【论文精读】A view-free image stitching network based on global homography-基于全局单应的无视图图像拼接网络
论文链接地址
代码链接地址
关于本文的代码,我已经调试过了,在调试过程中遇到的错误,我也做了一些总结,有需要的可以参考这篇博文。A view-free image stitching network based on global homography代码调试
文章目录
-
-
- 前言
- 摘要
- 一、介绍
- 二、相关工作
-
-
- 2.1 传统图像拼接
- 2.2 深度图像拼接
-
- 三、我们的方法
-
-
- 3.1 单应估计阶段
- 3.2 结构缝合阶段
- 3.3 内容修订阶段
- 3.4 损失函数
-
- 四、数据生成
- 五、实验
-
-
- 5.1 实现细节
- 5.2 与深度单应估计比较
- 5.3 与图像拼接算法比较
- 5.4 消融实验
-
- 六、总结
-
前言
L. Nie, C. Lin, K. Liao, M. Liu, and Y. Zhao, “A view-free image stitching network based on global homography,” Journal of Visual Communication and Image Representation, p. 102950, 2020. 本文提出了一种基于全局单应性的视角自由的图像拼接网络,简称VFISNet。
算法框架如下图:
 主要包括三个阶段:
主要包括三个阶段:
- Homography Estimation
- Structure Stitching
- Content Revision
**本文的主要贡献:**
1. 提出了一个视角自由的图像拼接网络
2. 为了尽可能减轻伪影,设计了一个global correlation层和一个结构到内容逐渐拼接模块
3. 构造了一个图像拼接合成数据集,图像之间的重叠区域更小
**本文的两大局限性:**
1. 不能处理任意分辨率的输入。
2. 合成数据集中没有视差。
因此,本文提出的网络在真实场景中的泛化能力并不理想。
摘要
图像拼接是一项传统但具有挑战性的计算机视觉任务,其目标是获得无缝的全景图像。最近,研究人员开始利用深度学习来研究图像拼接任务。然而,现有的学习方法在图像捕获过程中假设了一个相对固定的视图,因此对灵活视图的泛化能力较差。为了解决上述问题,我们提出了一种基于全局单应的级联无视图图像拼接网络。这种新颖的图像拼接网络不受图像视图的限制,可以分三个阶段实现。特别地,我们首先从不同的角度估计两个输入图像之间的全局单应性。然后提出了一个结构拼接层,利用全局单应性得到粗拼接结果。在最后一个阶段,我们设计了一个内容修改网络,以消除重影效应并细化缝合结果的内容。为了能够有效地学习各种视图,我们还提出了一种生成用于网络训练的合成数据集的方法。实验结果表明,与传统方法相比,我们的方法可以在非重叠区域以可接受的轻微失真为代价,几乎100%地消除重叠区域中的伪影。此外,所提出的方法是无视图的,特别是在特征点难以检测的场景中更具鲁棒性。
一、介绍
图像拼接是一种技术,通过拼接具有重叠部分的图像,可以创建无缝全景或高分辨率图像。图像可以从不同的时刻、不同的视角或不同的传感器获得。近年来,它受到越来越多的关注,已成为摄影图形、监控视频[1]和虚拟现实[2]等领域的热门话题。
经典的图像拼接遵循以下步骤。首先,在对图像进行特征提取和特征匹配后,估计出包括平移、旋转、缩放和消失点变换的3×3单应矩阵。然后利用单应性使原始图像与另一图像对齐。最后对原始图像和变形图像进行融合,得到拼接结果。然而,这种基本算法需要满足一个基本假设:图片的场景应该接近平面[3]。事实上,图像内容的深度总是不同的,这并不满足先前的假设。因此,很容易对缝合图像中的重叠部分造成重影效果或错位。为了减轻重影效果并提高缝合质量,一些现有的图像缝合算法计算多个内容感知局部扭曲[4–11]以对齐图像的重叠部分,一些算法通过找到最佳接缝来减少使用投影变换生成的伪影[12–15]围绕对象。对于深度拼接方法,有些方法[16–20]适合于拼接任意视图的图像,但其框架中只有一些步骤,如特征提取或特征匹配,是通过深度学习实现的,不能称之为完整的深度图像拼接模型。其他一些方法[21–23]都是通过深度学习来实现的,但它们只是针对某些特定情况而专门设计的,例如固定视图。
