PyTorch 2.0 重磅发布:一行代码提速 30%
在今天的 PyTorch 2022 开发者大会上,PyTorch 团队发布了一个新特性`torch.compile`,这个新特性将 PyTorch 的性能推向了新高度,并开始将 PyTorch 的部分实现从 C++ 中迁移到 Python 中。他们相信这是 PyTorch 一个实质性的新方向--因此称之为 **PyTorch 2.0**。`torch.compile` 是一个完全附加的(和可选的)功能,因此 **PyTorch 2.0 100% 向后兼容,** 因此基于 PyTorch 1.x 开发的项目可以不用做任何修改就能迁移到 PyTorch2.0 **。**
PyTorch 2.0 正式版本预计在 2023 年 3 月份发布,但可以使用以下命令安装预发布版本提前体验:
pip install numpy --pre torch[dynamo] --force-reinstall --extra-index-url https://download.pytorch.org/whl/nightly/cu117
一行提速 30%
只需使用torch.compile对模型进行编译,就可以享受 PyTorch 2.0 给模型速度带来的极致提升,简单示例代码如下。
import torch
import torchvision.models as models
model = models.resnet18().cuda()
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
compiled_model = torch. compile (model) # 关键一行
x = torch.randn(16, 3, 224, 224).cuda()
optimizer.zero_grad()out = compiled_model(x)
out.sum().backward()
optimizer.step()
PyTorch 团队在 163 个开源模型(包括图像分类、目标检测、图像生成等领域)进行验证,结论是模型在 NVIDIA A100 GPU 上的运行速度快了 43%。在 Float32 精度下,它的运行速度快了 21%,在 AMP 精度下,它的运行速度快了为 51%。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1arAr5ht-1670047163094)(https://p3-juejin.byteimg.com/tos-cn-i-k3u1fbpfcp/c9d8f0797ba4495189ae25e5691e546b~tplv-k3u1fbpfcp-zoom-1.image)]
2.0 完整解读
以下内容翻译自 https://pytorch.org/get-started/pytorch-2.0
概述
介绍 PyTorch 2.0 的变化是迈向下一代 PyTorch 2.x 系列版本的第一步。在过去的几年里,从 PyTorch 1.0 到 1.13,我们持续迭代和创新,并将 PyTorch 转移到新成立的 PyTorch 基金会,它是 Linux 基金会的一部分。 PyTorch 的最大优势除了我们令人惊叹的社区之外,还在于我们继续作为一流的 Python 集成、命令式风格、用户友好的 API 和选项。与 PyTorch 1.0 一样,PyTorch 2.0 依然提供了相同的 eager 开发模式和友好的用户体验,同时从根本上改变和提高了 PyTorch 在编译器级别下的操作方式。我们能够提供更快的性能、对动态输入和分布式有更好的支持。
PYTORCH 2.X:更快、更 PYTHONIC 和一如既往的灵活
今天,我们发布了torch.compile,这项特性将 PyTorch 的性能推向了新的高度,并开始将PyTorch 的部分内容从 C++ 中移回到 Python 中。我们相信这是 PyTorch 一个重要的新方向–因此我们称之为 2.0。torch.compile是一个完全附加的(和可选的)功能,因此 2.0 的定义是 100% 向后兼容。
