Visual Semantic Planning using Deep Successor Representations学习笔记
ABSTRACT
A crucial capability of real-world intelligent agents is their ability to plan a sequence of actions to achieve their goals in the visual world. In this work, we address the problem of visual semantic planning: the task of predicting a sequence of actions from visual observations that transform a dynamic environment from an initial state to a goal state. Doing so entails knowledge about objects and their affordances, as well as actions and their preconditions and effects. We propose learning these through interacting with a visual and dynamic environment. Our proposed solution involves bootstrapping reinforcement learning with imitation learning. To ensure cross task generalization, we develop a deep predictive model based on successor representations. Our experimental results show near optimal results across a wide range of tasks in the challenging THOR environment.
现实世界中智能agent的一个关键能力是,它们能够计划一系列行动,以实现其在可视世界中的目标。在这项工作中,我们解决了视觉语义规划的问题:从视觉观察中预测一系列动作的任务,这些动作将动态环境从初始状态转换为目标状态。这样做需要了解对象及其启示,以及行动及其先决条件和效果。我们建议通过与视觉和动态环境的互动来学习这些。我们提出的解决方案包括用模仿学习引导强化学习。为了保证跨任务的泛化,我们开发了一个基于后继表示的深度预测模型。我们的实验结果表明,在具有挑战性的THOR环境中,通过广泛的任务,我们得到了接近最优的结果。
AGENT
Agent的概念由Minsky在其1986年出版的《思维的社会》一书中提出。Minsky认为社会中的某些个体经过协商之后可求得问题的解,这些个体就是Agent。他还认为Agent应具有社会交互性和智能性。从此,Agent的概念便被引入人工智能和计算机领域,并迅速成为研究热点。
THOR
AI2-THOR是由艾伦人工智能研究所(AI2)、斯坦福大学、卡耐基梅隆大学、华盛顿大学、南加州大学合作完成的。它为人工智能Agent提供了一个室内装修效果图画风的世界,高度仿真,Agent可以和里面的各种家具家电交互——比如说打开冰箱、推倒椅子、把电脑放在桌子上等等。

为了让Agent与场景的交互尽可能接近真实,AI2-THOR除了包含表面上能看到的高质量3D场景之外,背后还有Unity 3D引擎,能让其中的物体遵循现实世界的物理规则来运动,也就是让交互动作尽可能真实。
另外,AI2-THOR还提供Python API。[1]
1 INTRODUCTION
Humans demonstrate levels of visual understanding that go well beyond current formulations of mainstream vision tasks (e.g. object detection, scene recognition, image segmentation). A key element to visual intelligence is the ability to interact with the environment and plan a sequence of actions to achieve specific goals; This, in fact, is central to the survival of agents in dynamic environments
人类表现出的视觉理解水平远远超出当前主流视觉任务(如目标检测、场景识别、图像分割)的公式。
视觉智能的一个关键要素是与环境互动的能力,以及为实现特定目标而计划一系列行动的能力;
事实上,这对于动态环境中代理的生存至关重要
Visual semantic planning, the task of interacting with a visual world and predicting a sequence of actions that achieves a desired goal, involves addressing several challenging problems. For example, imagine the simple task of putting the bowl in the microwave in the visual dynamic environment depicted in Figure 1. A successful plan involves first finding the bowl, navigating to it, then grabbing it, followed by finding and navigating to the microwave, opening the microwave, and finally putting the bowl in the microwave.
视觉语义规划的任务是与视觉世界进行交互,并预测实现预期目标的一系列动作,涉及解决几个具有挑战性的问题。例如,想象一下在图1所示的可视化动态环境中将碗放入微波炉的简单任务。一个成功的计划包括首先找到碗,导航到它,然后抓住它,然后找到并导航到微波炉,打开微波炉,最后把碗放入微波炉。
The first challenge in visual planning is that performing each of the above actions in a visual dynamic environment requires deep visual understanding of that environment, including the set of possible actions, their preconditions and effects, and object affordances. For example, to open a microwave an agent needs to know that it should be in front of the microwave, and it should be aware of the state of the microwave and not try to open an already opened microwave. Long explorations that are required for some tasks imposes the second challenge. The variability of visual observations and possible actions makes na ıve exploration intractable. To find a cup, the agent might need to search several cabinets one by one. The third challenge is emitting a sequence of actions such that the agent ends in the goal state and the effects of the preceding actions meet the preconditions of the proceeding ones. Finally, a satisfactory solution to visual planning should enable cross task transfer; previous knowledge about one task should make it easier to learn the next one. This is the fourth challenge.
视觉规划的第一个挑战是,在视觉动态环境中执行上述每个操作都需要对该环境有深入的视觉理解,包括一组可能的操作、它们的先决条件和效果,以及对象的可提供性。例如,要打开微波,一个代理人需要知道它应该在微波前面,它应该知道微波的状态,而不是试图打开一个已经打开的微波。第二个挑战是一些任务需要长时间的探索。视觉观察和可能的行动的可变性使得单纯的探索变得棘手。要找到一个杯子,代理可能需要一个一个地搜索几个柜子。第三个挑战是发出一系列动作,使代理以目标状态结束,并且前面动作的效果满足前面动作的先决条件。最后,视觉规划的一个令人满意的解决方案应该能够实现跨任务转移;以前对一项任务的了解应该会使学习下一项任务变得更容易。这是第四个挑战。
In this paper, we address visual semantic planning as a policy learning problem. We mainly focus on high-level actions and do not take into account the low-level details of motor control and motion planning.
在本文中,我们将视觉语义规划视为一个策略学习问题。
我们主要关注高级动作,不考虑电机控制和运动规划的低级细节。
Visual Semantic Planning (VSP) is the task of predicting a sequence of semantic actions that moves an agent from a random initial state in a visual dynamic environment to a given goal state.
视觉语义规划(Visual Semantic Planning, VSP)是预测一系列语义动作的任务,这些动作将代理从视觉动态环境中的随机初始状态移动到给定的目标状态。
To address the first challenge, one needs to find a way to represent the required knowledge of objects, actions, and the visual environment. One possible way is to learn these from still images or videos [12, 51, 52]. But we argue that learning high-level knowledge about actions and their preconditions and effects requires an active and prolonged interaction with the environment. In this paper, we take an interaction-centric approach where we learn this knowledge through interacting with the visual dynamic environment. Learning by interaction on real robots has limited scalability due to the complexity and cost of robotics systems [39, 40, 49]. A common treatment is to use simulation as mental rehearsal before real-world deployment [4, 21, 26, 53, 54]. For this purpose, we use the THOR framework [54], extending it to enable interactions with objects, where an action is specified as its pre- and post-conditions in a formal language.
要解决第一个挑战,需要找到一种方法来表示对象、操作和视觉环境所需的知识。一种可能的方法是从静态图像或视频中学习这些[12,51,52]。但我们认为,学习行动及其先决条件和效果的高级知识需要与环境进行积极和长期的互动。在本文中,我们采用了一种以交互为中心的方法,通过与可视化动态环境的交互来学习这些知识。由于机器人系统的复杂性和成本,在真实机器人上通过交互学习的可扩展性有限[39,40,49]。一种常见的处理方法是在实际部署之前使用模拟作为心理演练[4,21,26,53,54]。为此,我们使用了THOR框架[54],对其进行了扩展,以支持与对象的交互,其中一个操作在正式语言中指定为其前置和后置条件。
To address the second and third challenges, we cast VSP as a policy learning problem, typically tackled by reinforcement learning [11, 16, 22, 30, 35, 46]. To deal with the large action space and delayed rewards, we use imitation learning to bootstrap reinforcement learning and to guide exploration. To address the fourth challenge of cross task generalization [25], we develop a deep predictive model based on successor representations [7, 24] that decouple environment dynamics and task rewards, such that knowledge from trained tasks can be transferred to new tasks with theoretical guarantees [3].
为了解决第二个和第三个挑战,我们将VSP定义为一个策略学习问题,通常通过强化学习来解决[11,16,22,30,35,46]。针对行动空间大、奖励延迟的问题,我们采用模仿学习来引导强化学习,引导探索。为了解决交叉任务泛化[25]的第四个挑战,我们开发了一个基于后继表示的深度预测模型[7,24],该模型解耦了环境动力学和任务奖励,使得训练任务的知识可以在理论保证[3]的前提下转移到新的任务中。
In summary, we address the problem of visual semantic planning and propose an interaction-centric solution. Our proposed model obtains near optimal results across a spectrum of tasks in the challenging THOR environment. Our results also show that our deep successor representation offers crucial transferability properties. Finally, our qualitative results show that our learned representation can encode visual knowledge of objects, actions, and environments.
总之,我们解决了可视化语义规划的问题,并提出了一个以交互为中心的解决方案。我们所提出的模型在THOR环境的挑战下,在一系列任务中获得了接近最优的结果。我们的结果还表明,我们的深层继承表示提供了关键的可转移性。最后,我们的定性结果表明,我们的学习表示可以编码对象、动作和环境的视觉知识。
2. Related Work
Task planning. Task-level planning [10, 13, 20, 47, 48] addresses the problem of finding a high-level plan for performing a task. These methods typically work with highlevel formal languages and low-dimensional state spaces. In contrast, visual semantic planning is particularly challenging due to the high dimensionality and partial observability of visual input. In addition, our method facilitates generalization across tasks, while previous methods are typically designed for a specific environment and task.