与这些深度拼接方法不同,我们的目标是建立一个完整的深度学习模型,能够处理从任意视图捕获的图像。在本文中,我们提出了一种基于全局单应的级联无视图图像拼接网络,它可以尽可能地消除重影效应。
我们的方法概述如图1(e)所示。具体来说,第一阶段是单应估计。与现有的深单应估计不同[24–26],在我们的图像拼接中,两幅图像之间重叠部分的比例要低得多,这给拼接性能带来了很大的挑战。为了解决这个问题,我们通过计算特征地图中每个位置之间的全局相关性,在此阶段引入了全局相关性层[27,28]。第二阶段利用第一阶段得到的单应性对原始图像进行扭曲,并对扭曲后的图像进行平均融合,得到结构拼接结果。最后一个阶段称为内容修订阶段。基于已知的结构先验知识,我们设计了一个内容修改网络来消除重叠区域的重影效应,并修改缝合内容以获得感知自然的结果。
此外,训练网络生成缝合图像需要足够大的训练集。受DeTone等人[24]的启发,我们改进了为深度单应估计构建合成数据集的方式,并建议创建一个看似无限的数据集,由四个(IA、IB、f、Label)组成,用于图像拼接。数据集生成的管道如图1(a)-(d)所示。我们特别设计的网络和数据集使我们的算法能够处理任意视图的图像输入,从而将深度图像拼接从图像视图的限制中解放出来。
在实验中,我们证明了所提出的方法在很大幅度上优于以前的方法,证明了其在深度图像拼接中的有效性。本文的**贡献 **可总结如下:
①提出了一种无视图的图像拼接网络。据我们所知,这是第一个能够处理深度图像拼接领域中任意视图图像的工作。
②为了尽可能地消除重影效应,我们设计了一个全局相关层和一个结构到内容的渐进拼接模块。
③为了实现视差容忍拼接算法,我们为训练网络构建了一个合成数据集,该数据集显示了比以前方法更具挑战性的重叠部分。
本文的其余部分组织如下:第2节描述了相关工作。第3节和第4节分别介绍了所提出的无视图图像拼接网络和构建的合成数据集。第5节描述了实验。第6节讨论了结论和未来方向。
二、相关工作
在这一部分中,我们简要回顾了传统的图像拼接方法和深度图像拼接方法。
2.1 传统图像拼接
在传统的图像拼接方法中,有些方法计算了多个内容感知局部扭曲来代替单个全局扭曲以达到更好的局部对齐[4–11],有些方法提出寻找对象周围的最佳接缝以减少图像融合产生的伪影[12–15]。
在第一组方法中,Gao等人[4]发现通过单一单应性对齐图片具有明显的局限性,当场景深度不一致时,很容易产生伪影。将图像分为前景和背景,通过计算双单应性扭曲(DHW)来缓解该问题。基于他们鼓舞人心的工作,提出了尽可能投影(APAP)[6],将图像划分为密集网格,并将每个网格与唯一的局部单应性对齐。Zaragoza等人极大地减少了由于深度不一致而造成的重影效果,同时在非重叠区域带来了几何失真。同时,Chang等人[7]提出了一种保形半投影(SPHP)翘曲,通过该翘曲,非重叠区域的投影变换逐渐减少为仅包括平移、旋转和缩放的相似变换,以减少投影变换引起的几何失真。将APAP与SPHP相结合,Lin等人[10]提出了一种尽可能自然的自适应(ANAP)翘曲,以实现更自然的缝合结果。
接缝驱动的方法也有影响。在Eden等人[12]的工作中,除了引入数据代价来约束内容一致性外,还引入了接缝代价来增强重叠区域的平滑过渡。由于我们期待一个无缝拼接的图片,接缝切割可以是一个关键的步骤,以获得一个感知无缝的结果。通过寻找最佳单应性,提出了一种接缝驱动的图像拼接策略[15]。然后,Zhang等人[13]提出了一种对齐算法,寻找图像拼接的最优接缝,然后使用多波段混合算法得到最终的拼接结果。在上述工作的基础上,Lin等人[14]改进了接缝驱动方法,增加了保持曲线和直线结构的约束,实现了视差容忍的图像拼接。
2.2 深度图像拼接
