)
typeof(b)33.将e = c(1:10)向量转换为矩阵
e <- c(1:10)
f <- as.matrix(e)
print(f)第二部分:数据的导入
参考配套知识点的第二章,想了解更全面的知识点,可以看这【R语言知识点详细总结】中的第二章 数据的导入;这里只是以txt的导入为例,如果想看更多的文件导入方式,可以看下配套知识点的第二章,里面有更多格式的文件导入方式;
34.读取ReportCard1.txt和ReportCard2.txt文件到数据框
ReportCard1 = read.table(file='ReportCard1.txt', header=TRUE)
ReportCard2 = read.table(file='ReportCard2.txt', header=TRUE)
names(ReportCard1)
names(ReportCard2)第三部分:R的数据管理
参考配套知识点的第三章,想了解更全面的知识点,可以看这【R语言知识点详细总结】中的第三章 R的数据管理;
35.按照学号xh字段合并ReportCard1和ReportCard2
ReportCard = merge(ReportCard1, ReportCard2, by = 'xh')
print(head(ReportCard))36.ReportCard按照math字段进行降序排列
Ord = order(ReportCard$math, na.last = TRUE, decreasing = TRUE)
print(Ord) # Ord为位置向量,1号学生的数学成绩最高,3号学生的数学成绩最低或者为缺失值
# 如果想在数据框中按照这种顺序排列
a = ReportCard[Ord,]
print(head(a))37.查询ReportCard中math字段存在缺失值的行
a = is.na(ReportCard$math)
print(ReportCard[a,])38.查询ReportCard中存在缺失值的行
a = complete.cases(ReportCard)
print(ReportCard[!a,])39.对于ReportCard数据框生成缺失数据报告
install.packages("mice")
library(mice)
print(md.pattern(ReportCard))40.计算以2为底10的对数的平方根,并保留3位小数位数
round(sqrt(log(10,2)),digits=3)41.计算向量y的平均值,中位数,标准差,方差,最大最小值
mean(y) # 中位数
median(y)
sd(y)
var(y)
max(y)
min(y)42.根据ReportCard中学生的各门成绩计算每个学生的总分和平均分
attach(ReportCard)#访问数据框中域访问
SumScore = poli + chi + math + fore + phy + che + geo + his
detach(ReportCard)
AvScore = SumScore/8#计算平均值
ReportCard$sumScore = SumScore
ReportCard$avScore = AvScore
sum(is.na(ReportCard$sumScore))#计算总分为缺失值的观测值的观测样本数
mean(complete.cases(ReportCard))#计算完整观测样本的比率43.计算向量y的和,累计和,连乘积
sum(y)
cumsum(y)
prod(y)44.以ReportCard中的math字段值、均值、标准差生成标准正态分布
a = is.na(ReportCard$math)
