RINEX观测值文件读取(O文件)
因为不同生产厂家的接收机的观测量输出格式不一致,为了便于数据交换,制定了一个统一的标准格式,称为RINEX格式(Receiver Independent Exchange,RINEX)。
本文首先对RINEX2.1.1版本的观测值文件进行格式介绍,然后基于C语言,以程序设计的角度讲解如何读取数据,每行代码皆有详细注释和讲解,希望可以为测绘学子们带来帮助。
目录
观测值文件(Observation)
O文件头
O文件数据块
读取O文件程序设计
结构体声明
O文件读取
获取O文件历元数(get_epochnum)
字符串转换成浮点数(strtonum)
O文件头读取
O文件数据块读取
N文件读取中讲解了如何下载观测值文件数据 ,这里不再进行赘述。
观测值文件(Observation)
观测值文件由表头和数据块构成:
表头包括:RINEX版本号、接收机天线号、测站名、点号、观测值类型、采样间隔、开始时间、结束时间等等。
观测数据块包括:观测时刻、每颗卫星的伪距观测值和相位观测量,有的接收机还输出多普勒、信噪比值等。
O文件头
示例: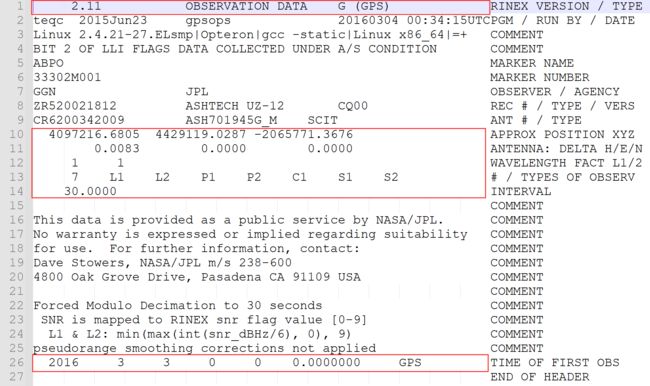
以上是2.11版本的GPS观测值文件,红框标注部分是本次伪距定位部分读取的主要数据。(当然考虑到程序的可移植性,其实应该将所有内容全部读取),将下来将对头文件进行讲解。
- 第一行:rinex的版本,观测值的类型,观测数据所属卫星系统
- 第二行:文件所采用程序的名称,文件单位的名称,文件的日期
- 第三行、四行:注释:针对所选系统进行解释
- 第五行:天线标志的名称(点名)
- 第六行:点名的编号
- 第七行:观测员姓名,观测单位名称
- 第八行:接收机序列号、接收机类型、接收机版本号
- 第九行:天线序列号、天线类型
- 第十行:测站的近似位置X、Y、Z
- 第十一行:天线高、天线中心相对于测站标志在东向偏移量、北向偏移量
- 第十二行:缺省的L1和L2载波的波长因子
- 第十三行:观测值类型的数量、观测值的类型
- 第十四行:观测值的历元间隔
- 第十五行到第二十五行:注释
- 第二十六行:观测起始时间、系统
- 第二十七行:文件头结束标注
O文件数据块
示例:
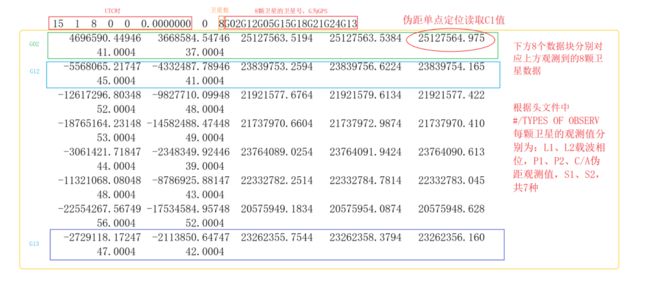
历元信息:
数据块的第一行记录了该历元的UTC时刻,年、月、日、时分秒,紧跟着一个整型单位的历元标志,记录了该历元的状况(0表示正常),然后是该历元观测到的卫星数量,以及各个卫星的PRN号。
当观测到的卫星数>12时,一行的信息存储不下会自动换行,如下图所示:
![]()
当观测到的卫星数>24时,再次换行,并且卫星的PRN号与前一行对其。
![]()
上述两个情况是从多系统中截取到的,对于单系统而言,每个历元的卫星观测数>10就是优质观测。所以只需要考虑卫星数>12的情况即可,当然为了程序的可移植性,将其写完善也没问题。
数据块信息:
历元信息往下一行就是记录观测值的数据块,以每颗卫星为单位,依照头文件中的观测值类型及顺序,从左到右依次排列,每行记录5个观测值,一行不够时转下行。当所有卫星数据记录完后,转到下一个历元。
读取O文件程序设计
结构体声明
O文件结构体的创建分为三个部分:O文件头结构体、历元信息结构体和数据块结构体。
为了之后调用方便,在创建结构体时,最好用typedef对结构体进行重命名。
用typedef重命名后,在创建结构体变量或结构体指针时,用下列等式右边的即可:
- struct obs_head = obs_head
- sturct obs_head* = pobs_head
时间系统中,年、月、日、时、分都以整数形式记录,秒用小数记录。
O文件头结构体:
//观测值头文件
typedef struct obs_head
{
double ver;//RINEX文件版本号
char type[30];//文件类型
double apX;//测站近似位置XYZ(WGS84)
double apY;
double apZ;
double ANTH;//天线高
double ANTdeltaE;//天线中心对于测站标志在东方向上的偏移量
double ANTdeltaN;//天线中心对于测站标志在北方向上的偏移量
int WAFL1;//缺省的L1载波的波长因子
int WAFL2;//缺省的L2载波的波长因子
int WAFflag;
int obstypenum;//观测值类型数量
char obstype[15];//rinex2.0观测值类型列表
double interval;//观测值的历元间隔
int f_y;//第一个观测记录的时刻
int f_m;
int f_d;
int f_h;
int f_min;
double f_sec;
char tsys[5];//时间系统
}obs_head,*pobs_head;
O文件历元信息结构体
//观测值历元数据结构体
typedef struct obs_epoch
{
//观测历元时刻
int y;
int m;
int d;
int h;
int min;
double sec;
int p_flag;//历元标志