支撑 torch.compile的一些新技术:TorchDynamo、AOTAutograd、PrimTorch 和TorchInductor。
- TorchDynamo 使用 Python Frame Evaluation Hooks 捕获 PyTorch 程序,这是我们 5 年来在安全计算图捕获方面研发的一项重大创新。
- AOTAutograd 重载了 PyTorch 的 autograd 引擎,使它可以生成超前(AOT)的反向追踪。
- PrimTorch 将约 2000 多个 PyTorch 运算符归纳为约 250 个原始运算符的封闭集,开发人员可以针对这些运算符构建一个完整的 PyTorch 后端,这大大降低了编写 PyTorch 功能或后端的障碍。
- TorchInductor 是一个深度学习编译器,可以为多个加速器和后端生成高速代码。对于英伟达 GPU,它使用 OpenAI Triton 作为一个关键的构建模块。
TorchDynamo、AOTAutograd、PrimTorch 和 TorchInductor 是用 Python 编写的,并支持动态形状(即能够输入不同大小的 Tensor 而无需重新编译),这使得它们很灵活,很容易拓展,并降低了开发人员和供应商的准入门槛。
为了验证这些技术,我们使用了来自不同机器学习领域的 163 个开源模型。我们精心打造了这个基准(benchmark),包括图像分类、物体检测、图像生成等任务,以及各种 NLP 任务,如语言建模、问答、序列分类、推荐系统和强化学习。我们将这些基准分为三类:
- 46 个来自 HuggingFace Transformers 的模型
- 61 个来自 TIMM 的模型
- 56 个来自 TorchBench 的模型
我们没有修改这些开源模型,只是增加了一个torch.compile函数来包装它们。
然后我们测量这些模型的速度并验证精度。由于加速比可能取决于数据类型,我们在Float32 和自动混合精度(AMP)上都进行了测速。我们报告了 0.75 * AMP + 0.25 * Float32 的加权平均速度,因为我们发现 AMP 在实践中更常见。
在这 163 个开源模型中,有 93% 的模型可以被 torch.compile 正常编译,并且编译后模型在 NVIDIA A100 GPU 上的训练运行速度提高了 43%。在 Float32 精度下,它的运行速度平均为 21%,在AMP精度下,它的运行速度平均为 51%。
注意事项:在桌面级 GPU(如 NVIDIA 3090)上,我们测得的速度比在服务器级 GPU(如 A100)上要低。截至目前,我们的默认后端 TorchInductor 支持 CPU 和 NVIDIA Volta 和 Ampere GPU。它(还)不支持其他 GPU、xPU 或旧的 NVIDIA GPU。

Speedups for torch.compile against eager mode on an NVIDIA A100 GPU
立刻尝鲜 : torch.compile正处于开发的早期阶段。从今天开始,你可以使用 PyTorch 的 nightly 版本试用torch.compile。我们预计在 2023 年 3 月初发布第一个稳定的 2.0 版本。
在 PyTorch 2.x 的规划中,我们希望在性能和可扩展性方面将编译模式(compiled mode)推得越来越远。正如我们在今天的大会上所谈到的,其中一些工作正在进行中,有些工作还没有开始,有些工作是我们希望看到的,但我们自己没有足够的精力来做。如果你有兴趣做出贡献,请在本月开始的 "Ask the Engineers: 2.0 Live Q&A Series"现场问答系列中与我们交谈(详情见本帖末尾),或者通过 Github/论坛。
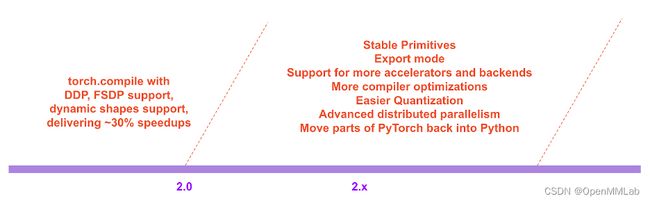
感言
下面是 PyTorch 的一些用户对我们新方向的看法。
- Sylvain Gugger, HuggingFace transformers 的主要维护者:
“只需添加一行代码,PyTorch 2.0 就能在训练 Transformers 模型时实现 1.5 倍到 2.0 倍的速度提升,这是自混合精度训练推出以来最令人兴奋的事情!”