math = ReportCard$math
math = math[!a]
dnorm(math,mean(math),sd(math))45."You like R. So do I":去掉So do I,空格换成_,所有字母大写
str = "You like R. So do I"
str_1 = strsplit(str,'S')[[1]] # 注:列表名$域名 或者 列表名[ [‘域名’] ] 或者 列表框[[域编号]]
str_2 = sub(' ', '_', sub(' ', '_', str_1[1])) # 为什么嵌套:sub好像只能替换第一个
str_3 = toupper(str_2)
print(str_3)46.生成一个4行4列的单位矩阵
print(diag(4))47.生成2个2行2列的矩阵m和n,一个值全是1,一个值全是2
m = matrix(1, nrow=2, ncol=2)
n = matrix(2, nrow=2, ncol=2)
print(m)
print(n)48.计算矩阵m和矩阵n相乘后的结果mn,并输出正对角元素值
mn = m %*% n
print(mn)
print(diag(mn)) 49.以1:9按照列优先方式生成3行3列的矩阵mm,并求该矩阵的转置矩阵
mm = matrix(1:9, nrow=3, ncol=3, byrow=TRUE)
print(mm)
print('转置后的矩阵:')
print(t(mm))50.求上一步生成的mm矩阵的特征值和特征向量
eigen(mm)51.将ReportCard中学生成绩的平均成绩分为A,B,C,D,E 5个等级 A :大于等于90分; B:大于等于80分,小于90分; C:大于等于70分,小于80分; D:大于等于60分,小于70分; E:小于60分;
attach(ReportCard)#访问数据框中域访问
SumScore = poli + chi + math + fore + phy + che + geo + his
detach(ReportCard)
AvScore = SumScore/8#计算平均值
ReportCard$sumScore = SumScore
ReportCard$avScore = AvScore
# 通过使用within和逻辑运算符将学生平均成绩分为5个级别
ReportCard = within(ReportCard,{
avScore[avScore>= 90] = 'A'
avScore[avScore>= 80 & avScore < 90] = 'B'
avScore[avScore>= 70 & avScore < 80] = 'C'
avScore[avScore>= 60 & avScore < 70] = 'D'
avScore[avScore < 60] = 'E'
})
# 下面通过%in%包含函数,找出非正常项
flag = ReportCard$avScore %in% c('A',"B","C","D","E")
# 通过使用flag标记,将非正常的标记为缺失值
ReportCard$avScore[!flag] = NA
# 输出平均成绩等级
print(ReportCard$avScore)52.将ReportCard中sex字段值1和2,替换成'M'和'F' 'M'表示男性; 'F'表示女性;
ReportCard$sex = factor(ReportCard$sex, levels = c(1,2), labels = c("M","F"))
str(ReportCard$sex)