与传统的图像拼接方法相比,深度拼接方法仍处于发展阶段。一些作品[16–18]用CNN取代传统的特征检测,以追求更好的缝合性能,而另一些作品使用神经网络来学习匹配特征[19]或根据检测到的特征估计变换参数[20]。除此之外,还有一些完整的深度学习方法专门针对某些特定条件而设计,如固定视图[21,23],鱼眼相机固定视图[22]等。据我们所知,目前还没有完整的深度学习方法可以执行无视图图像拼接。
三、我们的方法
Homography estimation stage

Structure stitching stage
===========================================================================================
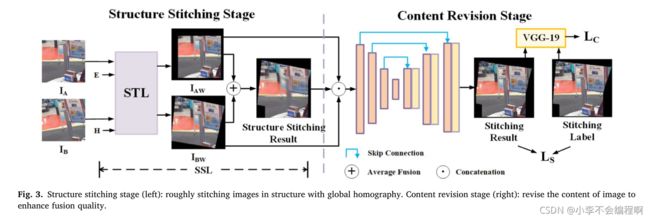
本部分主要就是介绍本文提出的拼接网络VFISNet的具体细节:
**1. Homography estimation stage**
单应性估计阶段就是基于先前的DHN方法,一个VGG风格的特征提取骨干网络。接着为了减小平均角点误差,提升单应性估计精度,从光流估计方法(PWC-Net、Flownet2等)得到启发,作者引入了一个Global Correlation层,然后接了三个卷积层和两个全连接层,输出是8个参数的f ff,表示图像 IB 相对于图像 IA 四个顶点的偏移量。再通过DLT层计算出图像 IB 变换到图像 IA 的单应性矩阵H。
**2. Structure stitching stage**
结构拼接阶段是基于空间变换网络。对于IA,使用单位矩阵,变换为IAW;对于IB,使用单应性估计阶段得到的H,变换为IBW,IAW和IBW通过平均融合得到Structure Stitching Result。再将IAW、IBW、Structure Stitching Result连接得到一个9通道的图像。此时得到的是一个粗对齐拼接结果,因为单应性估计是从图像四个顶点的偏移量计算出,不会将每个像素对齐,一点预测误差就会导致整个拼接结果视觉上的模糊。
**3. Content revision stage**
内容修正阶段是一个UNet网络,输入是粗对齐拼接结果,输出是精确对齐拼接结果。
**4. Loss function**
① 对于单应性估计阶段,损失函数是预测偏移量和ground truth偏移量之间的MSE误差;
②对于内容修正阶段,损失函数是预测拼接结果和ground truth label之间的L1误差,此外还加上了VGG19前4层提取特征图之间的L2误差。
===========================================================================================
为了拼接任意视图的图像,我们提出了一种基于全局单应的无视图图像拼接网络。如图1(e)所示,我们的方法包括三个阶段,每个阶段在图像拼接中起着独特的作用,具体的网络结构如图2和图3所示。在本节中,我们首先描述所提出的单应估计阶段。然后,我们描述了结构缝合阶段和内容修改阶段。最后,建立了无视点图像拼接网络的损失函数。
3.1 单应估计阶段
利用深度学习直接拼接大视差图像非常困难,因为它将特征检测、特征匹配、单应估计、图像配准和图像融合等任务集成到CNN中。因此,为了将CNN从复杂的任务中解放出来,一个预先训练好的单应估计网络是非常必要的。在这一阶段,我们的目标是获得图像之间的投影变换,从而为后续的拼接工作提供对齐信息。更重要的是,这一阶段对于我们的网络执行无视图图像拼接至关重要。
传统单应估计的步骤包括特征提取、特征匹配和通过直接线性变换(DLT)算法求解单应[29]。DLT可以作为从不同视角拍摄的两幅图像之间的一组匹配点估计投影变换的基本方法。相比之下,大多数深层单应性估计方案[24–26]仅由卷积神经网络完成,卷积神经网络可以作为一个优秀的特征提取工具,但相对缺乏特征匹配能力。考虑到单应估计和光流估计[28,30–32]都可以归结为在一对图像之间建立密集对应的问题,我们将光流估计中常用的全局相关层[27,28,32]引入到我们的工作中,以增强特征匹配部分。