int sat_num;//当前历元所观测到的卫星数量
int sPRN[24];//当前历元所能观测到的卫星的PRN列表
}obs_epoch,*pobs_epoch;
O文件数据块结构体
//观测值数据结构体
typedef struct obs_body
{
double obs[24][15];//观测值
}obs_body,*pobs_body;这里的24对应同时观测到的最大卫星数,15对应着15种类型的观测值,对于单系统而言,这是非常安全的数字,不会出现溢出的现象。
O文件读取
文件读取的思路是:
- 创建文件指针,打开文件
- 从数据块开始,读取O文件由多少个历元
- 分别创建O文件头和O文件数据块的指针,并为其开辟内存。
- 将数据依次按行进行读取
- 关闭文件
具体代码如下:
//数据读取
FILE* fp_obs = NULL;//观测值文件指针
pobs_head obs_h = NULL;
pobs_epoch obs_e = NULL;
pobs_body obs_b = NULL;//创建结构体指针,并将其初始化为空
//O文件读取
fp_obs = fopen("abpo0480.15o", "r");//以只读的方式打开O文件
int o_epochnum = get_epochnum(fp_obs);//获取O文件历元数
rewind(fp_obs);
obs_h = (pobs_head)malloc(sizeof(obs_head));//给O文件头开辟空间
obs_e = (pobs_epoch)malloc(sizeof(obs_epoch) * o_epochnum);
obs_b = (pobs_body)malloc(sizeof(obs_body) * o_epochnum);
if (obs_h && obs_e && obs_b)
{
read_h(fp_obs, obs_h);//读取O文件头
read_b(fp_obs, obs_e, obs_b, obs_h->obstypenum);//读取O文件数据块
}
fclose(fp_obs);//关闭O文件上述代码种,get_epochnum为自行创建的函数,获取O文件的历元数,read_h和read_b也是创建的函数,分别是读取文件头和读取数据块。
获取O文件历元数(get_epochnum)
用fgets函数逐行对文件进行读取:
fegts函数需要包含头文件
- char * fgets ( char * str, int num, FILE * stream );
- 输入一个char*类型的指针(用来存放读取的数据),读取的个数,文件指针,其返回类型为char* 也就是读取后的新位置。
//获取O文件历元数
extern int get_epochnum(FILE* fp_obs)
{
int n = 0;//记录历元数
int satnum = 0;//记录每个历元的卫星数
char flag;//存放卫星标志符号'G'
char buff[MAXRINEX];//存放读取的字符串
while (fgets(buff, MAXRINEX, fp_obs))
{
satnum = (int)strtonum(buff, 30, 2);
strncpy(&flag, buff + 32, 1);
if (flag == 'G')
{
n++;
}
//当卫星数超过12个时,一行存不下会转到下下一行,并且与上一行对齐
//所以当出现这种情况时,要减1
if (flag == 'G' && satnum > 12)
{
n--;
}
}
return n;
}上述代码中:
- n为记录的历元数,也是最后的返回值
- satnum是每个历元的卫星个数,用来判断是否有超过12颗卫星的情况,有换行情况结果需要减1
- buff用来临时存储fgets读取到的数据
- falg用来存放第32个字符,也就是第一个卫星的'G'字符,如果该行的第32个字符是'G' ,则表明该行是历元的开始,以此结果计数
字符串转换成浮点数(strtonum)
在用fgets函数读取数据时,我们是创建了一个buff的字符串接收的,对于正好是字符串类型的信息,例如观测类型tpye,我们可以利用strncpy函数,对字符串进行拷贝,拷贝到我们创建的结构体变量中。
先介绍一下strncpy函数:
- char * strncpy ( char * destination, const char * source, size_t num );
- strncpy和strcpy都是C语言库函数中拷贝字符串的,而strncpy加上了对拷贝字符个数的限制,更加安全
- 输入三个参数,目标地址,源头地址,拷贝字符个数
- 返回值为目标的地址
- 需包含头文件
但是很多参数是int、double类型的,那么我们需要先将其从char类型转换成double类型的,再对结构体成员进行赋值。
stronum的讲解在N文件读取中有详细解释,这里只放代码,代码中有详细注释。
//将字符串转换为浮点数,i起始位置,n输入多少个字符
static double strtonum(const char* buff, int i, int n)