- Ross Wightman,TIMM(PyTorch 生态系统中最大的 vision model hub 之一)的主要维护者:
“大多数的 TIMM 模型可以开箱即用,将其用于推理和训练,无需修改代码”
- Luca Antiga,grid.ai 的首席技术官, PyTorch Lightning 的主要维护者之一:
“PyTorch 2.0 体现了深度学习框架的未来。不需要用户干预即可捕获 PyTorch 程序,开箱即用的程序生成,以及巨大的设备加速,这种可能性为人工智能开发人员打开了一个全新的维度。”
动机
PyTorch 的理念一直是将灵活性和可编程性(hackability)放在首位,而性能紧随其后。我们致力于:
- 高性能 eager 执行方式
- 符合 Pythonic 风格的内部结构
- 对分布式、自动微分、数据加载、加速器等组件的优雅抽象。
自 2017 年推出 PyTorch 以来,硬件加速器(例如 GPU)的计算速度提高了约 15 倍,内存访问速度提高了约 2 倍。因此,为了保持高性能的 eager 执行方式,我们不得不将 PyTorch 的核心部分转移到 C++ 中,但将这些部分转移到 C++ 则难以避免地降低它们的可编程性(hackability),并增加代码贡献的上手难度。 从第一天起,我们就知道 eager 执行方式的性能限制。2017 年 7 月,我们开始了第一个为 PyTorch 开发编译器的研究项目。这个编译器需要让 PyTorch 程序运行得更快,但不能以牺牲 PyTorch 体验为代价。我们的关键标准是保持灵活性——支持研究人员在不同探索阶段使用动态输入和动态的程序。
技术概览
多年来,我们在 PyTorch 中构建了多个编译器项目。让我们将编译器分解为三个部分:
- 图获取(graph acquisition)
- 图降解(graph lowering)
- 图编译(graph compilation)
在构建 PyTorch 编译器时,graph acquisition 是更艰巨的挑战。 在过去的 5 年里,我们构建了 torch.jit.trace、TorchScript、FX tracing、Lazy Tensors,但它们都没有给我们带来想要的一切。有些灵活但不快,有些快但不灵活,有些既不快也不灵活,还有些用户体验不好(例如静悄悄地出错)。虽然 TorchScript 很有前途,但它需要对你的代码和你的代码所依赖的代码进行大量修改。对很多 PyTorch用户来说,这种要求使其成为一个不可行的方案
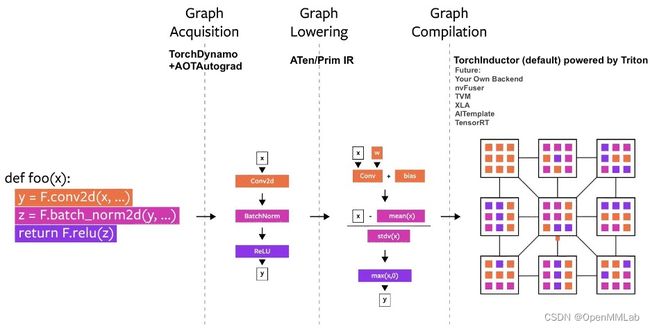
The PyTorch compilation process
TorchDynamo:可靠且快速地获取计算图
今年早些时候,我们开始研究 TorchDynamo,它使用了 PEP-0523 中引入的CPython 新功能 Frame Evaluation API,我们采用数据驱动的方法来验证其在 Graph Capture 上的有效性。我们使用了 7,000 多个用 PyTorch 编写的 Github 项目作为我们的验证集。TorchDynamo 正确、安全地捕获了它们中 99% 的计算图,并且开销可以忽略不计——不需要对原有代码做任何修改。作为对比,TorchScript 和其他方法甚至难以捕获其中的 50%,而且通常开销很大。这时我们才知道,我们终于突破了多年来在灵活性和速度上苦苦挣扎的障碍。
TorchInductor:使用 define-by-run IR 的快速代码生成
对于 PyTorch 2.0 的新编译器后端,我们从用户编写高性能自定义内核的方式中汲取灵感:越来越多地使用 Triton 语言。我们还希望有一个编译器后端能够使用类似于PyTorch eager 的抽象,并具有足够的通用性,以支持 PyTorch 中广泛的功能。TorchInductor 使用 pythonic define-by-run loop level IR 自动将 PyTorch 模型映射到 GPU 上生成的 Triton 代码和 CPU 上的 C++/OpenMP。TorchInductor 的核心 loop level IR 仅包含约 50 个运算符,并且它是用 Python 实现的,使其易于编程和扩展。