print(head(ReportCard))53.对于ReportCard,筛选出性别为M,平均等级为E的样本
MaleScore = subset(ReportCard, ReportCard$sex == 'M' & ReportCard$avScore == 'E')
print(MaleScore)54.从ReportCard中随机抽取10位同学的数据
xh = sample(ReportCard$xh, size = 10, replace = FALSE)
sample_s = ReportCard[ReportCard$xh %in% xh,]
print(sample_s)55.分别使用repeat和for循环依次打印50以内的6的倍数
# repeat循环
i = 6
repeat{ if(i > 50) break else {print(i); i = i + 6}}
# for循环
for(i in seq(from = 6, to = 50, by = 6))
print(i)第四部分:R的基本数据分析
参考配套知识点的第四章,想了解更全面的知识点,可以看这【R语言知识点详细总结】中的第四章 R的基本数据分析;
56.计算ReportCard中所有字段的基本描述统计量
summary(ReportCard)57.计算ReportCard中学生所有课程考试成绩的均值和标准差
Av.Course = sapply(ReportCard[,3:10], FUN = mean, na.rm = TRUE) # 均值
Sd.Course = sapply(ReportCard[,3:10],FUN = sd, na.rm = TRUE) # 方差
print(Av.Course)
print(Sd.Course)58.计算ReportCard中各科的平均分和总分
Av.Course = colMeans(ReportCard[,3:10],na.rm = TRUE) # 各科平均分
Sums.Course = colSums(ReportCard[,3:10],na.rm = TRUE) # 各科总分
print(Av.Course)
print(Sums.Course)59.计算ReportCard中每名学生所有科目的平均分和总分
Av.Person = rowMeans(ReportCard[,3:10],na.rm = TRUE)
Sum.Person = rowSums(ReportCard[,3:10],na.rm = TRUE)
print(Av.Person)
print(Sum.Person)60.计算ReportCard中女生各科成绩的平均值
#抽取女生的数据
FeMaleCard = subset(ReportCard,ReportCard$sex == "F")
#求女生各科成绩的平均值
Des.FeMale = sapply(FeMaleCard[3:10],FUN = mean,na.rm = TRUE)
print(Des.FeMale)61.分性别计算学生政治课考试成绩的基本描述
Des.Gender = tapply(ReportCard$poli,INDEX = ReportCard$sex,FUN = summary,na.rm = TRUE)
print(Des.Gender)62.计算学生数学、物理、化学的简单相关矩阵
Tmp = ReportCard[complete.cases(ReportCard),]
CorMatrix = cor(Tmp[,c(5,7,8)],use = "everything",method = "pearson")
print(CorMatrix)63.基于学生的数学、物理成绩的简单相关系数进行相关系数检验