{
double value = 0.0;
char str[256] = { 0 };
char* p = str;
/************************************
* 当出现以下三种情况报错,返回0.0
* 1.起始位置<0
* 2.读取字符串个数= 0; buff++)
{
//三目操作符:D和d为文件中科学计数法部分,将其转换成二进制能读懂的e
*p++ = ((*buff == 'D' || *buff == 'd') ? 'e' : *buff);
}
*p = '\0';
//三目操作符,将str中存放的数以格式化读取到value中。
return sscanf(str, "%lf", &value) == 1 ? value : 0.0;
}O文件头读取
当前期的准备工作完成后,后期的读取工作则非常简单了,主要思想如下:
- 按每个历元为单位,f进行循环读取
- 每个数据块利用switch语句按行进行读取
- 读取的时需要对标O文件,找到数据对应的格式
//读取O文件数据头
extern void read_h(FILE* fp_obs, pobs_head obs_h)
{
char buff[MAXRINEX] = { 0 };
char* lable = buff + 60;
int i = 0;
int j = 0;
while (fgets(buff, MAXRINEX, fp_obs))
{
if (strstr(lable, "RINEX VERSION / TYPE"))
{
obs_h->ver = strtonum(buff, 0, 9);
strncpy(obs_h->type, buff + 20, 30);
continue;
}
else if (strstr(lable, "APPROX POSITION XYZ"))
{
obs_h->apX = strtonum(buff, 0, 14);
obs_h->apY = strtonum(buff, 0 + 14, 14);
obs_h->apZ = strtonum(buff, 0 + 14 + 14, 14);
continue;
}
else if (strstr(lable, "ANTENNA: DELTA H/E/N"))
{
obs_h->ANTH = strtonum(buff, 0, 14);
obs_h->ANTdeltaE = strtonum(buff, 14, 14);
obs_h->ANTdeltaN = strtonum(buff, 14 + 14, 14);
continue;
}
else if (strstr(lable, "WAVELENGTH FACT L1/2"))
{
obs_h->WAFL1 = (int)strtonum(buff, 0, 6);
obs_h->WAFL2 = (int)strtonum(buff, 6, 6);
obs_h->WAFflag = (int)strtonum(buff, 6 + 6, 6);
continue;
}
else if (strstr(lable, "# / TYPES OF OBSERV"))
{
obs_h->obstypenum = (int)strtonum(buff, 0, 6);
if (obs_h->obstypenum <= 9)
{
for (i = 0; i < obs_h->obstypenum; i++)
{
strncpy(&(obs_h->obstype[i]), buff + 10 * i, 2);
}
}
else if (obs_h->obstypenum > 9)
{
for (i = 0; i < 9; i++)
{
strncpy(&(obs_h->obstype[i]), buff + 10 * i, 2);
}
fgets(buff, MAXRINEX, fp_obs);
for (i = 0; i < obs_h->obstypenum - 9; i++)
{
strncpy(&(obs_h->obstype[i + 9]), buff + 10 * i, 2);
}
}
continue;
}
else if (strstr(lable, "INTERVAL"))
{
obs_h->interval = strtonum(buff, 0, 11);
continue;
}
else if (strstr(lable, "TIME OF FIRST OBS"))
{
obs_h->f_y = (int)strtonum(buff, 0, 6);
obs_h->f_m = (int)strtonum(buff, 6, 6);
obs_h->f_d = (int)strtonum(buff, 6 + 6, 6);
obs_h->f_h = (int)strtonum(buff, 6 + 6 + 6, 6);
obs_h->f_min = (int)strtonum(buff, 6 + 6 + 6 + 6, 6);
obs_h->f_sec = strtonum(buff, 6 + 6 + 6 + 6 + 6, 6);
