nvidia.dali:深度学习加速神器!
最近准备准备整合一个基于pytorch的深度学习平台,把常用的训练推理流程、模型、数据管理、metric测试以及各种有效的黑科技攒到一起,作为个人的使用工具可以提升算法开发和实验效率。为了验证不同特性的有效性选择在比较有说服力的imagenet上进行实验。之前也做过很多次imagenet的训练和模型复现,但是训练一次imagenet比较耗时。最近使用上了一个比较有效的数据预处理框架:nvidia.dali,感觉效果不错。
DALI的概念
Nvidia DALI,NVIDIA’s Data Loading Library, is a collection of highly optimized building blocks, and an execution engine, to accelerate the pre-processing of the input data for deep learning applications。这是DALI的定义,说白了就是一个在神经网络中加速数据预处理(尤其是图像数据)的库。大家都知道,目前的神经网络任务中,基本可以分为以下几个步骤:
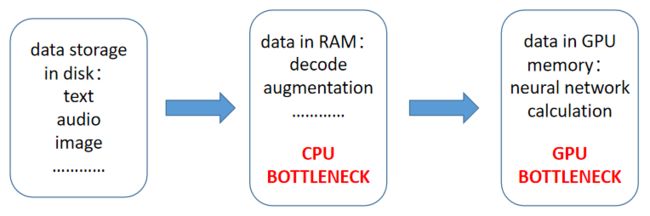
1、将数据(图片、视频、文本、音频或其他形式的数据)准备好存放在服务器的硬盘上;
2、通过CPU将硬盘上的数据读入内存,进行解码、数据增强等操作,将数据准备成可被神经网络使用的格式,这部分主要依赖于CPU的计算能力;
3、通过设备通信将内存中的数据传入GPU的显存中,进行神经网络计算,这部分主要依赖于GPU的计算能力。
整个流程中CPU和GPU的计算延时应该基本相当,这样CPU处理好的数据能被及时的被GPU利用,充分发挥二者的能力。如果CPU的处理速度大于GPU的计算速度,则会造成CPU算力浪费经常需要等待GPU;反之亦然。
随着黄教主不断发力发布算力越来越强的GPU以及计算机的硬件架构原因,这个过程的平衡逐渐被打破了。目前的神经网络应用中,经常看到GPU的算力较强而CPU较弱,数据预处理的过程耗时较长,成为了整个应用的bottleneck。而数据的预处理(以图像数据为例,数据的解码、图像翻转、resize等)大多都是计算密集型操作,这正是GPU擅长做的事情。那么为什么不考虑将这部分操作都从CPU挪到GPU上去做呢?于是nvidia做了dali这样一个库来实现这个transfer的过程。所以我们可以总结的说,DALI就做了一件事:把一部分数据处理的操作从CPU挪到了GPU上去做,挪动的比例得当的话,刚好可以实现CPU和GPU的延时同步,充分利用二者的计算能力。

一个DALI的使用sampler
我们以一个图像问题来简单介绍dali的使用方法。在DALI中,一个完整的数据预处理过程叫做一个pipeline,在这个pipeline中用户需要自己定义一些必须的内容,比如原始数据是什么格式(图片?二进制文件?视频?),需要做哪些数据预处理操作(图像翻转?图像归一化?)以及每个操作过程是在什么设备上运行(cpu?gpu?mixed?)。完成pipeline定以后需要将其build起来,然后打包成一个可被循环访问的数据结构,就可以在for循环中不断拿数据了。首先回顾一下,如果在Pytorch中使用原生API构建一个数据模块,我们可以这么做:
class MyDataset(torch.utils.data.Dataset):
def __init__(self, ...):
...
def __getitem__(self, idx):
# logit code about how to get a data from disk into RAM, usually decode image first and data augmentation then.
...
dataset = MyDataset(...)
data_loader = torch.utils.data.DataLoader(dataset, ...)
for index, data in enumerate(data_loader):
images, labels = data
images, labels = images.cuda(), labels.cuda()
...
这样的代码中,每张图片的预处理都在CPU上进行,最后通过Tensor.cuda()将其推到GPU的显存中参与运算。如果使用DALI,我们可以这么做:
from nvidia.dali.pipeline import Pipeline
import nvidia.dali.ops as ops
import nvidia.dali.types as types
from nvidia.dali.plugin.pytorch import DALIClassificationIterator
class SimplePipeline(Pipeline):
def __init__(self, batch_size, num_threads, device_id):
super(SimplePipeline, self).__init__(batch_size, num_threads, device_id, seed = 12)
# 类似pytorch的torchvision.datasets.ImageFolder,dali也提供了诸如FileReader、TFRecordReader这样的高阶API,能够解析不同类型的硬盘数据
self.input = ops.FileReader(file_root = image_dir)
# pipeline中定义了一个解码图像的模块,并指定其运行状态为CPU,输出的格式为RGB顺序
self.decode = ops.ImageDecoder(device = 'cpu', output_type = types.RGB)
# pipeline中定义了一个resize模块,并指定其运行状态为GPU,resize方式为保持ratio不变将其短边resize为224
self.resize = ops.Resize(device='gpu', resize_shorter=224)
# pipeline中定义了一个数据增强三件套模块,并指定其运行状态为GPU,分别包括crop、mirror和normalize
self.cmn = ops.CropMirrorNormalize(device='gpu', crop=(224, 224), dtype=types.FLOAT, mean=[0.485 * 255, 0.465 * 255, 0.406 * 255], std=[0.229 * 255, 0.224 * 255, 0.225 * 255], mirror=1)
# 这是pipeline中必须存在的一个函数,用来说明在调用该pipeline时,应该如何对数据进行实际的操作,可以理解为pytorch的module的forward函数。__init__中只定义了一些可使用的操作,具体怎么使用在这里说明
def define_graph(self):
jpegs, labels = self.input()
images = self.decode(jpegs)
images = self.resize(images)
images = self.cmn(images)
return (images, labels)
pipe = SimplePipeline(8, 4, 0)
pipe.build()
train_loader = DALIClassificationIterator(pipe)
for index, data in enumerate(train_loader):
images, labels = data
# 由于之前已经在gpu上对images进行操作了,所以images已经被处理成为gpu上的tensor了,而labels没有进行过gpu上的操作,因此它还是内存中的tensor,需要.cuda()转移到gpu上,可以通过对代码的调试详细分析
labels = labels.squeeze(-1).cuda().long()
...
上面的代码中,我们看到了一个dali处理图像数据的很简单的例子,希望大家从中理解dali的大概运行原理,而不用纠结每个参数或者每个API的接口具体形式,这些内容可以再dali的doc网站中全部查到。如果想要准确的使用某一个类型的数据,还是需要去查找每个API的接口参数及其对应的含义,甚至可能需要去看一下部分API的源码。DALI支持多种数据类型,甚至连TFRecord类型的数据都支持,可以通过dali把tfrecord数据集成到一个pytorch框架下的应用中,确实还是很方便的。我把自己的渣渣CPU版本数据预处理换成DALI+TFRecord再搭配上DDP后,训练速度直接飙了将近8倍,4块Tesla P100上训练一个epoch的imagenet只需要12分钟,四块卡的GPU利用率全部顶到100%,深深地治愈了我的强迫症,感谢DALI!!!
水平有限,欢迎讨论。