Tmp = ReportCard[complete.cases(ReportCard),]
cor.test(Tmp[,5],Tmp[,7],alternative = "two.side",method = "pearson")64.在性别和平均成绩等级列联表的基础上,分析学生性别和平均成绩等级两个变量之间是否独立
CrossTable = table(ReportCard[,c(2,12)]) chisq.test(CrossTable)第五部分:R的数据可视化
参考配套知识点的第五章,想了解更全面的知识点,可以看这【R语言知识点详细总结】中的第五章 R的数据可视化;
65.读取ForestData.txt文件到Forest数据框
Forest = read.table(file='/home/mw/input/wlong6309/ForestData.txt', header = TRUE, sep = "")
print(head(Forest))66.对Forest中的temp字段值绘制茎叶图
stem(Forest$temp)67.对Forest中的temp和month字段,绘制各月温度的箱线图

Forest$month = factor(Forest$month,levels = c("jan","feb","mar","apr","may","jun","jul","aug","sep","oct","nov","dec"))
boxplot(temp~month,data = Forest,main = "森林地区各月温度箱线图")68.对Forest中的temp字段,绘制森林地区温度直方图
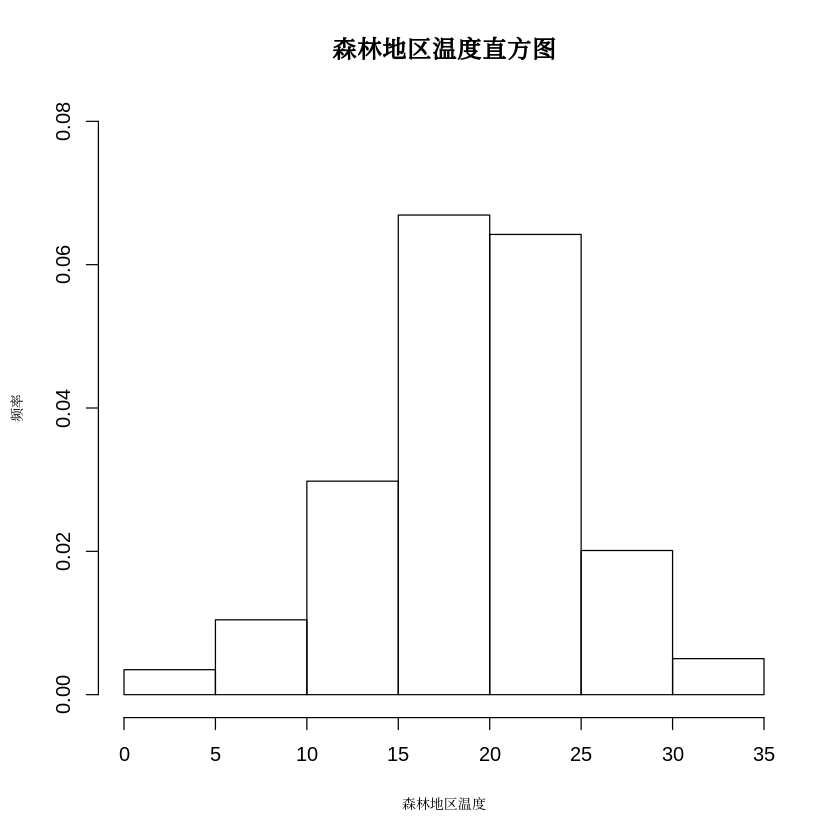
hist(Forest$temp,xlab = "森林地区温度",ylab = "频率",main = "森林地区温度直方图",cex.lab = 0.7,freq = FALSE,ylim = c(0,0.08))
69.对ReportCard中平均成绩等级(ABCDE)和人数绘制条形图
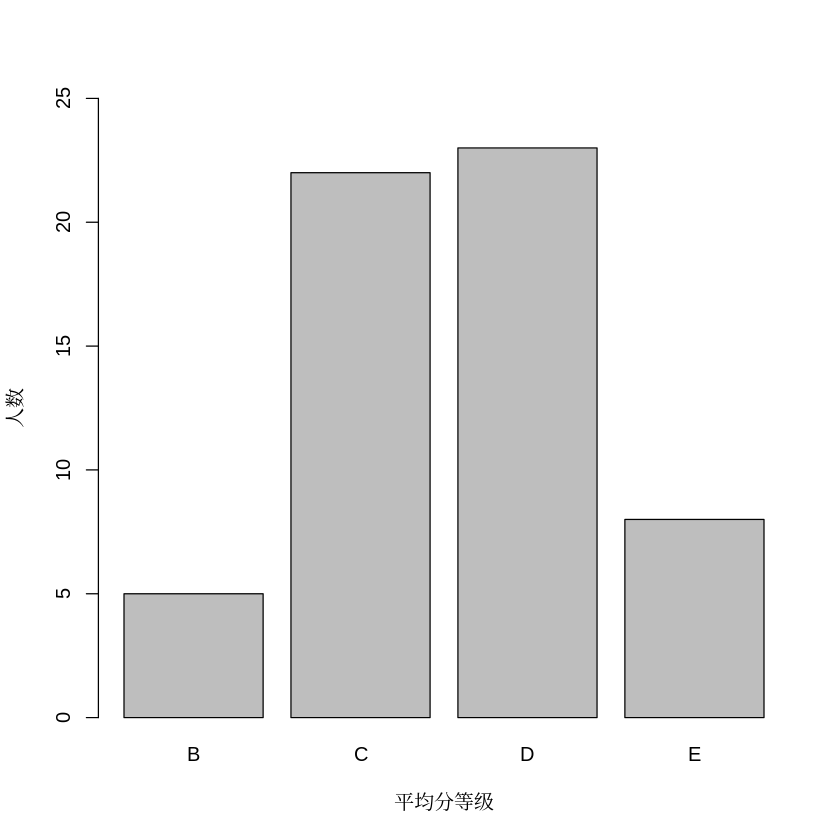
NumGrade = tapply(ReportCard$avScore,INDEX = ReportCard$avScore,FUN = length)
barplot(NumGrade,xlab = "平均分等级",ylab = "人数",ylim = c(0,25))70.对ReportCard中平均成绩等级(ABCDE)和人数绘制饼图

Pct = round(NumGrade/length(ReportCard$avScore)*100,2)
GLabs = paste(c("B","C","D","E"),Pct,"%",sep = "")
pie(NumGrade,labels = GLabs,cex = 0.8,main = "平均分等级饼图",cex.main = 0.8)
71.对Forest中温度temp和湿度RH两个字段,以tremp为x轴以RH为y轴绘制散点图
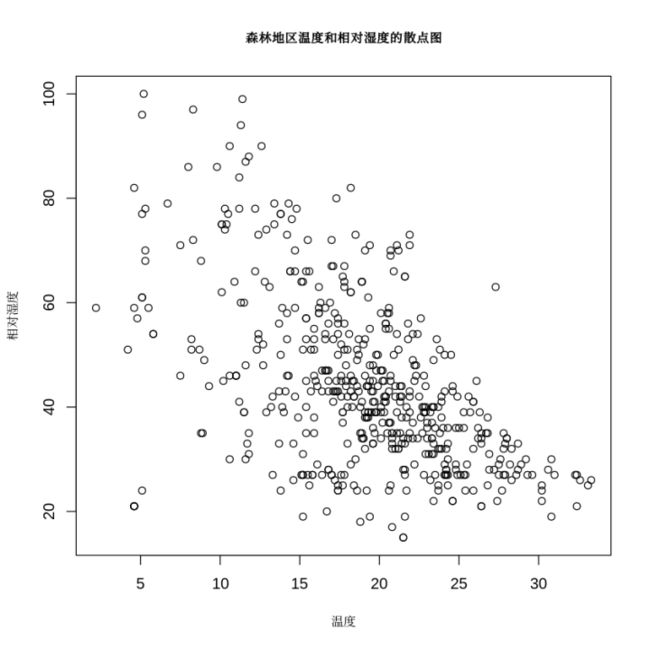
plot(Forest$temp,Forest$RH,main = "森林地区温度和相对湿度的散点图",xlab = "温度",ylab = "相对湿度",cex.main = 0.8,cex.lab = 0.8)
72.对于Forest森林数据,温度和相对湿度的简单散点图,以及添加方法求解回归线的散点图
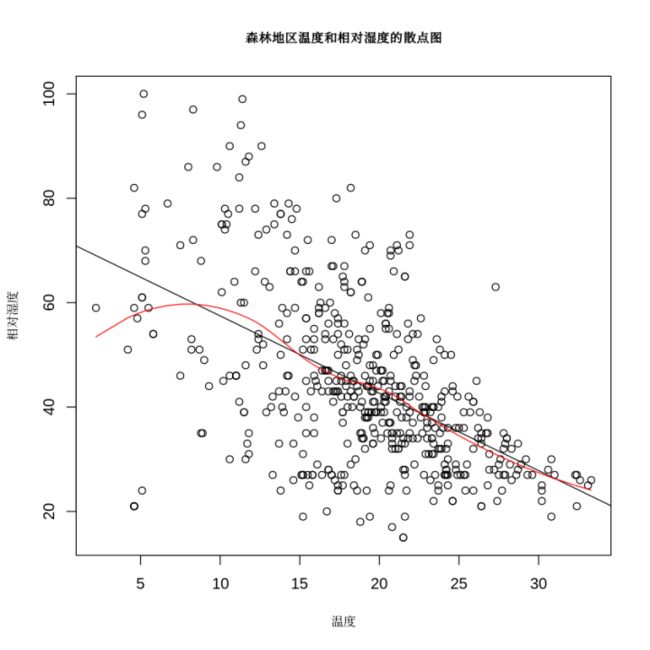