与其他单应估计一致[24–26],我们也使用灰度图像(GA,GB)作为网络输入。首先,使用具有共享权重的特征提取器来学习特征表示并降低图2蓝色部分中的特征映射的维数。这里每个小的蓝色块包括两个卷积层和一个最大池层。对特征映射FIA,FIB ∈Wl×Hl×Cl进行L2归一化后,采用全局相关层来学习两个特征映射之间的特征全局相似性CVl∈Wl×Hl× (Wl×Hl)。对于FlA中的每个位置,我们需要计算其与FlB中每个位置的相关性,如下所示:
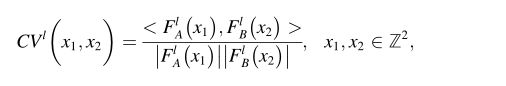
其中x1和x2定义了特征图中的位置,FlA(x1)表示特征图FlA中位置x1的一维特征向量。如上述公式所示,CVl(x1,x2)在0和1之间变化,且FlA(x1)和FlB(x2)越相似,CVl(x1,x2)越大,这也意味着特征匹配越好。
随后,使用由三个卷积层和两个完全连接层组成的回归网络来处理CVl和预测偏移量f,偏移量f可以与单应性一一对应,并将在第4节中详细说明。最后,通过DLT算法将预测的偏移量转换为相应的张量单应H。
估计出的全局单应性提供了全局对齐信息,可方便地用于后续结构缝合阶段。利用这种单应性,我们可以将具有大视差的图像对转换为具有小视差的图像对。通过将大视差图像拼接问题转化为小视差图像拼接问题,显著降低了CNN图像拼接的难度。
3.2 结构缝合阶段
在没有结构先验的情况下从头开始训练缝合网络是非常困难的,因为它需要同时学习缝合图像的结构信息和内容细节。为了解决这个问题,我们将剩下的拼接工作分为结构拼接和内容修改两部分。在此阶段,我们确定缝合图像的粗略轮廓,这能够为后续内容修订阶段提供重要的结构先验信息。
为了实现结构拼接,我们对[33]中介绍的空间变换层(STL)进行了改进,提出了一种结构拼接层(SSL)来获取拼接图像的结构信息。该部分分为四个步骤完成,如图3(左)所示。
首先,为每个图像输入生成一个与缝合标签大小相同的网格。网格中的每个元素表示其二维空间位置(u,v)。
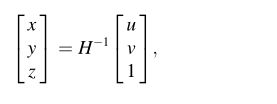
其中H表示从IB到IA的投影变换。(x,y,z)是原始图像的齐次坐标。我们通过等式2获得IBW的相应坐标,同时通过用同一等式中的单位矩阵E替换H来获得IAW的坐标。
在第三步中,我们通过双线性插值直接得到光滑的扭曲图像。最后,对IAW和IBW进行平均融合,得到结构拼接结果。具体来说,重叠区域的像素值等于IAW和IBW的像素值之和,加权0.5。
在我们的整个拼接模型中,SSL充当桥梁,将估计的H转换为可供内容修订网络使用的结构拼接结果。然而,在SSL中求解H的逆和双线性插值的过程可能会影响我们训练阶段中梯度的反向传播。为了避免这个问题,我们在不进行联合优化的情况下分别训练我们的单应估计网络和其他部分。这样,作为一个结合了空间变换和图像融合的模块,无需训练参数,无论训练网络的哪个部分,SSL都不会对训练过程中的反向传播产生影响。
3.3 内容修订阶段
基于特征失配可能导致单应估计误差的事实,结构拼接图像中的重叠区域不可避免地存在重影效应。因此,提出了一种内容修改阶段,以消除重叠区域中的伪影,同时保持非重叠区域的内容不发生显著失真。
为了达到这个目标,我们设计了一个编码器-解码器网络来消除伪影并修改缝合结果的内容。如图3(右)所示,该模块首先通过8个卷积层从结构缝合结果中提取特征,其中每层的滤波器数量分别设置为64、64、128、128、256、256、512和512。随着卷积核数的指数增长,编码器将三通道RGB图像的结构拼接结果分解为多通道特征的表示,最后分解为特征基的表示。为了减少计算量,在第二、第四和第六卷积层之后,采用2×2最大池层来降低特征图的维数。至于解码器,其结构可以被视为编码器的镜像,在最后一层有三个通道。该解码器设计用于将特征基重组为更复杂的特征表示,并将特征基重组为期望的缝合结果。此外,为了防止梯度消失问题和每层中的信息不平衡[34],我们在具有相同分辨率的低级和高级特征之间添加了跳过连接。
3.4 损失函数