AOTAutograd:在 AOT 计算图中复用 Autograd
对于 PyTorch 2.0,我们想要加速训练。因此,至关重要的是,我们不仅要捕获用户级代码,还要捕获反向传播。此外,我们也想要重用已有的、久经检验的 PyTorch Autograd 系统。AOTAutograd 利用 PyTorch 的 torch_dispatch ****扩展机制来追踪我们的 Autograd 引擎,使我们能够“提前”捕获向后传递,这使我们能够使用 TorchInductor 同时加速前向和反向传播。
PrimTorch:稳定的原始运算符
为 PyTorch 编写后端具有挑战性。PyTorch 有 1200 多个运算符,如果考虑每个运算符的各种重载,则有 2000 多个。
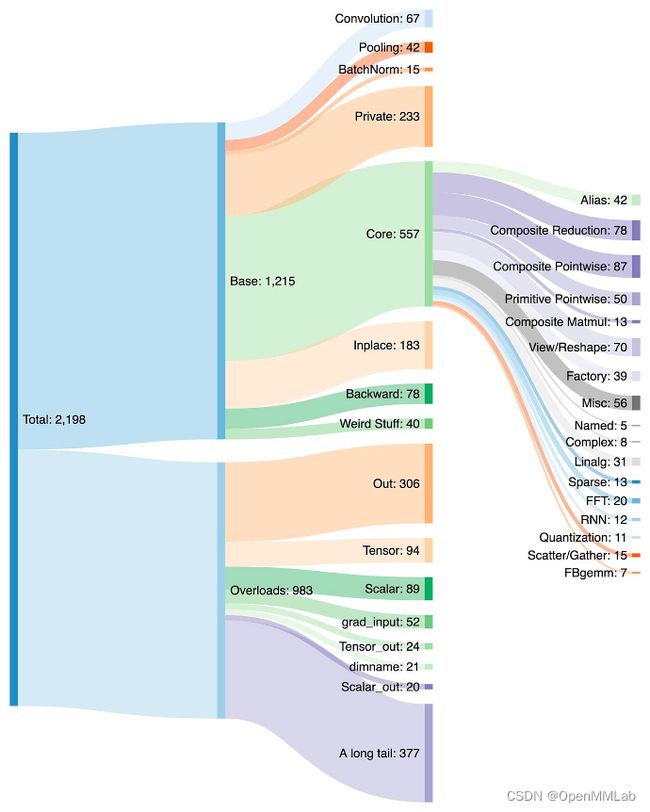
A breakdown of the 2000+ PyTorch operators
因此,编写后端或跨领域的功能成为一项耗费精力的工作。在 PrimTorch 项目中,我们致力于定义更小且更稳定的运算符集。PyTorch 程序可以统一降解到这些运算符集。我们的目标是定义两个运算符集:
- Prim ops 大约有 250 个相当低级别的运算符。这些适用于编译器,因为它们足够低级别,您需要将它们重新融合在一起以获得良好的性能。
- ATen ops 大约有 750 个规范运算符,适合按原样输出。这些适用于那些已经在 ATen 级别集成的后端,或者那些不需要编译以从较低级别的运算符集(如 Prim ops)恢复性能的后端。
我们将在下面的开发者/供应商体验部分讨论更多关于此主题的内容
用户体验
我们引入了一个简单的函数 torch.compile 来包装您的模型并返回一个编译后的模型。
compiled_model = torch.compile(model)
这个 compiled_model 保持着对您的模型的引用,并将 forward 函数编译为更优化的版本。在编译模型时,我们给出了几个参数来配置:
def torch.compile(model: Callable,
*,
mode: Optional[str] = "default",
dynamic: bool = False,
fullgraph:bool = False,
backend: Union[str, Callable] = "inductor",
# advanced backend options go here as kwargs
**kwargs
) -> torch._dynamo.NNOptimizedModule
-
mode ****指定编译器在编译时应该优化什么。
- 默认模式会尝试高效编译,即不花费太长时间编译,并且不使用额外内存。
- 其他模式,如 reduce-overhead 更多地减少框架开销,但会消耗少量额外内存。max-autotune 会编译很长时间,试图为您提供它可以生成的最快代码。
- dynamic ****指定是否开启针对动态形状的代码生成路径。某些编译器优化不能应用于动态形状程序。明确指定您想要一个具有动态形状还是静态形状的编译程序将有助于编译器为您提供更好的优化代码。
- fullgraph ****类似于 Numba 的 nopython. 它将整个程序编译成一个计算图,或者给出一个错误来解释为什么它不能这样做。大多数用户不需要使用此模式。如果您非常注重性能,那么您可以尝试使用它。
- 后端 ****指定要使用的编译器后端。默认情况下,使用 TorchInductor,但还有一些其他可用的。

编译体验旨在在默认模式下提供最多的好处和最大的灵活性,上图是您在每种模式下获得模型的特点。
现在,让我们看一下编译真实模型并运行它(使用随机数据)的完整示例
import torch
import torchvision.models as models
model = models.resnet18().cuda()
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
compiled_model = torch.compile(model)