plot(Forest$temp,Forest$RH,main = "森林地区温度和相对湿度的散点图",xlab = "温度",ylab = "相对湿度",cex.main = 0.8,cex.lab = 0.8)
M0 = lm(RH~temp,data = Forest)
abline(M0$coefficients)
M.Loess = loess(RH~temp,data = Forest)
Ord = order(Forest$temp)
lines(Forest$temp[Ord],M.Loess$fitted[Ord],lwd = 1,lty = 1,col = 2)73.对Forest森林数据,绘制温度和相对湿度以及风力的三维散点图

install.packages("scatterplot3d")
library("scatterplot3d")
with(Forest,scatterplot3d(temp,RH,wind,main="森林地区温度、相对湿度和风力的三维散点图",xlab="温度",ylab="相对湿度",zlab="风力",cex.main=0.7,cex.lab=0.7,cex.axis=0.7))74.对ReportCard数据,绘制学生各门课程考试成绩的相关系数图

install.packages("corrgram")
library("corrgram")
corrgram(ReportCard[,3:10],lower.panel=panel.shade,upper.panel=panel.pie,text.panel=panel.txt,main="成绩的相关系数图")第六部分:R的统计分析
参考配套知识点的第六章,想了解更全面的知识点,可以看这【R语言知识点详细总结】中的第六章 R的统计分析;
75.下表给出了28位学生某门课程的成绩数据,问80分是否可以作为学生成绩的3/4分位数?显著性水平=0.01

# 采用非参数检验中的符号检验
x <- c(95,89,68,90,88,60,81,67,60,60,60,63,60,92,60,88,88,87,60,73,60,97,91,60,83,87,81,90)
binom.test(min(sum(x>80),sum(x<80)),sum(x!=80), 0.75)76.某网站收集了19家大型公司CEO邮箱里每天收到的垃圾邮件件数,得到如下数据(单位:封),问:垃圾邮件数量的中心位置是否超过了320封?
310 350 370 377 389 400 415 425 440 295 325 296 250 340 298 365 375 360 385
# 采用Wilcoxon符号秩检验
spamail <- c(310,350,370,377,380,400,415,425,440,295,325,296,250,340,298,365,375,360,385)
wilcox.test(spamail,320,alt='great',conf.int=TRUE)77.今测得10名非铅作业工人和7名铅作业工人的血铅值如下表所示,试用Wilcoxon秩和检验分析两组工人血铅值有无差异。

# Wilcoxon秩和检验
x <- c(24,26,29,34,43,58,63,72,87,101)
y <- c(82,87,97,121,164,208,213)
# 不采用连续性修正
wilcox.test(x,y,alternative="less",exact=FALSE,correct=FALSE)78.为研究血型与肝病之间的关系,调查295名肝病患者及638名非肝病患者(对照组)不同血型的得病情况,如下表所示,问血型与肝病之间是否存在着关联?