本质上,深层单应网络[24–26]可以被视为解决单应的八个参数的回归任务。即使在无监督估计方法[25,26]中,在计算无监督损失函数之前,也必须首先预测单应性。因此,在我们的工作中,我们直接采用一种更简单但更有效的监督方法,通过最小化预测偏移量f^与其地面真值f之间的L2距离来估计单应性,如下所示:
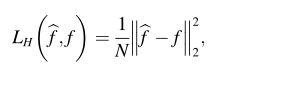
其中N定义偏移量f^中的组件数量。
为了约束缝合图像的结构尽可能接近标签的结构,在输出和标签之间的对应位置使用L1损耗:
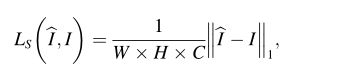
其中I^和I分别表示缝合结果和缝合标签。W、H和C定义缝合结果的宽度、高度和通道数。
受[35,36]的启发,我们还基于VGG-19[37]定义了一个内容丢失,它鼓励输出和标签具有类似的特征表示。随着内容的丢失,容易导致图像特征发生剧烈变化的图像接缝的伪影和不连续性可以显著减少。设ψj(⋅) 是从VGG-19中的第j个卷积层获得的特征图,含量损失定义为以下等式:
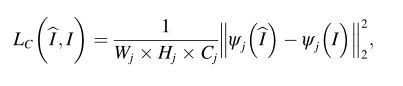 其中Wj、Hj和Cj分别表示特征地图的宽度、高度和通道号。
其中Wj、Hj和Cj分别表示特征地图的宽度、高度和通道号。
四、数据生成

===========================================================================================
数据集生成的过程如上图所示:
**1.** 首先在COCO2014数据集的一张图片上随机裁剪出一个128×128的区域,如图中绿框所示,作为IA;
**2.** 接着在[-64, 64]范围内进行随机位移,得到图中蓝框;
**3.** 然后在[-25, 25]范围内对图像四个顶点随机扰动,得到图中红框,红框相对于绿框四个顶点的偏移量就作为单应性估计阶段的ground truth偏移量,红框和绿框围成的像素内容作为内容修正阶段的Label;
**4.** 将绿框到红框计算出的单应性矩阵逆变换应用到原图上,在蓝框位置处裁剪出IB。
从而得到一组训练样本(IA,IB,f,Label)。
===========================================================================================
训练神经网络通常需要大量的数据。然而,现有的图像拼接数据集只有少量的数据,这不足以用于深度学习方法。为了满足这一要求,我们改进了生成用于深度单应估计的合成数据集的方法[25],并提出了一种可以从任何现有的真实图像数据集(如Microsoft COCO[38])生成用于图像拼接的看似无限的数据的方法。数据集生成的管道如图1(a)-(d)所示,该过程的细节描述如下。
在我们的工作中,每幅真实图像将生成一个四重(IA,IB,f, Label),其中IA和IB是一对从不同角度重叠区域的图像,Label是拼接结果的真值,f代表8个偏移,对应一个8自由度的单应性。与纯单应估计方法相比[24-26],我们的图像对重叠区域明显较小。特别是,在对蓝色方块的四个顶点(pix,piy∈[−p,p])进行扰动以获得不同的视角之前,我们首先进行随机平移操作(tx,ty∈[−t,t]),以确保两幅图像中只有一小块区域是重叠的。图1 (a)(b)©)中四个顶点的总偏移量f可由以下公式计算:

其中i∈{1,2,3,4}定义了正方形的不同点。Fix和fiy分别表示点I在x和y方向上的偏移量。
对于卷积神经网络,当我们确定输入的大小时,输出的大小也是确定的。然而,当涉及到图像拼接时,尽管图像大小相同,但拼接结果的大小根据图像对的不同透视图而变化。为了解决这一矛盾,我们设置了缝合标签的最大大小,以确保所有标签都可以完全包含在画布中。最大大小可以通过在图像块IA的顶部、底部、左侧和右侧展开TP像素来计算。最后,我们通过将原始图像裁剪成预设大小并用值0填充绿色和红色正方形外的区域,获得感知无缝和自然的缝合标签,如图1(e)所示。
五、实验
===========================================================================================