任务计划。任务级计划[10,13,20,47,48]解决了为执行任务寻找高层次计划的问题。这些方法通常使用高级形式语言和低维状态空间。相比之下,由于视觉输入的高维性和部分可观测性,视觉语义规划就显得尤为具有挑战性。此外,我们的方法促进了任务间的泛化,而以前的方法通常是针对特定的环境和任务设计的。
Perception and interaction. Our work integrates perception and interaction, where an agent actively interfaces with the environment to learn policies that map pixels to actions. The synergy between perception and interaction has drawn an increasing interest in the vision and robotics community. Recent work has enabled faster learning and produced more robust visual representations [1, 32, 39] through interaction. Some early successes have been shown in physical understanding [9, 26, 28, 36] by interacting with an environment.
感知和交互。我们的工作集成了感知和交互,其中一个代理主动地与环境交互,以学习将像素映射到操作的策略。感知和交互之间的协同作用在视觉和机器人领域引起了越来越多的兴趣。最近的研究使学习变得更快,并通过交互产生了更健壮的视觉表示[1,32,39]。一些早期的成功已经通过与环境的互动在物理理解[9,26,28,36]方面得到了证明。
Deep reinforcement learning. Recent work in reinforcement learning has started to exploit the power of deep neural networks. Deep RL methods have shown success in several domains such as video games [35], board games [46], and continuous control [30]. Model-free RL methods (e.g., [30, 34, 35]) aim at learning to behave solely from actions and their environment feedback; while model-based RL approaches (e.g., [8, 44, 50]) also estimate a environment model. Successor representation (SR), proposed by Dayan [7], can be considered as a hybrid approach of model-based and model-free RL. Barreto et al. [3] derived a bound on value functions of an optimal policy when transferring policies using successor representations. Kulkarni et al. [24] proposed a method to learn deep successor features. In this work, we propose a new SR architecture with significantly reduced parameters, especially in large action spaces, to facilitate model convergence. We propose to first train the model with imitation learning and fine-tune with RL. It enables us to perform more realistic tasks and offers significant benefits for transfer learning to new tasks.
深度强化学习。最近的强化学习研究已经开始利用深度神经网络的力量。深RL方法在电子游戏[35]、棋盘游戏[46]、连续控制[30]等多个领域取得了成功。无模型的RL方法(如[30,34,35])的目的是学习仅仅从行为及其环境反馈行为;而基于模型的RL方法(如[8,44,50])也可以估计环境模型。由Dayan[7]提出的后继表示(SR)可以看作是基于模型和无模型RL的混合方法。Barreto等人在使用后继表示传递策略时,推导出最优策略的值函数的一个界。Kulkarni等人提出了一种学习深层后继特征的方法。在这项工作中,我们提出了一种新的SR架构,其参数显著减少,特别是在大型动作空间中,以促进模型的收敛。我们建议先用模仿学习训练模型,再用RL进行微调。它使我们能够执行更现实的任务,并为将学习转移到新任务中提供了显著的好处。
Learning from demonstrations. Expert demonstrations offer a source of supervision in tasks which must usually be learned with copious random exploration. A line of work interleaves policy execution and learning from expert demonstration that has achieved good practical results [6, 43]. Recent works have employed a series of new techniques for imitation learning, such as generative adversarial networks [19, 29], Monte Carlo tree search [17] and guided policy search [27], which learn end-to-end policies from pixels to actions.
从示范中学习。专家示范提供了一个监督任务的来源,这些任务通常必须通过大量的随机探索来学习。将策略执行与专家论证相结合的工作路线,取得了良好的实践效果[6,43]。近年来的研究工作采用了生成对抗网络[19,29]、蒙特卡罗树搜索[17]和引导策略搜索[27]等一系列模仿学习新技术,从像素点到动作点学习端到端的策略。
Synthetic data for visual tasks. Computer games and simulated platforms have been used for training perceptual tasks, such as semantic segmentation [18], pedestrian detection [33], pose estimation [38], and urban driving [5, 41, 42, 45]. In robotics, there is a long history of using simulated environments for learning and testing before real-world deployment [23]. Several interactive platforms have been proposed for learning control with visual inputs [4, 21, 26, 53, 54]. Among these, THOR [54] provides high-quality realistic indoor scenes. Our work extends THOR with a new set of actions and the integration of a planner.
视觉任务的合成数据。利用计算机游戏和仿真平台训练感知任务,如语义分割[18]、行人检测[33]、姿态估计[38]、城市驾驶等[5,41,42,45]。在机器人技术中,在实际部署[23]之前,使用模拟环境进行学习和测试已有很长的历史。已经提出了几种使用视觉输入进行学习控制的交互平台[4,21,26,53,54]。其中,THOR[54]提供了高质量的逼真的室内场景。我们的工作扩展了THOR的一套新的行动和一体化的规划。
3 Interactive Framework
交互框架
To enable interactions with objects and with the environment, we extend the THOR framework [54], which has been used for learning visual navigation tasks. Our extension in Figure 2. Example images that demonstrate the state changes before and after an object interaction from each of the six action types in our framework. Each action changes the visual state and certain actions may enable further interactions such as opening the fridge before taking an object from it.
为了支持与对象和环境的交互,我们扩展了THOR框架[54],该框架用于学习可视化导航任务。
图2中的扩展。
示例图像展示了框架中六种操作类型的对象交互前后的状态变化。
每个动作都会改变视觉状态,某些动作可能会使进一步的交互成为可能,比如在从冰箱中拿东西之前打开冰箱。
cludes new object states, and a discrete description of the scene in a planning language
包括新的对象状态,和一个离散的描述场景的规划语言
3.1 Scenes
场景
In this work, we focus on kitchen scenes, as they allow for a variety of tasks with objects from many categories. Our extended THOR framework consists of 10 individual kitchen scenes. Each scene contains an average of 53 distinct objects with which the agent can interact. The scenes are developed using the Unity 3D game engine.
在这项工作中,我们主要关注厨房场景,因为它们允许使用来自不同类别的对象执行各种任务。我们扩展的THOR框架由10个单独的厨房场景组成。每个场景平均包含53个不同的对象,代理可以与之交互。场景是使用Unity 3D游戏引擎开发的。
3.2 Objects and Actions
物品和动作
We categorize the objects by their affordances [15], i.e.
我们根据对象的可提供性[15]对其进行分类,即,
the plausible set of actions that can be performed. ,
即一组可行的行动。
For the tasks of interest, we focus on two types of objects: 1) items that are small objects (mug, apple, etc.) which can be picked up, held, and moved by the agent to various locations in the scene, and 2) receptacles that are large objects (table, sink, etc.) which are stationary and can hold a fixed capacity of items.
对于感兴趣的任务,我们专注于两种类型的对象:1)项小物体(杯子,苹果,等等),可以捡起,举行,并由代理场景中不同的位置,和2)插座大对象(表、水槽等)固定,可以保持固定容量的物品。
A subset of receptacles, such as fridges and cabinets, are containers.
容器的一个子集,如冰箱和橱柜,是容器。
These containers have doors that can be opened and closed.
这些容器的门可以打开和关闭。
The agent can only put an item in a container when it is open.
代理只能在容器打开时将某项物品放入容器中。
We assume that the agent can hold at most one item at any point.
我们假设代理在任何点最多可以持有一项物品。
We further define the following actions to interact with the objects
我们进一步定义以下操作来与对象交互
1. Navigate {receptacle}: moving from the current location of the agent to a location near the receptacle;
2. Open {container}: opening the door of a container in front of an agent;
3. Close {container}: closing the door of a container in front of an agent;
4. Pick Up {item}: picking up an item in field of view;
5. Put {receptacle}: putting a held item in the receptacle;
6. Look Up and Look Down: tilting the agent’s gaze 30 degrees up or down.
1. 导航{容器}:从代理的当前位置移动到容器附近的位置;
2. Open {container}:打开在代理面前的容器的门;
3.Close {container}:关闭在代理面前的容器的门;
4. 拾取{item}:在视图中拾取一个项目;
5. 放{容器}:将持有的物品放入容器中;
6. 向上看和向下看:将代理的目光向上或向下倾斜30度。
The combination of actions and arguments results in a large action set of 80 per scene on average.
动作和参数的组合产生了平均每个场景80个动作的大动作集。
Fig. 2 illustrates example scenes and the six types of actions in our framework.
图2展示了我们的框架中的示例场景和六种类型的操作。
Our definition of action space makes two important abstractions to make learning tractable: 1) it abstracts away from navigation, which can be tackled by a subroutine using existing methods such as [54];
我们对动作空间的定义有两个重要的抽象使学习变得容易处理:1)它抽象了导航,而导航可以通过使用现有的方法(如[54])的子程序来处理;
[54] ZHU Y, MOTTAGHI R, KOLVE E等. Target-driven visual navigation in indoor scenes using deep reinforcement learning[C]//2017 IEEE International Conference on Robotics and Automation (ICRA). Singapore, Singapore: IEEE, 2017: 3357–3364.