x = torch.randn(16, 3, 224, 224).cuda()
optimizer.zero_grad()
out = compiled_model(x)
out.sum().backward()
optimizer.step()
第一次运行时optimized_model(x),它会编译模型。因此,运行时间会更长。但随后的运行速度很快。
模式
编译器有一些预设,以不同的方式调整编译后的模型。你可能正在运行一个小模型,由于框架的开销而变得很慢。或者,你可能正在运行一个大的模型,它几乎无法容纳在内存中。根据你的需要,你可能想使用不同的模式。
# API NOT FINAL
# default: optimizes for large models, low compile-time
# and no extra memory usage
torch.compile(model)
# reduce-overhead: optimizes to reduce the framework overhead
# and uses some extra memory. Helps speed up small models
torch.compile(model, mode="reduce-overhead")
# max-autotune: optimizes to produce the fastest model,
# but takes a very long time to compile
torch.compile(model, mode="max-autotune")
读取和更新属性
访问模型属性的工作方式与在 eager 执行方式下一样。您可以像往常一样访问或修改模型的属性(例如model.conv1.weight)。这在代码修正方面是完全安全可靠的。TorchDynamo 将守卫(guards)插入代码以检查其假设是否成立。如果属性以某种方式发生变化,那么 TorchDynamo 就会知道根据需要自动重新编译。
# optimized_model works similar to model, feel free to access its attributes and modify them
optimized_model.conv1.weight.fill_(0.01)
# this change is reflected in model
Hooks
Module 和 Tensor hooks 目前还不能完全工作,在完整开发完成后将能使用完整功能。
序列化
你可以序列化优化前后模型的 statedict。它们指向相同的参数和状态,因此是等价的。
torch.save(optimized_model.state_dict(), "foo.pt")
# both these lines of code do the same thing
torch.save(model.state_dict(), "foo.pt")
您当前还无法序列化 optimized_model。如果您希望直接保存对象,请改为保存 model。
torch.save(optimized_model, "foo.pt") # Error
torch.save(model, "foo.pt") # Works
推理和导出
对于模型推理,在使用 torch.compile 生成编译模型后,在实际模型服务之前最好运行一些预热步骤。这有助于缓解服务初期的峰值延迟。 此外,我们将引入一种称为 torch.export 的模式,该模式会为需要高保证、可预测延迟的环境谨慎地导出整个模型和守卫(guards)。torch.export 将需要更改您的程序,特别是如果您有数据相关的控制流。
# API Not Final
exported_model = torch._dynamo.export(model, input)
torch.save(exported_model, "foo.pt")
此特性还在在开发的早期阶段。
调试问题
编译模式是不透明的并且难以调试。你会有这样的问题:
- 为什么我的程序在编译模式下崩溃?
- 编译模式和 eager 模式下的精度是否能对齐?
- 为什么我没有体验到加速?
