目标检测算法——小目标检测
一、定义
1、以物体检测领域的通用数据集COCO物体定义为例,小目标是指小于32×32个像素点(中物体是指32*32-96*96,大物体是指大于96*96)。
2、在实际应用场景中,通常更倾向于使用相对于原图的比例来定义:物体标注框的长宽乘积,除以整个图像的长宽乘积,再开根号,如果结果小于3%,就称之为小目标。
二、难点
coco上面:
1、包含小目标的样本数量较少,这样潜在的让目标检测模型更关注中大目标的检测。
2、由小目标覆盖的区域更小,这样小目标的位置会缺少多样性。我们推测这使得小目标检测的在验证时的通用性变得很难。

三、解决方案
按照常规流程分为:数据层面、backbone、neck & head、其他(后处理、loss)
数据层面
1、过采样包含小目标的图像
注意会使得中大目标一定程度掉点,需要权衡。

2、在包含小目标样本中多次复制粘贴小目标
MS COCO中的实例分割mask使得我们可以将任意目标从它原来的位置进行拷贝。拷贝被粘贴在不同的位置。通过增加每张样本中小目标的个数,匹配的anchor的数据增加了。这样改进了小目标在RPN训练期间在loss函数中的贡献。
但是要注意不同的策略带来的效果,不好的策略甚至造成性能下降
1)需要保存原图和增广图同时训练

2)一幅图中黏贴一个物体多次、黏贴多个物体多次、黏贴所有物体多次三种方案,最优的黏贴次数不同,作者的实验条件下黏贴多个物体三次最好。

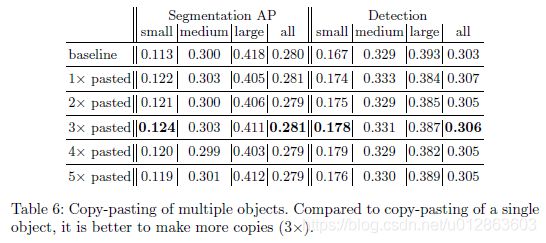

3)只考虑 未被遮挡的目标,因为使用有遮挡区域的不连续样本会失真。我们确保新粘贴的目标 不与任何现有的目标重叠,至少与图像边界保持5个像素的距离。不需要进行边缘高斯模糊等(除非用其他更复杂的融合策略)

4)在将目标粘贴到新路径之前,我们进行随机变换。我们通过将目标尺寸在±20%范围,旋转在±15°范围缩放。
5)mosaic增强
3、提升输入图像分辨率
4、提高图像采集的分辨率
5、tile图像(裁切)
检测小物体的另一个重要策略是将图像切割后形成batch,这个操作叫做tile,作为预处理步骤。tile可以有效地将检测器聚焦在小物体上,但允许你保持所需的小输入分辨率,以便能够运行快速推断。 如果你在训练中使用tile,重要的是要记住,你也需要在推理时tile你的图像。
6、过滤无关类别
类别管理是提高数据集质量的一项重要技术。如果你有一个类与另一个类明显重叠,你应该从数据集中过滤掉这个类。也许,你认为数据集中的小物体不值得检测,所以你可能希望将其拿掉。
backbone
1、RFBNet
Neck & head
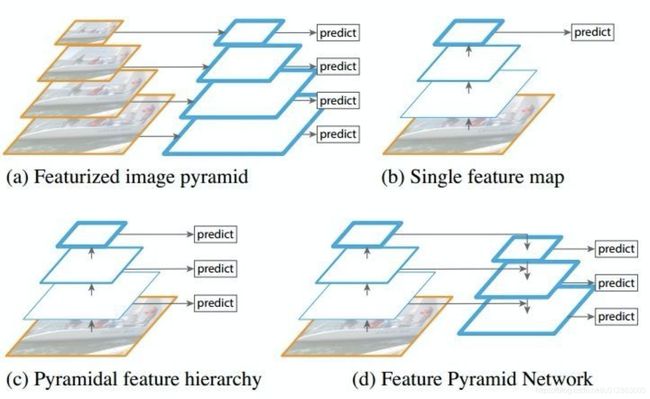
1、FPN(已开源)
不同阶段的特征图对应的感受野不同,它们表达的信息抽象程度也不一样。浅层的特征图感受野小,比较适合检测小目标(要检测大目标,则其只“看”到了大目标的一部分,有效信息不够);深层的特征图感受野大,适合检测大目标(要检测小目标,则其”看“到了太多的背景噪音,冗余噪音太多)。所以,有人就提出了将不同阶段的特征图,都融合起来,来提升目标检测的性能,这就是特征金字塔网络。
这里跳过了SSD网络,因为FPN可以认为是SSD结构的进化。
2、ssh网络(已开源)
由于可以通过融合不同分辨率的特征图来提高特征的丰富度和信息含量来检测不同大小的目标,自然会有人进一步猜测,如果只检测高分辨率的特征图(浅层特征)来检测小人脸,使用中分辨率特征图(中间特征)来检测大的脸。(个人感觉并不如FPN,FPN也可以设置不同的规则分治)
还有一种方法就是不共享主干网络,不同网络检测不同尺寸的人脸(小米是这么干的,由于单独任务简单,每个主干网络也设计的简单)
整体结构如下:

检测模块结构如下:
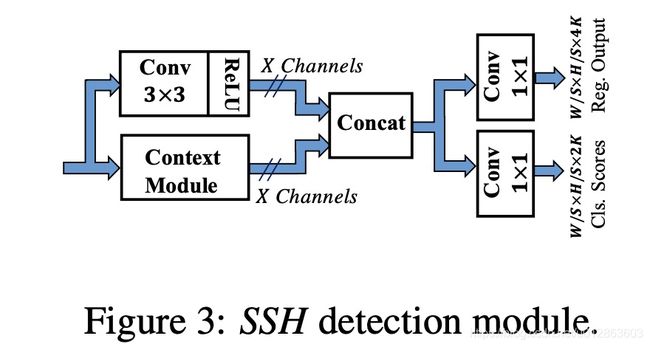
上下文模块如下:

3、Faceboxes(已开源)
对那些底层的小anchor进行一个稠密化的工作,具体就是在每个感受野的中心,也就是SSD中的anchor中心,对其进行偏移。根据其密度大小进行2 、3或4倍的稠密化工作。如下图

个人感觉可能直接使用后面的anchor free 中基于密集检测的算法更优,比如centernet (object as point)
4、利用上下文信息
主要有两篇文章,具体比较晦涩,还未细看
1) 小目标,特别是像人脸这样的目标,不会单独地出现在图片中(想想单独一个脸出现在图片中,而没有头、肩膀和身体也是很恐怖的)。像[PyramidBox]( PyramidBox: A Context-assisted Single Shot Face Detector )方法,加上一些头、肩膀这样的上下文Context信息,那么目标就相当于变大了一些,上下文信息加上检测也就更容易了。
2) 通用目标检测中另外一种加入Context信息的思路,[Relation Networks]( Relation Networks for Object Detection )虽然主要是解决提升识别性能和过滤重复检测而不是专门针对小目标检测的,但是也和上面的PyramidBox思想很像的,都是利用上下文信息来提升检测性能,可以归类为Context一类。
5、利用GAN 网络
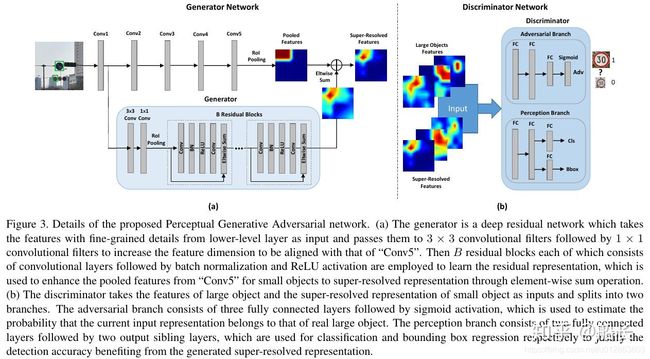
Perceptual GAN 使用了GAN对小目标生成一个和大目标很相似的Super-resolved Feature(如下图所示),然后把这个Super-resolved Feature叠加在原来的小目标的特征图(如下下图所示)上,以此增强对小目标特征表达来提升小目标(在论文中是指交通灯)的检测性能。效果提升非常明显,需要后续仔细学习。

其他
1、自动学习模型的anchor
YOLOv5模型会根据你的自定义数据自动为你完成这项工作。你所要做的就是开始训练。
主要就是利用kmeas进行聚类。
2、focal loss
3、匹配策略
不是用iou,使用改进版的比如: GIOU、DIOU、CIOU
4、如果需要,更改rio pooling为rio align
5、SNIPER
图像金字塔是传统的提升物体检测精度的策略之一,其能提升精度的一个原因是尺寸多样性的引入。但是图像金字塔也有一个非常严重的缺点:即增加了模型的计算量,SNIPER提出动机便是解决图像金字塔计算量大的问题。
需要注意SNIPER并不是一个检测算法,而是对输入图像的一个采样策略,是对图像金字塔的替代。其采样的结果(chips)将作为输入输入到物体检测算法中。
算法虽然使用了RPN,但是并不是离开了RPN就无法工作了,RPN提供了一个提取假正利率的功能,这个可以通过Selective Search或者Edge Box近似替代。
另外,SNIPER仅仅是对训练速度的提升,往往更重要的检测速度并没有提升,反而是 模型必须依赖图像金字塔,这反而降低了模型的通用性,并不适合工业界,可能对打比赛提升性能有用
最后,作者开源的源码和论文出入较大,读起来比较费劲,以后有需要再学习。
参考链接:
1、 https://segmentfault.com/a/1190000039027917
2、 https://blog.csdn.net/abrams90/article/details/89371797
3、 https://www.cnblogs.com/xuanyuyt/p/11328548.html
4、 https://zhuanlan.zhihu.com/p/121666693
5、 https://mp.weixin.qq.com/s/XJz8SwQiGlck8oF6GeiQUw
6、 https://arxiv.org/pdf/1708.03979.pdf
7、 https://mp.weixin.qq.com/s/ZllNiZsGoNdpP0ez7238hQ
8、 https://zhuanlan.zhihu.com/p/46810110
9、 https://zhuanlan.zhihu.com/p/37081185