学习笔记:https://blog.csdn.net/jing_jing95/article/details/88171942
and 2) it allows the model to learn with semantic actions, abstracting away from continuous motions, e.g., the physical movement of a robot arm to grasp an object.
2)它允许模型通过语义动作来学习,从连续的动作中抽象出来,例如机器人手臂抓取物体的物理动作。
A common treatment for this abstraction is to “fill in the gaps” between semantic actions with callouts to a continuous motion planner [20, 47].
这种抽象的一种常见处理方法是用对连续运动规划器的标注“填补语义动作之间的空白”[20,47]。
It is evident that not all actions can be performed in every situation.
显然,并不是所有的行动都能在每一种情况下执行。
For example, the agent cannot pick up an item when it is out of sight, or put a tomato into fridge when the fridge door is closed.
例如,代理不能在物品看不见的情况下拿起物品,或者在冰箱门关闭的情况下将西红柿放入冰箱。
To address these requirements, we specify the pre-conditions and effects of actions.
为了满足这些需求,我们指定了操作的先决条件和效果。
Next we introduce an approach to declaring them as logical rules in a planning language.
接下来,我们将介绍一种方法,在规划语言中将它们声明为逻辑规则。
These rules are only encoded in the environment but not exposed to the agent.
这些规则只编码在环境中,而不公开给代理
Hence, the agent must learn them through interaction.
因此,代理必须通过交互来学习它们。
3.3. Planning Language
3.3 规划语言
The problem of generating a sequence of actions that leads to the goal state has been formally studied in the field of automated planning [14]. Planning languages offer a standard way of expressing an automated planning problem instance, which can be solved by an off-the-shelf planner. We use STRIPS [13] as the planning language to describe our visual planning problem.
在自动规划[14]领域中,已经正式研究了生成导致目标状态的一系列操作的问题。规划语言提供了一种表示自动化规划问题实例的标准方法,可以通过现成的规划器来解决。我们使用STRIPS[13]作为规划语言来描述我们的视觉规划问题。
In STRIPS, a planning problem is composed of a description of an initial state, a specification of the goal state(s), and a set of actions. In visual planning, the initial state corresponds to the initial configuration of the scene. The specification of the goal state is a boolean function that returns true on states where the task is completed. Each action is defined by its precondition (conditions that must be satisfied before the action is performed) and postcondition (changes caused by the action). The STRIPS formulation enables us to define the rules of the scene, such as object affordances and causality of actions.
在STRIPS中,规划问题由对初始状态的描述、目标状态的说明和一组操作组成。在视觉规划中,初始状态对应于场景的初始配置。目标状态的规范是一个布尔函数,在任务完成的状态上返回true。每个操作由其前置条件(在执行操作之前必须满足的条件)和后置条件(由操作引起的更改)定义。STRIPS的结构使我们能够定义场景的规则,例如对象的可接受性和动作的因果关系。
STRIPS(Stanford Research Institute Problem Solver)规划语言是最经典的一种规划语言,下面的规划问题也是基于STRIPS语言的描述。STRIPS语言包含三个要素:状态表示、目标表示和动作表示。
4. Our Approach
We first outline the basics of policy learning in Sec. 4.1. Next we formulate the visual semantic planning problem as a policy learning problem and describe our model based on successor representation. Later we propose two protocols of training this model using imitation learning (IL) and reinforcement learning (RL). To this end, we use IL to bootstrap our model and use RL to further improve its performance.
4. 我们的方法
我们首先在第4.1节中概述策略学习的基础。接下来,我们将视觉语义规划问题作为一个策略学习问题来描述,并基于后继表示来描述我们的模型。随后,我们提出了两种使用模仿学习(IL)和强化学习(RL)训练该模型的方案。为此,我们使用IL引导我们的模型,并使用RL进一步提高其性能。
4.1. Successor Representation
We formulate the agent’s interactions with an environment as a Markov Decision Process (MDP), which can be specified by a tuple (S;A; p; r; ƴ ). S and A are the sets of states and actions. For s ∈ S and a ∈ A, p( s' | s , a ) defines the probability of transiting from the state s to the next state s' ∈ S by taking action a. r(s, a) is a real-value function that defines the expected immediate reward of taking action a in state s. For a state-action trajectory, we define the future discounted return R = 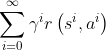 , where
, where ![]() is called the discount factor, which trades off the importance of immediate rewards versus future rewards.
is called the discount factor, which trades off the importance of immediate rewards versus future rewards.
我们将agent与环境的交互描述为一个马尔可夫决策过程(MDP),它可以由一个元组(S;A; p; r; ƴ )。S和A是状态和动作的集合。对于s ∈ S和s ∈ S, p( s' | s , a )通过采取行动a. r(s,a)是一个实值函数,定义了状态s中采取行动a的期望即时回报。对于状态-行动轨迹,我们定义了未来的折现收益R = ,其中![]() 被称为贴现因子,它权衡了即时奖励和未来奖励的重要性。
被称为贴现因子,它权衡了即时奖励和未来奖励的重要性。
马尔科夫决策过程
马尔科夫决策过程 (Markov Decision Processes, MDP)。马尔可夫决策过程是基于马尔可夫过程理论的随机动态系统的决策过程,其分五个部分:
1. 表示状态集 (states);
2. 表示动作集 (Action);
3. 表示状态 s 下采取动作 a 之后转移到 s’ 状态的概率;
4. 表示状态 s 下采取动作 a 获得的奖励;
5. 是衰减因子。
和一般的马尔科夫过程不同,马尔科夫决策过程考虑了动作,即系统下个状态不仅和当前的状态有关,也和当前采取的动作有关。还是举下棋的例子,当我们在某个局面(状态s)走了一步 (动作 a )。这时对手的选择(导致下个状态 s’ )我们是不能确定的,但是他的选择只和 s 和 a 有关,而不用考虑更早之前的状态和动作,即 s’ 是根据 s 和 a 随机生成的。
马尔科夫决策过程是强化学习的理论基础。有的时候我们知道马尔科夫决策过程所有信息(状态集合,动作集合,转移概率和奖励),有的时候我们只知道部分信息 (状态集合和动作集合),还有些时候马尔科夫决策过程的信息太大无法全部存储 (比如围棋的状态集合总数为)。强化学习算法按照上述不同情况可以分为两种: 基于模型 (Model-based) 和非基于模型 (Model-free)。基于模型的强化学习算法是知道并可以存储所有马尔科夫决策过程信息,非基于模型的强化学习算法则需要自己探索未知的马尔科夫过程。
策略和价值
强化学习技术是要学习一个策略 (Policy)。这个策略其实是一个函数,输入当前的状态 s,输出采取动作 a 的概率。有监督学习希望分类器正确地对实例分类,那么强化学习的目标是什么呢?强化学习希望把策略训练什么样呢? 假设我们的系统在一个状态 s 中,我们不会选择当前奖励 最大的动作 a。因此这个动作可能导致系统进入死胡同,即系统之后会受到很大的处罚。为了避免这种情况,策略要考虑到后续的影响。因此我们最大化递减奖励的期望。
其中 是马尔科夫决策过程的第五个部分:衰减因子。 用于平衡当前奖励和远期奖励的重要性,也是用来避免计算结果无穷。是系统在当前策略下第 k 步之后获得的奖励。这种目标既考虑了当前奖励又考虑了远期奖励,避免了下一个状态是死胡同的问题。
根据上面的目标,人们提出了价值的概念。一个策略下的一个状态的价值定义:这个状态下,按照这个策略,系统能够获得的递减奖励期望。
后来人们进一步扩展了价值的概念,将价值扩展到状态-动作对上。
强化学习的目标是找到一个策略 , 使得这个策略下每个状态的价值最大。但是这里有一个问题,对于两个策略,有可能出现:策略1状态 a 的价值大于策略2状态 b 的价值,但策略2状态 c 的价值大于策略1状态 d 的价值。因此我们不确定,是否存在一个策略3的所有状态价值大等于其他策略的状态价值。如果不存在这么一个策略,我们的目标是迷茫的。
但是万幸,下面的定理保证了这么一个策略存在。这么一个所有状态价值大等于其他所有的状态价值,我们可以称之为最优策略。强化学习算法的目标就是找到最优策略。

[7]
回报和返还(return)
使用未来的累积折现回报(cumulative discounted reward):
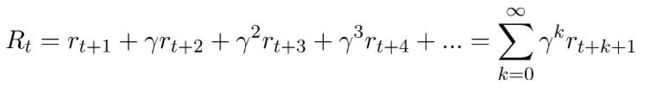
其中0<γ<1。以这种方式定义返还的两个好处是,返还在无穷级数中得到了很好的定义,而且它把更大的权重给了更早的回报,这意味着我们更关心即将得到的回报,而不是将来会得到更多的回报。我们为γ选择的值越小就越正确。这种情况在我们让γ等于0或1时就可以看到。如果γ等于1,这个方程就变成了对所有的回报都同样的关心,无论在什么时候。另一方面,当γ等于0时,我们只关心眼前的回报,而不关心以后的回报。这将导致我们的算法极其短视。它将学会采取目前最好的行动,但不会考虑行动对未来的影响。
策略
一个策略,写成π(s, a),描述了一种行动方式。它是一个函数,能够采取一个状态和一个行动,并返回在那个状态下采取这个行动的概率。因此,对于一个给定的状态,即
![]()
必须是真实的。
我们的策略应该描述如何在每个状态中采取行动.