如果编译模式产生错误或崩溃或与 eager 模式不同的结果(超出机器精度限制),这不太可能是您的代码的错误。但是,了解错误的原因是哪一段代码是有用的。 为了帮助调试和可复现性,我们创建了几个工具和日志记录功能,其中一个尤为重要:Minifier 。 Minifier ****会自动将您看到的问题缩小为一小段代码。这个小代码片段重现了原始问题,您可以使用缩小的代码提交 github issue。这将帮助 PyTorch 团队轻松快速地解决问题。 如果您没有看到预期的加速,那么我们有 torch._dynamo.explain ****工具可以解释您的代码的哪些部分导致了我们所说的“图形中断”。图中断通常会阻碍编译器加速代码,减少图中断的数量可能会加速您的代码(达到收益递减的某个限制)。 您可以在 PyTorch 的故障排除指南中了解这些以及更多内容。
动态形状
在查看支持 PyTorch 代码通用性的必要条件时,一个关键要求是支持动态形状,并允许模型采用不同大小的张量,而无需在每次形状更改时重新编译。 截至今天,对动态形状的支持是有限的,并且正在快速进行中。它将在稳定版本中具有完整的功能。你可以设置 dynamic=True 以启用它。在特征分支(symbolic-shapes)上我们取得了更多进展,我们已经在使用 TorchInductor 的完整符号形状训练中成功运行 BERT_pytorch。对于动态形状的推理,我们有更多的覆盖面。例如,让我们看一下常见的动态形状发挥作用的场景——使用语言模型生成文本。 我们可以看到,即使形状从 4 一直动态变化到 256,编译模式也能够始终优于 eager 高达 40%。在不支持动态形状的情况下,常见的解决方法是填充到最接近的 2 的幂。但是,正如我们从下表中看到的那样,它会产生大量的性能开销,并且还会导致编译时间显著延长。此外,填充有时并不容易正确执行。 通过在 PyTorch 2.0 的编译模式中支持动态形状,我们可以获得最佳的性能和易用性。
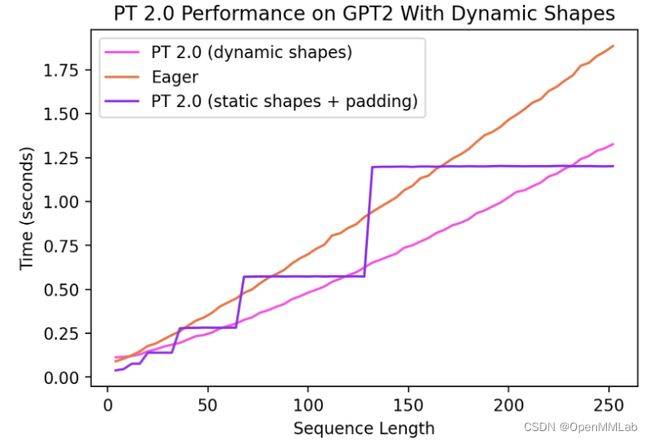
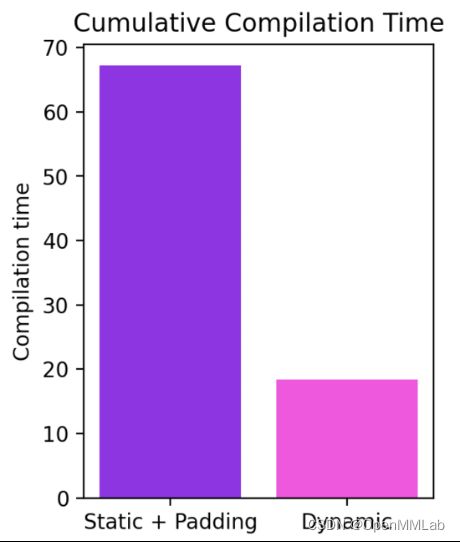
目前的工作发展非常迅速,随着我们对基础设施进行根本性改进,我们可能会暂时让一些模型倒退。可以在此处找到我们在动态形状方面的最新进展。
分布式
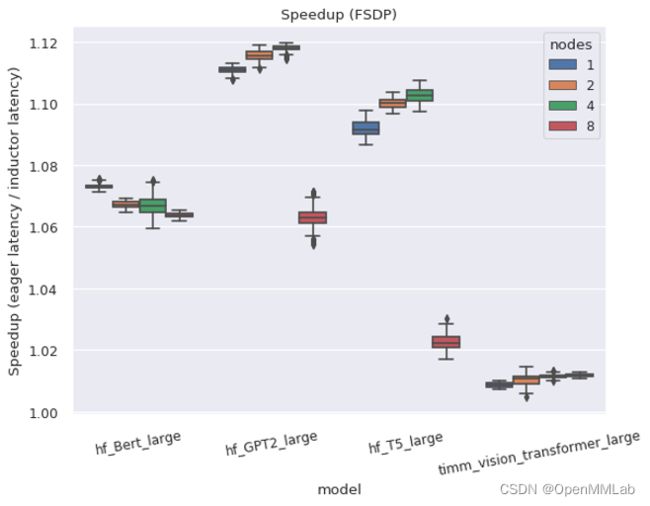
总之,torch.distributed 的两个主要分布式包装器在编译模式下运行良好。 DistributedDataParallel(DDP) 和 FullyShardedDataParallel(FSDP) 都可以在编译模式下正常工作,并且相对于 eager 模式提供了更好的性能和内存利用率。但也有一些注意事项和限制。 FP32 精度加速
左图:编译模式下 FSDP 比 eager 模式的加速(FP32 精度)。 右图:编译模式下的 FSDP 比 eager 模式下占用的内存要少得多