**概括:**
训练过程总共分两步,先训练Homography estimation stage,再训练后面Content revision stage。
**评价:**
1. 与深度单应性估计方法比较
2. 与现有拼接方法比较
3. 消融实验
===========================================================================================
在本节中,首先将提出的单应估计模块与其他深度单应估计方法进行比较,以验证其在大视差下对齐图像的能力。并与经典的图像拼接算法进行了对比实验。最后,进行了烧蚀研究,以验证每个组件的效率。
5.1 实现细节
由于在图像拼接领域中没有基准数据集,我们使用第4节中提出的方法获得了一个合成数据集。具体来说,我们从MS-COCO中选取了50000幅大于480×360的真实图像来生成训练集,同时提取1000幅图像来生成测试集。网络输入(IA、IB)的大小为128×128,而标签的大小设置为304×304,以覆盖任意视图的所有缝合结果。考虑到图像拼接中图像输入的重叠率可能非常小,我们设置了最大平移参数t=64和最大扰动参数p=25,使得数据集中的重叠率在20%到100%之间。
随后,我们按照两个步骤训练我们的网络。首先,我们只通过最小化LH来训练单应估计网络。采用Adam Optimizer[39],学习率在0.0002到0.00002之间。其次,我们的网络的其余部分是通过同时最小化LS和LC来进行训练的,训练策略与前面的步骤几乎相同。实际上,我们打算在第二步对整个网络进行训练,期望在初步实验中,在结构损失和内容损失的约束下,单应估计器得到进一步优化。但实验结果表明,当梯度从内容修正模块反向传播到单应估计模块时,单应估计的精度会降低,因此我们将这两部分分别训练。
5.2 与深度单应估计比较
现有的深层单应估计[24–26]已经取得了有希望且稳健的结果。我们注意到,有监督方法[24]和无监督方法[25]对于单应预测采用几乎相同的VGG式结构,唯一的区别是它们的损失函数不同。但无论损失函数是什么,它们在[25]的实验中表现几乎相同。
另一件需要注意的是,他们使用的数据集[24,25]与我们的数据集非常不同。主要区别在于,图像对在其数据集中的重叠率在60%到100%之间,而在我们的数据集中,最小重叠率可以是20%。因此,直接将我们的工作与他们现有的实验结果进行比较是不公平的。观察到这一事实后,我们只比较了不同方法下单应估计的性能。为了实现这一目标,我们严格控制除网络结构完全一致之外的所有条件。这些条件包括数据集、数据预处理和增强、优化器的选择、学习率和迭代次数等。
在本实验中,我们在1000个测试数据上评估了我们的模型。根据不同的重叠率,我们将测试数据分为8类,以探索不同模型预测的偏移量的平均RMSE,如图4所示。如我们所见,有监督[24]和无监督[25]所采用的VGG式网络的性能比我们的方法差近3倍。随着重叠率的降低,VGG模型的RMSE增长速度也明显快于我们的模型,这表明我们的模型对大视差拼接情况更具鲁棒性。
为了更直观地显示不同模型的性能,我们还对八个类别进行了一组对齐实验。图5显示了一些结果,其中(b)使用估计的单应性被扭曲以与(a)对齐。与其他学习方法相比,我们的结果在所有情况下都更接近基本事实。显然,重叠率越低,扭曲图像的大小应该越小。然而,当重叠率低于50%时,通过VGG样式方法获得的扭曲图像的大小显著大于图像大小的50%,这意味着该方法在低重叠率的情况下具有较差的对齐能力。相比之下,作为所提出的全局相关层的一个优点,我们的模型在低重叠率下仍然保持相当大的对齐性能。
5.3 与图像拼接算法比较
现有的深度缝合方法[23]从固定视图缝合图像,而我们的方法从任意不同的视图工作。因此,将他们的工作与我们的工作进行比较是不恰当的。取而代之,我们选择了几种具有代表性的图像拼接算法进行比较。具体来说,我们根据图像内容将测试集分为4类:重复模式、背景、远场景和近场景。然后,我们将我们的方法与传统的基线、APAP[6]、SPHP[7]和鲁棒ELA[11]进行比较。传统的基线方法由四个步骤完成,即SIFT[40]、RANSAC[41]、DLT和平均融合,为了简洁起见,在下文中将其简称为基线。结果如图6所示。