我们在强化学习中的目标是学习一种最优策略,定义为
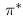
最优策略告诉我们如何采取行动来最大化每个状态的返还。
对于许多马尔可夫决策来说,最优策略是确定的。每个状态都有一个最优的行动。有时这被写成
![]()
它是从状态到这些状态中的最优行动的映射。
价值函数
为了学习最优策略,我们利用了价值函数。在强化学习中有两种类型的价值函数:状态值函数(state value function),用V(s)表示,和行动值函数,用Q(s,a)表示。
状态值函数在遵循策略时描述一个状态的值。当从状态的行为以我们的策略π开始时,这就是预期的返还。
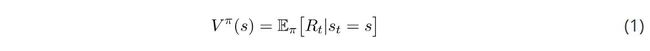
需要注意的是,即使在相同的环境中,价值函数也会根据策略发生变化。这是因为状态的价值取决于你的行动,因为你在那个特定的状态下的行动会影响你期望看到的回报。同时还要注意期望的重要性。期望(expectation)就像一个平均值;它就是你期望看到的返还。我们使用期望的原因是当你到达一个状态后会发生一些随机事件。你可能有一个随机的策略,这意味着我们需要把我们采取的所有不同行动的结果结合起来。此外,转换函数(transition function)可以是随机的,也就是说,我们可能不会以100%的概率结束任何状态。请记住上面的例子:当你选择一个行动时,环境将返回下一个状态。即使给出一个行动,也可能会有多个状态返还。当我们看贝尔曼方程时,会看到更多这样的情况。期望将所有这些随机因素考虑在内。
我们将使用的另一个价值函数是行动值函数。行动值函数告诉我们当跟随某个策略时,在某些状态下执行某个行动的值。给出状态和在π下的行动,这是期望的返还:
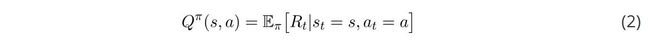
对状态值函数的注释同样适用于行动值函数。根据该策略,期望将考虑未来行动的随机性,以及来自环境的返还状态的随机性。
[8]
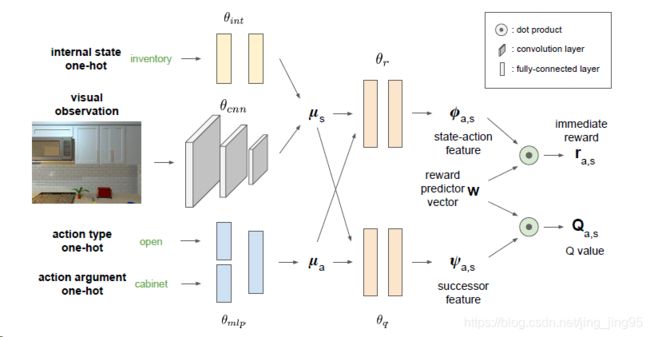
Figure 3.An overview of the network architecture of our successor representation (SR) model. Our network takes in the current state as well as a specific action and predicts an immediate reward ra;s as well as a discounted future reward Qa;s, performing this evaluation for each action. The learned policy π takes the argmax over all Q values as its chosen action.
对我们的后继表示(SR)模型的网络体系结构的概述。我们的网络接收当前状态以及特定的操作,并预测即时的奖励ra;s以及折扣的未来奖励Qa;s,对每个操作执行此评估。学习策略π以argmax所有Q值为选择行动。
argmax是一种函数,是对函数求参数(集合)的函数。当我们有另一个函数y=f(x)时,若有结果x0= argmax(f(x)),则表示当函数f(x)取x=x0的时候,得到f(x)取值范围的最大值;若有多个点使得f(x)取得相同的最大值,那么argmax(f(x))的结果就是一个点集。换句话说,argmax(f(x))是使得 f(x)取得最大值所对应的变量点x(或x的集合)。arg即argument,此处意为“自变量”。
一个策略π:S→A定义了一个从状态到行动的映射。策略学习的目标是找到并遵循能够从状态s0开始最大化未来贴现收益R的最优策略π*。与直接优化参数化策略不同,我们采取基于价值的方法。我们根据策略π定义了一个状态-动作值函数Qπ:S x A → R:
 (1)
(1)
也就是,从状态s开始的预期返回的场景,进行动作a,并遵循策略π。最优策略π*的Q值遵循贝尔曼方程[49]:
![]() (2)
(2)
在DQN(deep Q-learning networks),Q函数近似于一个神经网络![]() ,并且可以通过最小化公式(2)中的贝尔曼方程两边的L2距离被训练。一旦我们学习
,并且可以通过最小化公式(2)中的贝尔曼方程两边的L2距离被训练。一旦我们学习![]() ,在状态S时的最优动作可以被
,在状态S时的最优动作可以被![]() 选择。
选择。
DQN
深度增强学习(Deep Reinforcement Learning, DRL)是DeepMind(被谷歌收购)近几近来重点研究且发扬光大的机器学习算法框架。DQN(Deep Q-Learning Network)可谓是深度强化学习的开山之作,是将深度学习与强化学习结合起来从而实现从感知(Perception)到动作( Action )的端对端学习的一种全新的算法。DQN由DeepMind在NIPS 2013上首次发表,后又在Nature 2015上发表改进版。后续又有Double DQN,Prioritised Replay,Dueling Network等进一步改进。[2]
DQN与Qleanring类似都是基于值迭代的算法,但是在普通的Q-learning中,当状态和动作空间是离散且维数不高时可使用Q-Table储存每个状态动作对的Q值,而当状态和动作空间是高维连续时,使用Q-Table不动作空间和状态太大十分困难。
所以在此处可以把Q-table更新转化为一函数拟合问题,通过拟合一个函数function来代替Q-table产生Q值,使得相近的状态得到相近的输出动作。因此我们可以想到深度神经网络对复杂特征的提取有很好效果,所以可以将DeepLearning与Reinforcement Learning结合。这就成为了DQN。[3]
L2_distance(欧几里得距离)[4]
欧几里得度量(euclidean metric)(也称欧氏距离)是一个通常采用的距离定义,指在m维空间中两个点之间的真实距离,或者向量的自然长度(即该点到原点的距离)。在二维和三维空间中的欧氏距离就是两点之间的实际距离。[5]
贝尔曼方程
贝尔曼方程(Bellman Equation)也被称作动态规划方程(Dynamic Programming Equation),由理查·贝尔曼(Richard Bellman)发现。
贝尔曼方程是动态规划(Dynamic Programming)这些数学最佳化方法能够达到最佳化的必要条件。此方程把“决策问题在特定时间怎么的值”以“来自初始选择的报酬比从初始选择衍生的决策问题的值”的形式表示。借此这个方式把动态最佳化问题变成简单的子问题,而这些子问题遵守从贝尔曼所提出来的“最佳化还原理”。[6]
理查德·贝尔曼推导出了以下公式,让我们可以开始解决这些马尔可夫决策问题。贝尔曼方程在强化学习中无处不在,对于理解强化算法的工作原理是非常必要的。但在我们了解贝尔曼方程之前,我们需要一个更有用的符号,定义为
![]()
和
![]()
,如下所示:
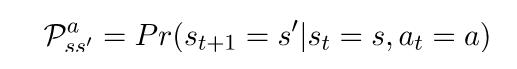
![]()
是过渡概率。如果我们从状态s开始,然后采取行动a,我们就会得到状态
![]()
和概率
![]()
。
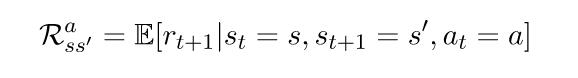
![]()
是另一种写为期望(或平均)回报的方式,我们从状态s开始,采取行动a,然后移动到状态
![]()
。
最后,有了这些条件,我们就可以推导出贝尔曼方程了。我们将考虑贝尔曼方程的状态值函数。根据返还的定义,我们可以重写方程(1),如下所示:
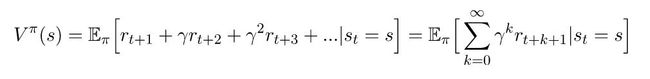
如果我们从求和中得到第一个回报,我们可以这样重写它:
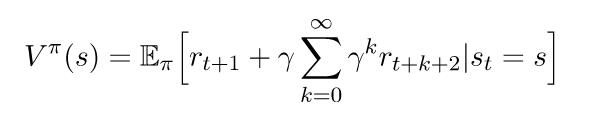
这里的期望描述的是,如果我们继续遵循策略π的状态s,我们期望返还的是什么。通过对所有可能的行动和所有可能的返还状态的求和,可以明确地编写为期望。下面的两个方程可以帮助我们完成下一个步骤。
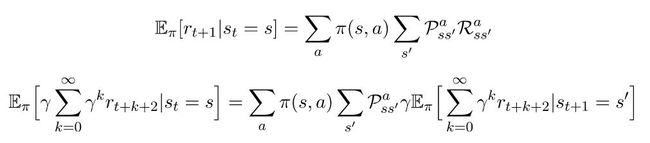
通过在这两个部分之间分配期望,我们就可以把我们的方程转化成:
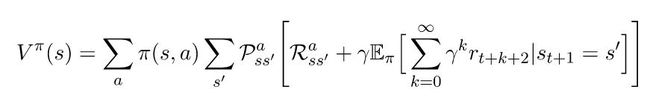
注意,方程(1)与这个方程的末尾形式相同。我们可以替换它,得到:
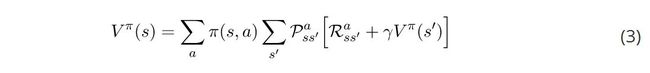
贝尔曼方程的行动值函数可以以类似的方式进行推导。本文结尾有具体过程,其结果如下:
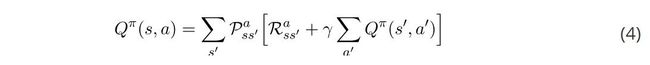
贝尔曼方程的重要性在于,它们让我们表达了其它状态的价值。这意味着,如果我们知道
![]()
的值,我们可以很容易地计算出
![]()
的值。这为计算每个状态值的迭代方法打开了大门,因为如果我们知道下一个状态的值,我们就可以知道当前状态的值。最重要的事情是我们需要记住一些编号方程。最后,在贝尔曼方程中,我们可以开始研究如何计算最优策略,并编码我们的第一个强化学习agent。
在我们推导出贝尔曼方程的过程中,我们得到了这一系列的方程,从方程(2)开始:

[8]
Successor representation (SR), proposed by Dayan [7], uses a similar value-based formulation for policy learning. It differs from traditional Q learning by factoring the value function into a dot product of two components: a reward predictor vector w and a predictive successor feature ![]() . To derive the SR formulation, we start by factoring the immediate rewards such that
. To derive the SR formulation, we start by factoring the immediate rewards such that
Dayan[7]提出的后继表示(SR)使用了类似的基于价值的策略学习公式。它不同于传统的Q学习,它将价值函数分解为两个部分的点积:奖励预测向量w和预测后继特征![]() .为了推导SR公式,我们首先考虑即时回报:
.为了推导SR公式,我们首先考虑即时回报:
![]()
where is a state-action feature. We expand Eq. (1) using this reward factorization:
在这里 是一个状态动作特性。我们使用这个奖励因子分解来展开公式(1):

We refer to ![\psi \left ( s,a \right )^{\pi } = E^{\pi }\left [ \sum _{\infty }^{i=0} \gamma ^{i}\phi _{s,a}\mid s_{0}= s,a_{0}= a\right ]](http://img.e-com-net.com/image/info8/60a9df735f21436b9b361ef010701b80.gif) as the successor features of the pair (s, a) under policy .