# 卡方独立性检验
x <- c(98,67,13,18,38,41,8,12,289,262,57,30)
dim(x)<- c(4,3)
chisq.test(x)79.为了解某种药物的治疗效果,采集药物A与B的疗效数据整理成二维列联表如下,检验药物与疗效的独立性。
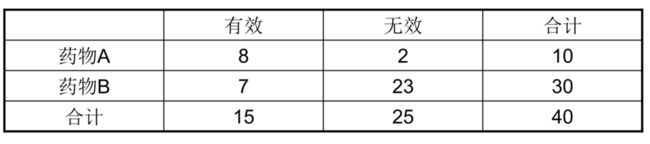
# Fisher精确性检验
medicine<-matrix(c(8,7,2,23),2,2)
fisher.test(medicine)80.为研究4种不同药物对儿童咳嗽的治疗效果,将25个体质相似的病人随机分为4组,分别采用A、B、C、D 4种药物进行治疗,5天后测量每个病人每天的咳嗽次数如下表所示,试比较这4种药物的治疗效果是否相同?
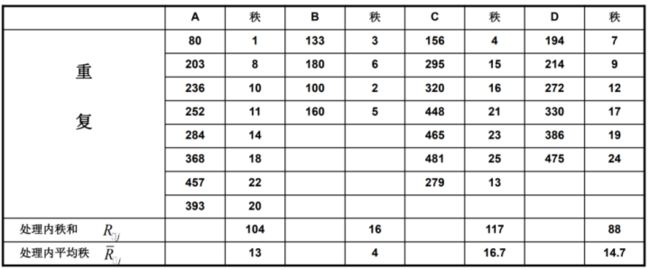
# 多组数据位置推断—Kruskal-wallis检验
drug <- c(80,203,236,252,284,368,457,393,133,180,100,160,156,295,320,448,465,481,279,194,214,272,330,386,475)
gr.drug<-c(1,1,1,1,1,1,1,1,2,2,2,2,3,3,3,3,3,3,3,4,4,4,4,4,4)
kruskal.test(drug,gr.drug)81.设有来自A,B,C,D4个地区的四名厨师制作京城水煮鱼,为了比较他们的品质是否相同,经四位美食评委评分结果如下表所示,试测试4个地区制作的水煮鱼这道菜的品质有无区别。
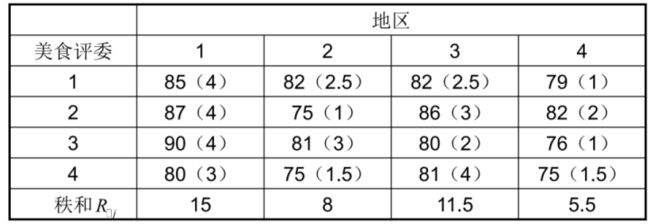
# 多组数据位置推断—Friedman检验
beijingfish <- c(85,82,82,79,87,75,86,82,90,81,80,76,80,75,81,75)
treat.BF <- c(1,2,3,4,1,2,3,4,1,2,3,4,1,2,3,4)
block.BF <- c(1,1,1,1,2,2,2,2,3,3,3,3,4,4,4,4)
friedman.test(beijingfish,treat.BF,block.BF)82.现收集了某大学部分学生一年级英语期末成绩,与其高考英语成绩进行比较,调查12位学生的结果如下表,试检验学生中学的学习成绩与大学学习成绩有相关关系。

x <- c(65,79,67,66,89,85,84,73,88,80,86,75)
y <- c(62,66,50,68,88,86,64,62,92,64,81,80)
cor.test(x,y) #pearson相关性检验
cor.test(x,y,meth='spearman') # spearman相关系数
cor.test(x,y,meth='kendall') # kendall相关系数82.给出两个向量x和y如下,做一元线性回归分析
x:318,910,200,409,425,502,314,1210,1022,1225
y:524,1019,638,815,913,928,605,1516,1219,1624
x<-c(318,910,200,409,425,502,314,1210,1022,1225)
y<-c(524,1019,638,815,913,928,605,1516,1219,1624)
plot(x,y)
lm.reg<-lm(y~1+x)
summary(lm.reg)
op=par(mfrow=c(2,2))
plot(lm.reg)#产生四个图,分别是:1 residual vs fitted;2 Normal QQ-plot;3 scale-location; 4 cook’s distance.
