半监督生成对抗网络(SGAN)matlab实战
一、原理
半监督学习(semi-supervised learning)是GAN在实际应用中最有前途的领域之一,与监督学习(数据集中的每个样本有一个标签)和无监督学习(不使用任何标签)不同,半监督学习只为训练数据集的一小部分提供类别标签。通过内化数据中的隐藏结构,半监督学习努力从标注数据点的小子集中归纳,以有效地对从未见过的新样本进行分类,要使半监督学习有效,标签数据和无标签数据必须来自相同的基本分布。
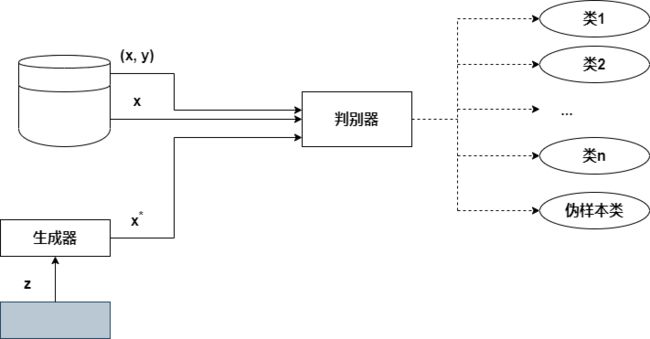
半监督生成对抗网络(Semi-Supervised GAN, SGAN)是一种生成对抗网络,其判别器是多分类器。这里的判别器不只是区分两个类(真和假),而是学会区分N+1类,其中N是训练数据集中的类数,生成器生成的伪样本增加了一个类。判别器接收3种数据输入:来自生成器的伪数据、真实的无标签数据样本X和真实的标签数据样本(x,y),其中y是给定样本对应的标签;然后判别器输出分类,以区分伪样本与真实样本区,并为真实样本确定正确的类别。注意,标签数据比无标签数据少得多。实际情况中,这一对比甚至比本图所显示的更明显,标签数据仅占训练数据的一小部分。
二、代码实战
clear all; close all; clc;
%% Semi-Supervised Generative Adversarial Network
%% Load Data
load('mnistAll.mat')
trainX = preprocess(mnist.train_images);
trainY = mnist.train_labels;
testX = preprocess(mnist.test_images);
testY = mnist.test_labels;
%% Settings
settings.latentDim = 100; settings.num_classes = 10;
settings.batch_size = 32; settings.image_size = [28,28,1];
settings.lr = 0.0002; settings.beta1 = 0.5;
settings.loss_weights = [.5,.5];
settings.beta2 = 0.999; settings.maxepochs = 50;
%% Initialization
%% Generator
paramsGen.FCW1 = dlarray(initializeGaussian([128*7*7,...
settings.latentDim]));
paramsGen.FCb1 = dlarray(zeros(128*7*7,1,'single'));
paramsGen.BNo1 = dlarray(zeros(128,1,'single'));
paramsGen.BNs1 = dlarray(ones(128,1,'single'));
paramsGen.TCW1 = dlarray(initializeGaussian([3,3,128,128]));
paramsGen.TCb1 = dlarray(zeros(128,1,'single'));
paramsGen.BNo2 = dlarray(zeros(128,1,'single'));
paramsGen.BNs2 = dlarray(ones(128,1,'single'));
paramsGen.TCW2 = dlarray(initializeGaussian([3,3,64,128]));
paramsGen.TCb2 = dlarray(zeros(64,1,'single'));
paramsGen.BNo3 = dlarray(zeros(64,1,'single'));
paramsGen.BNs3 = dlarray(ones(64,1,'single'));
paramsGen.CNW1 = dlarray(initializeGaussian([3,3,64,1]));
paramsGen.CNb1 = dlarray(zeros(1,1,'single'));
stGen.BN1 = []; stGen.BN2 = []; stGen.BN3 = [];
%% Discriminator
paramsDis.CNW1 = dlarray(initializeGaussian([3,3,1,32]));
paramsDis.CNb1 = dlarray(zeros(32,1,'single'));
paramsDis.CNW2 = dlarray(initializeGaussian([3,3,32,64]));
paramsDis.CNb2 = dlarray(zeros(64,1,'single'));
paramsDis.BNo1 = dlarray(zeros(64,1,'single'));
paramsDis.BNs1 = dlarray(ones(64,1,'single'));
paramsDis.CNW3 = dlarray(initializeGaussian([3,3,64,128]));
paramsDis.CNb3 = dlarray(zeros(128,1,'single'));
paramsDis.BNo2 = dlarray(zeros(128,1,'single'));
paramsDis.BNs2 = dlarray(ones(128,1,'single'));
paramsDis.CNW4 = dlarray(initializeGaussian([3,3,128,256]));
paramsDis.CNb4 = dlarray(zeros(256,1,'single'));
paramsDis.FCW1 = dlarray(initializeGaussian([settings.num_classes+2,256*4*4]));
paramsDis.FCb1 = dlarray(zeros(settings.num_classes+2,1,'single'));
stDis.BN1 = []; stDis.BN2 = []; stDis.BN3 = [];
% average Gradient and average Gradient squared holders
avgG.Dis = []; avgGS.Dis = []; avgG.Gen = []; avgGS.Gen = [];
%% Train
numIterations = floor(size(trainX,4)/settings.batch_size);
% Loss due to true or not
dlossreal=-mean(log(d_output_real(1,:)+eps)+...
labels_real.*log(d_output_real(2:end,:)+eps),'all');
dlossfake=-mean(log(1-d_output_fake(1,:)+eps)+...
labels_fake.*log(d_output_fake(2:end,:)+eps),'all');
d_loss = .5*(dlossreal+dlossfake);
% g_loss=-mean(log(d_output_fake(1,:)+eps)+...
% labels_real.*log(d_output_fake(2:end,:)+eps),'all');
g_loss=-mean(log(d_output_fake(1,:)+eps),'all');
% For each network, calculate the gradients with respect to the loss.
GradGen = dlgradient(g_loss,paramsGen,'RetainData',true);
GradDis = dlgradient(d_loss,paramsDis);
end
%% progressplot
function progressplot(paramsGen,stGen,settings)
r = 5; c = 5;
noise = gpdl(randn([settings.latentDim,r*c]),'CB');
gen_imgs = Generator(noise,paramsGen,stGen);
gen_imgs = reshape(gen_imgs,28,28,[]);
fig = gcf;
if ~isempty(fig.Children)
delete(fig.Children)
end
I = imtile(gatext(gen_imgs));
I = rescale(I);
imagesc(I)
title("Generated Images")
colormap gray
drawnow;
end
%% dropout
function dly = dropout(dlx,p)
if nargin < 2
p = .3;
end
[n,d] = rat(p);
mask = randi([1,d],size(dlx));
mask(mask<=n)=0;
mask(mask>n)=1;
dly = dlx.*mask;
end