as the successor features of the pair (s, a) under policy .
根据策略,我们称为这对(s,a)的后继特征。
Intuitively, the successor feature ![]() summarizes the environment dynamics under a policy in a state-action feature space, which can be interpreted as the expected future “feature occupancy”. The reward predictor vector w induces the structure of the reward functions, which can be considered as an embedding of a task. Such decompositions have been shown to offer several advantages, such as being adaptive to changes in distal rewards and apt to option discovery [24]. A theoretical result derived by Barreto et al. implies a bound on performance guarantee when the agent transfers a policy from a task t to a similar task t0, where task similarity is determined by the l2-distance of the corresponding w vectors between these two tasks t and t0 [3]. Successor representation thus provides a generic framework for policy transfer in reinforcement learning.
summarizes the environment dynamics under a policy in a state-action feature space, which can be interpreted as the expected future “feature occupancy”. The reward predictor vector w induces the structure of the reward functions, which can be considered as an embedding of a task. Such decompositions have been shown to offer several advantages, such as being adaptive to changes in distal rewards and apt to option discovery [24]. A theoretical result derived by Barreto et al. implies a bound on performance guarantee when the agent transfers a policy from a task t to a similar task t0, where task similarity is determined by the l2-distance of the corresponding w vectors between these two tasks t and t0 [3]. Successor representation thus provides a generic framework for policy transfer in reinforcement learning.
直观地说,后继特性 ![]() 总结状态-动作特征空间中策略下的环境动态,可以理解为未来预期的“特征占用”。奖励预测向量w引入了奖励函数的结构,可以认为是任务的嵌入。这样的分解已经被证明提供了几个优势,例如能够适应远端奖励的变化和易于发现[24]选项。Barreto等人的理论结果表明,当代理将策略从任务t转移到相似的任务t'时,性能保证存在一个界限,其中任务相似性由这两个任务t和t'[3]之间对应的w向量的l2-距离决定。因此,后继表示为强化学习中的策略转移提供了一个通用框架。
总结状态-动作特征空间中策略下的环境动态,可以理解为未来预期的“特征占用”。奖励预测向量w引入了奖励函数的结构,可以认为是任务的嵌入。这样的分解已经被证明提供了几个优势,例如能够适应远端奖励的变化和易于发现[24]选项。Barreto等人的理论结果表明,当代理将策略从任务t转移到相似的任务t'时,性能保证存在一个界限,其中任务相似性由这两个任务t和t'[3]之间对应的w向量的l2-距离决定。因此,后继表示为强化学习中的策略转移提供了一个通用框架。
4.2. Our Model
We formulate the problem of visual semantic planning as a policy learning problem. Formally, we denote a task by a Boolean function ![]() , where a state s completes the task t if t(s) = 1. The goal is to find an optimal policy
, where a state s completes the task t if t(s) = 1. The goal is to find an optimal policy ![]() , such that given an initial state s0,
, such that given an initial state s0, ![]() generates a state-action trajectory
generates a state-action trajectory ![]() that maximizes the sum of immediate rewards
that maximizes the sum of immediate rewards  , where
, where ![]() and
and ![]() .
.
我们将视觉语义规划问题表述为一个策略学习问题。形式上,我们用一个布尔函数![]() 表示一个任务。其中如果 t(s) = 1,状态s完成任务t。目标是找到一个最优策略
表示一个任务。其中如果 t(s) = 1,状态s完成任务t。目标是找到一个最优策略![]() ,使给定初始状态s0,
,使给定初始状态s0,![]() 生成状态-动作轨迹最大化即时回报的总和,
生成状态-动作轨迹最大化即时回报的总和, ![]() 和
和![]() .
.
We parameterize such a policy using the successor representation (SR) model from the previous section. We develop a new neural network architecture to learn ![]() , and w. The network architecture is illustrated in Fig. 3. In THOR, the agent’s observations come from a first-person RGB camera. We also pass the agent’s internal state as input, expressed by one-hot encodings of the held object in its inventory. The action space is described in Sec. 3.2. We start by computing embedding vectors for the states and the actions. The image is passed through a 3-layer convolutional encoder, and the internal state through a 2-layer MLP, producing a state embedding
, and w. The network architecture is illustrated in Fig. 3. In THOR, the agent’s observations come from a first-person RGB camera. We also pass the agent’s internal state as input, expressed by one-hot encodings of the held object in its inventory. The action space is described in Sec. 3.2. We start by computing embedding vectors for the states and the actions. The image is passed through a 3-layer convolutional encoder, and the internal state through a 2-layer MLP, producing a state embedding ![]() .
.
我们使用上一节中的后继表示(SR)模型对此类策略进行参数化。我们开发了一种新的学习神经网络结构来学习 ![]() 和w.网络结构如图3所示。在THOR中,agent的观察来自第一人称RGB摄像机。我们还将代理的内部状态作为输入传递,该输入由其库存中所持有对象的独热编码表示。操作空间在第3.2节中描述。我们首先计算状态和动作的嵌入向量。图像通过3层卷积编码器传递,内部状态通过2层MLP传递,产生状态嵌入层
和w.网络结构如图3所示。在THOR中,agent的观察来自第一人称RGB摄像机。我们还将代理的内部状态作为输入传递,该输入由其库存中所持有对象的独热编码表示。操作空间在第3.2节中描述。我们首先计算状态和动作的嵌入向量。图像通过3层卷积编码器传递,内部状态通过2层MLP传递,产生状态嵌入层 ![]() 。
。
The action a = [atype; aarg] is encoded as one-hot vectors and passed through a 2-layer MLP encoder that produces an action embedding ![]() . We fuse the state and action embeddings and generate the stateaction feature s;a = h(s; a; r) and the successor feature s;a = m(s; a; q) in two branches. The network predicts the immediate reward rs;a = T s;aw and the Q value under the current policy Qs;a = T s;aw using the decomposition from Eq. (3) and (4).
. We fuse the state and action embeddings and generate the stateaction feature s;a = h(s; a; r) and the successor feature s;a = m(s; a; q) in two branches. The network predicts the immediate reward rs;a = T s;aw and the Q value under the current policy Qs;a = T s;aw using the decomposition from Eq. (3) and (4).