par(op)
# 求预测值和预测区间
point <- data.frame(x=425)
lm.pred <- predict(lm.reg,point,interval='prediction',level=0.95)
print(lm.pred)第七部分:随机考察题
83.计算从1加到100,至少采用3种不同的方法
#从1加到100
#方法1:for循环
sum1=0
for(i in seq (from=1, to=100,by=1) ) sum1=sum1+i
print(sum1)
#方法2:repeat循环
i=0
sum2=0
repeat{if(i>100) break else {sum2=sum2+i; i=i+1}}
print(sum2)
#方法3:while循环
sum3=0
i=0
while(i<=100){ sum3=sum3+i; i=i+1}
print(sum3)
#方法4 : sum函数
print(sum(c(1:100)))84.计算从1的平方加到100的平方,至少采用3种方法
#从1的平方加到100的平方
#方法1:for函数
sum4=0
for(i in seq (from=1, to=100, by=1) ) sum4=sum4+i^2
print(sum4)
#方法2:repeat循环
i=0
sum5=0
repeat{if(i>100)break else { sum5=sum5+i^2; i=i+1}}
print(sum5)
#方法3:while循环
sum6=0
i=0
while (i<=100){ sum6=sum6+i^2; i=i+1}
print(sum6)
#方法4: sum函数
print(sum(c((1:100)^2)))85.创建[1,100]之间所有奇数组成的向量
t = seq(from=1, to=100, by=2) #从1到100,间隔为2,输出数
print(t)86.将长度为200的数值型向量t中第5个元素删除,并在此位置中添加元素11和21;
t = c(1:200)
t = t[-5] #删除第5个元素
t = c(t[1:4], 11, 21, t[5:199]) #在第五个元素的位置上,添加11,21两个数
print(t)87.将1到24构成的自然数序列构建为行数为3、列数为4、组数为2的数组并访问第二组数据;
y = c(1:24)
t = array(y, c(3,4,2)) #访问第二组数据
print(t)88.使用以下向量作为数据框的列,创建一个数据框。并访问temp这一列;
X = c(1,1,1)
Y = c(2,2,2)
temp = c(14.7,18.5,25.9)
RH = c(66,73,41)
X = c(1,1,1)
Y = c(2,2,2)
temp = c(14.7,18.5,25.9)
RH = c(66,73,41)
data = data.frame(X,Y,temp,RH) #定义数据框
print(data)
print(data[,'temp'] ) #访问temp列,或者也可以写成data[,3]89.设置随机种子,随机生成服从标准正态分布函数的100个数字;
set.seed(100)
y = rnorm(100,0,1)#生成100个标准正态分布的100个数
print(y)90.将y从小到大排序,然后用排好的值,做出其正态分布密度图;
y = sort(y)#将y中的数值进行排序
print(y)
plot(y, dnorm(y, 0, 1), type="l", main="正态分布密度图") #生成正态分布密度图91.请利用R代码编写一函数程序如下,并计算f(5)
![]()
#首先,定义一个f函数
f = function(n){
sum = 0 #定义一个sum,存储总和
for(i in 1:n) sum = sum + i^3 #定义一个for循环,依次将n个数的立方求和
return(sum) #返回求和后的数
}
f(5) #当n为5时,调用f函数,结果为22592.用R来计算以下公式,并保留两位小数;
![]()
round(abs(exp(1)-exp(2))^(1/3),2)93.求向量x=c(3:95)的均值、中位数、标准差、方差、最大值、最小值、向量长度以及向量的各个元素的和;
x=c(3:95)
mean(x)
median(x)
sd(x)
var(x)
max(x)
min(x)
length(x)
sum(x)94.将ReportCard1.txt和ReportCard2.txt这两个文件读取并保存在Reportcard1和Reportcard2两个变量中;使用merge函数以“xh”为关键字,将两个文件合并,并保存到Reportcard变量中。
Reportcard1 = read.table("/home/mw/input/wlong6309/ReportCard1.txt",header=T)
Reportcard2 = read.table("/home/mw/input/wlong6309/ReportCard2.txt",header=T)
Reportcard = merge(Reportcard1,Reportcard2,by='xh')