正如我们所看到的,先前方法的结果在重叠区域上表现出不同程度的重影效果。相反,我们的方法可以在非重叠区域以可接受的轻微失真为代价,几乎100%地消除重叠区域中的伪影。这种优势得益于我们提出的结构到内容渐进缝合模块,该模块充分利用了全局单应性和精细内容修改网络的结构先验。此外,如果我们更加关注图6中红色圆圈的内容,很容易发现,通过消除双线性插值产生的图像模糊,我们的结果在感知上更加自然,纹理更加细腻。
另一个优点是我们的方法更健壮,特别是在特征角点难以检测或特征点周围的纹理太相似的场景中。图7示出了基线的故障情况,其中“RANSAC”表示在特征匹配和RANSAC算法之后基线的中间过程。此外,红点表示RANSAC删除的不匹配点,绿点对表示正确的匹配点。如图7所示,RANSAC后的结果中仍然存在不匹配,例如最左侧的绿色特征点,这直接导致基线结果与地面真实值相差很远。对于其他缝合方法,结果与基线相似。与使用固定参数的传统算法提取特征不同,我们的方法通过学习可训练卷积滤波器来提取特征,这在其他类似领域(如光学估计)已被证明具有惊人的性能[28,30–32]。因此,即使在传统方法无法检测到足够的特征点的情况下,我们的无视图网络仍然具有相当可靠的鲁棒性。
5.4 消融实验
深度图像拼接的第一步是单应性估计,包括特征提取、特征匹配、偏移量预测和求解DLT。在单应性估计的帮助下,我们可以获得图像对齐的先验信息,使我们的网络具备无视图图像拼接的能力。为了验证这个模块的重要性,我们比较了在有单应性估计和没有单应性估计的情况下的性能,如表1 ’ w/o HE '和图8所示。具体来说,在没有HE提供的足够的结构先验信息的情况下,CNN很难学习从Ib视图到Ia视图对非重叠区域的无视图插值过程,与图8 ’ w/o HE ‘和’ Ours '相比。此外,根据网络结构的不同,我们还将单应性估计分为vgg型单应性估计(VGG-HE)和全局相关单应性估计(GC-HE)。在4.2节中,我们验证了这两种不同结构在单应性估计和图像对齐方面的性能。在后续的实验中,我们也评估了它们对图像拼接的影响。
SSL用于缝合图像的结构,它有助于获得缝合图像的基本轮廓,同时忽略可能的重影效果。SSL由空间变换层(STL)和张量平均融合组成。当我们使用SSL对网络进行训练时,我们可以获得更多关于缝合图像轮廓的先验信息,从而获得更精确的缝合结果。如图8所示,“w/o SSL”和“Ours”在图像内容上类似,而Ours的轮廓更平滑,更接近地面真实情况,尤其是在红色圆圈的部分。因此,我们可以获得更高的PSNR和SSIM,这意味着我们的结果具有更低的噪声误差和更高的结构相似性,如表1所示。
内容修订网络细化了前一阶段获得的结构缝合结果。对于重叠部分的图像,这部分网络可以消除几乎所有的重影效果;对于图像的非重叠区域,它可以重塑缝合图像的轮廓和结构,使接缝处的最终结果更自然。表1和图8还显示了有CR和无CR情况下的结果。与我们的结果相比,无CR情况下的缝合结果中可能存在明显的重影效应,其中“VGG-HE”比“GC-HE”有更多的伪影,因为GC-HE可以更准确地估计单应性。这一部分非常重要,没有CR的拼接图像的质量明显比我们的差,如表1所示,而单独使用CR网络没有任何影响。因此,只有完全包含HE、SSL和CR三个阶段的完整管道才能实现无自然视图的图像拼接。
六、总结
在本文中,我们提出了一种无视图图像拼接体系结构,可分为3个阶段:单应估计、结构拼接和内容修改。在单应性估计阶段,我们通过卷积层、全局相关层和回归网络分别提取特征、匹配特征和预测单应性。在第二阶段,利用单应性进行SSL结构拼接,确定拼接结果的粗轮廓。在内容修改阶段,在保持拼接结果轮廓不失真的同时,对图像内容进行细化。此外,还提出了一种生成无视图图像拼接数据集的方案,以实现对各种视图的有效学习。与现有的图像拼接算法相比,我们的无视图图像拼接网络几乎可以100%消除重叠区域中的伪影,并且在显著减少重影效果的情况下更具鲁棒性,特别是在特征角点难以检测的场景中。
完!