动作![]() 被编码为一个独热向量,并通过一个2层MLP编码器,该编码器产生一个动作嵌入层
被编码为一个独热向量,并通过一个2层MLP编码器,该编码器产生一个动作嵌入层![]() 。我们融合状态和动作嵌入,生成状态动作特性
。我们融合状态和动作嵌入,生成状态动作特性![]() 和在两个分支中的后继特征
和在两个分支中的后继特征![]() 。利用式(3)和式(4)的分解,网络预测即时奖励
。利用式(3)和式(4)的分解,网络预测即时奖励![]() 和当前策略Q下的Q值
和当前策略Q下的Q值![]() 。
。
多层感知机(MLP)原理简介
多层感知机(MLP,Multilayer Perceptron)也叫人工神经网络(ANN,Artificial Neural Network),除了输入输出层,它中间可以有多个隐层,最简单的MLP只含一个隐层,即三层的结构,如下图:
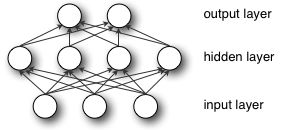
从上图可以看到,多层感知机层与层之间是全连接的(全连接的意思就是:上一层的任何一个神经元与下一层的所有神经元都有连接)。多层感知机最底层是输入层,中间是隐藏层,最后是输出层。
输入层没什么好说,你输入什么就是什么,比如输入是一个n维向量,就有n个神经元。
隐藏层的神经元怎么得来?首先它与输入层是全连接的,假设输入层用向量X表示,则隐藏层的输出就是
f(W1X+b1),W1是权重(也叫连接系数),b1是偏置,函数f 可以是常用的sigmoid函数或者tanh函数:
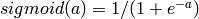
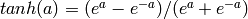
最后就是输出层,输出层与隐藏层是什么关系?其实隐藏层到输出层可以看成是一个多类别的逻辑回归,也即softmax回归,所以输出层的输出就是softmax(W2X1+b2),X1表示隐藏层的输出f(W1X+b1)。
MLP整个模型就是这样子的,上面说的这个三层的MLP用公式总结起来就是,函数G是softmax
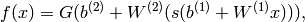
因此,MLP所有的参数就是各个层之间的连接权重以及偏置,包括W1、b1、W2、b2。对于一个具体的问题,怎么确定这些参数?求解最佳的参数是一个最优化问题,解决最优化问题,最简单的就是梯度下降法了(SGD):首先随机初始化所有参数,然后迭代地训练,不断地计算梯度和更新参数,直到满足某个条件为止(比如误差足够小、迭代次数足够多时)。这个过程涉及到代价函数、规则化(Regularization)、学习速率(learning rate)、梯度计算等,本文不详细讨论.[9]
4.3. Imitation Learning
Our SR-based policy can be learned in two fashions. First, it can be trained by imitation learning (IL) under the supervision of the trajectories of an optimal planner. Second, it can be learned by trial and error using reinforcement learning (RL). In practice, we find that the large action space in THOR makes RL from scratch intractable due to the challenge of exploration. The best model performance is produced by IL bootstrapping followed by RL fine-tuning. Given a task, we generate a state-action trajectory
我们以sr为基础的政策可以从两方面学习。首先,它可以通过模仿学习(IL)在最优规划器轨迹的监督下进行训练。
其次,它可以通过使用强化学习(RL)的反复试验来学习。在实践中,我们发现THOR中巨大的动作空间使得RL从零开始变得棘手,这是由于探索的挑战。最好的模型性能是通过IL引导和RL微调产生的。给定一个任务,我们生成一个状态-动作轨迹:
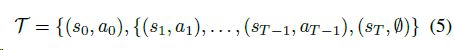
using the planner from the initial state-action pair (s0; a0)to the goal state sT (no action is performed at terminalstates). This trajectory is generated on a low-dimensional state representation in the STRIPS planner (Sec. 3.3). Each low-dimensional state corresponds to an RGB image, i.e., the agent s visual observation. During training, we perform input remapping to supervise the model with image-action pairs rather than feeding the low-dimensional planner states to the network. To fully explore the state space, we take planner actions as well as random actions off the optimal plan. After each action, we recompute the trajectory. This process of generating training data from a planner is illustrated in Fig. 4. Each state-action pair is associated with a true immediate reward ^rs;a. We use the mean squared loss function to minimize the error of reward prediction
使用初始状态-动作对(s0;a0)到目标状态sT(在终止状态不执行任何操作)。该轨迹是在条带规划器(第3.3节)中的低维状态表示上生成的。每个低维状态对应一个RGB图像,即,代理人的视觉观察。在训练过程中,我们使用图像-动作对执行输入重映射来监控模型,而不是将低维规划器状态提供给网络。为了充分挖掘状态空间,我们在最优规划中采取规划行动和随机行动。在每个动作之后,我们重新计算轨迹。从规划器生成训练数据的过程如图4所示。每个状态-动作对都与一个真正的即时奖励![]() 相关联。我们使用平均损失的平方函数来最小化回报预测的误差:
相关联。我们使用平均损失的平方函数来最小化回报预测的误差:

Following the REINFORCE rule [49], we use the discounted return along the trajectory T as an unbiased estimate of the true Q value: ^Q s;a PT?1 i=0 i^rs;a. We use the mean squared loss to minimize the error of Q prediction:
加强规则[49]后,我们使用贴现回报沿着轨迹T,也就是一个无偏估计的真正的Q值: 。我们使用均方损失来最小化Q预测的误差:
。我们使用均方损失来最小化Q预测的误差:

The final loss on the planner trajectory T is the sum of the reward loss and the Q loss: LT = Lr +LQ. Using this loss signal, we train the whole SR network on a large collection of planner trajectories starting from random initial states.
规划轨迹T上的最终损失为奖励损失与Q损失之和:LT = Lr +LQ。利用这一损失信号,我们将整个SR网络训练在从随机初始状态开始的大量规划轨迹集合上。
4.4. Reinforcement Learning
When training our SR model using RL, we can still use the mean squared loss in Eq. (6) to supervise the learning of reward prediction branch for and w. However, in absence of expert trajectories, we would need an iterative way to learn the successor features . Rewriting the Bellman equation in Eq. (2) with the SR factorization, we can obtain an equality on and :
当我们使用RL训练我们的SR模型时,我们仍然可以使用Eq.(6)中的均方损失来监督对于 和w的奖励预测分支的学习。但是,在没有专家轨迹的情况下,我们需要迭代的方法来学习后继特征
和w的奖励预测分支的学习。但是,在没有专家轨迹的情况下,我们需要迭代的方法来学习后继特征 。将式(2)中的Bellman方程改写为SR因子分解,可得一个和的等式:
。将式(2)中的Bellman方程改写为SR因子分解,可得一个和的等式:
![]()
在这里![]() 与DQN相同,我们最小化了公式(8)两侧的l2损失:
与DQN相同,我们最小化了公式(8)两侧的l2损失:
![]()
We use a similar procedure to Kulkarni et al. [24] to train our SR model. The model alternates training between the reward branch and the SR branch. At each iteration, a minibatch is randomly drawn from a replay buffer of past experiences [35] to perform one SGD update.
我们使用类似Kulkarni等人的[24]过程来训练我们的SR模型。该模型在奖励分支和SR分支之间交替进行培训。在每次迭代中,从过去经验的重播缓冲区中随机抽取一个小批处理来执行一次SGD更新。
4.5. Transfer with Successor Features
A major advantage of successor features is its ability to transfer across tasks by exploiting the structure shared by the tasks.
后继特性的一个主要优势是它能够通过利用任务共享的结构在任务之间进行传输。
给定一个固定的状态-行为对表示,令![]() 表示由和奖励预测向量w的所有实例化产生的所有可能的MDPs的集合。假定
表示由和奖励预测向量w的所有实例化产生的所有可能的MDPs的集合。假定![]() 是在集合
是在集合![]() 中第i次任务的最优策略。我们把
中第i次任务的最优策略。我们把![]() 表示为在新任务
表示为在新任务![]() 执行任务
执行任务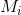 的最优策略的值函数,把
的最优策略的值函数,把![]() 作为在我们的SR模型中
作为在我们的SR模型中![]() 的近似值。在近似值中给定一个范围如:
的近似值。在近似值中给定一个范围如:
![]()
我们为使用![]() 的新任务
的新任务![]() 定义一个策略π',在这里
定义一个策略π',在这里![]()
Theorem 2 in Barreto et al. [3] implies a bound of the gap between value functions of the optimal policy n +1 and the policy 0:
Barreto等人的定理2[3]隐含了最优策略![]() 的值函数与策略π'之间的差的一个界:
的值函数与策略π'之间的差的一个界:
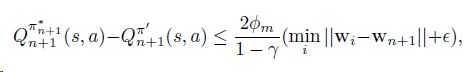
在这里![]()
This result serves the theoretical foundation of policy transfer in our SR model. In practice, when transferring to a new task while the scene dynamics remain the same, we freeze all model parameters except the single vector w. This way, the policy of the new task can be learned with substantially higher sample efficiency than training a new network from scratch.
该结果为SR模型中的政策转移提供了理论依据。在实际应用中,当切换到一个新任务时,在场景动态不变的情况下,我们冻结除单个向量w外的所有模型参数。这样,学习新任务的策略比从头开始训练一个新的网络具有更高的样本效率。
4.6. Implementation Details
We feed a history of the past four observations, converted to grayscale, to account for the agent‘s motions. We use a time cost of -0.01 to encourage shorter plans and a task completion reward of 10.0. We train our model with imitation learning for 500k iterations with a batch size of 32, and a learning rate of 1e-4. We also include the successor loss in Eq. (9) during imitation learning, which helps learn better successor features. We subsequently fine-tune the network with reinforcement learning with 10,000 episodes.