print(head(Reportcard))95.将Reportcard中的缺失值删除
Reportcard = na.omit(Reportcard)
print(head(Reportcard))96.将Reportcard中的性别重新编码,将其中的1用M替代,2由F替代
Reportcard$sex = factor(Reportcard$sex, levels=c(1,2),labels=c("M","F"))
Reportcard$sex97.在数据框Reportcard中计算每条学生的总成绩和平均成绩。其中总成绩用变量(Sumscore),平均成绩用(Avscore)
SumScore = rowSums(Reportcard[, 3:10], na.rm=TRUE)
Reportcard$SumScore = SumScore
AvScore = rowMeans(Reportcard[, 3:10], na.rm=TRUE)
Reportcard$AvScore = AvScore
print(head(Reportcard))98.以Avscore为标准将成绩划分称等级(A,B,C,D,E),并将重新编码的变量存储avscore变量中,然后用柱状图查看该班学生成绩等级的分布情况 ,其中(大于等于90分为A,大于等于80并小于90分为B,大于等于70分并小于80分为C,大于等于60分并小于70分为D,小于60分为E)
Reportcard = within(Reportcard,{
AvScore[AvScore>=90] = 'A'
AvScore[AvScore>=80 & AvScore<90] = 'B'
AvScore[AvScore>=70 & AvScore<80] = 'C'
AvScore[AvScore>=60 & AvScore<70] = 'D'
AvScore[AvScore<60] = 'E'
})
avScore = Reportcard[,12]#将重新编码的数据保存到avScore中
print(avScore)
n=table(Reportcard$AvScore)
barplot(n,ylim=c(0,25)) #生成柱状图99.以1:6按照列的顺序生成2行3列的数据,并计算每行每列的最大最小值
data = matrix(c(1,2,3,4,5,6), nrow=2)
row_max = c()
row_min = c()
col_max = c()
col_min = c()
for(i in 1:nrow(data))
{
row_max = c(row_max, max(data[i,]))
row_min = c(row_min, min(data[i,]))
}
data = cbind(data, row_max, row_min)
for(j in 1:ncol(data))
{
col_max = c(col_max, max(data[,j]))
col_min = c(col_min, min(data[,j]))
}
data = rbind(data, col_max, col_min)
print(data)100.用R爬取58同城石家庄在售新房首页
install.packages("rvest")
library(rvest)#包含爬虫函数的包
## 读取网页,获取石家庄在售新房
page_text <- read_html("https://sjz.58.com/xinfang/")#加载第一页的数据
#获取小区名称
estate_name <- page_text %>% html_nodes("span.items-name") %>% html_text()
#获取小区所在位置
estate_detail_address <- page_text %>% html_nodes("span.list-map") %>% html_text()#详细地址
estate_brief_address <- substr(estate_detail_address,3,4)#所在县区
#均价
estate_price <- page_text %>% html_nodes("p.price") %>% html_nodes("span")%>% html_text()
#处理数据:翰林观天下售价显示的是周边均价(保留)
estate_price <- c(estate_price[1:16], "15990", estate_price[17:59])
#将爬取到的数据存入数据框中
estate <- data.frame(name=estate_name,address=estate_brief_address,price=estate_price)
# 只输出前几行
print(head(estate))100题完,直接运行请点击如下链接:
https://www.heywhale.com/mw/project/6131fb0bbc40120017e9cec7http://xn--100r-294f23eza237og8mh7j31gd0hv90kgwfyl7c