strncpy(obs_h->tsys, buff + 6 + 6 + 6 + 6 + 6 + 18, 3);
continue;
}
else if (strstr(lable, "END OF HEADER"))
break;
}
}上述代码中,char* lable +60用来定位到文件头的标签位置。通过strstr(需要包含
在观测值类型那一行,需要注意同样的问题,即:观测值类型过多时会转到下一行,这里需要判断一下最左侧的数字是否>9。
其他位置则是对应O文件,输入特定的格式即可。
O文件数据块读取
主要思想:
- 按每个历元进行读取(大循环)
- 每个历元中,按每颗卫星进行读取(中循环)
- 每颗卫星中,按行进行读取(有几行取决于观测值类型的数量)(小循环)
//读取O文件数据块
extern void read_b(FILE* fp_obs, pobs_epoch obs_e, pobs_body obs_b, int type)
{
int n = 0;//历元数
int i = 0;//第i颗卫星
int j = 0;//第i颗卫星的第j行观测值
int k = 0;//第j行第k个观测值
char buff[MAXRINEX] = { 0 };
char flag = { 0 };//判断符号
while (fgets(buff, MAXRINEX, fp_obs))
{
//按照格式将历元参考时间依次存入,年需+2000
//除秒以外,均转换成整型
obs_e[n].y = (int)strtonum(buff, 1, 2) + 2000;
obs_e[n].m = (int)strtonum(buff, 4, 2);
obs_e[n].d = (int)strtonum(buff, 7, 2);
obs_e[n].h = (int)strtonum(buff, 10, 2);
obs_e[n].min = (int)strtonum(buff, 13, 2);
obs_e[n].sec = strtonum(buff, 15, 11);
obs_e[n].p_flag = (int)strtonum(buff, 28, 1);
//输入卫星数
obs_e[n].sat_num = strtonum(buff, 29, 3);
strncpy(&flag, buff + 32, 1);
//判断卫星数是否超过12,分类处理
if (obs_e[n].sat_num <= 12 && flag == 'G')
{
for (i = 0; i < obs_e[n].sat_num; i++)
{
//将卫星编号存储到第n个历元中,第i个PRN位置(只读数字,不读'G')
//两个卫星编号的间隔为3个字符
obs_e[n].sPRN[i] = strtonum(buff, 33 + 3 * i, 2);
}
}
//如果卫星数超过12个,则下一行继续执行读取卫星数
else if (obs_e[n].sat_num >= 12 && flag == 'G')
{
for (i = 0; i < 12; i++)
{
obs_e[n].sPRN[i] = strtonum(buff, 33 + 3 * i, 2);
}
fgets(buff, MAXRINEX, fp_obs);
for (i = 0; i < obs_e[n].sat_num - 12; i++)
{
obs_e[n].sPRN[i + 12] = strtonum(buff, 33 + 3 * i, 2);
}
}
//对一块历元中的i个卫星进行数据读取
for (i = 0; i < obs_e[n].sat_num; i++)
{
//根据头文件读取的观测值类型判断每一颗卫星循环几行
for (j = 0; j < (int)ceil(type / 5.0); j++)//ceil(X),返回比X大的最小整数
{
int count = type / 5;//计数
fgets(buff, MAXRINEX, fp_obs);
//依次读取一行中的观测值
//这里加个三目操作符判断一下,是不是到了最后一行,如果到了最后一行则不进行整行读取
for (k = 0; j == count ? k < type % 5 : k < 5; k++)
{
obs_b[n].obs[i][k + 5 * j] = strtonum(buff, 16 * k, 16);
}
}
}
n++;
}
}
上述代码中,需要注意:
- 除了需要传入文件指针、结构体指针外,还需要将头文件中读取到的观测值类型的数量传入其中,便于数据读取处的判断。
- 在读取时间时,年需要加2000,秒是double类型的
- 卫星数>12和卫星数<12需要分开考虑
- for (k = 0; j == count ? k < type % 5 : k < 5; k++),其中j == count ? k < type % 5 : k < 5为三目操作符,用来判断该行是否还需要整行读取。
不同版本的观测值文件格式会有差异,但是大体思路都是一致的,历元——卫星——观测值,以上,便是观测值文件读取的全部内容了,