我们提供了过去四次观测的历史记录,转换为灰度,以解释代理的运动。我们使用-0.01的时间成本来鼓励更短的计划和10.0的任务完成奖励。我们对模型进行了500k次迭代的模仿学习训练,批量大小为32,学习速度为1e-4。我们还包括了在模仿学习中Eq.(9)中的后继损失,这有助于更好地学习后继特征。我们随后对网络进行了微调,增加了10000场景的强化学习。
5. Experiments
We evaluate our model using the extended THOR framework on a variety of household tasks. We compare our method against standard reinforcement learning techniques as well as with non-successor based deep models. The tasks compare the different methods abilities to learn across varying time horizons. We also demonstrate the SR network s ability to efficiently adapt to new tasks. Finally, we show that our model can learn a notion of object affordance by interacting with the scene.
我们使用扩展的THOR框架对各种家务任务进行评估。我们将我们的方法与标准的强化学习技术以及基于非后继的深度模型进行了比较。这些任务比较了不同方法的学习能力,跨越不同的时间范围。我们也展示了SR网络有效适应新任务的能力。最后,我们证明我们的模型可以通过与场景的交互学习对象可提供性的概念。
5.1. Quantitative Evaluation
5.1 定量评价
We examine the effectiveness of our model and baseline methods on a set of tasks that require three levels of planning complexity in terms of optimal plan length.
我们检查了我们的模型和基线方法在一组任务上的有效性,这些任务需要按照最优计划长度进行三个层次的规划复杂性。
Experiment Setup
We explore the two training protocols introduced in Sec. 4 to train our SR model
实验设置
我们研究了第4节中介绍的两种训练协议来训练SR模型
1. RL: we train the model solely based on trial and error, and learn the model parameters with RL update rules.
1. RL:我们只在反复试验的基础上对模型进行训练,利用RL更新规则学习模型参数。
2. IL: we use the planner to generate optimal trajectories starting from a large collection of random initial stateaction pairs. We use the imitation learning methods to train the networks using supervised losses.
2. IL:我们使用规划器从大量随机初始状态动作对集合出发,生成最优轨迹。我们使用模仿学习的方法来训练具有监督损失的网络。
Empirically, we find that training with reinforcement learning from scratch cannot handle the large action space. Thus, we report the performance of our SR model trained with imitation learning (SR IL) as well as with additional reinforcement learning fine-tuning (SR IL + RL).
从经验上看,从无到有的强化学习训练并不能适应大的动作空间。因此,我们报告了用模仿学习(SR IL)和附加强化学习微调(SR IL + RL)训练的SR模型的性能。
We compare our SR model with the state-of-the-art deep RL model, A3C [34], which is an advantage-based actorcritic method that allows the agent to learn from multiple copies of simulation while updating a single model in an asynchronous fashion. A3C establishes a strong baseline for reinforcement learning. We further use the same architecture to obtain two imitation learning (behavior cloning) baselines. We use the same A3C network structure to train a softmax classifier that predicts the planner actions given an input. The network predicts both the action types (e.g., Put) and the action arguments (e.g., apple). We call this baseline CLS-MLP. We also investigate the role of memory in these models. To do this, we add an extra LSTM layer to the network before action outputs, called CLS-LSTM. We also include simple agents that take random actions and take random valid actions at each time step.
我们将SR模型与最先进的深度RL模型A3C[34]进行比较,后者是一种基于优势的actorcritical方法,允许代理在异步更新单个模型的同时从多个模拟副本中学习。A3C为强化学习建立了一个强有力的基线。我们进一步使用相同的架构来获得两个模仿学习(行为克隆)基线。我们使用相同的A3C网络结构来训练一个softmax分类器,它可以预测给定输入的计划器动作。网络预测操作类型(例如Put)和操作参数(例如apple)。我们将此基线称为CLS-MLP。我们还研究了记忆在这些模型中的作用。为此,我们在操作输出之前向网络添加一个额外的LSTM层,称为cl -LSTM。我们还包括在每个时间步上执行随机操作和随机有效操作的简单代理。
Levels of task difficulty
We evaluate all of the models with three levels of task difficulty based on the length of the optimal plans and the source of randomization
任务难度等级
我们根据最优计划的长度和随机化的来源,对所有具有三个任务难度等级的模型进行了评估
1. Level 1 (Easy): Navigate to a container and toggle its state. A sample task would be go to the microwave and open it if it is closed, close it otherwise. The initial location of the agent and all container states are randomized. This task requires identifying object states and reasoning about action preconditions.
1. 第1级(容易):导航到容器并切换其状态。一个样本任务是走到微波炉前,如果它是关闭的,打开它,否则就关闭它。代理的初始位置和所有容器状态都是随机的。该任务需要识别对象状态并对操作先决条件进行推理。
2. Level 2 (Medium): Navigate to multiple receptacles, collect items, and deposit them in a receptacle. A sample task here is pick up three mugs from three cabinets and put them in the sink. Here we randomize the agent s initial location, while the item locations are fixed. This task requires a long trajectory of correct actions to complete the goal.
2. 二级(中级):导航到多个容器,从中收集物品,并将其放入其他容器中。这里的一个示例任务是从三个橱柜中取出三个杯子,并将它们放入水槽中。这里我们随机化代理的初始位置,而项目位置是固定的。这项任务需要一个长期的正确行动轨迹来完成目标。
3. Level 3 (Hard): Search for an item and put it in a receptacle. An example task is find the apple and put it in the fridge. We randomize the agent s location as well as the location of all items.This task is especially difficult as it requires longerterm memory to account for partial observability, such as which cabinets have previously been checked.
3.三级(高难度):搜索一个物品并将其放入容器中。一个例子任务是找到苹果并把它放进冰箱。我们随机化代理的位置以及所有项目的位置。这个任务特别困难,因为它需要较长时间的内存来考虑部分可观察性,比如以前检查过哪些柜子。
We evaluate all of the models on 10 easy tasks, 8 medium tasks, and 7 hard tasks, each across 100 episodes. Each episode terminates when a goal state is reached. We consider an episode fails if it does not reach any goal state within 5,000 actions. We report the episode success rate and mean episode length as the performance metrics. We exclude these failed episodes in the mean episode length metric. For the easy and medium tasks, we train the imitation learning models to mimic the optimal plans. However for the hard tasks, imitating the optimal plan is infeasible, as the location of the object is uncertain. In this case, the target object is likely to hide in a cabinet or a fridge which the agent cannot see. Therefore, we train the models to imitate a plan which searches for the object from all the receptacles in a fixed order. For the same reason, we do not perform RL fine-tuning for the hard tasks.
我们评估了所有模型的10个简单任务,8个中等任务和7个困难任务,每一个都跨越100个场景。当达到目标状态时,每个场景都将终止。如果在5000个动作中没有达到任何目标状态,我们认为该事件失败。我们将场景成功率和平均场景长度作为性能指标。我们在平均场景长度度量中排除了这些失败的剧集。对于简单任务和中等任务,我们训练模仿学习模型来模拟最优方案。但对于难度较大的任务,由于目标位置的不确定性,模拟最优方案是不可行的。在这种情况下,目标对象很可能隐藏在代理无法看到的橱柜或冰箱中。因此,我们训练模型模拟一个从所有容器中按固定顺序搜索目标的计划。出于同样的原因,我们不对困难的任务执行RL微调。
Table 1 summarizes the results of these experiments. Pure RL-based methods struggle with the medium and hard tasks because the action space is so large that naive exploration rarely, if ever, succeeds. Comparing CLS-MLP and CLS-LSTM, adding memory to the agent helps improving success rate on medium tasks as well as completing tasks with shorter trajectories in hard tasks. Overall, the SR methods outperform the baselines across all three task difficulties. Fine-tuning the SR IL model with reinforcement learning further reduces the number of steps towards the goal.
表1总结了这些实验的结果。纯粹的基于rl的方法很难完成中等难度的任务,因为操作空间太大,以至于单纯的探索很少能成功。通过比较CLS-MLP和CLS-LSTM,在代理中添加内存有助于提高中等任务的成功率,并有助于完成难度任务中轨迹较短的任务。总的来说,SR方法在所有三个任务困难中都优于基线。通过强化学习对SR IL模型进行微调,可以进一步减少实现目标的步骤。

Table 1. Results of evaluating the model on the easy, medium, and hard tasks. For each task, we evaluate how many out of the 100 episodes were completed (success rate) and the mean and standard deviation for successful episode lengths. The numbers in parentheses show the standard deviations. We do not fine-tune our SR IL model for the hard task.