外部启动脚本以及那些内在使用 DDP 的包装器通常可以开箱即用。Hugging Face Accelerate、Lightning、torchrun 和 Ray Train 都已经过测试和验证。DeepSpeed 和 Horovod 尚未经过测试,我们希望尽快启用它们。 手动梯度检查点(即torch.utils.checkpoint*)正在开发中,预计将在不久的将来启用。启用它的工作正在进行中,AOTAutograd 的 min-cut 分区程序部分缓解了这种情况,它重新计算 backward 调用中的某些值以减少峰值内存使用。从图中显示的 FSDP 在编译模式下的内存压缩结果可以看出这一点。 其他实验性分布式子系统,例如 DistributedTensor 和 PiPPy,尚未使用 TorchDynamo 进行测试。
分布式数据并行 (DDP)
DDP 的效率提升依赖于反向传播计算与 AllReduce 通信的重叠,并将较小的逐层 AllReduce 操作分组到“桶”中。TorchDynamo 编译的 AOTAutograd 函数在与 DDP 简单结合时阻碍了通信重叠;但通过为每个“桶”编译单独的子图,并允许通信操作发生在子图外部和子图之间,性能得以恢复。编译模式下的 DDP 支持目前还需要static_graph=True和find_unused_parameters=True,但这些不会是长期要求。有关 DDP + TorchDynamo 的方法和结果的更多详细信息,请参阅这篇文章。
FullyShardedDataParallel (FSDP)
FSDP 本身是一个“测试版”PyTorch 功能,由于能够调整哪些子模块被包装,并且通常有更多的配置选项,因此它的系统复杂性比 DDP 更高。配置 use_original_params=True 后,FSDP 可与 TorchDynamo 和 TorchInductor 一起用于各种流行模型。兼容性问题预计在特定模型或配置中产生,但都会被积极改进。提交 github issue 的模型将会被优先改进。 用户指定一个 auto_wrap_policy 参数来指示将其模型的哪些子模块一起包装在用于状态分片的 FSDP 实例中,或者手动将子模块包装在 FSDP 实例中。例如,当每个“transformer block”都包装在一个单独的 FSDP 实例中时,许多 transformer 模型运行良好,因此一次只需要具体化一个 transformer 块的完整状态。Dynamo 将在每个 FSDP 实例的边界插入图中断,以允许前向(和后向)通信操作发生在图外并与计算并行。 如果在不将子模块包装在单独实例中的情况下使用 FSDP,它会回退到与 DDP 类似的操作,但没有分桶。因此,所有梯度都在一次操作中减少,即使在 Eager 中也不会有计算/通信重叠。此配置仅使用 TorchDynamo 进行了功能测试,未进行性能测试。
最后的想法
我们对PyTorch 2.0及以后的发展方向感到非常兴奋。通往最终2.0版本的道路将是崎岖不平的,但请尽早加入我们的旅程。如果你有兴趣进一步深入研究或为编译器做出贡献,请关注这个月开始的 Ask the Engineers: 2.0 Live Q&A Series。其他资源包括:
- 入门 @ https://pytorch.org/docs/master/dynamo/get-started.html
- 教程@ https://pytorch.org/tutorials/
- 文档@ https://pytorch.org/docs/master和pytorch.org/docs/master/dynamo
- 开发者讨论@ https://dev-discuss.pytorch.org
欢迎点击链接加入技术交流群讨论 PyTorch 2.0 !!!