表1。对模型进行简单、中等和困难任务的评价结果。对于每个任务,我们评估100个场景中完成了多少场景(成功率),以及成功的场景长度的平均值和标准偏差。括号中的数字表示标准差。我们没有为适应艰巨的任务而对SR IL模型进行微调。
5.2. Task Transfer
5.2 任务转移
One major benefit of the successor representation decomposition is its ability to transfer to new tasks while only retraining the reward prediction vector w, while freezing the successor features. We examine the sample efficiency of adapting a trained SR model on multiple novel tasks in the same scene. We examine policy transfer in the hard tasks, as the scene dynamics of the searching policy retains, even when the objects to be searched vary. We evaluate the speed at which the SR model converges on a new task by finetuning the w vector versus training the model from scratch. We take a policy for searching a bowl in the scene and substituting four new items (lettuce, egg, container, and apple) in each new task. Fig. 5 shows the episode success rates (bar chart) and the successful action rate (line plot).
后继表示分解的一个主要好处是,它能够转移到新的任务,同时只训练奖励预测向量w,同时冻结继承者的特征。我们研究了在同一场景中,将训练好的SR模型应用于多个新任务的样本效率。我们在困难的任务中研究策略转移,因为搜索策略的场景动态保持不变,即使要搜索的对象不同。我们通过调整w向量和从零开始训练模型来评估SR模型收敛于新任务的速度。我们采取一个策略,在场景中搜索一个碗,并在每个新任务中替换四个新物品(生菜、鸡蛋、容器和苹果)。图5为情节成功率(柱状图)和动作成功率(线状图)。

Figure 5. We compare updating w with retraining the whole network for new hard tasks in the same scene. By using successor features, we can quickly learn an accurate policy for the new item. Bar charts correspond to the episode success rates, and line plots correspond to successful action rate.
图5。我们将更新w后在同一场景中对整个网络进行新的困难任务的再培训与从头训练的模型进行了比较。通过使用后继特性,我们可以快速地了解新项目的准确策略。条形图对应的是场景成功率,线状图对应的是动作成功率。
By fine-tuning w, the model quickly adapts to new tasks, yielding both high episode success rate and successful action rate. In contrast, the model trained from scratch takes substantially longer to converge. We also experiment with fine-tuning the entire model, and it suffers from similar slow convergence.
通过对w的微调,该模型可以快速适应新的任务,从而获得较高的事件成功率和动作成功率。相比之下,从零开始训练的模型收敛所需的时间要长得多。我们还对整个模型进行了微调实验,结果表明该模型收敛速度较慢。
5.3. Learning Affordances
5.3 学习的可得性
An agent in an interactive environment needs to be able to reason about the causal effects of actions. We expect our SR model to learn the pre- and post-conditions of actions through interaction, such that it develops a notion of affordance [15], i.e., which actions can be performed under a circumstance. In the real world, such knowledge could help prevent damages to the agent and the environment caused by unexpected or invalid actions.
互动环境中的代理需要能够推断出行为的因果影响。我们期望我们的SR模型通过交互来学习操作的前置和后置条件,这样它就发展了一个可得性[15]的概念,即,即在某种情况下可以执行哪些操作。在现实世界中,这样的知识可以帮助防止意外或无效行为对agent和环境造成的损害。
We first evaluate each network s ability to implicitly learn affordances when trained on the tasks in Sec. 5.1. In these tasks, we penalize unnecessary actions with a small time penalty, but we do not explicitly tell the network which actions succeed and which fail. Fig. 6 illustrates that a standard reinforcement learning method cannot filter out unnecessary actions especially given delayed rewards. Imitation learning methods produce significantly fewer failed actions because they can directly evaluate whether each action gets them closer to the goal state.
我们首先评估每个网络在接受第5.1节任务训练时隐式学习可得性的能力。在这些任务中,我们用很小的时间惩罚不必要的操作,但是我们没有明确地告诉网络哪些操作成功了,哪些操作失败了。图6说明,标准的强化学习方法不能过滤掉不必要的行为,特别是在延迟奖励的情况下。模仿学习方法产生的失败行为显著减少,因为它们可以直接评估每个行为是否让它们更接近目标状态。

Figure 6. We compare the different models likelihood of performing a successful action during execution. A3C suffers from the large action space due to naive exploration. Imitation learning models are capable of differentiating between successful and unsuccessful actions because the supervised loss discourages the selection of unsuccessful actions.
图6。我们比较了在执行过程中执行成功操作的不同模型的可能性。A3C由于初级的探索,行动空间大。模仿学习模型能够区分成功和不成功的行为,因为监督损失阻碍了不成功行为的选择。
We also analyze the successor network’s capability of explicitly learning affordances. We train our SR model with reinforcement learning, by executing a completely random policy in the scene. We define the immediate reward of issuing a successful action as +1:0 and an unsuccessful one as -1.0 . The agent learns in 10,000 episodes. Fig. 7 shows a t-SNE [31] visualization of the state-action features ![]() . We see that the network learns to cluster successful state action pairs (shown in green) separate from unsuccessful pairs (orange). The network achieves an ROC-AUC of 0.91 on predicting immediate rewards over random state-action actions, indicating that the model can differentiate successful and unsuccessful actions by performing actions and learning from their outcomes.
. We see that the network learns to cluster successful state action pairs (shown in green) separate from unsuccessful pairs (orange). The network achieves an ROC-AUC of 0.91 on predicting immediate rewards over random state-action actions, indicating that the model can differentiate successful and unsuccessful actions by performing actions and learning from their outcomes.
分析了后继网络的显式学习能力。通过在场景中执行完全随机的策略,用强化学习训练SR模型。我们将发出成功操作的即时回报定义为+1:0,而发出失败操作的即时回报定义为-1.0。agent在10000个场景里学习。图7为状态-动作特征![]() 的t-SNE[31]可视化。我们看到,网络学会将成功的状态操作对(绿色显示)与失败的状态操作对(橙色)分开进行集群。该网络对随机的状态-动作对的行为的即时回报预测的ROC-AUC为0.91,表明该模型可以通过执行行为并从行为的结果中学习来区分成功和不成功的行为。
的t-SNE[31]可视化。我们看到,网络学会将成功的状态操作对(绿色显示)与失败的状态操作对(橙色)分开进行集群。该网络对随机的状态-动作对的行为的即时回报预测的ROC-AUC为0.91,表明该模型可以通过执行行为并从行为的结果中学习来区分成功和不成功的行为。

Figure 7. Visualization of a t-SNE [31] embedding of the stateaction vector k for a random set of state-action pairs. Successful state-action pairs are shown in green, and unsuccessful pairs in orange. The two blue circles highlight portions of the embedding with very similar images but different actions. The network can differentiate successful pairs from unsuccessful ones.
图7。为一组随机的状态动作对嵌入状态动作向量![]() 的t-SNE[31]的可视化。成功的状态-动作对用绿色表示,失败的状态-动作对用橙色表示。两个蓝色圆圈用非常相似的图像突出显示了嵌入的部分,但是操作不同。网络可以区分成功对和不成功对。
的t-SNE[31]的可视化。成功的状态-动作对用绿色表示,失败的状态-动作对用橙色表示。两个蓝色圆圈用非常相似的图像突出显示了嵌入的部分,但是操作不同。网络可以区分成功对和不成功对。
6. Conclusions
In this paper, we argue that visual semantic planning is an important next task in computer vision. Our proposed solution shows promising results in predicting a sequence of actions that change the current state of the visual world to a desired goal state. We have examined several different tasks with varying degrees of difficulty and show that our proposed model based on deep successor representations achieves near optimal results in the challenging THOR environment. We also show promising cross-task knowledge transfer results, a crucial component of any generalizable solution. Our qualitative results show that our learned successor features encode knowledge of object affordances, and action pre-conditions and post-effects. Our next steps involve exploring knowledge transfer from THOR to realworld environments as well as examining the possibilities of more complicated tasks with a richer set of actions.
本文认为,视觉语义规划是计算机视觉的一个重要研究方向。我们提出的解决方案在预测一系列将当前视觉世界状态更改为期望目标状态的操作方面显示了良好的结果。我们研究了不同难度的几个不同任务,结果表明,我们提出的基于深度后继表示的模型在具有挑战性的THOR环境中取得了接近最优的结果。我们还展示了很有前景的跨任务知识转移结果,这是任何可推广解决方案的关键组成部分。我们的定性结果表明,我们学习的后继特征编码了物品的可得性以及行为的先决条件和后效应的知识。我们接下来的步骤包括探索从THOR到现实世界环境的知识转移,以及用更丰富的行动来研究更复杂任务的可能性。
后继表示(successor representation,SR)
强化学习 reinforcement learning RL
模仿学习(IL)
参考文献:
[1] https://blog.csdn.net/yh0vlde8vg8ep9vge/article/details/78823489
[2] http://lanbing510.info/2018/07/17/DQN.html
[3] https://blog.csdn.net/qq_30615903/article/details/80744083
[4] https://en.wikipedia.org/wiki/Euclidean_distance
[5] https://baike.baidu.com/item/%E6%AC%A7%E5%87%A0%E9%87%8C%E5%BE%97%E5%BA%A6%E9%87%8F/1274107?fromtitle=%E6%AC%A7%E6%B0%8F%E8%B7%9D%E7%A6%BB&fromid=1798948#2
[6] https://baike.baidu.com/item/%E8%B4%9D%E5%B0%94%E6%9B%BC%E6%96%B9%E7%A8%8B
[7] https://blog.csdn.net/hellocsz/article/details/80754644
[8] http://www.atyun.com/10331.html
[9] http://www.atyun.com/10331.html